✏️ 오늘 학습한 내용
1. 데이터 팀의 역할
2. 데이터 조직의 구성원
3. 데이터 웨어하우스와 데이터 레이크, ETL/ELT
4. 데이터 웨어하우스 옵션들
5. 데이터 스택 트랜드
🔎 데이터 팀의 역할
📃 데이터 조직의 비전은?
신뢰할 수 있는 데이터를 바탕으로 부가 가치를 생성하는 것입니다.
데이터 조직은 대부분의 회사에서 직접 매출을 내는 것이 아니라 그 회사의 본업, 매출을 더 잘할 수 있게 하는 부가 가치를 만드는 역할을 수행합니다.
📃 데이터 조직은 어떤 방식으로 매출에 기여를 하는 가?
-
의사 결정에 데이터를 활용
-
Decision Science라고 부르기도 합니다.
-
데이터 기반 지표 정의, 대시보드와 리포트 생성 등을 수행
-
-
고품질 데이터를 기반으로 사용자 서비스 경험 개선 혹은 프로세스 최적화
-
머신 러닝과 같은 알고리즘을 통해 사용자의 서비스 경험을 개선합니다.
-
Product science라 부르기도 합니다.
-
Product를 계산하고 비용을 줄임으로써 앞단의 Decision science 팀에서 트래킹하던 지표 KPI를 개선하는 형태로 발전
-
📃 데이터 웨어하우스란?
-
회사에 필요한 모든 데이터를 모아 놓은 중앙 데이터베이스
-
데이터의 크기에 맞게 어떤 데이터베이스를 사용할지 선택
- AWS RedShift, 구글 클라우드의 BigQuery
- Snowflake
- 하둡 (Hive/Presto) / SPark
-
중요 포인트는 프로덕션 데이터베이스와 별개의 데이터베이스여야 한다는 것
-
데이터 웨어하우스의 구축이 진정한 데이터 조직이 되는 첫 번째 스텝
-
📃 ETL이란?
-
다른 곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
-
Extract : 외부 데이터 소스에서 데이터를 추출
-
Transform : 데이터의 포맷을 원하는 형태로 변환
-
Load : 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재
-
데이터 파이프라인이라 부르기도 합니다.
-
-
관련하여 가장 많이 사용되는 framework는 Airflow
- Airflow는 오픈소스 프로젝로 파이썬3 기반, Airbnb에서 시작
- AWS와 구글 클라우드에서도 지원
-
ETL 관련 SaaS도 출현하기 시작
- 흔한 데이터 소스의 경우 FiveTran, Stitch Data와 같은 SaaS를 사용하는 것도 가능
📃 시각화 대시보드란?
-
보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
- 지표의 경우 3A가 중요 (Accessible, Actionable, Auditable)
- Accessible : 언제나 원할 때 지표를 볼 수 있어야함
- Actionable : 등락의 의미가 분명해야함, 의미를 해석을 해야하는 경우 좋은 지표가 아님
- Auditable : 보고 있는 지표의 숫자가 맞는 숫자인지 확인할 방법이 따로 있어야함
- 지표의 경우 3A가 중요 (Accessible, Actionable, Auditable)
-
가장 널리 사용되는 대시보드:
- 구글 클라우드의 룩커 (Looker)
- 세일즈포스의 태블로 (Tableau)
- 마이크로소프트의 파워 BI (Power BI)
- 오픈소스 아파치 수퍼셋 (Superset)
📃 머신 러닝이란?
-
데이터로부터 패턴을 찾아 학습
- 데이터의 품질과 크기가 중요
- 데이터로 인한 왜곡(bias) 발생 가능
- AI 윤리
- 내부동작 설명 가능 여부도 중요
-
장점 : 프로그래밍에 대한 배움 없이 가능한 알고리즘
-
단점
-
블랙박스 : 왜 이렇게 동작하는 지 이해할 수 없고, 설명할 수 없습니다.
-
Garbage in garbage out : 데이터의 품질이 나쁘면 머신러닝의 품질도 나빠집니다.
