✏️ 오늘 학습한 내용
1. Docker 정리
2. 서버 관리의 어려움
3. Container Orchestration
4. K8s 소개
5. K8s 아키텍처
6. K8s/Docker 사용 예시
🔎 Docker 정리
Docker를 실제 Production 환경에서 사용할 때 유의할 점
-
Docker volumes
-
Host volumes은 보통 개발 시 소스코드를 바로 container 안으로 마운트하기 위함
-
Production에서는 named volumes를 써야함!
( docker run -v를 실행할 때 Container 이름과 Container 경로를 지정하는 방식 )
-
-
Docker container는 read-only로 사용
-
내용을 바꿔야한다면 실행 중인 컨테이너를 수정하지 말아야합니다!
( 컨테이너가 종료되면 날라가기 때문에 ) -
변경 사항이 발생하면 항상 이미지를 새로 빌드하고 다시 컨테이너들을 새로 실행해야합니다.
-
이에 대한 자동화가 중요 (CI/CD 프로세스)
ex) Github Actions - CI/CD
-
-
다수의 Docker Container들을 다수의 호스트들에서 실행 필요
-
용량 문제 (Capacity)
-
Fail-over (혹은 fail-tolerant)
( 서버가 실패하면 서비스가 다 날라감 )
-
Docker는 생산성 향상의 Utility 툴
Docker를 개발, 테스트, 배포 관점에서만 생각하지 말고 생산성을 높이기 위한 Utility 툴 용도로 여기는 것도 좋습니다.
-
일관된 방식으로 소프트웨어 설치
-
분리된 충돌없는 환경에서 소프트웨어 설치/실행
🔎 서버 관리의 어려움
관리해야하는 서버의 수가 늘어날 수록 발생하는 문제도 많아집니다.
어느 서버에 문제가 있는지? 어느 서비스에 문제가 있는지? 이러한 문제들을 얼마나 빠르게 감지하고 해결할 수 있을지?
...
결국, 사람들이 이러한 문제들을 Burn out이 오지않게 빠르고 효율성있게 감지하고 해결하는 것이 중요해집니다.
📃 해결방안
1. 문서화
-
지금 서비스 상황과 셋업 방법 문서화
-
다양한 문제 발생시 해결 방법 문서화
문서를 현재 상황에 맞게 업데이트하는 것은 엄청난 노력이 필요할 뿐아니라 상황에 따라 의미가 없는 경우도 많습니다.
또한, 적은 수의 서버를 메뉴얼하게 관리하는 것은 가능할 수 있어도 몇 백대의 서버를 일일히 관리하고 명령을 실행한다는 것은 거의 불가능에 가깝기에 좋은 방법은 아니라고 할 수 있습니다.
2. 문서화가 아닌 코드
소프트웨어를 설치하고 하는 자체를
문서화가 아니라 코드로 대신하는 것.
자동화된 스크립트를 작성함으로써,
세부 내용을 기억하지않아도 코드로 다 기록이 되고
코드를 봄으로써 이해할 수 있게합니다.
이 방법이 요즘 트랜드이고,
이를 Infrastructure As Code 라고 부릅니다.
-> 이는 DevOps 엔지니어가 꼭 알아야하는 기술
-
문서보다는 코드로 관리
- 대화형 명령보다는 자동화된 스크립트로 해결
- 다수의 서버들에 명령을 대신 실행해줌
-
다양한 툴들이 많음
- Chef
- Puppet
- Ansible
- Terraform
-
장점
-
자동화를 해주기에 서버를 일일히 로그인해서 문제 해결을 하고 새로운 모듈을 설치할 필요 없습니다.
-
하나의 커맨드를 다수의 서버에 전파해서 실행하는 것이 가능
-
-
단점
-
Learning curve가 높음
( 배우기가 매우 복잡 ) -
설치시 소프트웨어 충돌 문제에는 크게 도움이 안됨
( 분리된 공간을 제공하는 것이 아니기에 )
-
3. Virtual Machine의 도입
Infrastructure As Code 위에 소프트웨어들이 실행되는 공간을 분리하는 방법!
실제 하드웨어 위에 가상 하드웨어를 올리는 방식이라 OS를 별도로 갖고 있어야하며 무겁습니다.
-
소프트웨어 충돌 해결을 위해 VM을 사용
- 한 Physical Server에 다수의 VM을 올리고 서비스별로 VM을 하나씩 할당
-
단점
-
VM이 전반적으로 리소스 소비가 크고 느림
-
결정적으로 특정 VM 벤더 혹은 클라우드에게 종속됨
( Lock-in )VM을 제공해주는 벤더가 몇개 없을 뿐더러 대부분은 유료서비스입니다.
