✏️ 오늘 학습한 내용
1. Open Weather DAG 구현
2. Backfill과 Airflow
🔎 Open Weather DAG 구현
Open Weathermap API란
-
위도/경도 기반으로 그 지역의 기후 정보를 알려주는 서비스
-
무료 계정으로 api key를 받아서 호출 시 사용
목적
API를 통해 서울 8일 간의 낮/최소/최대 온도를 읽어오는 것
구현 세부사항
-
API Key를 open_weather_api_key라는 Variable로 저장
-
서울의 위도와 경도 구하기
-
One-Call API 사용
https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&exclude={part}&appid={API key}&units=metric -
Redshift의 weather_forecast 테이블에 저장
CREATE TABLE schema_name.weather_forecast ( date date primary key, temp float, -- 낮 온도 min_temp float, max_temp float, # created_date는 레코드 생성시간으로 자동 생성됨 # incremental update를 할 때 활용. created_date timestamp default GETDATE() ); -
One-Call API는 JSON 형태로 데이터를 전달
-
API의 daily 필드에 8일 간의 날씨 정보가 존재
-
날짜 정보는 "dt" 필드에 존재 (epoch형태)
epoch -> timestamp -> str -
온도 정보는 "temp" 필드에 존재
- day,min,max,night,eve,morn
-
-
Redshift connection의 autocommit 끄기
autocommit = False -
Full Refresh
-
INSERT INTO 방식 (테이블 제거 후 재생성)
-
COPY 방식 (Redshift의 bulk update방식)
( 바이너리 파일로 만들어 S3에 적재 -> COPY로 Redshift에 적재 )
-
Full Refresh 방식으로 구현
대략적인 서울의 위도 경도 값 : 37.5665 / 126.9780
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
import json
def get_Redshift_connection():
# autocommit is False by default
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
@task
def etl(schema, table):
api_key = Variable.get("open_weather_api_key")
# 서울의 위도/경도
lat = 37.5665
lon = 126.9780
# https://openweathermap.org/api/one-call-api
url = f"https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&appid={api_key}&units=metric&exclude=current,minutely,hourly,alerts"
response = requests.get(url)
# data = response.json()과 동일
data = json.loads(response.text)
ret = []
for d in data["daily"]:
# epoch을 timestamp로 변환
# timestamp를 str로 변환
day = datetime.fromtimestamp(d["dt"]).strftime('%Y-%m-%d')
ret.append("('{}',{},{},{})".format(day, d["temp"]["day"], d["temp"]["min"], d["temp"]["max"]))
cur = get_Redshift_connection()
drop_recreate_sql = f"""DROP TABLE IF EXISTS {schema}.{table};
CREATE TABLE {schema}.{table} (
date date,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);
"""
# for문에 insert를 넣지 않고 반복문 연산 결과를 한번에 insert함
insert_sql = f"""INSERT INTO {schema}.{table} VALUES """ + ",".join(ret)
logging.info(drop_recreate_sql)
logging.info(insert_sql)
try:
# 위에서 지정한 테이블 재생성 SQL문을 실행
cur.execute(drop_recreate_sql)
cur.execute(insert_sql)
cur.execute("Commit;")
except Exception as e:
cur.execute("Rollback;")
# Error 발생시 알림을 주기 위해
# 꼭 raise를 설정
raise
with DAG(
dag_id = 'Weather_to_Redshift',
start_date = datetime(2023,5,30), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
) as dag:
etl("skqltldnjf77", "weather_forecast")Primary Key Uniqueness
일반적으로 빅데이터 기반의 데이터 웨어하우스는 Primary Key Uniqueness를 보장해주지 않습니다.
그럼 Primary Key Uniqueness를 아예 보장하지 않는 건가요? -> 엔지니어마다의 별도의 방법을 통해 보장합니다.
Primary Key Uniqueness란?
-
테이블에서 하나의 레코드를 유일하게 지칭할 수 있는 필드
- 하나의 필드가 일반적이지만 다수의 필드도 가능
-
e.g.)