-
🔎 데이터 조직의 구성원
📕 데이터 엔지니어
📃 데이터 엔지니어의 역할
-
기본적으로는 소프트웨어 엔지니어
- 파이썬이 대세, 자바 혹은 스칼라와 같은 언어도 아는 것이 좋음
-
데이터 웨어하우스 구축
-
데이터 웨어하우스를 만들고 이를 관리, 클라우드로 가는 것이 추세
-
주요 작업 중 하나가 ETL 코드를 작성하고 주기적으로 실행하는 것
- ETL Scheduler 혹은 Framework이 필요 ( Airflow가 대세)
-
-
데이터 분석가와 과학자 지원
- 데이터 분석가, 데이터 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해주는 것이 데이터 엔지니어의 중요한 역할 중의 하나
📃 데이터 엔지니어가 알아야하는 기술
( 주니어 단계 - 꼭 알아야하는 기술 )
-
SQL : 기본 SQL, Hive, Preseto, SparkSQL
-
데이터 웨어하우스 : Redshift/Snowflake/BigQuery
-
ETL/ELT Framework : Airflow
-
대용량 데이터 처리 플랫폼 : Spark/YARN
( 알아두면 좋은 기술 )
-
컨테이너 기술 : Docker/K8s
-
클라우드 컴퓨팅 : AWS, GCP, Azure
-
도움이 되는 기타 지식
- 머신 러닝 일반
- A/B 테스트, 통계
📕 데이터 분석가
📃 데이터 분석가의 역할
-
비지니스 인텔리전스를 책임짐
-
중요 지표를 정의하고 이를 대시보드 형태로 시각화
- 대시보드로는 테블로와 룩커 등의 툴이 가장 흔히 사용됨
- 오픈소스로는 수퍼셋(superset)이 많이 사용됨
-
이런 일을 수행하려면 비즈니스 도메인에 대한 깊은 지식이 필요
-
-
회사내 다른 팀들의 데이터 관련 질문 대답
-
임원들이나 팀 리드들이 데이터 기반 결정을 내릴 수 있도록 도와줌
-
질문들이 굉장히 많고 반복적이기에 어떻게 셀프서비스로 만들 수 있느냐가 관건
-
📕 MLOps
📃 MLOps의 역할
-
DevOps가 하는 일은?
-
DevOps 엔지니어는 서비스 코드를 만들지는 않음
-
개발자가 만든 코드를 시스템에 반영하는 프로세스를 수행함 (CI/CD, deployment)
-
시스템이 제대로 동작하는지 모니터링
-
이슈 감지시 escalation 프로세스
- On-call 프로세스
-
개발자가 만든 코드를 배포하기 위해서 계속해서 테스트하는 CI 프로세스를 진행,
테스트가 완료되면 빌드를 하고 패키지를 만드는 프로덕션에 배포해주는 CD 프로세스를 운영,
서비스가 정상적으로 동작하는 지 계속해서 모니터링하고 이슈가 보이면 이전 코드로 Rollback을 하던지 escalation 프로세스를 수행
DevOps엔지니어들은 교대로 돌아가며 당직처럼, 문제가 발생시 상시 처리할 수 있도록 준비하는 On-call 프로세스를 수행
-
MLOps가 하는 일은?
-
앞의 DevOps가 하는 일은 동일, 차이점은 서비스 코드가 아니라 ML 모델이 대상
-
모델을 계속적으로 빌딩하고 배포하고 성능을 모니터링
-
ML 모델 빌딩과 프로덕션 배포를 자동화할 수 있을까? 계속적인 모델 빌딩(CT)과 배포!
-
모델 서빙 환경과 모델의 성능 저하를 모니터링하고 필요시 escalation 프로세스 진행
-
-
머신러닝 모델을 테스트하고 배포하고, 모니터링하고 문제가 발생하면 해결을 위한 작업을 follow up하는 직군
📃 MLOps 엔지니어가 알아야하는 기술
- 데이터 엔지니어가 알아야 하는 기술
- 파이썬/스칼라/자바
- 데이터 파이프라인과 데이터 웨어하우스
- DevOps 엔지니어가 알아야 하는 기술
- CI/CD, 서비스 모니터링
- 컨테이너 기술 (K8S, 도커)
- 클라우드 (AWS,GCP,Azure)
- 머신러닝 관련 경험/지식
- 머신러닝 모델 빌딩과 배포
- ML 모델 빌딩 Framewokr 경험
- SageMaker, Kubeflow, MLflow
📕 데이터 디스커버리 서비스
📃 데이터 디스커버리 란?
-
별도의 직군은 아니지만 데이터 활용이 커지면 꼭 필요한 서비스
-
데이터가 커지면 테이블과 대시보드의 수가 증가!!
데이터 분석시 어느 테이블이나 대시보드를 봐야하는 지 혼란이 생김
-> 해결하고자 직접 새로운 테이블이나 대시보드를 또 만들어 냄
-> 정보 과잉 문제가 더 심해지는 악순환 발생
따라서, 주기적인 테이블과 대시보드 클린업이 필수!