또한, 사용하는 그 한 벤더에 종속되게 됩니다.
-
4. Docker의 도입
VM과 유사하지만 Docker Engine이라는 Application 위에서 동작하기 때문에 훨씬 경량화되어있습니다.
-
모든 소프트웨어를 Docker Image로 만들면 어디서건 동작
-
VM에 비해 리소스 낭비도 적고 실행 시간도 빠름
-
거기다가 오픈소스이기에 클라우드 혹은 특정업체에 대한 Lock-in 이슈도 없음
-
거의 단점이 없음
- Docker Container의 수가 늘어나면 관리가 힘들어지는 것 정도
-> 효율적으로 관리할 수 있는 도구가 필요 (K8s)
- Docker Container의 수가 늘어나면 관리가 힘들어지는 것 정도
=> Docker는 이제 서비스 배포의 기본이 되었습니다.
모든 것의 컨테이너화 ->
이를 Containerization이라 부릅니다.
📃 마이크로서비스란?
하나의 웹 서비스 (Monolith)를 다수의 작은 서비스(Microservices)들로 구현하는 방식을 뜻합니다.
-
Monolith 방식의 문제점
- Backend, Frontend 등이 모두 한 코드베이스에 존재
한 코드베이스에 존재함으로써,
각 팀이 빠르게 각자의 스피드에 맞게 개발하기가 힘들어집니다.
이를 극복하기 위해 나온 것이 microservice
- Backend, Frontend 등이 모두 한 코드베이스에 존재
-
Microservice
기능에 맞게 나누는 방식으로 자기만의 속도로 개발을 진행할 수 있도록 나온 아키텍쳐-
Decentralization ( 탈중앙화 )
-
Modularity ( 기능의 모듈화 )
-
Domain driven design ( 각 팀이 알아서 디자인 )
-
Focus on empowering teams ( 각 개발팀에 권한을 위임하고 힘을 실어줌 )
-
-
단점
-
복잡해지면 어떻게 연동이 되고 있는지 알기 힘듦
-
어떤 서비스들이 있는지 알기 힘듦
-> 이를 해결하기 위해 나온 것이 Service Registry
-
-
Service Registry
- 그 시스템에서 지원하는 모든 API, Microservice들이 등록이 됨
( 마치 Docker image들을 관리하는 Docker image registry와 같음 )
- 그 시스템에서 지원하는 모든 API, Microservice들이 등록이 됨
🔎 Container Orchestration
다수의 Container들이 다수의 서버 위에 존재하는 상황에서 마치 오케스트라 연주의 지휘자가 있는 것처럼 Container들을 효율적으로 관리하기 위한 도구
📃 Container Orchestration 기능
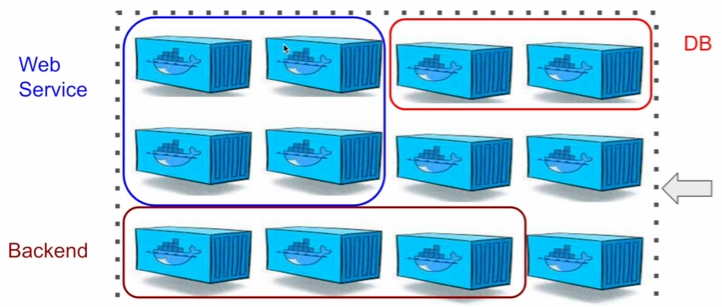
-
한 클러스터 안에 다양한 서비스들이 공존할 수 있게함
-
DB, Web Service, Backend, etc
-
자원 요청을 받아 마스터가 자원을 할당
-
-
다양한 기능 제공
-
개발자가 만든 이미지를 배포
-
스케일링 (로드밸런싱을 통한 트래픽 분배)
-
네트워크 (컨테이너 간 네트워크 연결)
-
인사이트 등
-
소프트웨어 배포
-
서비스 이미지를 Container로 배포
-
이상이 감지되면 이전 안정 버전으로 롤백
-
v1에서 v2로 배포되는 경우 문제 발생시 v1으로 롤백
-
Container 수가 많을 수록 큰 이슈
-
DevOps 팀 관점에서 가장 중요한 기능
-
스케일링
-
특정 서비스의 Container 수를 쉽게 늘리고 줄이는 것
-
이때 서버의 utilizaiton을 고려
예시)
- before
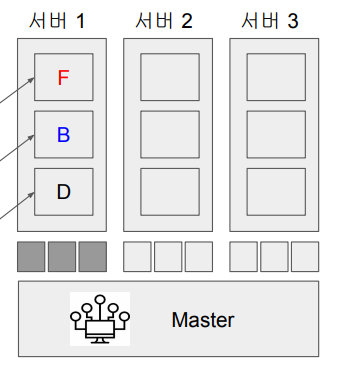
3개의 서버가 있고,
FrontEnd, BackEnd, DB 이렇게 3가지 서비스가 있다고 할때, 초기에 한 서버에서 F,B,D를 모두 돌려 그 서버의 utilization이 100%가 된 상황입니다.