CREATE TABLE products ( product_id INT PRIMARY KEY, name VARCHAR(50), price decimal(7, 2) ); CREATE TABLE orders ( order_id INT, product_id INT, PRIMARY KEY (order_id, product_id), FOREIGN KEY (product_id) REFERENCES products (product_id) ); -
Primary key uniqueness를 보장해주지 않는 이유는?
- 보장하는데 메모리와 시간이 더 들기 때문에 대용량 데이터의 적재에 걸림돌이 되기 때문입니다.
( 모든 레코드들의 Primary Key를 B+Tree와 같은 형태로 메모리에 올려두고 체크를 매번 해야하기 때문 )
- 보장하는데 메모리와 시간이 더 들기 때문에 대용량 데이터의 적재에 걸림돌이 되기 때문입니다.
Primary Key 유지 방법
예시 테이블
CREATE TABLE keeyong.weather_forecast (
date date primary key,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);-
날씨 정보이기 때문에 최근 정보를 더 신뢰할 수 있습니다.
이 점을 이용해서 date가 중복될 때, created_date를 기준으로 더 최근 정보를 선택하는 것입니다.
( ROW_NUMBER로 보장 ) -
date별로 created_date의 역순으로 일련번호를 부여
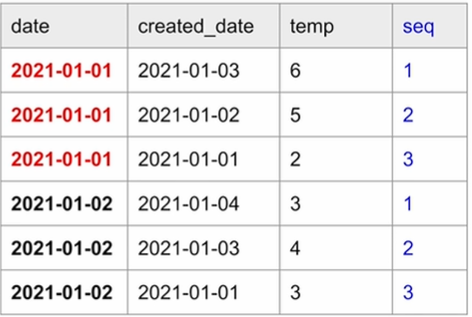
ROW_NUMBER() OVER (partition by date order by created_date DESC) seq를 통해 각 date별로 created_date 역순으로 정렬 후 일련번호를 부여그 후,
seq=1인 경우만 남기고 중복 제거하면 primary key uniqueness가 보장됩니다. -
위 내용들을 정리하면
-
임시 테이블(스테이징 테이블)을 만들고 거기에 현재 모든 레코드를 복사
-
임시 테이블에 새로 데이터 소스에서 읽어들인 레코드들을 추가
( Incremental Update )
( 중복 발생 ) -
중복을 제거하는 SQL 작성
ROW_NUMBER() ... -
위의 SQL을 바탕으로 최종 원본 테이블로 복사
-
원본 테이블의 레코드 전부 삭제
-
임시 테이블을 원본 테이블로 복사
-
위 2개의 원본 테이블을 수정하는 SQL문은 데이터의 정합성을 위해 트랜잭션이 꼭 들어가야합니다.
autocommit이 true인 경우
임시 테이블을 제작하는 부분은 트랜잭션 처리를 하지 않더라도 데이터 적합성을 해치지 않습니다.그러나 autocommit이 false라면, 트랜잭션을 하지 않으면 실행이 되지 않기에 임시테이블을 제작하는 부분도 모두 트랜잭션 처리해야합니다.
-
-
구현
from airflow import DAG
from airflow.decorators import task
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from datetime import timedelta
import requests
import logging
import json
def get_Redshift_connection():
# autocommit is False by default
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
@task
def etl(schema, table, lat, lon, api_key):
# https://openweathermap.org/api/one-call-api
url = f"https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&appid={api_key}&units=metric&exclude=current,minutely,hourly,alerts"
response = requests.get(url)
data = json.loads(response.text)
ret = []
for d in data["daily"]:
day = datetime.fromtimestamp(d["dt"]).strftime('%Y-%m-%d')
ret.append("('{}',{},{},{})".format(day, d["temp"]["day"], d["temp"]["min"], d["temp"]["max"]))
cur = get_Redshift_connection()
# 원본 테이블이 없다면 생성
create_table_sql = f"""CREATE TABLE IF NOT EXISTS {schema}.{table} (
date date,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);"""
logging.info(create_table_sql)
# 임시 테이블 생성
create_t_sql = f"""CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};"""
logging.info(create_t_sql)
try:
# 원본 테이블이 없는 경우 생성
cur.execute(create_table_sql)
# 임시 테이블 생성
cur.execute(create_t_sql)
# 여기서 커밋을 안해도 되긴하지만
# autocommit이 false이므로 중간 중간에 commit을 해주는게 좋음
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
# 에러 발생시 raise로 알림
raise
# 임시 테이블 데이터 입력
insert_sql = f"INSERT INTO t VALUES " + ",".join(ret)
logging.info(insert_sql)
try:
# 임시 테이블에 데이터 추가
cur.execute(insert_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
# 기존 테이블 대체
alter_sql = f"""DELETE FROM {schema}.{table};
INSERT INTO {schema}.{table}
SELECT date, temp, min_temp, max_temp FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1;"""
logging.info(alter_sql)
try:
# 기존 테이블 삭제 및 교체
cur.execute(alter_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
with DAG(
dag_id = 'Weather_to_Redshift_v2',
start_date = datetime(2022,8,24), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 4 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
) as dag:
etl("skqltldnjf77", "weather_forecast_v2", 37.5665, 126.9780, Variable.get("open_weather_api_key"))Upsert란?