-
Data Discovery 서비스
어떤 셀프 서비스 형태로 어떤 데이터를 봐야하는 지 어떤 대시보드를 봐야하는 지 본인들이 알아서 검색해서 찾을 수 있도록 하는 서비스
-
Data Catalog
데이터 시스템 내의 모든 데이터, 테이블, 대시보드, ETL 데이터 파이프라인 등을 모두 가져와서 저장을 한 DB
=> 이러한 Data Catalog를 사람들이 쓰기 쉽게 검색 가능하게 만들어주는 Tool이 Data Discovery
데이터 디스커버리 오픈소스 서비스
- 리프트에서 만든 아문센
- 링크드인에서 만든 데이터허브
- 셀렉트스타 (실리콘밸리에서 한인 창업자가 만든 서비스)
🔎 데이터 웨어하우스와 데이터 레이크, ETL/ELT
📃 데이터 웨어하우스 옵션별 장단점
-
데이터 웨어하우스는 기본적으로 클라우드가 대세
-
데이터가 커져도 문제가 없는 확장가능성(Scalable)과 적정한 비용이 중요한 포인트
-
크게 고정비용 옵션과 가변비용 옵션이 존재하며 후자가 좀 더 확장 가능한 옵션
- 고정비용 : Redshift
- 가변비용 : BigQuery, Snowflake
-
오픈소스 기반(Presto, Hive)을 사용하는 경우도 클라우드 버전 존재
-
데이터가 작다면 굳이 빅데이터 기반 데이터베이스를 사용할 필요가 없음
📃 데이터 레이크
-
구조화 데이터 + 비구조화 데이터 (로그 파일)
-
보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 가까움
-
보통은 데이터 웨어하우스보다 몇배는 더 크고 더 경제적인 스토리지
-
보통 클라우드 스토리지가 됨
-> AWS의 S3가 대표적인 데이터 레이크 -
데이터 레이크가 있는 환경에서 ETL과 ELT
- ETL : 데이터 레이크와 데이터 웨어하우스 바깥에서 안으로 데이터를 가져오는 것
- ELT : 데이터 레이크와 데이터 웨어하우스 안에 있는 데이터를 처리하는 것

ELT는 내부 데이터를 처리하는 것으로,
데이터 레이크의 데이터를 정제해서 다시 데이터 레이크에 저장을 하던지,
데이터 레이크의 데이터를 정제해서 데이터 웨어하우스에 저장을 하던지
혹은
데이터 웨어하우스에서 데이터를 정제해서 다시 데이터 웨어하우스에 저장하던지,
이러한 행위들을 ELT라고 합니다.
📃 ETL -> ELT
-
ETL의 수는 회사의 성장에 따라 쉽게 100개 이상으로 발전
-
중요한 데이터를 다루는 ETL이 실패했을 경우 이를 빨리 고쳐서 다시 실행하는 것이 중요
-
이를 적절하게 스케줄하고 관리하는 것이 중요해지며 그래서 ETL 스케줄러 혹은 Framework가 필요
- Airflow가 대표적인 Framework
-
-
데이터 요약을 위한 ETL도 필요해짐에 따라 ELT가 등장
-
ETL은 다양한 데이터 소스에 있는 데이터를 읽어오는 일을 수행
-
이를 모두 이해해서 조인해서 사용하는 것은 데이터가 다양하고 점점 커지기에 불가능
-
주기적으로 요약 데이터를 만들어 사용하는 것이 더 효율적
-> DBT 사용
ex) 고객 매출 요약 테이블, 제품 매출 요약 테이블, ..
-
ETL은 보통 Airflow로 구현을 하고,
ELT는 Airflow로 스케줄링은 하지만,
그 안에서 이렇게 데이터들을 join해서 새로운 데이터들을 만들어낼 때는 DBT라는 툴을 사용합니다.
