✏️ 오늘 학습한 내용
1. AWS CLI
2. Docker
3. ECS/ECR
4. Lambda
5. ApiGateway
6. CloudWatch
7. DevOps
8. MLOps
🔎 AWS CLI
AWS 웹 콘솔이 아닌 AWS CLI를 통해 콘솔 명령어를 사용하여 컨트롤을 해보도록 하겠습니다.
AWS CLI 란?
-
AWS 서비스를 관리하는 통합 도구
-
도구 하나로써 스크립트를 통해 자동화할 수 있는 기능을 제공
-
즉, 콘솔 명령어를 통해 컨트롤을 할 수 있는 명령 쉘 인터페이스
AWS CLI 설치
-
설치가 완료되면
aws --version을 통해 확인
AWS configure - CLI 설정
-
IAM에 들어가 사용자 생성
-
보안 자격 증명에서 액세스 키(CLI)를 발급 받고 csv파일 저장
-
커맨드 창에
aws configure입력 후 액세스 키의 내용 입력
- region name : ap-northeast-2 (서울 지역 이름)
- output format : json
-
사용자 계정에 S3에 접속할 수 있는 권한을 추가
ex) AmazonS3FullAccess -
aws s3 ls로 S3 리스트를 출력이 잘 되는지 확인 -
aws s3 mb s3://citron-profiles명령어로 버킷을 생성해주고 웹 콘솔을 통해 잘 생성이 되었는지 확인
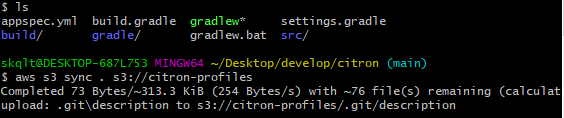
Sync 명령어
sync 명령어를 사용하면 local에 있는 파일을 S3에 손쉽게 업로드할 수 있습니다.
-
업로드 할 파일이 있는 경로에서 커맨드 창을 열기
-
aws s3 sync . s3://citron-profiles명령어로 위에서 생성한 버킷에 전부 업로드
-
aws s3 rm s3://citron-profiles --recursive명령어로 방금 버킷에 올린 파일을 전부 제거
🔎 Docker
📃 Docker가 나오게 된 계기

-
초기의 Traditional Deployment 방식 :
하드웨어, 운영체제 설치 후에 그 위에 어플리케이션을 개발하는 방식 -
가상화의 등장으로 인한 Virtualized Deployment 방식 :
한 대의 PC에 논리적으로 공간을 분리하여 여러 개의 서비스를 띄울 수 있도록 구성- Hypervisor : 하나의 OS에서 여러 개의 OS를 설치할 수 있고 여러 개의 어플리케이션을 별도의 공간에 선택해서 설치가 가능하게 해주는 환경
- Hypervisor의 경우, 사용하긴 했으나 너무 무거워 실제로 서비스를 하기에는 운용적인 측면에서 리스크가 존재했습니다.
-
Container Deployment 방식
Linux 내 Container를 제어하는 LXC 기술을 기반으로 한 Docker라는 기술 등장- Docker : Container 기반의 경량화된 이미지를 통해 서비스를 별도로 제공
ex) MSA와 같은 굉장히 복잡한 시스템들을 Docker 기반 하에 각각 가상화를 시켜 Container에 올려서 모니터링 및 관리를 편리하게 할 수 있습니다.
-
Kubernetes Deployment
-
Kubernetes : Docker가 굉장히 많은 Container를 띄울 수 있기에 복잡도가 높아지는데 이를 하나로 관리할 수 있는 기능
-
굉장히 많은 Container를 운용하고 있을 때, Kubernetes를 사용하는 것이 용이
-
📃 Docker란?
AWS에서의 Docker란, 환경에 구애받지 않고 애플리케이션을 신속하게 구축, 배포 및 확장을 할 수 있게 해주는 소프트웨어 플랫폼입니다.
jar파일을 만들어 배포를 한다고 했을 때, 하나의 코드로 작성을 해도 환경에 dependency한 부분들이 많습니다.
예를 들어, 윈도우에서 작성하고 리눅스에서 배포한다고하면, 배포될 때마다 여러가지 설치되어있는 환경이나 다른 옵션들 때문에 정상 작동을 하지 않을 때가 많습니다.
그렇기에, 코드만 가지고 배포하는 것이 아니라 가상화된 독립된 환경까지 배포하는 것이 Docker의 주 기능입니다.
📃 Docker의 장점
-
더 많은 소프트웨어를 빠르게 제공
-
운영 표준화
작은 컨테이너식 애플리케이션을 사용함으로써 손쉽게 배포하고 문제를 파악하여 롤백할 수 있습니다. -
원활한 이전
-
비용 절감
📃 Docker image

-
Docker를 운용하기 위해선 Docker File을 작성합니다.
-
작성한 파일을 빌드해서 이미지화시킵니다.
-
이 이미지를 기반으로해서 Container를 생성합니다.
-
이미지(Image)
이미지는 컨테이너를 생성할 때 필요한 요소로
컨테이너의 목적에 맞는 바이너리와 의존성이 설치되어 있습니다.여러 개의 계층으로 된 바이너리 파일로 존재합니다.
-
컨테이너(Container)
호스트와 다른 컨테이너로부터 격리된 시스템 자원과 네트워크를 사용하는 프로세스
이미지는 읽기 전용으로 사용하여 변경사항을 컨테이너 계층에 저장합니다.
=> 컨테이너에서 무엇을 하든 이미지에는 영향을 주지 않습니다.
📃 Docker LIFE CYCLE
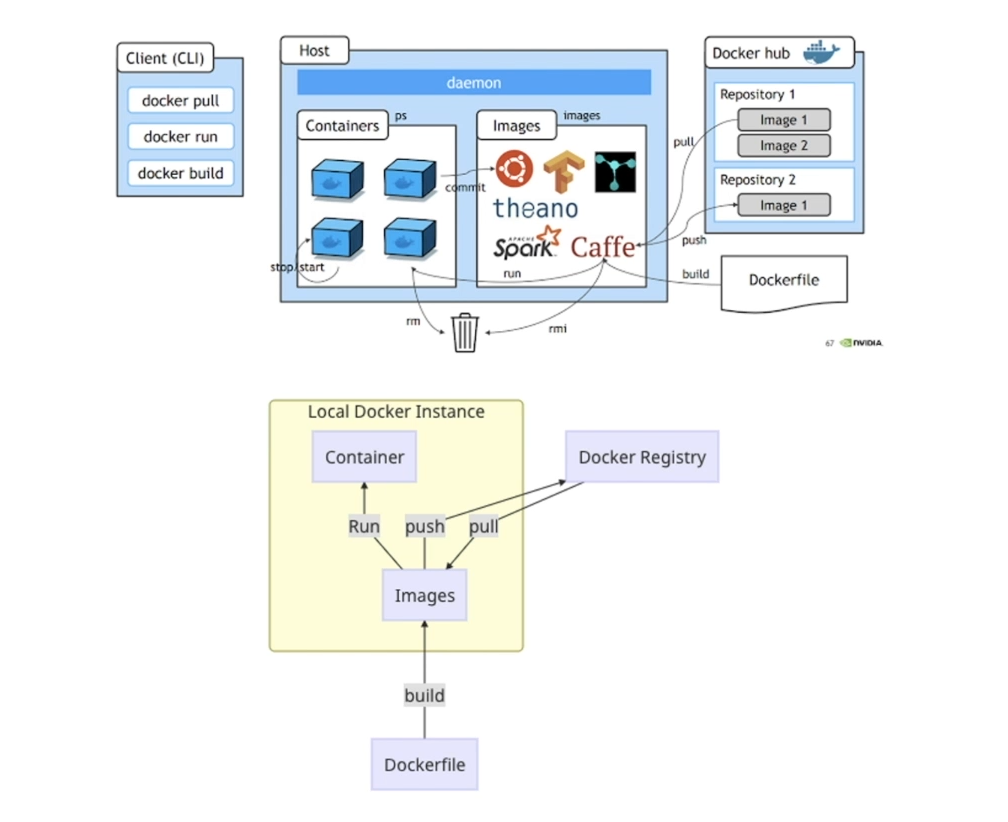
- Dockerfile을 빌드하여 이미지를 생성하거나 혹은 Docker hub에서 이미지를 가져올 수 있습니다.
docker buildordocker pull- 이 이미지를 컨테이너화해서 서비스할 수 있도록 구성합니다.
docker run- 만든 이미지를 Docker Registry (Docker hub)에 업로드할 수도 있습니다.
