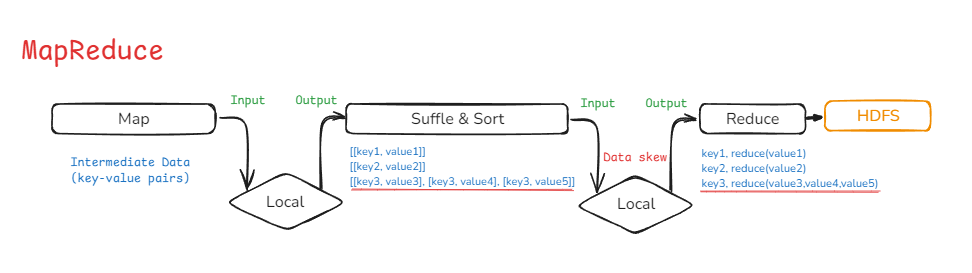
왜 MapReduce가 아니라 Spark일까?
기존 Hadoop의 분산 처리 방식이였던 MapReduce는 디스크 기반으로,
데이터의 중간 과정을 로컬디스크에 저장하기 때문에 I/O 오버헤드가 지속적으로 발생했습니다.
MapReduce의 대체제로 나온 Spark는 In-memory 기반으로 I/O 오버헤드도 상당히 줄었으며,
DAG 기반의 최적화된 실행 전략으로 10배 이상 빠른 속도로 처리할 수 있게 되었습니다.
📚 Spark의 분산 처리 방식
Spark의 분산 처리는 크게 2가지 방식으로 분류할 수 있습니다.
1. 다수의 Worker들을 이용한 병렬 처리 방식 (Cluster)
2. Partition 단위의 분산 처리 방식
위 2가지 방식에 최종적으로 Spark의 실행 흐름에 따른 정리까지 천천히 포스팅해보겠습니다.
📖 1. 다수의 Worker들을 이용한 병렬 처리 방식
Spark는 Cluster 환경을 통해 여러 컴퓨터를 하나의 시스템처럼 동작하게 합니다.
작업해야 할 데이터의 양이 너무 거대해 하나의 컴퓨팅 파워로 부족하다면, 컴퓨터 여러 대를 연결해서 나눠서 처리하겠다는 것이죠.
Spark의 Cluster 구조는 일반적으로 아래 그림처럼 알려져있습니다.
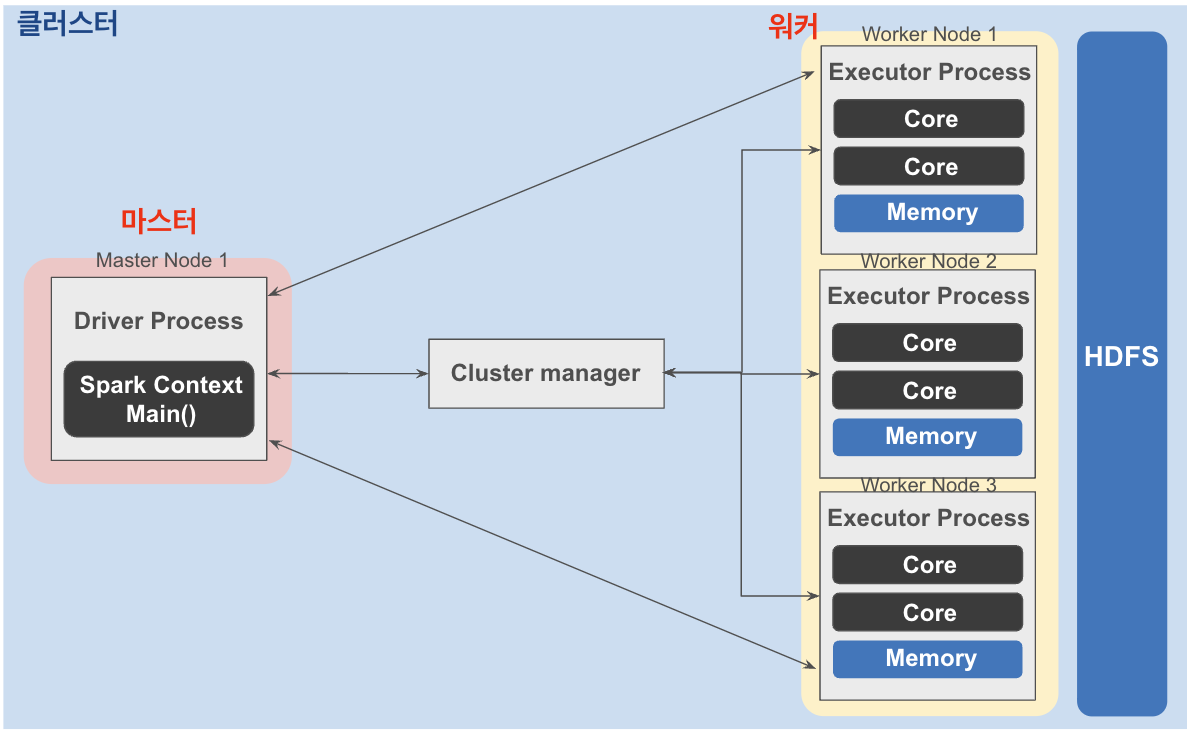
Cluster는 크게 Master Node, Cluster Manager, Worker Node로 3개의 요소로 구성되어있다고 알려져있으나,
자칫 착각할 수 있는 부분이 있기에 이를 정정하고 넘어가겠습니다.