📃 다양한 데이터 소스의 예
-
프로덕션 데이터베이스의 데이터
( MySQL, Postgres, ...) -
이메일 마케팅 데이터
( Mailchimp, HubSpot, SendGrid, ... ) -
크레딧 카드 매출 데이터
( Stripe ) -
서포트 티켓 데이터, 서포트 콜 데이터
( Zendesk, Kustomer, Talkdesk ... ) -
세일즈 데이터
( Salesforce ) -
사용자 이벤트 로그
( 비구조화된 매우 커다란 데이터 -> 데이터 레이크에 저장 )
📃 Airflow(ETL 스케줄러)
-
ETL 관리 및 운영 Framework의 필요성
-
다수의 ETL이 존재할 경우 이를 스케줄해주고 이들 간의 의존관계(dependency)를 정의해주는 기능 필요
-
Backfill : 특정 ETL이 실패할 경우 이에 관한 에러 메세지를 받고 재실행해주는 기능
이 Backfill을 사용하기 쉬운 구조가 Airflow
-
-
가장 많이 사용되는 Framework : Airflow
-
AWS와 구글클라우드와 Azure에서도 지원
-
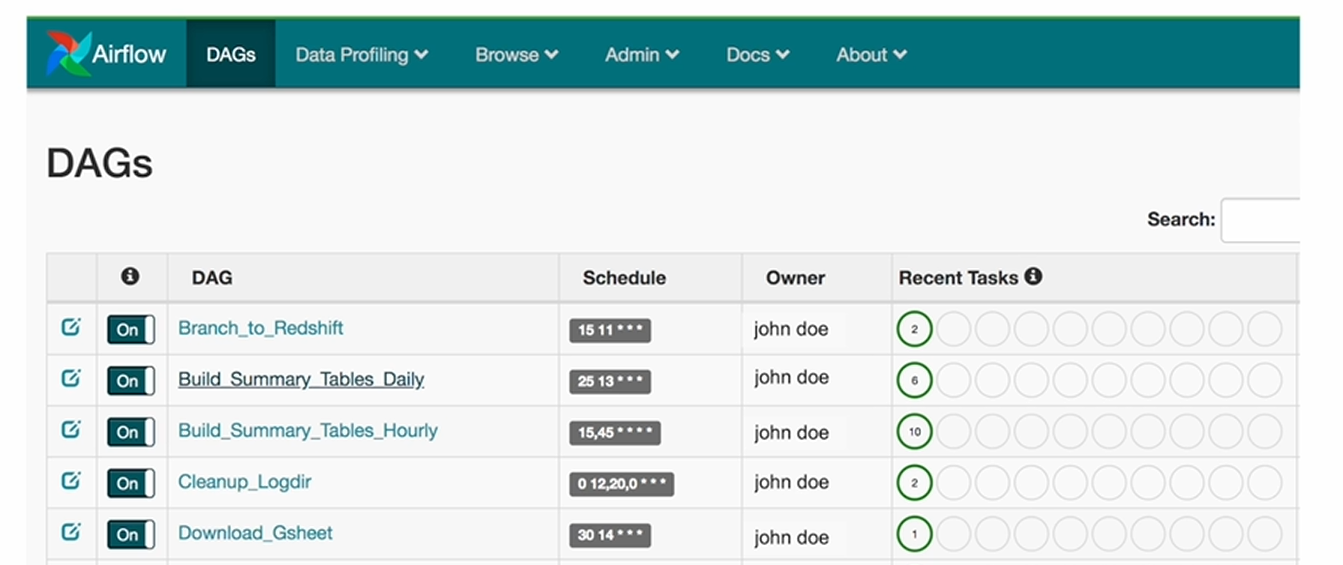
Airflow에서는 ETL을 DAG라 부르며 웹 인터페이스를 통한 관리 기능을 제공
-
크게 3가지 컴포넌트로 구성
- 스케줄러
- 웹 서버
- 워커(Worker)
-
-
DAG : Airflow의 ETL이자 데이터 파이프라인
📃 빅데이터 처리 Framework
-
분산 환경 기반
- 1대 혹은 그 이상의 서버로 구성
- 분산 파일 시스템과 분산 컴퓨팅 시스템이 필요
-
Fault Tolerance
- 소수의 서버가 고장나도 동작해야함
-
Replication Factor
- 서버의 일부가 고장이 나는 상황을 대비해 데이터를 여러 서버에 동일하게 저장을 하는 것
-
확장이 용이해야함
- Scale Out이 되어야함
- 용량을 증대하기 위해서 서버 추가
Scale Up : 서버 사양을 올리는 것
Scale Out : 서버를 추가하는 것
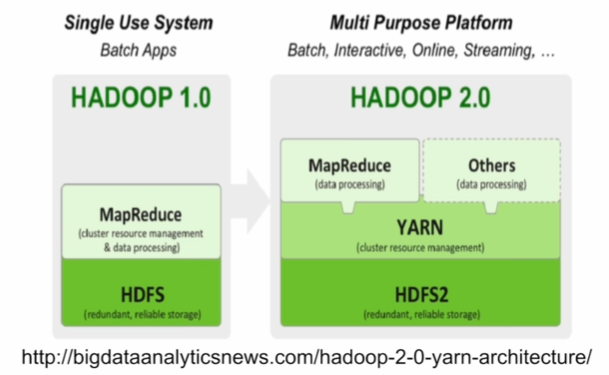
📃 대표적인 빅데이터 프로세싱 시스템
- 1세대 : 하둡 기반의 MapReduce, Hive/Presto
- 2세대 : Spark
🔎 데이터 웨어하우스 옵션들
-
AWS Redshift
-
Snowflake
-
Google CLoud BigQuery
-
Apache Hive
-
Apache Presto
-
Apache Iceberg
-
Apache Spark
-
위 옵션들의 공통점은?