docker pullHost : 로컬 혹은 실제 운용하는 서버
Docker hub : Docker의 Github역할
📃 Docker Network
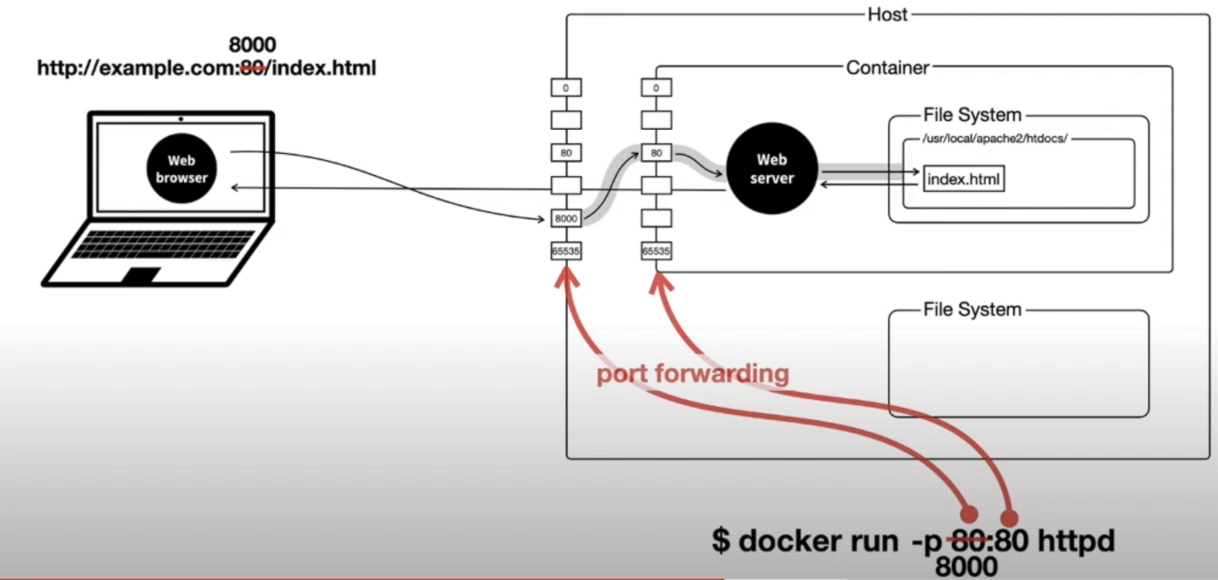
Host라는 물리적인 서버 내에서 Container를 생성했다고 했을 때,
이 Host와 Container는 네트워크 상 별도의 포트로 연동할 수 있어야합니다.Docker를 실행시킬 때, 아래 명령어를 사용하여 포트를 서로 매핑해줍니다. (port forwarding)
docker run -p 8000:80 httpd최종적으로 Host의 포트로 Client가 접속할 수 있게됩니다.
ex) http://example.com:8000/index.html
📃 Docker 주요 명령어
- container 생성 및 실행 관련 명령어
- container 생성 및 실행 : run
- container 중지 : stop
- container 실행 : start
- container 재실행 : restart
- container 관리 관련 명령어
- container 확인 : ps
- container 삭제 : rm
- container 실행 관리 관련 명령어
- container log 확인 : logs
- container에 명령어 수행 : exec
- image 관리 관련 명령어
- image 확인 : images
- image 삭제 : rmi
- image 내려받기 : pull
- image 업로드 : push
- image 태그 지정 : tag
📃 Dockerfile

Java 예시
FROM openjdk:8-jdk-alpine ARG JAR_FILE=build/libs/*.jar COPY ${JAR_FILE} demo-0.0.1-SNAPSHOT.jar ENTRYPOINT ["java","-jar","/demo-0.0.1-SNAPSHOT.jar"]FROM : jdk 8버전을 선택
ARG JAR_FILE : 파일을 내부적으로 지정
COPY : 지정한 파일을 카피
ENTRYPOINT : 카피한 파일을 실행하도록 지정
📃 Docker-compose

도커가 여러 개 있으면 일일히 띄우기가 복잡합니다.
이때, Docker-compose를 이용하면 여러 도커를 쉽게 관리할 수 있습니다.
Docker를 개별로 사용하는 예시
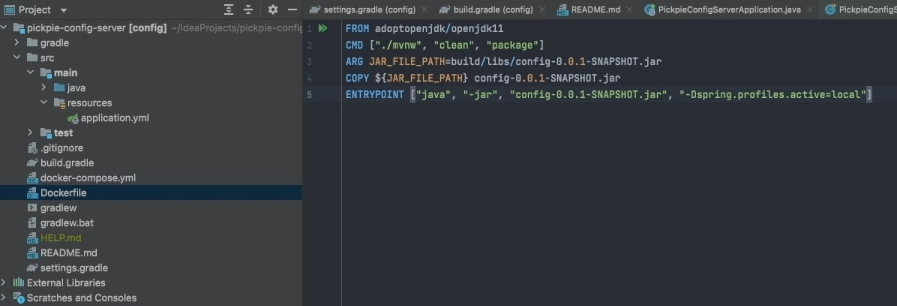
pickle-config-server라는 프로젝트를 Docker로 실행해보도록 하겠습니다.
docker build -t 이미지이름 dockerfile경로
tag 옵션을 통해 이미지의 이름을 pip-config-server:0.0.1라고 지정하겠습니다.
또한, 명령어 마지막에.을 넣어 dockerfile이 있는 위치를 root로 설정하겠습니다.
docker build -t pip-config-server:0.0.1 .만든 이미지를
-d옵션을 사용해 백그라운드에서 실행시켜보겠습니다.
docker run -d pip-config-server:0.0.1마지막으로,
docker ps명령어를 통해 실행이 되었는지 프로세스를 확인해보면 됩니다.
Docker-compose를 사용하는 예시
Docker-compose를 사용해 docker 여러 개를 운용해보겠습니다.
docker-compose.yml예시
version: '3'
services:
db: # 서비스 이름을 DB로 지정, DB를 사용할 목적으로 생성
image: mysql # DB로 쓸 mysql을 이미지로 불러옴
ports:
- "3306:3386" # 3306에서 3386으로 포트포워딩
restart: always
environment:
MYSQL_HOST: PICKPIE
MYSQL_PASSWORD: PICKPIE1234!!
MYSQL_DB: PICKPIE
MYSQL_ROOT_PASSWORD: PICKPIE1234!!
configserver: # 서비스 이름을 configserver로 지정, 여러 개의 docker를 실행하기 위한 목적
depends_on: # 서비스가 시작되고 중지되어야하는 순서를 설정
- rabbitmq
build:
dockerfile: Dockerfile
context: .
environment:
# name=value
- SPRING-PROFILES_ACTIVE=local
- spring.rabbitmq.host=rabbitmq
ports:
- "8888:8888"
restart : always
networks:
- pip-network # 동일한 네트워크 사용
rabbitmq:
image: rabbitmq:latest # dockerhub에 있는 rabbitmq라는 이미지의 최신버젼을 받아옴
ports:
- "15671:15671"
- "15672:15672"
- "5672:5672"
- "5671:5671"
environment:
- RABBITMQ_DEFAULT_USER=guest
- RABBITMQ_DEFAULT_PASS=guest
restart: always
networks:
- pip-network # 동일한 네트워크 사용
zipkin:
image: openzipkin/zipkin # 이것도 이미지를 가져와 사용
ports:
- "9411:9411"
restart: always
networks:
- pip-network # 동일한 네트워크 사용
values:
db: {}
networks:
pip-network: # 서비스 내의 인스턴스는 모두 같은 네트워크에 있어야 상호 간의 통신이 가능
driver: bridge위와 같이
docker-compose.yml파일을 만들어주고
단순히docker-compose up -d명령만 입력해주면
한번에 여러 docker가 생성이 됩니다.
docker ps로 확인
🔎 ECS/ECR
Amazon Elastic Container Registry (ECR)
-
Docker의 이미지를 저장할 수 있는 AWS 내의 서비스
-
기존에 dockerhub를 이용했다면 AWS에서는 ECR을 이용하여 private하게 이미지를 저장하고 관리할 수 있습니다.
Amazon Elastic Container Service (ECS)
- ECR에 저장된 이미지 기반으로 가상화된 서비스를 제공하는 것
📕 ECR
Docker 이미지를 ECR로 옮기는 작업을 수행해보겠습니다.
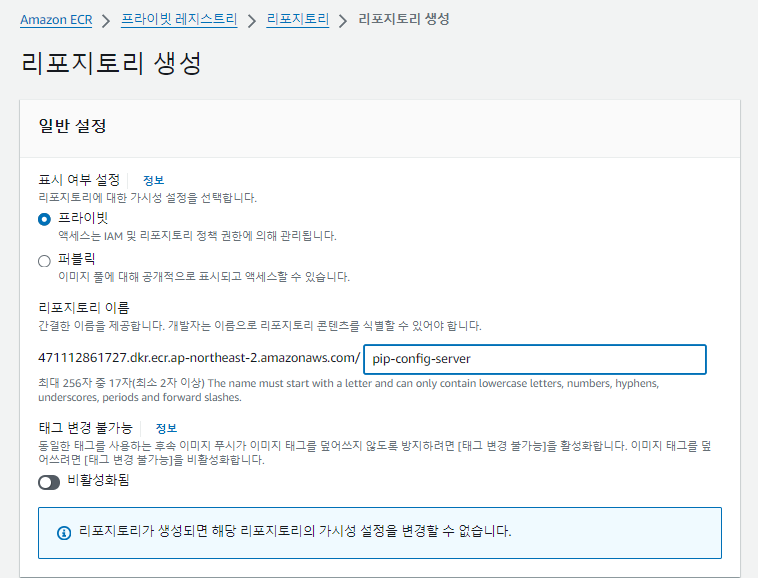
ECR 생성
AWS에서 ECS에 접근 후에, Amazon ECR로 접근할 수 있습니다.