위 그림의 마스터라 표시된 부분이 올바르지 않습니다.
Master Node는 리소스 및 스케줄링 관리만 할뿐, Driver 자체는 Worker Node에서 실행됩니다.
또한, Master Node 자체가 Cluster Manager와 거의 역할이 다르지 않습니다.
이를 정리을 해보자면,
위 그림을 기준으로 좌측의 'Driver Process'가 담긴 Node는 마스터가 아닌 워커의 일종이고,
오히려 Cluster Manager가 마스터에 가장 가까울 것입니다.
( Standalone 기준 )
위 요소들을 하나씩 설명하며 저의 견해를 작성해보겠습니다.
Cluster Manager
Cluster의 전반적인 리소스 관리 및 작업 스케줄링을 담당하는 시스템입니다.
Cluster Manager는 YARN, K8s 같은 외부 프레임워크를 사용하거나,
Standalone 모드를 통해 별도의 설정 없이 Master Node를 Cluster Manager로 사용할 수도 있습니다.자세한 내용은 아래에서 추가로 설명하겠습니다.
Master Node
Master Node는 Cluster Manager와 동일한 역할을 수행합니다. Worker Node를 등록 및 관리하고 모니터링 기능도 제공해줍니다.
그렇다면 Cluster Manager와 차이가 무엇일까요?
제 생각에 Master Node란,
Spark에서 자체 제공하는 일종의 Cluster Manager라고 생각하는데요.실제로 Master Node는 Standalone 모드에서만 존재하며,
외부 프레임워크(YARN,K8s)를 Cluster Manager로 사용할 때는 Master Node가 존재하지 않습니다.
( 단, Mesos는 자체적으로 Master Node를 사용합니다. )또한,
Standalone 모드의 Master Node는 Cluster Manager를 내포하고 있다는 점과 Cluster Manager 역할을 제외한 Master Node만의 역할이 두드러지지 않는다는 점이를 고려했을 때, Master Node는 단일 Cluster라는 제약만 가졌을 뿐 Cluster Manager와 다를 바가 없다고 생각합니다.
Worker Node
Cluster의 가장 중요한 작업자들입니다. 실제 Task를 수행하는 작업자들로 여러 개의 Worker들을 연결해 Large 데이터들도 병렬 처리할 수 있도록 하는 것이죠.
Worker들의 모든 Core와 메모리를 종합해 Cluster Manager가 하나의 시스템처럼 관리하는 것이고요.
기존 리소스로 데이터 처리가 버겁다면 scale out을 통해 Worker를 늘려주면 되니 확장성도 좋습니다.
그리고 Driver와 Executor에 대해서도 작성하겠습니다.
Driver
Driver는 Spark Application의 전체적인 실행 흐름을 제어하는 프로세스라고 할 수 있습니다.
예를 들어, 사용자가 SparkContext을 실행한다면 실제로 그 작업을 수행하기 위해 Spark Application 내 Job이 생성되게됩니다.