이는 비효율적이므로 여유가 된다면, 각 서버마다 균등하게 서비스를 분배하는 것이 좋습니다.
- after

서비스들의 사용량이 많아져 컨테이너를 증축해야하는 경우, 위와 같은 방식으로 다른 서버에 서비스를 추가할 수 있습니다.
( 총 9개의 컨테이너 중 8개가 사용됨 )
네트워크
-
서비스가 다수의 컨테이너로 나눠지면서 이를 대표하는 Load Balancer를 만들어주어야합니다.
-
서비스들 간에는 서로를 쉽게 찾을 수 있어야합니다.
- 서비스 디스커버리
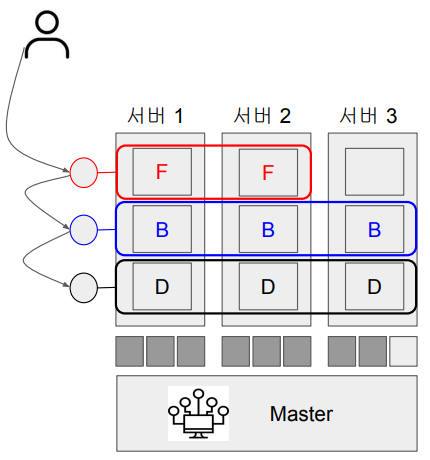
FrontEnd를 대표하는 로드밸런서, BackEnd를 대표하는 로드밸런서, DB를 대표하는 로드밸런서가 각각 한개씩 있는 상황입니다.
이 로드밸런서는 속한 Container 수와 관계없이,
모든 Request를 받아서 속해있는 Container들에게
나눠주고 그러면서 Container가 고장이 나면,
그 Container를 서비스에서 제거하는 역할을 수행합니다.
인사이트
-
노드/컨테이너 문제 발생시 해결
-
Logging/Analytics 등의 기능 제공
-
전체 서비스 분석
- 시각화
- 문제 분석
📃 Container Orchestration 툴들
K8s를 중심으로 정리가 되고 있으며,
모든 클라우드 업체들이 K8s 관련 서비스를 내놓고 있는 추세입니다.
( EKS, AKS, GKE )
- Mesos
- Marathon
- DEIS
- Rancher
- Nomad
- Docker Swarm
- K8s
🔎 K8s 소개
Kubernetes (K8s)란?
컨테이너 기반 서비스를 배포하고 스케일링 및 관리를 함으로써 운영을 자동화를 해주는 오픈소스 프레임워크
-
구글에서 사용하던 Borg를 서비스를 오픈소스화함
-
클라우드나 온프레미스 모두에서 잘 동작함
-
주로 Docker Container들이 대상이 됨
( 어느 컨테이너든 가능 ) -
물리서버나 가상서버 위에서 모두 동작
가장 많이 사용되는 Container Orchestration 시스템
-
사용 회사와 커뮤니티 활동이 굉장히 많고 활발
-
카카오, 네이버, 쿠팡 등의 국내 업체도 활발히 사용
-
모든 글로벌 클라우드 업체들이 지원
( EKS, AKS, GKE )
좋은 확장성
-
확장성이 좋아서 다양한 환경에서 사용
-
머신러닝 : Kubeflow
-
CI/CD : Tekton
-
Service Mesh : Istio
-
Serverless : Kubeless
-
-
다수의 서버에서 컨테이너 기반 프로그램을 실행하고 관리
-
Docker Container (컨테이너 기반 프로그램)
-
보통 Docker와 K8s는 같이 사용됨
-
Pod :
- 쿠버네티스에서 실행하는 최소 Unit
- 같은 디스크(volume)와 네트워크를 공유하는 하나 이상의 Container들의 집합
-
🔎 K8s 아키텍처
기본적으로 쿠버네티스는 다수의 서버로 구성되어있습니다.