AWS CLI를 통해 업로드
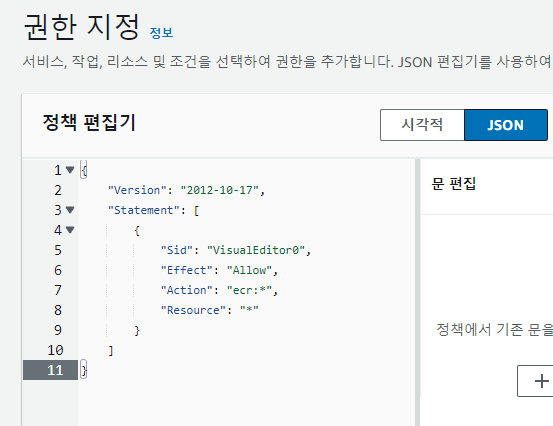
먼저, IAM에서 사용자 계정에 ECR에 접근할 수 있는 권한을 주도록 하겠습니다.
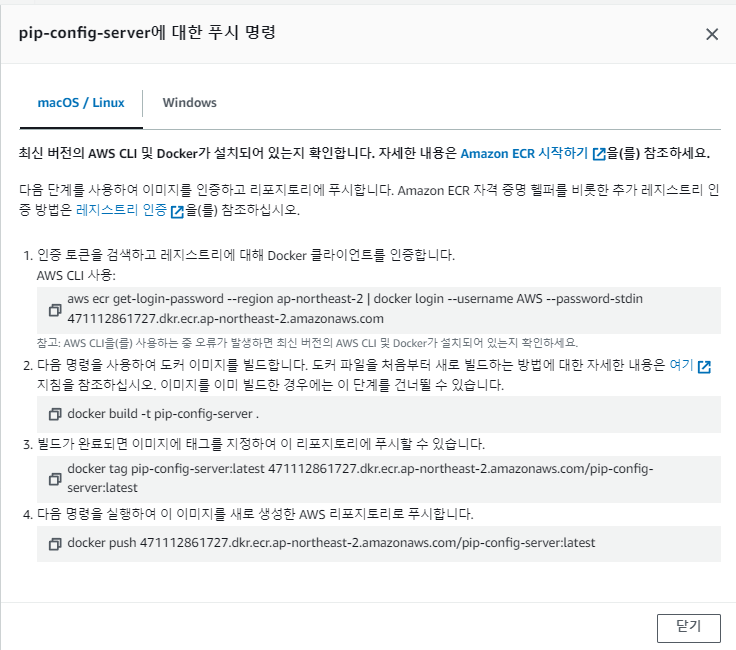
AWS의 푸시 명령을 따라서 AWS CLI를 사용해보겠습니다.
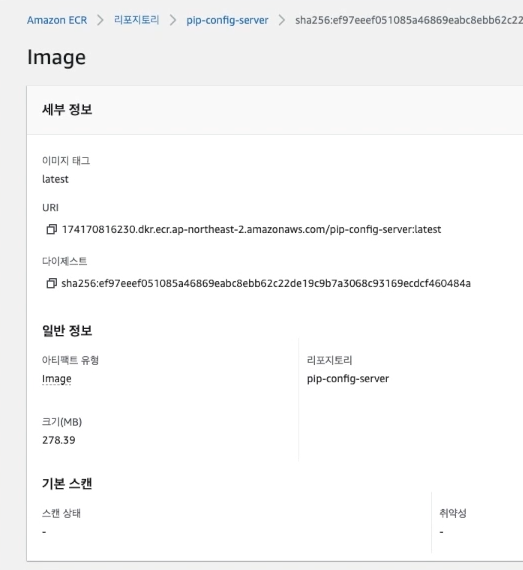
기존의 Docker프로젝트에 푸시 명령어를 사용하여 이미지를 업로드하였습니다.
📕 ECS
위에서 업로드한 이미지를 통해서 별도의 EC2 인스턴스를 만들 수 있고, EC2에서 Docker를 설치하는 방법도 있으며, Elastic beanstalk을 만들 때 아예 Docker Container를 만들어 운용하는 방법도 있습니다.
그러나, 이러한 방법들은 별도의 서비스가 하나 더 사용되기 때문에 비용적인 측면에선 불리할 수 있습니다.
그렇기에, 별도의 서버 없이 이미지만 가지고 운용할 수 있게 하는 것이 바로 ECS 서비스입니다.
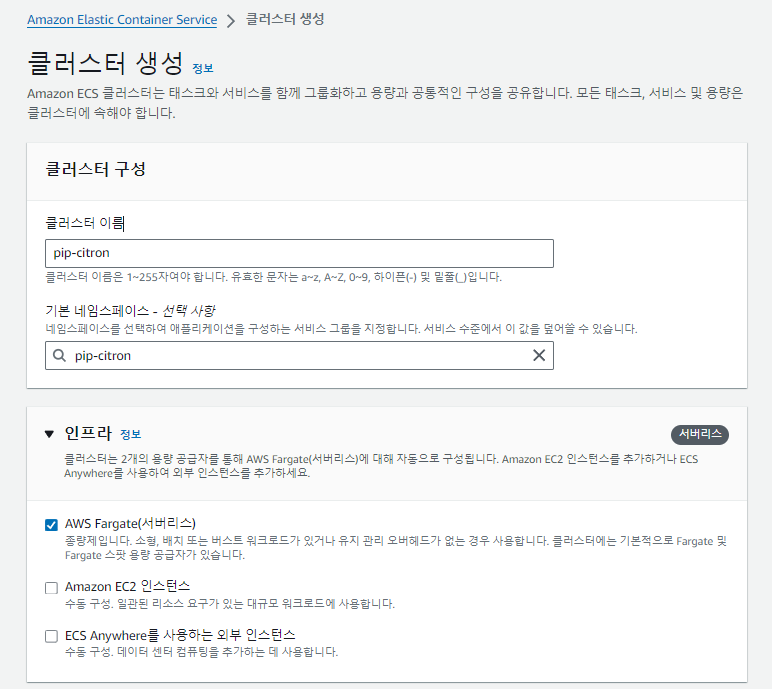
ECS 클러스터 생성
클러스터를 생성할 때, AWS Forgate를 선택해 서버리스로 인프라를 구축합니다.
테스크 정의
클러스터를 사용하기 위해선 테스크를 정의해줘야합니다.
(테스크 정의 -> 테스크 정의 생성)
컨테이너 이름 : 사용자 지정
이미지 URL : 위에서 생성한 ECR 내부의 이미지 URL

테스크 등록
생성한 클러스터로 돌아가 테스크를 생성 및 등록을 해줍니다.

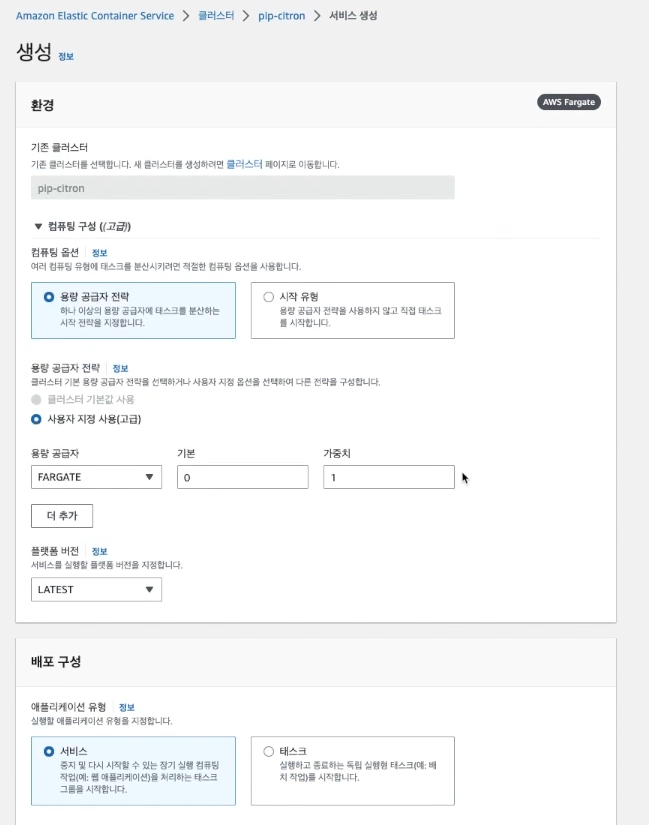
서비스 생성
테스크를 등록한 후에 서비스도 생성해주어야 힙니다.