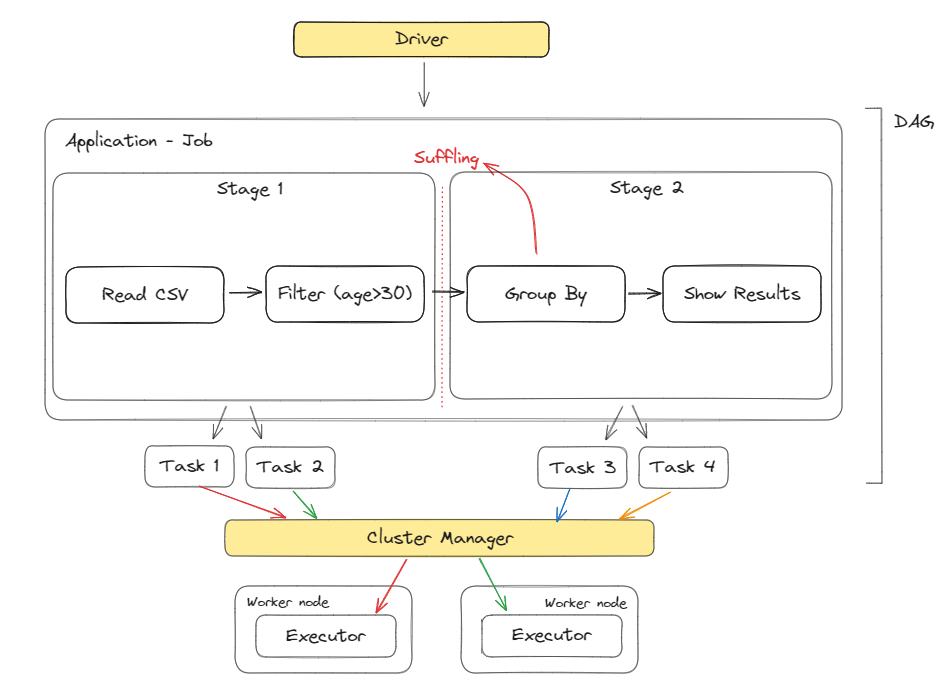
Driver는 이 Application의 Job을 Task로 쪼개 Executor에게 할당하는 역할을 수행하는 것입니다.Driver의 동작 방식을 간략하게 그려보았습니다.
- 코드를 기반으로 Spark Job 실행 계획(DAG)를 생성
- DAG를 Job → Stage → Task로 변환
- Cluster Manager(YARN/K8s)에게 Executor 요청
- Executor에게 Task를 배포
- Executor가 Task를 실행 후 결과 반환
- Driver가 최종 결과를 사용자에게 전달
또한, Driver가 로컬에서 실행되느냐, Cluster 내부에서 실행되느냐에 따라서
Client Mode / Cluster Mode로 나뉘게 됩니다.그런데 Cluster 내부에서 실행된다면 어디에서 실행이 되는 걸까요?
처음에 언급했던 그림에서 보면 Master Node에서 실행이 되는 것처럼 표기됐지만,
실제로 Driver는 Worker Node에서 실행이 됩니다.Cluster Manager가 Worker Node 중 하나를 지정하여 Driver를 실행하는 것이죠.
Executor
Executor는 Worker Node에서 실행되는 실제 연산을 수행하는 핵심 구성 요소입니다.
Task를 실행하고 데이터를 저장하는 Spark의 작업 단위로,
Task는 더이상 분리되지 않고 하나의 Executor에서 실행됩니다.또한, 하나의 Worker Node는 Executor를 여러개 보유할 수 있으며
하나의 Executor는 Task를 여러개 보유할 수 있습니다.Driver로부터 배포받은 Task를 수행하고 해당 결과를 Driver에 반환해주는 것이 주 역할입니다.
따라서 이를 종합해보면,
Spark의 Master Node는 Standalone 모드에서만 존재하기 때문에 보편적인 Cluster 구조 상에 존재하지 않는다는 점,
Master Node가 Driver Process를 실행하는 주체가 아니고
Driver는 로컬 혹은 Worker Node에서 실행된다는 점을 고려했을 때,
위 그림에서 표기된 Master Node가 아닌 Worker Node라고 보는게 올바르다고 생각합니다.
아래 그림이 더 정확한 표현이 되겠네요.