- Iceberg를 제외하고, 모두 SQL를 지원하는 빅데이터 기반 데이터베이스
Spark의 경우, 데이터 웨어하우스라고 할 수는 없으나,
Iceberg와 Spark를 결합하면 Iceberg가 스토리지 역할을,
Spark는 스토리지에 있는 데이터를 읽어서 프로세싱하는 엔진 역할을 하기 때문에,
두 개를 합쳐서 데이터 웨어하우스라 할 수 있습니다.
📃 AWS Redshift
-
AWS 기반의 데이터 웨어하우스로 PB 스케일 데이터 분산 처리 가능
-
Postgresql과 호환되는 SQL로 처리 가능
-
초기에는 고정비용 모델이였으나 이제는 가변비용 모델도 지원 (Redshift Serverless)
-
온디맨드 가격 이외에도 예약 가격 옵션도 지원
-
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
-
AWS 내의 다른 서비스들과 연동이 쉽습니다.
-
S3, DynamDB, SageMaker 등등
-
Redshift의 기능 확장을 위해 Redshift Spectrum, AWS Athena 등의 서비스와 같이 사용 가능
-
-
배치 데이터 중심이지만 실시간 데이터 처리 지원
-
웹 콘솔 이외에도 API를 통한 관리/제어 가능 (AWS CLI)
📃 Snowflake
-
2014년에 클라우드 기반 데이터웨어하우스로 시작
-
지금은 데이터 클라우드라 부를 수 있을 정도로 발전
-
데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace 제공
-
ETL과 다양한 데이터 통합 기능 제공
-
-
SQL 기반으로 빅데이터 저장, 처리, 분석이 가능합니다.
- 비구조화된 데이터 처리와 머신러닝 기능 제공
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- AWS S3, GC 클라우드 스토리지, Azure Blog Storage도 지원
-
배치 데이터 중심이지만 실시간 데이터 처리 지원
-
웹 콘솔 이외에도 API를 통한 관리/제어 가능 (AWS CLI)
📃 Google Cloud Bigquery
-
2010년에 시작된 구글 클라우드의 데이터 웨어하우스 서비스
-
구글 클라우드의 대표적인 서비스
-
BigQuery SQL이라는 SQL로 데이터 처리 가능 (Nested fields, repeated fields 지원)
( 굉장히 복잡한 구조의 스키마도 처리 가능 )- Nested fields : JSON이 Nesting된 것처럼 field 안에 subfield가 있고... 한 부분들을 전부 SQL로 처리할 수 있습니다.
- Repeated fields : List array 유사합니다.