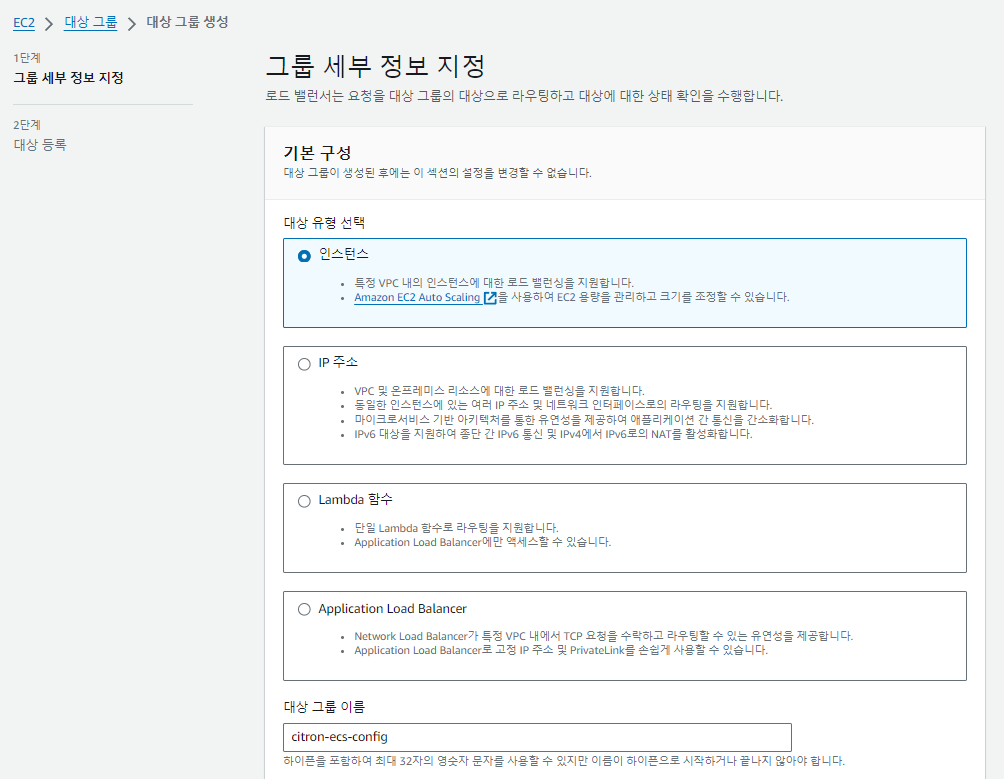
ELB 생성
만든 서비스에 접속하려면 별도의 ELB(로드밸런싱)를 구성해야합니다.
대상 그룹 생성
로드 밸런서 생성

ECS 서비스 동작 완료
위와 같은 과정을 통해,
앞단의 도메인이 ELB를 통해서 ECS 서비스에 연결하도록 만들어 서비스가 동작할 수 있도록 만들어보았습니다.
추가적으로,
ECS를 사용한다면 별도의 EC2나 Elastic Beanstalk없이 Docker로 그 과정을 간단하게 구성할 수 있습니다.CI/CD도 ECR에 배포하게되면 바로 연계해서 서비스까지 적용할 수 있도록 구성할 수 있습니다.
🔎 Lambda
서버리스의 대표적인 서비스로,
서버 없이 단순히 소스코드의 함수만으로 서비스를 제공할 수 있게 해주는 컴퓨팅 서비스입니다.
Lambda 생성
- 소스 코드
import json import boto3 from datetime import datetime client = boto3.client('s3') # boto3를 통해 s3에 대해 읽어옴 def lambda_handler(event, context): what_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] try: response = client.get_object(Bucket=bucket, Key=key) text = response['Body'].read().decode() data = json.loads(text) # 온도가 40이 넘으면 뜨겁고, 넘지않으면 좋다. if data['temperature'] > 40: print(f"Temperature detected : {data['temperature']}C at {what_time}") print("Be careful! It's getting really hot!!") else: print("So far so good") except Exception as e: print(e) raise e소스 코드를 입력 후 Deploy를 눌러 반영합니다.

📃 Lambda 트리거
Lambda는 보통 어떤 이벤트가 일어났을 때,
특정 프로그램 실행시키고 싶을 경우 사용합니다.
이와 같이, 특정 이벤트의 발생 맞추어 특정 람다에 등록되어 있는 함수를 시키려는 경우 트리거를 사용합니다.
S3 구성
S3에서 이벤트가 발생했을 때 위에서 추가한 소스코드가 동작할 수 있도록 만들어보겠습니다.
-
이벤트 알림 생성
먼저, 이전에 만들어 두었던 S3 버킷인 citron-profiles에 전송(put)이 들어왔을 때, 이벤트 알림이 발생하도록 설정을 해주겠습니다.

- 전송 : ✅
- lambda 함수 : 방금 만든 함수 등록
-
권한 설정
퍼블릭 액세스 차단을 비활성화해주고,
버킷 정책을 생성하여 S3 접근 권한을 할당해줍니다.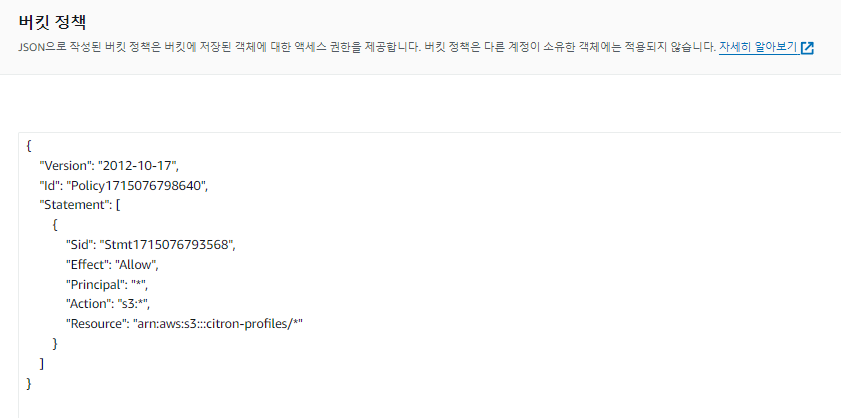
-
업로드
그리고, 내부에 temperature을 가리킬 json파일을 업로드하겠습니다.
{ "temperature": 45 }
-
트리거 확인
Lambda 함수에 S3 이벤트에 대한 트리거가 추가된 것을 확인할 수 있습니다.
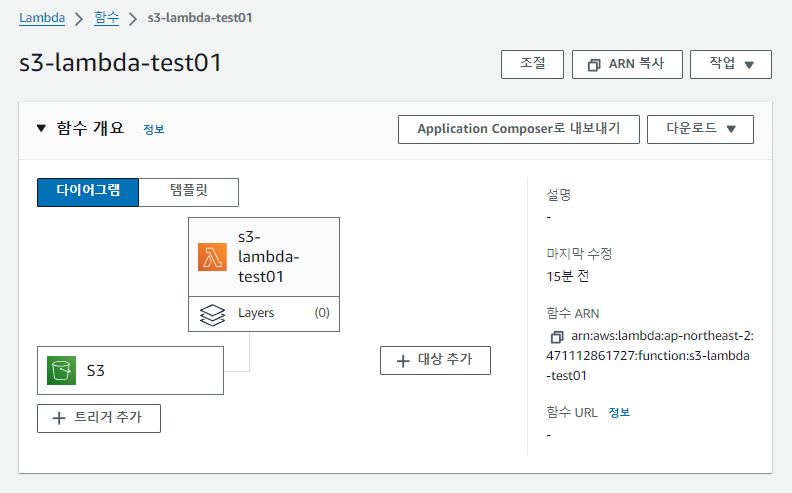
-
로그 확인
함수가 정상적으로 작동하고 있는 지 CloudWatch를 통해 로그를 확인해보겠습니다.
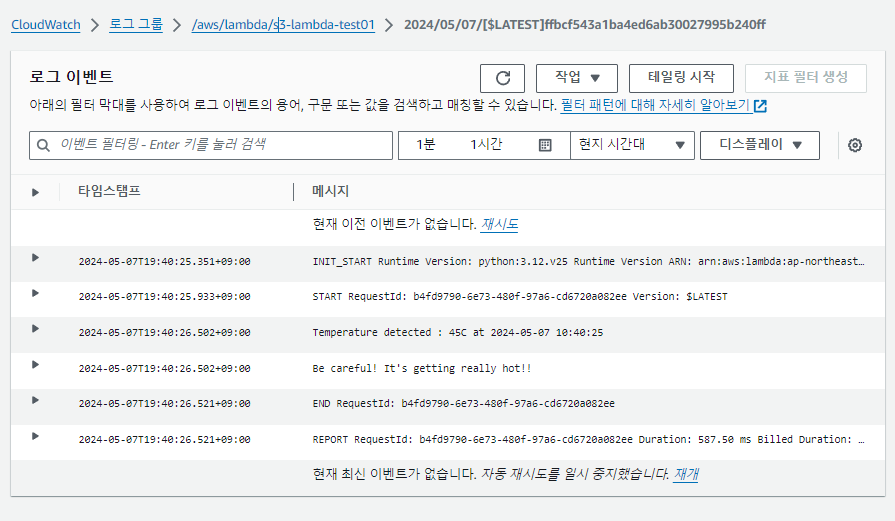
Temperature가 45이기에 really hot 문구를 보아 정상 작동하고 있음을 확인할 수 있습니다.