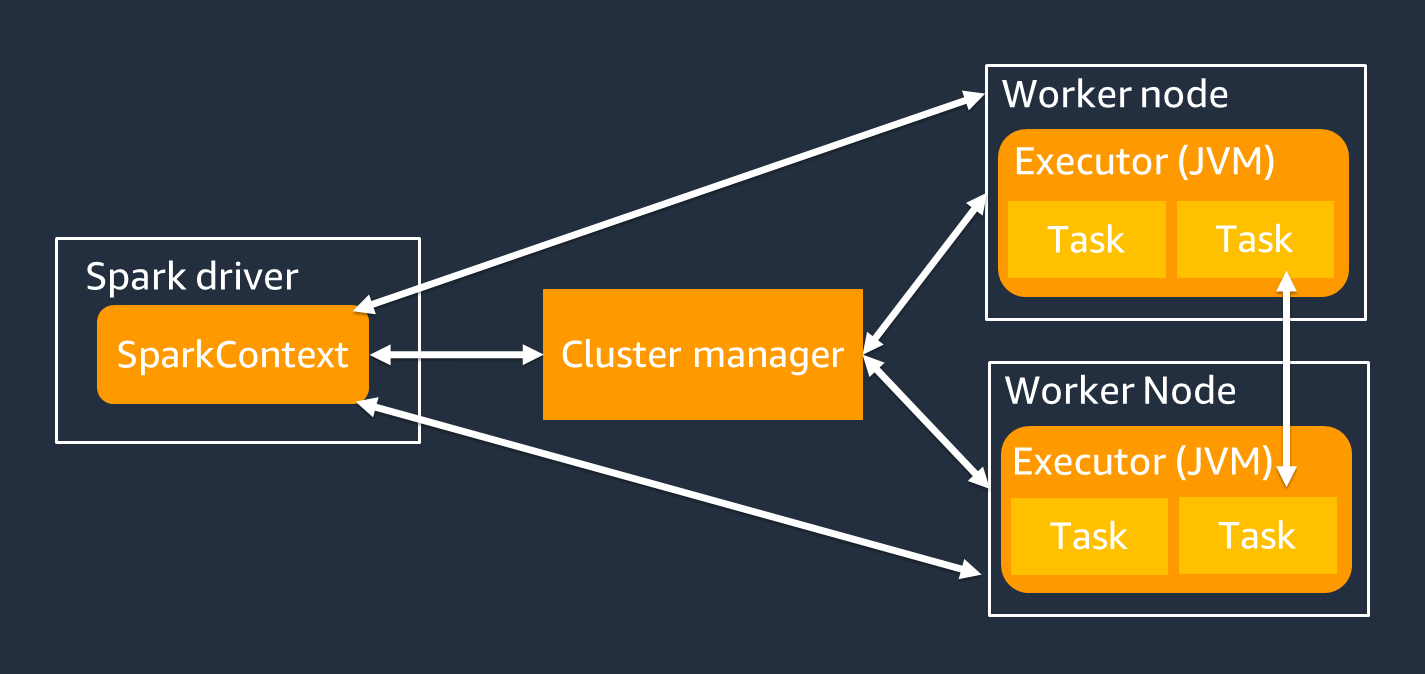
결론
-
Standalone(Cluster X) 모드의 경우, Master node가 Cluster Manager의 역할을 수행한다.
( 리소스 및 스케줄링 관리 ) -
Cluster(ex. K8s, Yarn) 모드의 경우, Cluster Manager가 있기 때문에 Master node는 존재하지 않는다.
-
Spark 실행(spark-submit)은 사용자가 직접 API를 통해서 실행하는 것이지,
Master node, Worker Node 내부에 접근해서 실행하는 것이 아니다. -
Driver 자체는 Worker Node 내부에서 실행된다.
📃 Spark Application 용어 정리
-
Application :
spark-submit으로 제출되는 전체 단위의 프로그램.
하나의 Driver와 여러 개의 Executor들이 하나의 Application에 속할 수 있습니다. -
Job :
Action 연산(ex: count(), save(), collect())이 호출될 때마다 하나씩 생성되는 실행 단위를 뜻합니다.
하나의 Application은 여러 개의 Job을 보유할 수 있습니다. -
Stage :
Job 내부에서 RDD lineage를 기준으로 나뉘는 작업 단위로 shuffling을 기준으로 분리됩니다.
하나의 Job은 여러 개의 Stage로 구성될 수 있습니다. -
Task :
Stage를 각 partition 단위로 나눈 실제 실행 단위 (가장 작은 작업)
Task는 더이상 나눌 수 없으며, 하나의 Executor는 여러 개의 Task를 보유할 수 있습니다.
이후 포스팅 -> Spark의 분산 처리 방식 1-2
Reference
