✏️ 오늘 학습한 내용
1. Airflow Docker 환경 재설정
2. Summary 테이블 구현
3. Slack 연동
🔎 Airflow Docker 환경 재설정
먼저, Airflow를 설치하기 위해 Clone 했었던
learn-airflow repo를 최신버전으로 갱신해줍니다.
git pull
docker-compose.yaml 수정
-
_PIP_ADDITIONAL_REQUIREMENTS환경변수 수정
( DAG에 필요한 파이썬 모듈 등 추가 ) -
data 폴더를 Host 폴더에 생성 (임시 데이터 저장 용)
/sources/data- 이를 docker volume으로 지정해서 나중에 디버깅에 사용
${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data
- 이를 docker volume으로 지정해서 나중에 디버깅에 사용
# 변경 사항
environment:
# DATA_DIR란 변수 추가
AIRFLOW_VAR_DATA_DIR: /opt/airflow/data
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- yfinance pandas numpy
oauth2client gspread}
volumes:
…
- ${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data
airflow-init:
…
mkdir -p /sources/logs /sources/dags /sources/plugins /sources/data
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins,data}
Detached 모드로 실행
-d 옵션을 사용하여 Airflow를 백그라운드에서 실행
docker compose up -d
웹 UI 로그인
http://localhost:8080 으로 웹 UI 로그인
- ID/PW = airflow:airflow
위에서 설정한 DATA_DIR란 변수는 웹 UI의 Admin->Variables에 접근해도 보이지가 않습니다.
DAG와 Airflow 환경 정보들은 Postgres의 Named Volume으로 유지되고 있습니다.
환경변수로 설정된 것은 Web UI에서는 안보이지만
프로그램에서는 사용 가능합니다.
그러나 커맨드라인에서는 이를 확인할 수 있습니다.
docker exec -it airflow-setup-airflow-scheduler-1 airflow variables get DATA_DIR
-> 결과 : /opt/airflow/data
-
airflow variables get DATA_DIR명령어란?-
airflow 명령어 중에는 tasks와 dags에 관련된 명령만 있는 것이 아니라 variables, connections도 있습니다.
-
이 명령어의 경우, DATA_DIR라는 이름의 변수를 찾아 출력해줍니다.
-
📃 Airflow 실행환경 관리방안
기타 환경설정값들 (Variables, Connections 등)을 어떻게 관리/배포할까?
- 보통 docker-compose.yml 파일에서 정의
예시)
x-airflow-common:
&airflow-common
…
environment:
&airflow-common-env
AIRFLOW_VAR_DATA_DIR: /opt/airflow/data
AIRFLOW_CONN_TEST_ID: test_connection어디까지 Airflow 이미지로 관리하고 무엇을 docker-compose.yml에서 관리해야할까?
- Production 세팅의 Docker 이미지인 경우
일반적으로, dags를 넣어 Airflow 이미지를 만들고 그 Airflow 이미지를 Docker-compose에서 사용하는 것이 더 좋습니다.
- 개발 중인 경우
매번 Docker 이미지를 새로 만들면서 거기에 dags 소스코드를 매번 복사해넣는 것이 번거롭기 때문에,
개발을 할 때는, Host volume을 사용해서 이미지 자체는 dags코드를 포함하지 않고 host의 dags 폴더를 mount하게 해서 사용하는 것이 일반적
📃 Airflow DAG 관리방안
- Production의 경우
- Airflow image로 DAG 코드를 복사하여 만드는 것이 깔끔
- 개발 용도의 경우
- docker-compose에서 host volume형태로 설정하는 것이 용이
📃 .airflowignore란?
-
Airflow가 의도적으로 무시해야하는 DAG_FOLDER의 디렉토리 또는 파일을 지정
-
Airflow의 DAG 스캔 패턴
Airflow가 DAG를 찾는 방식은
Airflow.cfg 파일에dags_folder라는 키가 있고 이 키에 세팅이 된 경로에 가서 어떤 파일이 있는지 서브 폴더까지 스캔합니다.거기에 있는 DAG 모듈이 포함된 모든 파이썬
스크립트를 실행해서 새로운 DAG를 찾게 됩니다.이때, 실행이 무조건 되기에 개발하다만 DAG가 있는 경우 사고가 발생합니다.
-> 이러한 부분을 ignore처리
-
.airflowignore의 각 줄은 정규식 패턴으로 지정하며 매칭되는 파일을 무시됩니다.
ex) 정규식 -> 매칭되는 파일 ( ignore 대상 )
project_a -> project_a_dag_1.py
tenant_[\d] -> tenant_1.py
🔎 Summary 테이블 구현
CTAS로 ELT를 구현해보겠습니다.
좀 더 자세하게 SQL의 CTAS를 Airflow 상의 DAG로 구현해서 Redshift의 테이블로 만들 것입니다.