🔎 ApiGateway
게이트웨이를 역할을 할 수 있는 서버리스 서비스
일반적으로 백엔드 서버라고 하면 Rest API를 많이 사용하는데,
Api Gateway를 사용하면 이러한 API들을 별도의 서버 구성 없이 간단한 코드를 통해서 게이트웨이를 구성할 수 있습니다.=> 규모와 상관없이 API를 생성 유지, 관리 및 보호
- 게이트웨이(Gateway) : 한 네트워크에서 다른 네트워크로 이동하기 위해 거쳐야 하는 지점
( 네트워크 간 프로토콜이 다른 경우 중재 역할 )
ApiGateway 생성
-
API 생성
ApiGateway 내에서 REST API를 하나 생성해보겠습니다.
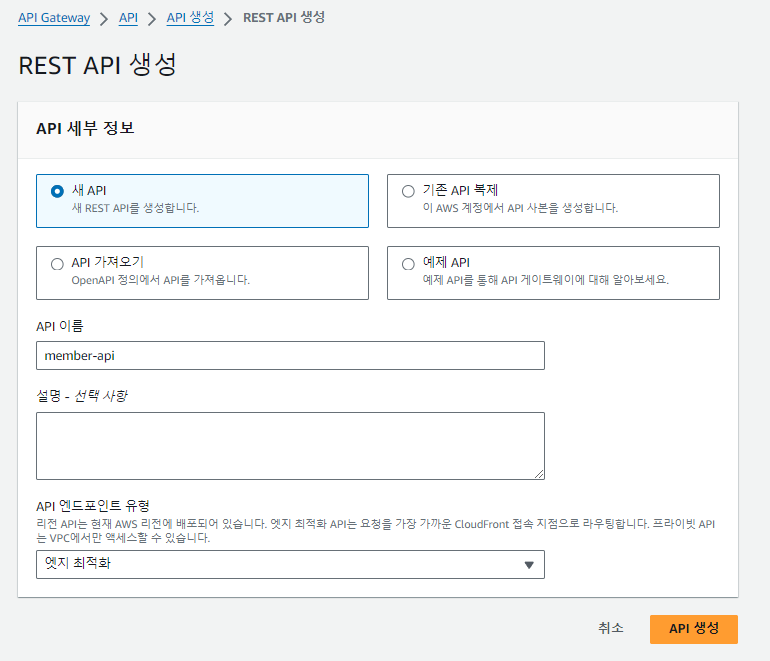
-
리소스 생성
members라는 리소스를 하나 생성해주겠습니다.

-
메서드 생성
members 리소스를 기반으로 회원가입 할 수 있는 메서드 POST를 만들어주겠습니다.
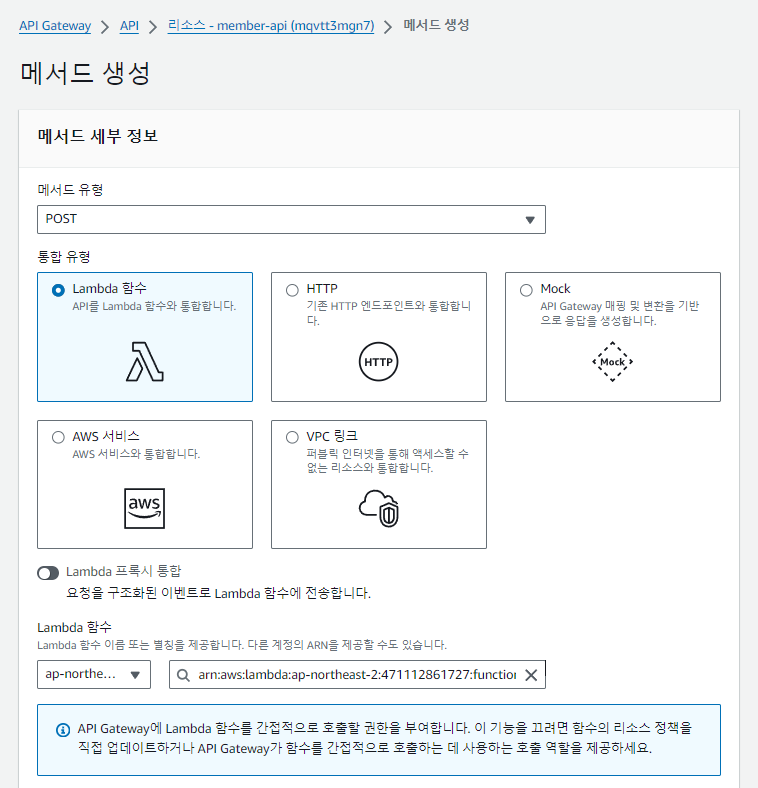
- Lambda 생성
메서드를 생성하기 전에, 메서드를 트리거 삼을 Lambda를 하나 생성해주겠습니다.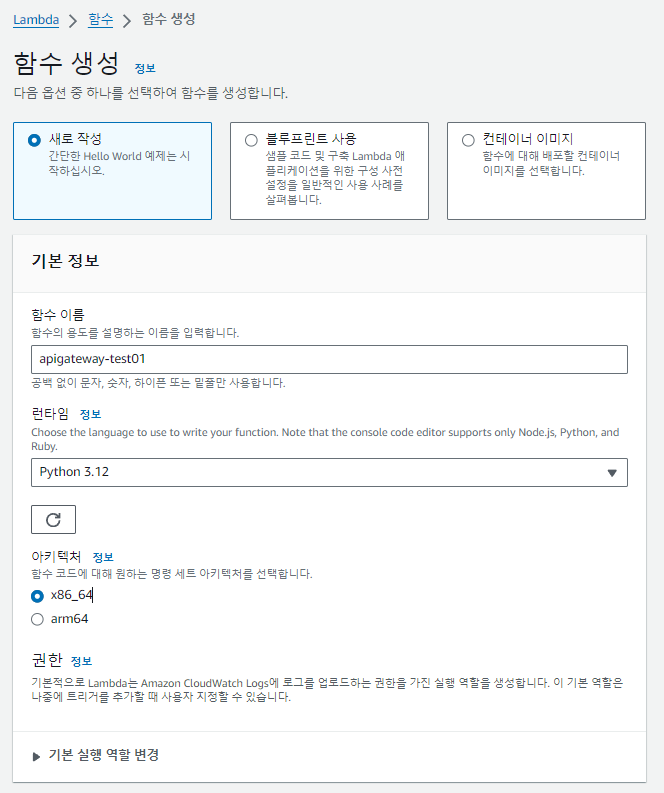
이런 식으로 별도의 서버 구축 없이 API 서버를 구성할 수 있는 서비스가 apigateway입니다.
