Spark의 분산 처리 방식에 대해 다루기에 앞서
Client Mode와 Cluster Mode를 정리하고 넘어가야할 것 같습니다.
📃 Client Mode와 Cluster Mode
Spark에서 작업 실행의 핵심은 Driver입니다.
Driver가 어디에서 실행되느냐에 따라 Client Mode / Cluster Mode로 나뉘게됩니다.
일반적으로 spark-submit 명령를 통해 Application을 실행할 때 해당 Mode들을 선택할 수 있습니다.
( 단, spark-submit이 실행 가능한 위치는 Mode마다 다릅니다. )
# Cluster Manager : yarn
# cluster mode
spark-submit \
--master yarn \ # 외부 프레임워크 yarn, k8s
--deploy-mode cluster \ # mode : cluster
my_spark_app.py # 실행 코드
# client mode
spark-submit \
--master yarn \
--deploy-mode client \
my_spark_app.py
# Cluster Manager : Master node(standalone)
# cluster mode
spark-submit \
--master spark://master-hostname:7077 \ # Master Node의 주소
--deploy-mode cluster \
my_spark_app.pyCluster Mode란?
Cluster Mode는 spark-submit 명령어를 통해 Spark Application을 실행할 때,
Driver가 Cluster 내부에서 실행되는 모드입니다.
spark-submit 명령을 Cluster Manager가 입력 받아 Cluster 내의 Driver를 실행시키는 방식인 것이죠.
( spark-submit -> Cluster Manager -> Driver -> Executor )
-
spark-submit은 어느 위치에서 실행할 수 있을까요?
-
Cluster Mode의 경우, Driver의 위치와 무관하게 Cluster와 네트워크 상 연결이 되어있는 곳이라면 어디에서든 실행할 수 있습니다.
-
spark-submit을 실행시키기 위한 Edge Node를 만드는 방법도 있습니다.
- Cluster에 접근 가능한 Bastion Host를 만들어 간접적인 접근을 통해 Job을 제출하도록 만드는 방식이죠.
- 이 경우, 클러스터 내부를 외부 사용자로부터 보호할 수 있다는 장점이 있습니다.
-
-
Driver가 Cluster 내부에서 실행되면 어떤 장점이 있을까요?
-
먼저, 네트워크 연결이 빠르고 안정적입니다.
Driver와 Executor가 동일한 Cluster 내에 있기 때문에 그렇지 않은 경우의 Cluster 내부로 진입하는 과정을 생각한다면 상대적으로 빠르고 안정적이라고 볼 수 있습니다. -
운영 환경의 제약을 받지 않습니다.
Cluster 내의 리소스를 그대로 사용하기 때문에 적은 메모리의 외부 환경에서도 손쉽게 spark-submit 명령이 가능합니다. -
가장 중요한 점은 오랜 시간동안 Job을 수행하기에 적합하다는 것입니다.
Driver가 Cluster 내부에 있기 때문에 외부 로컬환경에서 spark-submit 명령을 내리고 종료하더라도 어떠한 영향없이 장시간 동안 Job 수행이 가능하게 됩니다. 또한, Cluster Manager가 Driver를 관리하기 때문에 Driver 장애 발생시 자동으로 재실행을 할 수 있습니다.
-
-
단점?
- 단점은 Log 확인이나 디버깅이 Client Mode에 비해 번거롭다는 점 외에는 아직 확인하지 못했습니다.
Client Mode란?
Client Mode는 Spark Application을 실행할 때,
Driver가 spark-submit을 실행한 로컬 환경에서 실행되는 모드입니다.
즉, spark-submit을 실행하는 위치와 Driver의 위치가 동일하다는 것입니다.
( spark-submit(Local) -> Driver(Local) -> Cluster Manager -> Executor )
또한, Driver의 실행 위치만을 두고 나누었을 뿐이지,
Client Mode라고 Cluster를 사용하지 않아도 되는 것은 아닙니다.
( 별도의 Cluster 환경이 없는 경우는 단일 Cluster 환경인 standalone으로 사용 )
그러면 Cluster Mode의 여러 장점들이 역으로 Client Mode의 단점이 될텐데,
왜 장점이 적고 단점이 많은 Client Mode를 사용하는 것일까요?
제 생각에는 테스트, 개발을 위한 일종의 경량화 버전이라고 보면 될 것 같습니다. log확인이나 디버깅이 상대적으로 간단하고 단순 작업만을 하길 원한다면 Cluster Mode에 비해 간편하기 때문이죠.
-
Client Mode를 사용하는 상황 예시
-
테스트/개발/디버깅
-
Cluster 내 리소스를 아끼고 싶을 때, 로컬 리소스로 대신하는 경우
-
Jupyter Notebook을 통한 데이터 분석을 하는 경우
-
Edge Node를 사용하는 경우
-
Edge Node를 사용하면 Cluster Mode의 장점을 살리면서 Client Mode를 실행시킬 수 있습니다. Cluster 내의 Bastion Host를 만들어서 그곳에 Driver를 위치시키고 spark-submit 명령을 수행한다면 Log 확인, 디버깅도 쉬우면서 네트워크 안정성도 챙기게 되겠죠.