Update와 Insert의 하이브리드 버전
-
Primary Key를 기준으로 존재하는 레코드라면 새 정보로 수정 (update)
-
존재하지 않는 레코드라면 새 레코드로 적재 (insert)
-
보통 데이터 웨어하우스마다 UPSERT를 효율적으로 해주는 문법을 지원해줌
🔎 Backfill과 Airflow
관리하는 데이터 파이프라인의 수가 늘어나면 에러가 꼭 발생하기 때문에 어떻게 관리하느냐가 데이터 엔지니어의 삶에 큰 영향을 줍니다.
-> Backfill의 중요성
Incremental Update가 실패하면?
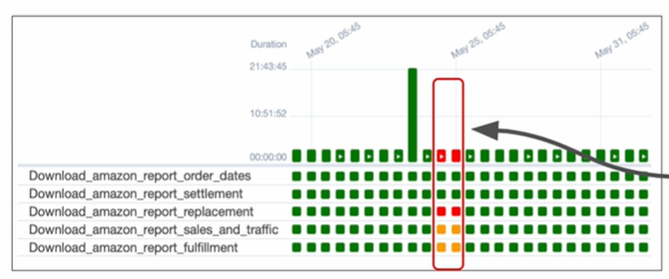
하루에 한번 동작하고 Incremental하게 업데이트하는 파이프라인이라면?
위의 경우 5월 24일 ~ 5월 25일 간 실행이 실패했기에 데이터에 공백이 발생합니다.
나중에라도 이를 알았을 때 실패한 부분을 쉽게 재실행할 수 있는가? 이게 바로 데이터 엔지니어의 삶에 매우 영향을 미칩니다.
( Full Refresh는 문제가 생겨도 다시 실행하면 되기에 이 내용이 의미가 없습니다. )
즉,
-
Full Refresh를 사용하는 편이 좋습니다.
( 가능하다면 ) -
Incremental Update는 효율성이 더 좋을 수 있지만 운영/유지보수의 난이도가 올라갑니다.
-
실수 등으로 데이터가 빠지는 일이 생길 수 있음
-
과거 데이터를 다시 다 읽어와야하는 경우 다시 모두 재실행을 해주어야함
-
Backfill의 정의
실패한 데이터 파이프라인을 재실행 혹은 읽어온 데이터들의 문제로 다시 다 읽어와야하는 경우를 의미
보통의 Daily DAG 작성
datetime.now()을 기준으로 하루를 빼고 그 날짜에 해당하는 데이터를 읽어옵니다.
from datetime import datetime, timedelta
y = datetime.now() - timedelta(1)
yesterday = datetime.strftime(y,'%Y-%m-%d')
# 어제 날짜에 해당하는 데이터를 읽어옴
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"지난 1년치 데이터를 Backfill해야한다면?