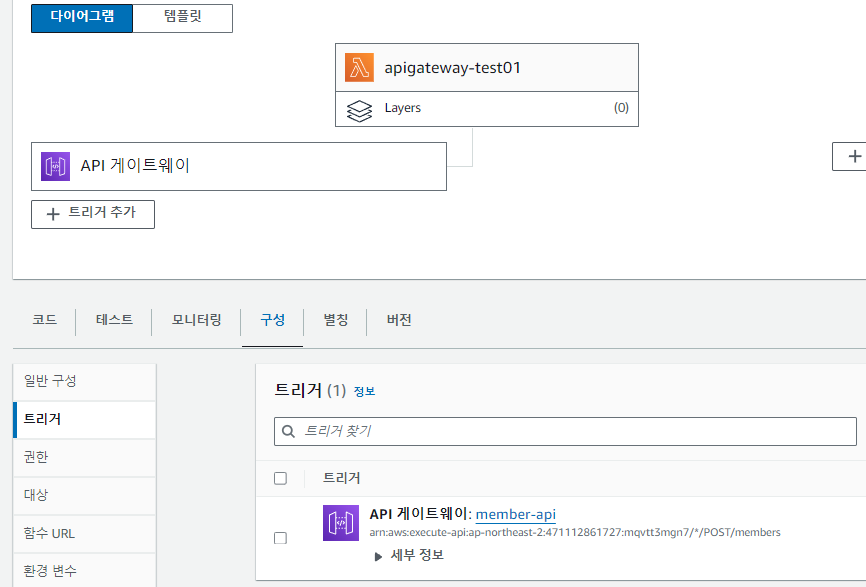
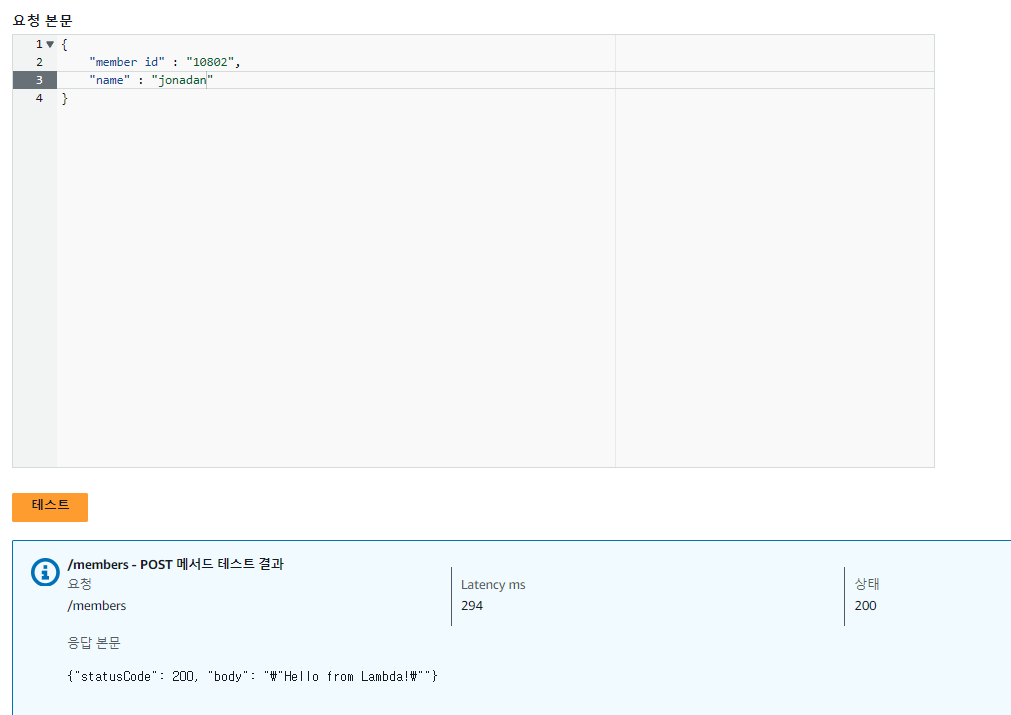
- Lambda 생성
🔎 CloudWatch
애플리케이션을 모니터링하고, 어떤 성능에 대해서 대응을 하며, 리소스 사용률을 모니터링해서 최적화할 수 있는 도구
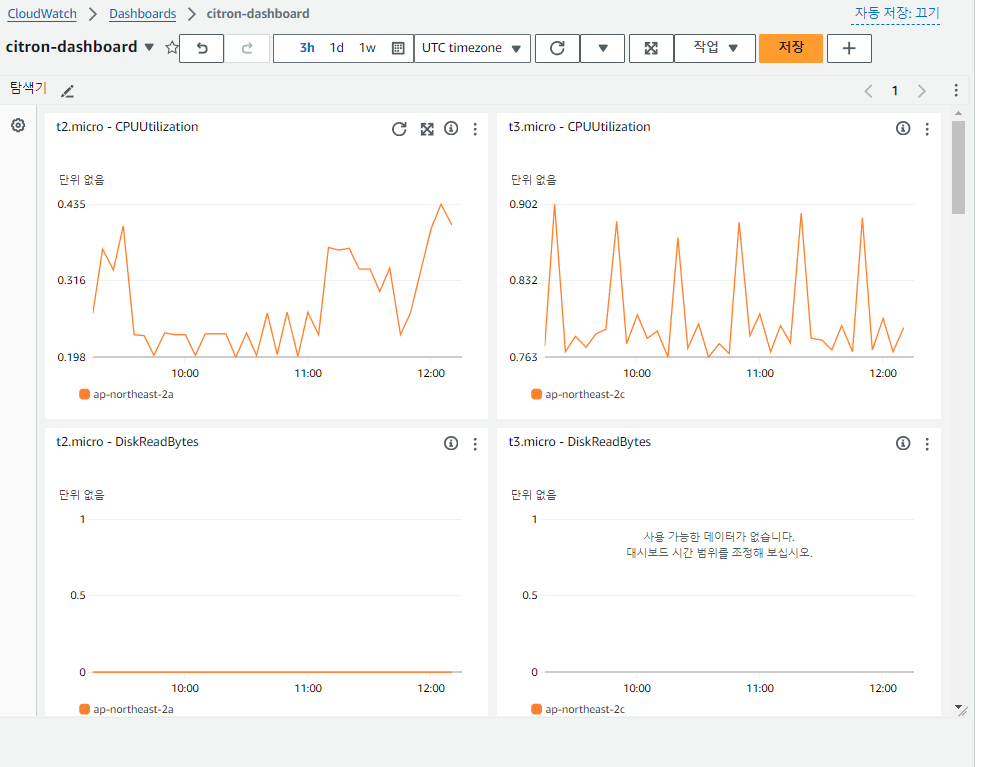
CloudWatch 대시보드 생성
이런 식의 가시화가 가능합니다.
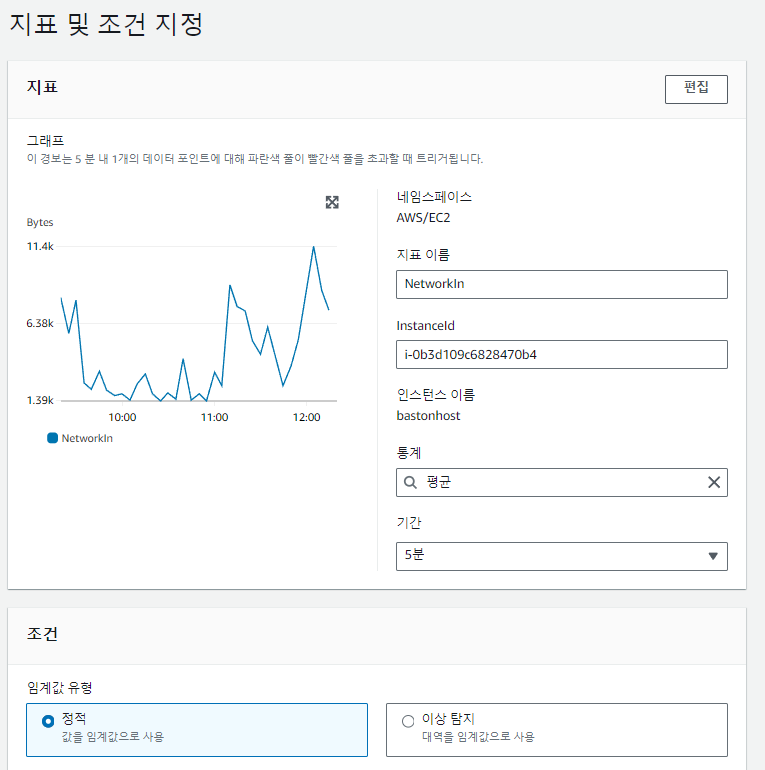
경보 생성
특정 임계치에 도달 했을 때, 알림을 제공하는 기능도 설정할 수 있습니다.
ex) 경보 생성 -> EC2 -> 인스턴스 -> NetworkIn 지표 선택
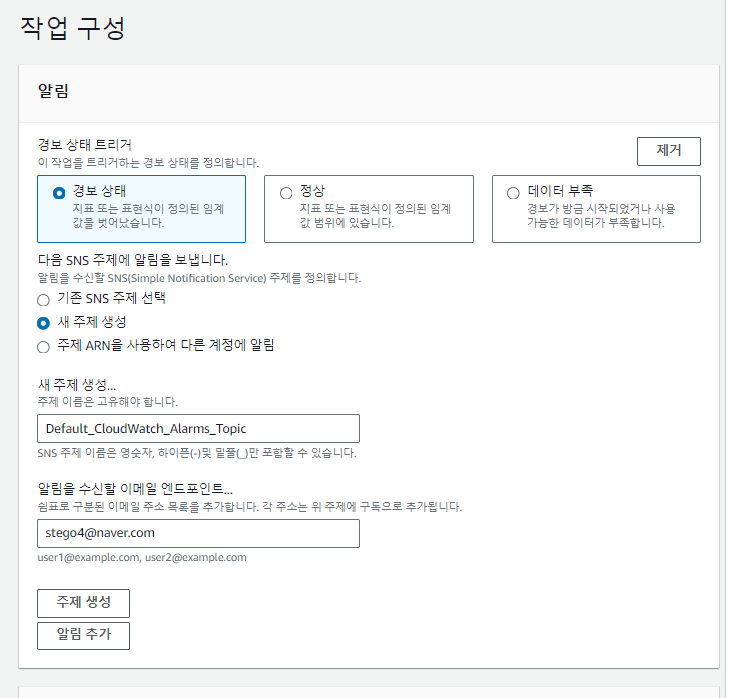
임계치를 500이라 하고 이메일로 알림이 오도록 작업 구성을 해보겠습니다.
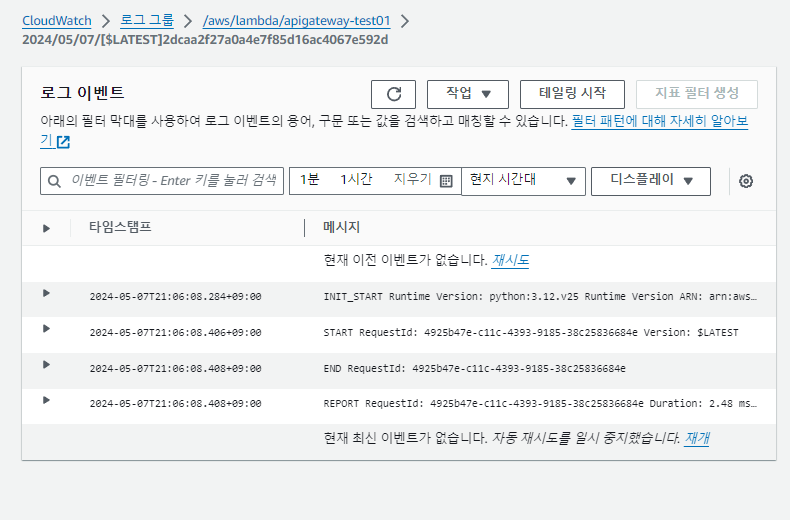
로그 그룹
AWS 내의 모든 로그가 이곳에 남습니다.