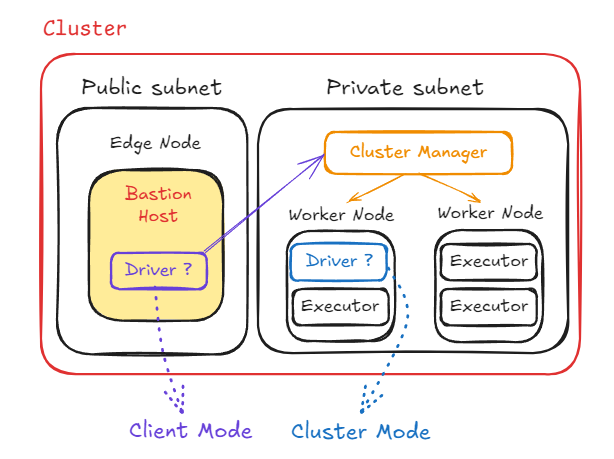
Edge Node에서의 Client Mode와 Cluster Mode
그러면 Edge Node에서의 Client Mode, Cluster Mode의 기능 상의 역할이 동일한 것이 아닌가? 어떤 차이점이 있지? 라는 생각이 들 수 있습니다.
다시 집고 넘어가자면 Edge Node는 Cluster 내의 Bastion Host를 의미합니다.
이 Bastion Host에서 spark-submit 명령을 실행하기 위한 목적으로 Edge Node를 생성한 것이죠.
이 Bastion Host에 Driver가 위치한다면 Client Mode가,
Worker Node에 Driver가 위치한다면 Cluster Mode가 됩니다.
공통점으로는 Cluster 내에 존재하기 때문에 Cluster의 리소스를 사용할 수 있고 네트워크가 안정적이다는 장점이 있습니다.
그렇다면 차이점은 Cluster의 특징이 아닌 단순 Driver의 위치 차이로 인한 특징들이겠네요.
-
차이점 (Cluster/Client)
-
Driver의 자동 재실행 가능/불가능
( Driver를 실행시키는 주체가 Cluster Manager/Local에서 수동 실행 ) -
로그 확인의 불편함/편리함
( Cluster Manager에 따른 UI가 필요/Local에서 바로 확인 가능 ) -
리소스 관리 일관성의 유/무 - Cluster Manager의 자원 관리 체계
이 부분을 조금 자세히 살펴보겠습니다.
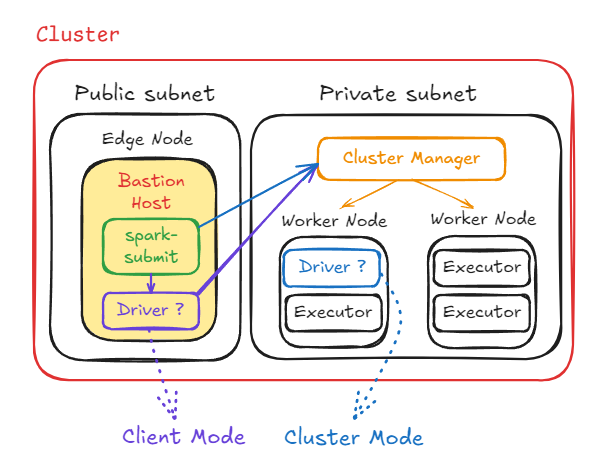
먼저, Driver에서는 OOM 현상이 발생할 수 있습니다.
Task의 수행 결과를 Driver가 받기 때문에 그 데이터 양이 상당하다면 Driver 내의 리소스가 부족해 OOM 현상이 발생할 수 있습니다. 그렇기에 실행 전 Driver의 리소스를 알맞게 설정하는 것이 중요합니다.Cluster Manager는 자원 관리 체계를 갖추고 있어, 이러한 OOM 현상을 막고자 실행 전에 리소스 관리를 하게 됩니다. 그런데 Cluster Mode는 Cluster Manager가 Driver까지 제어할 수 있어 문제가 없지만, Client Mode는 Cluster Manager가 Executor까지만 제어 가능하여 Driver의 리소스를 책정할 수도, 제어할 수도 없습니다.
그렇게 되면 Client Mode에서 어떤 일이 발생할까요?
예를 들어, Edge Node에 다수의 사용자가 Job을 동시에 실행했다고 하겠습니다. 그러면 Cluster Manager가 Driver를 제어하지 못하여 Driver 간의 충돌이 발생하고, 사전에 Driver의 리소스를 조정하지 않아 OOM 현상이 발생할 수도 있습니다. 중요한 점은 Cluster Manager가 이를 방지하지도 못하지만 감지조차 하지 못한다는 것이죠.그렇기에, Client Mode를 사용할 때 여러 사용자의 동시 접근에 대해서는 주의를 기울일 필요가 있습니다.
-
이렇게 Edge Node를 통해 Client Mode와 Cluster Mode를 살펴보니,
큰 틀로써 Cluster Mode는 운영 용도, Client Mode는 테스트/개발 용도로 잡고
상황에 맞추어 그때마다 바꿔 사용하면 되겠다는 생각이 드네요.
그런데 또 드는 의문점..
- Driver는 어떻게 설치할까요..?
-> Driver는 설치하는 것이 아니라 spark-submit 실행 시에 자동으로 생성됩니다.- Cluster Mode는 Cluster Manager가 생성해주고,
- Client Mode는 spark-submit과 동시에 Driver가 생성되는 것이라고 보면 될 것 같습니다.
다음은 Client, Cluster Mode의 실행 흐름을 소스코드 기반으로 정리해보겠습니다.
Reference