-
가변 비용과 고정 비용 옵션 지원
-
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- 클라우드 스토리지, 데이터플로우, AutoML 등등
-
배치 데이터 중심이지만 실시간 데이터 처리 지원
-
웹 콘솔 이외에도 API를 통한 관리/제어 가능 (AWS CLI)
📃 Apache Hive
-
Facebook이 2008년에 시작한 아파치 오픈소스 프로젝트
-
하둡 기반으로 동작하는 SQL 기반 데이터 웨어하우스 서비스
-
HiveQL이라 부르는 SQL 지원
-
MapReduce 위에 동작하는 버전과 Apache Tez를 실행 엔진으로 동작하는 버전 2가지
-
다른 하둡 기반 오픈 소스들과 연동이 쉬움 (Spark, HBase 등)
-
자바나 파이썬으로 UDF 작성 가능
-
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
-
배치 빅데이터 프로세싱 시스템 (실시간 x)
-
데이터 파티셔닝과 버킷팅과 같은 최적화 작업 지원
-
빠른 처리속도보다는 처리할 수 있는 데이터 양의 크기에 최적화
-
-
웹 UI와 커맨드라인 UI (CLI라 부름) 두 가지를 지원
-
Spark에 밀린 분위기
📃 Apache Presto
-
Facebook이 2013년에 시작한 아파치 오픈소스 프로젝트
-
하이브와 문법이 매우 유사하지만 데이터의 양(디스크 중심)보다는 처리 속도(메모리 중심)에 집중
-
다양한 데이터소스에 존재하는 데이터를 대상으로 SQL 실행가능
- HDFS, S3, MySQL 등
- PrestoSQL이라 부르는 SQL 지원
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
-
배치 빅데이터 프로세싱 시스템
- Hive 와는 다르게 빠른 응답 속도에 좀 더 최적화 (메모리 기반)
-
AWS Athena가 바로 Presto 기반으로 만들어짐
-> Hive와 Presto는 기본적으로 Hadoop 위에서 돌아가는 SQL 엔진
📃 Apache Iceberg
-
Netflix가 2018년에 시작한 아파치 오픈소스 프로젝트로 데이터 웨어하우스 기술이 아님
-
대용량 SCD(Slowly-Changing Datasets) 데이터를 다룰 수 있는 테이블 포맷
-
HDFS, S3, Azure Blob Storage 등의 클라우드 스토리지 지원
-
ACID 트랜잭션과 타임여행 (과거 버전으로 롤백과 변경 기록 유지 등)
-
스키마 진화 (Schema Evolution) 지원을 통한 컬럼 제거와 추가 가능 (테이블 재작성 없이)
-
-
자바와 파이썬 API를 지원
-
Spark, Flink, Hive, Hudi 등의 다른 Apache 시스템과 연동 가능
📃 Apache Spark
-
UC 버클리 AMPLab이 2013년에 시작한 아파치 오픈소스 프로젝트
-
빅데이터 처리 관련 다양한 기능 제공
- 배치처리(API/SQL), 실시간 처리, 그래프 처리, 머신러닝 기능 제공
-
다양한 분산처리 시스템 지원
( 분산처리 시스템을 갖고 있는 것이 아니라 분산처리 시스템 내에서 사용 )- 하둡(YARN), AWS EMR, Google Cloud Dataproc, Mesos, K8s 등
-
다양한 파일시스템과 연동 가능
- HDFS, S3, Cassandra, HBase 등
-
CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
-
다양한 언어 지원 : 자바, 파이썬, 스칼라, R
🔎 데이터 스택 트랜드
📕 데이터 플랫폼의 발전단계
-
초기 단계 : 데이터 웨어하우스 + ETL
-
발전 단계 : 데이터 양 증가
- Spark와 같은 빅데이터 처리시스템 도입
- 데이터 레이크 도입
-
성숙 단계 : 데이터 활용 증대
- 현업단의 데이터 활용이 가속화
- ELT 단이 더 중요해지면서 dbt 등의 analytics engineering 도입
- MLOps 등 머신러닝 관련 효율성 증대 노력 증대
📃 발전 단계: 데이터 양 증가
-
Spark과 같은 빅데이터 처리시스템 도입
-
데이터 레이크 도입 : 보통 로그 데이터와 같은 대용량 비구조화 데이터 대상
( 크게 3가지 형태의 flow )- 데이터 소스 -> 데이터 파이프라인 -> 데이터 웨어하우스
- 데이터 소스 -> 데이터 파이프라인 -> 데이터 레이크
( 데이터 소스가 굉장히 큰 경우 ) - 데이터 레이크 -> 데이터 파이프라인 -> 데이터 웨어하우스
- 이때 Spark/Hadoop 등이 사용됨
- Hadoop: Hive/Presto 등이 기반됨
점점 데이터 양이 커지기에 데이터 레이크와 같은 경제적이고,
Scale이 더 큰 스토리지가 필요해졌습니다.
또한, 이런 대용량 데이터를 프로세싱 하려다보니,
대용량 분산처리시스템의 도입이 필요해지게 되었습니다.
📃 성숙 단계: 현업단의 데이터 활용 가속화
- ELT 단에서 생기는 품질이 더 중요해지면서 dbt 등의 analytics engineering 도입
- 데이터 레이크 to 데이터 레이크, 데이터 레이크 to 데이터 웨어하우스, ...
- MLOps 등 머신러닝 개발 운영 관련 효율성 증대 노력 증대