리소스 상태
CloudWatch의 EC2 리소스 상태란에서 CPU, 메모리와 같은 리소스의 상태를 대쉬보드 혹은 EC2에서 확인할 수 있게 해줍니다.

🔎 Devops
Devops는 소프트웨어의 개발과 운영의 합성어로서, 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 뜻합니다.
📃 Devops가 나오게 된 계기
AWS와 같은 클라우드 서비스들이 확장되면서 애자일 개발 방법론과 같이 함께 빠른 주기로 협업하면서 배포하고 출시하는 문화가 만들어지게 되면서 Devops라는 용어가 나타났습니다.
기존에는 개발자가 따로 있고 시스템 운영자가 따로 있었지만, 이제는 개발자들이 인프라도 운영하고 클라우드도 운영하는 업무를 많이 지향하고 있습니다.
이런 환경과 문화, 개발 방법론이 급 부상하기 시작해서 지금은 Devops 엔지니어가 별도의 직무로 있을 정도로 중요한 파트가 되었습니다.
📃 DevOps의 개념
-
문화 : 사람 (팀, 인원, 가치, 의사소통)
DevOps를 통해 하나의 문화를 만들어 나갑니다. -
자동화 : 일 (프로세스, 방법론)
자동화를 통해 효울성과 빠른 속도를 지향합니다.
-
측정 : 서비스 (서비스의 가치, 성격)
지표를 측정하여 지속적으로 개선해 나갑니다. -
공유 : 자원 (H/W, S/W, 기술, 도구)
공유를 통해 함꼐 발전해 나갑니다. -
축적 : 시간 (일정, 변경 가능성, 회복탄력성, 예측)
기록을 축적하여 자산을 만들어 나갑니다.
Devops는 굉장히 광범위한 의미를 가지고 있습니다. 개발 조직의 핵심 코어가 될 수 있는 직무일 수도 개발 방법론일 수도 있습니다. 약간 추상적이면서도 중심이 되는 그런 역할이 바로 Devops입니다.
📃 DevOps 엔지니어의 역할
DevOps 엔지니어란?
DevOps 문화를 위해서 자동화하고, 기술적 문제를 기술적으로 예방하고 해소시키는 사람
Soft skill
사회 기술, 의사소통 기술, 성격 또는 성격 특성, 태도, 직업 속성 등 사람들이 환경을 탐색하고 다른 사람들과 잘 일하는 능력을 이야기합니다.
Technical skill
기술적 스킬은 특정한 일을 효과적으로 수행하는 지식과 능력을 이야기합니다.
IT 영역에서는 프로그래밍 언어 작성 능력, SW 디자인, 데이터베이스 및 서버 관리 등 특정한 기술의 지식과 수행 능력이 있겠습니다.
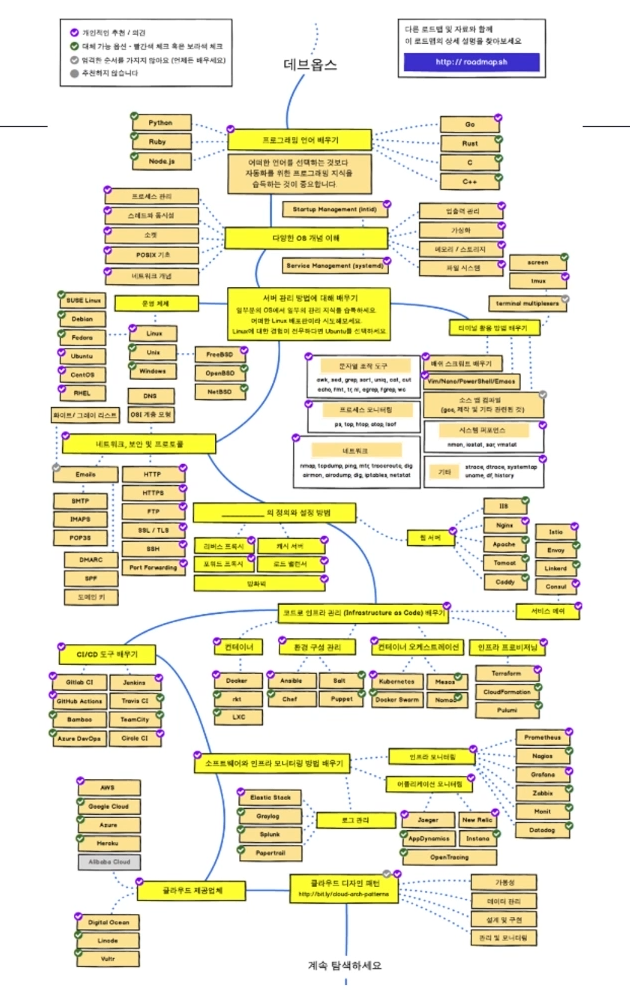
DevOps 엔지니어 로드맵
🔎 MLOps
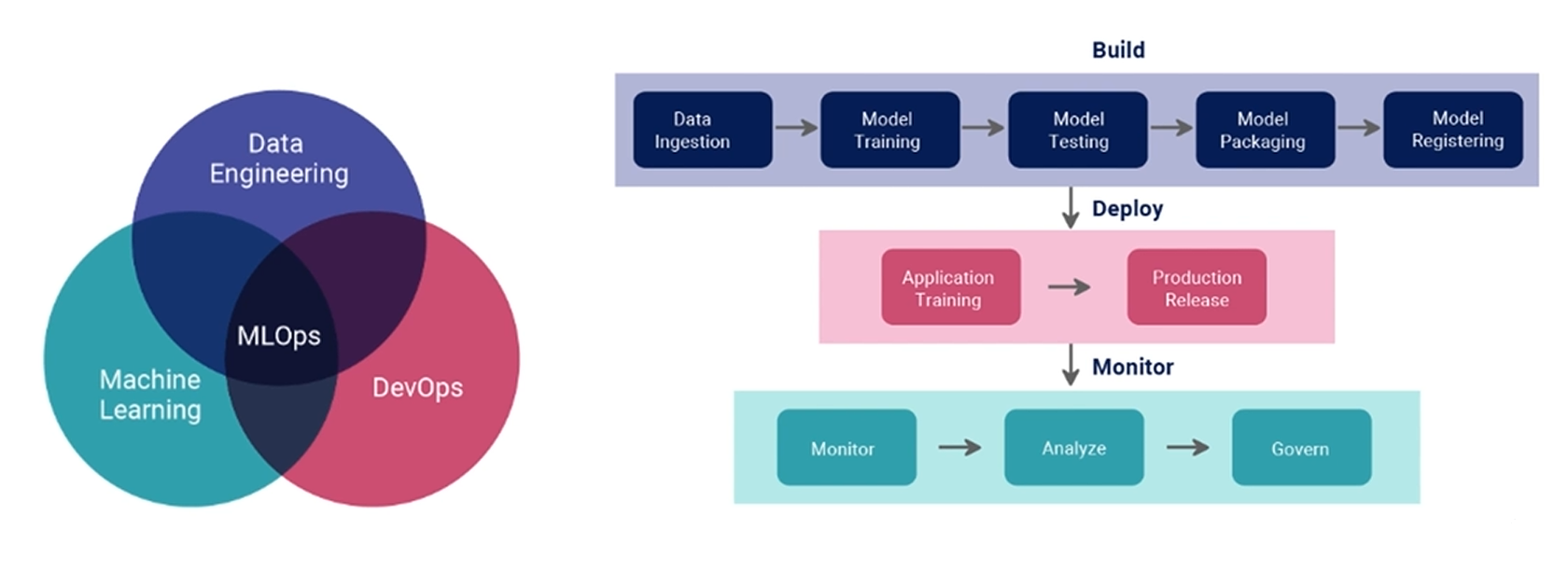 DevOps와 DataEngineering이 연결된 MLOps라는 역할이 두각이 되고 있습니다. 빅데이터를 사용하는 기업에서는 MLOps를 통해서 자동화되는 파이프라인을 구성하는 역할도 진행하고 있습니다.
DevOps와 DataEngineering이 연결된 MLOps라는 역할이 두각이 되고 있습니다. 빅데이터를 사용하는 기업에서는 MLOps를 통해서 자동화되는 파이프라인을 구성하는 역할도 진행하고 있습니다.