-
기존 ETL 코드를 조금 수정해서 지난 1년치 데이터에 대해 돌림
-
그 과정 중에서 실수하기도 쉽고 수정하는데 시간이 오래 걸림
Backfill 친화적 ETL 구현
-
시스템적으로 Backfill을 쉽게 해주는 방법을 구현
-
날짜 별로 Backfill 결과를 기록하고 성공 여부 기록 : 나중에 결과를 쉽게 확인
-
이 날짜를 시스템에서 ETL의 인자로 제공
-
데이터 엔지니어는 읽어와야하는 데이터의 날짜를 계산하지 않고 시스템이 지정해준 날짜를 사용
-
-
Airflow의 접근 방식
-
ETL 별로 실행날짜와 결과를 메타데이터 데이터베이스에 기록
-
모든 DAG 실행에는 "execution_date"가 지정되어 있음
- execution_date으로 채워야하는 날짜와 시간이 넘어옴
-
이를 바탕으로 데이터를 갱신하도록 코드 작성
-
이점 : Backfill이 쉬워짐
-
Daily Incremental Update 구현
-
예를 들어 2020년 11월 7일의 데이터부터 매일매일 하루치 데이터를 읽어온다고 가정
-
이 경우 언제부터 해당 ETL이 동작할까요?
- 2020년 11월 8일에 처음 실행됩니다.
-
반대로, 2020년 11월 8일날 동작하지만 읽어와야하는 데이터의 날짜는?
- 2020년 11월 7일 (start_date)
Airflow에서 말하는 DAG의 start_date는 읽어와야하는 데이터의 날짜 기준!
- 2020년 11월 7일 (start_date)
즉, Airflow의 start_date는 DAG의 시작 날짜가 아니라 읽어와야하는 데이터의 시작 날짜입니다.
따라서, Daily DAG의 경우. DAG의 시작 전날이 바로 start_date가 되는 것입니다.
매우 혼동스러운 부분이기 때문에 다시 정리
-
Airflow의 start_date는 DAG의 시작 날짜가 아닌 처음 읽어와야하는 데이터의 날짜
-
execution_date는 읽어와야하는 데이터의 날짜로 설정됨
이를 혼동했을 경우 발생할 수 있는 잘못된 사례
예를 들어, daily job의 start_date를 2020년 8월 6일, 오늘 날짜를 8월 14일로 설정했다고 가정하겠습니다.
이때, 이 Job이 Enable되는 순간 이 Job은 catchup 파라미터의 값에 따라 8번을 자동 실행하게 됩니다. ( catchup의 default값이 true이므로 별도의 설정을 하지 않으면 자동 실행됨 )
start_date와 execution_date 이해하기
- 2020-08-10 02:00:00으로 start date로 설정된 daily job이 있음
- catchup이 True로 설정되어 있다고 가정
(Default : True)
- catchup이 True로 설정되어 있다고 가정
- 현재 시간이 2020-08-13 20:00:00이고 처음으로 이 job이 활성화됨
문제 : 이 경우 이 job은 몇번 실행될 것인가?
(execution_date)
2020-08-10 02:00:00
2020-08-11 02:00:00
2020-08-12 02:00:00
2020-08-13 02:00:00
-> 총 4번 (X)
인줄 알았으나 정답은 3번
2020-08-10의 경우, start_date이기에 하루 다음 날부터 DAG가 실행 가능합니다.
( 데이터를 하루 동안 수집해야함 )
-> 하루 밀린 것과 같이 돌아감
따라서 돌아가는 job은 3번입니다.
2020-08-10 02:00:00
2020-08-11 02:00:00
2020-08-12 02:00:00
Backfill과 관련된 Airflow 변수들
start_date :
DAG가 처음 실행되는 날짜가 아니라 DAG가 처음 읽어와야하는 데이터의 날짜/시간. 실제 첫 실행날짜는 start_date + DAG의 실행주기
execution_date :
DAG가 읽어와야하는 데이터의 날짜와 시간
catchup :
DAG가 처음 활성화된 시점이 start_date보다 미래라면 그 사이에 실행이 안된 것들을 어떻게 할 것인지 결정해주는 파라미터.True가 default 값이고 이 경우
실행안 된 것들을 모두 따라잡으려고 함.False가 되면 실행안된 것들을 무시함
end_date :
이 값은 보통 필요하지 않으며 Backfill을 날짜 범위에 대해 하는 경우에만 필요
airflow dags backfill -s …. -e ….