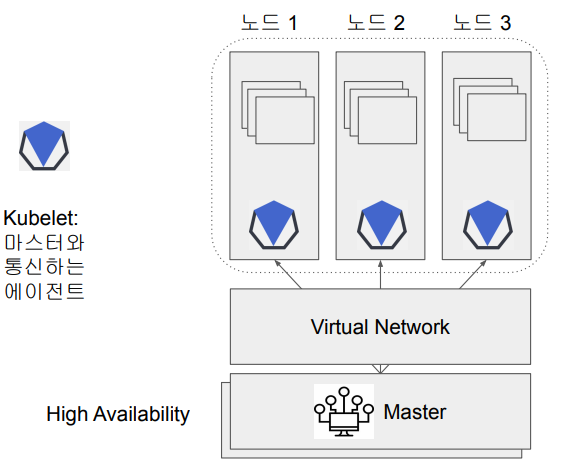
-
High Availability ( HA )
어떤 중요한 서비스를 2개 이상의 서버를 구성함으로써 한 서버가 다운되도 계속해서 서비스가 운영되도록 하는 것
-
Master
-
Cluster를 관리해주는 역할
-
Master를 통해서 쿠버네티스가 제공해주는 기능을 사용
-
이 Master에는 다수의 프로세스가 동작
-
Master가 관리하는 다수의 서버를 Node라고 부름
-
-
Node는 물리서버이거나 가상서버
-
Kubelet
-
Master와 Node가 통신하기 위한 에이전트
-
각 Node의 상황을 파악
-
상황에 따라 Pod를 만들고 그 안에 새로운 Docker Container를 생성
-
-
Virtual Network
-
Pod 간의 network 연결
-
분리된 Network을 만들어 보안을 보장
-
K8s 프로세스들
-
Master 안에는 여러 프로세스들이 있습니다.
-
API Server (Container로 동작) : kube-apiserver
-
쿠버네티스의 Entrypoint 역할
-
서버에 Access하는 방법
- Web UI, CLI (kubectl), API
-
-
Scheduler
-
노드들의 상황 파악 - utilization
-
Pods 생성과 할당을 할 때 고려해야할 정보 제공
-
-
Controller Manager
- 전체 상황을 모니터링
- fault tolerance 보장
( 문제가 있는 Node를 다른 Node로 옮겨서 재실행 )
-
Master는 High Availability가 중요!
( 서비스가 계속 동작할 수 있게 끔 ) -
etcd
- Master가 중요한 환경설정 정보를 저장하는데 사용하는 Key-value 스토어
-
-
Controller runtime
- 대부분 Docker runtime이 설치됨
Kubectl : 커맨드라인 툴
docker와 docker-compose와 유사합니다.
-
kubectl run hello-minikube
지정한 pod를 실행 -
kubectl cluster-info
cluster의 정보 확인 -
kubectl get node
노드들이 어떻게 세팅이 되어 있는지?
Pod?
쿠버네티스 사용시 컨테이너를 바로 다루지 않고,
Mapping을 한 Pod라는 블록을 사용해 그 안에서 컨테이너를 다룹니다.
-
Pod
-
K8s 사용자가 사용하는 가장 작은 빌딩 블록
-
보통은 하나의 container로 구성
-
하나보다 많은 경우, 보통 helper container가 같이 사용됨
-
같은 Pod 안에서는 디스크와 네트워크가 공유됨
-
Fail-over를 위해 replicas를 지정하는 것이 일반적
( 실패했을 시를 대비한 복제본 )
-> 다양한 방법으로 복제본을 유지
-
즉, Pod는 네트워크 주소를 갖는 self-contained server
YAML 환경 설정 예시
# pod-definition.yml
apiVersion: apps/v1
# Pod, Service, ReplciSet, Deployment 중 하나 지정
kind: Pod
# Pod의 이름 : nginx
metadata:
name: nginx
# Container의 이름 nginx
spec:
containers:
- name: nginx
image: nginx-
Deployment
Pod가 여러 개 있는 경우, 보통 Deployment를 통해 관리합니다.
Auto-Scaling하고 싶은 경우, 특정 GPU에 따라 container 수를 줄이거나 늘리거나 할때 Deployment를 사용합니다. -
Service
같은 역할을 하는 Pod의 그룹을 어떻게 접근할지 지정
Pod 생성 예시
# 위 yml 파일을 바탕으로 Pod를 생성
kubectl create -f pod-definition.yml
# 모든 pod 확인
kubectl get pods
# nginx라는 이름의 Pod에 대한 상세 정보
kubectl describe pd nginx
# yml 파일을 바탕으로 Pod를 생성하지않고
# 지정한 image를 기반으로 nginx라는 Pod를 생성하는 것
kubectl run nginx --image nginx🔎 K8s/Docker 사용 예시
이 두 회사의 포스팅을 읽어보고 추후에 비교 분석을 해보겠습니다.
쿠버네티스에 대한 추가적인 공부가 필요해지면
아래 강의도 수강할 예정!
https://www.udemy.com/course/learn-kubernetes/