📃 AWS Datapipeline
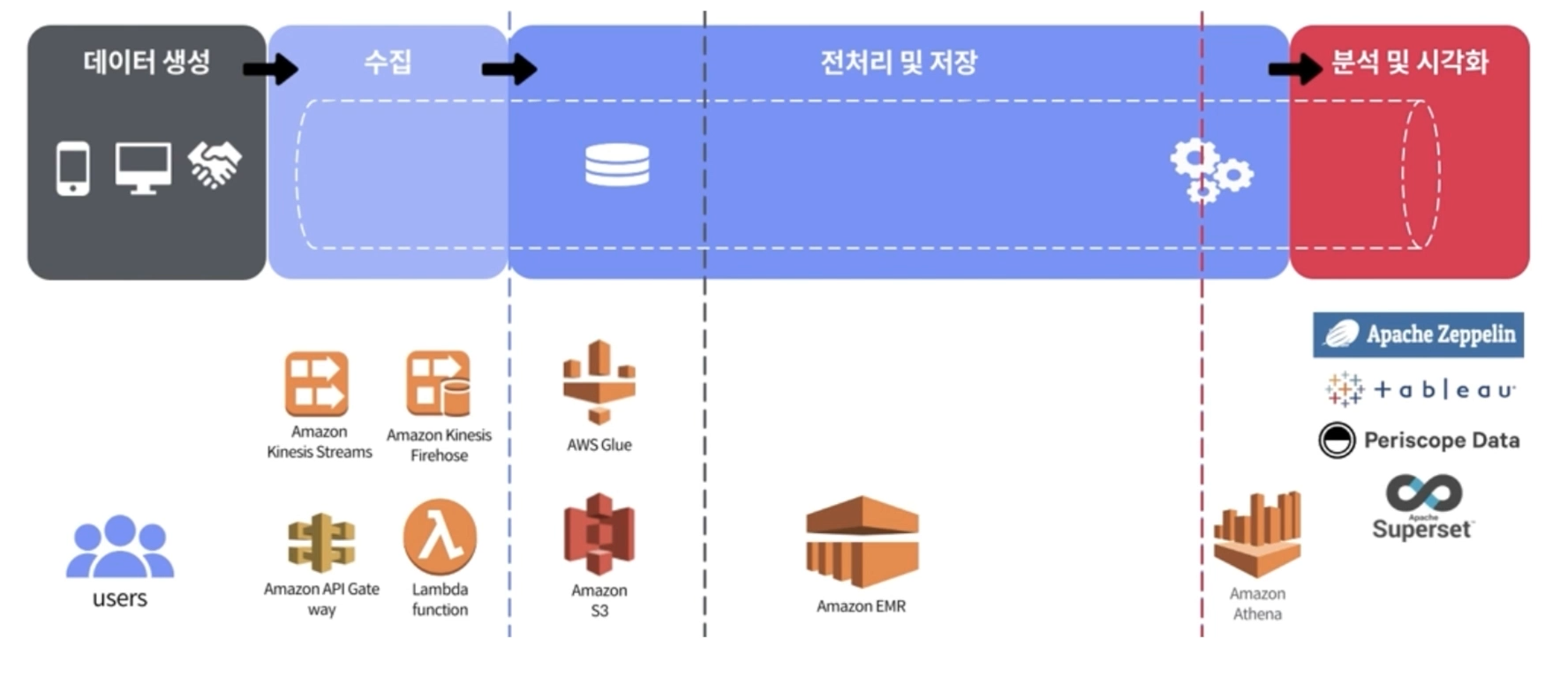
데이터 수집
-
실시간 데이터 수집 : Kinesis
-
배치성 데이터 수집 : API Gateway, Lambda
데이터 전처리 및 저장
-
Amazon S3 : 데이터 저장, 주로 데이터 레이크 용도 (초기 적재)
S3의 경우, 3단계의 flow로 사용될 수 있습니다. 원초적인 데이터를 저장하는 초기단계, 전처리 후에 저장하는 중간단계, 최종적으로 저장하는 마지막단계
-
AWS Glue : 메타 데이터 저장
-
Amazon EMR : AWS의 대용량 데이터 적재 담당
-
AWS Redshift : RDS 성격의 Column베이스로 제공하는 서비스, 비용이 높으나 접근성이 높음
데이터 분석 및 시각화
Tableau, Apache Zeppeline와 같은 여러가지 분석 및 시각화 툴을 사용
보다 구체화된 예시
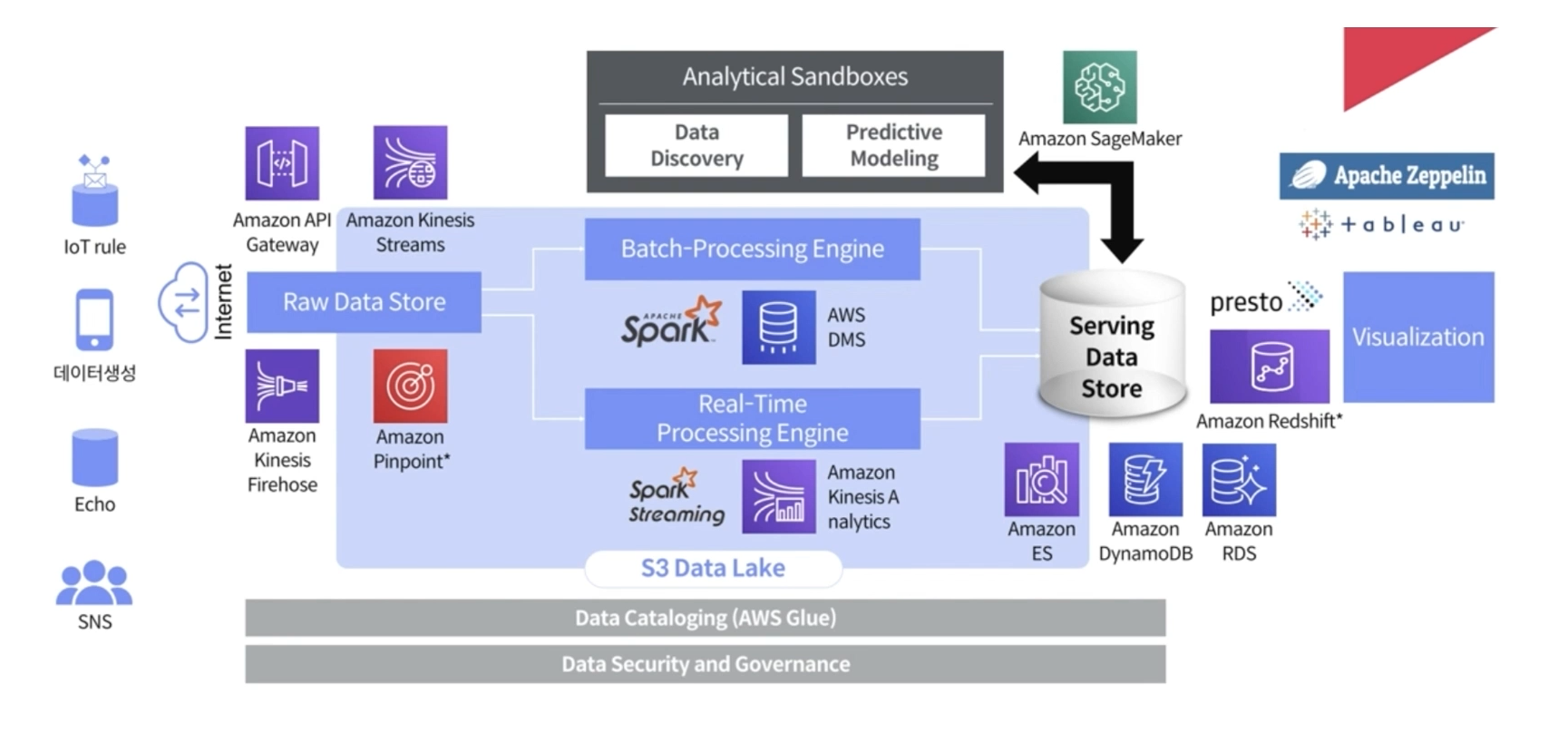
비정형 데이터(Raw Data)가 들어오면,
실시간 데이터는 Kinesis, Batch성 데이터는 ApiGateway를 통해 받을 수 있습니다.Batch 내부에는 Spark를 이용할 수 있는 AWS DMS가 존재하고, Kinesis쪽도 마찬가지로 Spark Streaming을 이용해서 분석을 진행합니다.
또한, 전체적으로 비정형 데이터들은 S3에 Data Lake를 만들어 저장합니다.
비정형 데이터들을 최종적으로 서빙해서 저장하는 곳에는 DynamoDB나 RDS, Redshift를 이용해 저장하고 조회하는 데 사용합니다.
( 데이터 웨어하우스를 구성할 떄는 Redshift를 이용 )모델 학습할 때는, Amazon SageMaker를 통해 전처리한 것을 학습하고 모델을 만들 수 있습니다.
이러한 학습을 자동화시키는 부분까지 MLOps에 포함이 됩니다.
마지막으로, Airflow라는 서비스를 이용해서 전체적으로 이러한 flow를 정의해놓을 수 있습니다. 혹은 전체적으로 Data Catalog를 만들어서 관리해주는 AWS Glue라는 서비스를 사용할 수 있습니다.
( Airflow vs. AWS Glue )