Summary table: 간단한 DAG 구현
-
Build_Summary.py: MAU 요약 테이블 생성
( 월 별 방문자의 수 ) -
코드
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow.hooks.postgres_hook import PostgresHook
from datetime import datetime
from datetime import timedelta
from airflow import AirflowException
import requests
import logging
import psycopg2
from airflow.exceptions import AirflowException
def get_Redshift_connection():
hook = PostgresHook(postgres_conn_id = 'redshift_dev_db')
return hook.get_conn().cursor()
def execSQL(**context):
schema = context['params']['schema']
table = context['params']['table']
select_sql = context['params']['sql']
logging.info(schema)
logging.info(table)
logging.info(select_sql)
cur = get_Redshift_connection()
# 임시 table 생성, CTAS
sql = f"""DROP TABLE IF EXISTS {schema}.temp_{table};CREATE TABLE {schema}.temp_{table} AS """
sql += select_sql
cur.execute(sql)
# 그 결과가 하나라도 있는 경우, 그 임시 테이블의 이름을 원본 테이블의 이름으로 변경
cur.execute(f"""SELECT COUNT(1) FROM {schema}.temp_{table}""")
# fetchone() -> Row를 가져오는 method
count = cur.fetchone()[0]
# 하나도 없는 경우 Error 반환
if count == 0:
raise ValueError(f"{schema}.{table} didn't have any record")
try:
# 임시 테이블의 이름을 원본 테이블의 이름으로 변경
sql = f"""DROP TABLE IF EXISTS {schema}.{table};ALTER TABLE {schema}.temp_{table} RENAME to {table};"""
# Autocommit이 False 이기에 COMMIT를 해줘야 적용됨
# Autocommit이 False인 경우 BEGIN이 의미가 없기에 사용해도 되고 안사용해도 됨
sql += "COMMIT;"
logging.info(sql)
cur.execute(sql)
except Exception as e:
cur.execute("ROLLBACK")
logging.error('Failed to sql. Completed ROLLBACK!')
# Airflow에서 정의해주는 Exception
raise AirflowException("")
dag = DAG(
dag_id = "Build_Summary",
start_date = datetime(2021,12,10),
# @once를 설정하였기에
# 주기적으로 실행되는 것이 아니라
# 필요할 때 웹 UI에서 트리거를 하든,
# CLI에서 명령을 통해 실행을 하던지 직접 실행
schedule = '@once',
catchup = False
)
execsql = PythonOperator(
task_id = 'mau_summary',
python_callable = execSQL,
params = {
'schema' : 'skqltldnjf77',
'table': 'mau_summary',
'sql' : """SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
;"""
},
dag = dag
)Summary table: 사용자별 channel 정보 요약
Build_Summary.py와 대부분의 내용이 동일하지만
PythonOperator의 params 파라미터만 다르게 수정해보겠습니다.
( SQL 쿼리 외 크게 달라지는 부분이 없음 )
params = {
'schema' : 'skqltldnjf77',
'table': 'channel_summary',
'sql' : """SELECT
DISTINCT A.userid,
# 처음 방문한 채널이 무엇인지?
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and
unbounded following) AS First_Channel,
# 마지막에 방문한 채널이 무엇인지?
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and
unbounded following) AS Last_Channel
FROM raw_data.user_session_channel A
LEFT JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid;"""
},
-> rows between unbounded preceding and unbounded following
- unbounded preceding : 맨 처음 row의 값
- unbounded following : 맨 뒤 row의 값
즉, 범위에 row의 모든 값이 포함된다는 의미
CTAS 부분을 별도의 환경설정 파일로 분리
CTAS를 DAG 파일에서 분리하여 별도의 환경설정 파일로 만듦으로써 SQL Query 부분을 비개발자(데이터 분석가)가 쉽게 접근하고 이용할 수 있도록 만들어보겠습니다.
- 환경 설정 중심의 접근 방식
- dags 폴더 안에 config 폴더 생성
- 그 내부에 summary 테이블 별로 하나의 환경설정 파일 생성
( dictionary 형태가 필요하기에 .py 파일로 생성 )
- 비개발자가 사용하기에 접근성이 좋아짐
ex)
dags/config/mau_summary.py
{
'table': 'mau_summary',
'schema': 'skqltldnjf77',
'main_sql': """SELECT …;""",
'input_check': [ ],# list형태로 다수의 check가능
'output_check': [ ],
}📃 NPS Summary 테이블 생성해보기
-
NPS (Net Promoter Score)
-
10점 만점으로 '주변에 추천하겠는가?'라는 질문을 기반으로 고객 만족도 계산
-
10, 9점 추천하겠다는 고객(promoter)의 비율에서 0~6점의 불평 고객(dtractor)의 비율을 뺀 것이 NPS
-
-
SQL 쿼리문
SELECT LEFT(created_at, 10) AS date, ROUND( SUM( CASE WHEN score >= 9 THEN 1 WHEN score <= 6 THEN -1 END )::float*100/COUNT(1), 2 ) nps FROM keeyong.nps GROUP BY 1 ORDER BY 1;
CTAS를 환경설정 파일로 분리
dags/config/nps_summary.py
{
'table': 'nps_summary',
'schema': 'skqltldnjf77',
'main_sql': """
SELECT LEFT(created_at, 10) AS date,
ROUND(SUM(CASE
WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)::float*100/COUNT(1), 2)
FROM raw_data.nps
GROUP BY 1
ORDER BY 1;""",
'input_check': [ {
# 수가 count(150000) 보다 작으면 Error
'sql': 'SELECT COUNT(1) FROM raw_data.nps',
'count': 150000
} ],
'output_check': [ {
# temp 테이블에서 쿼리문을 돌린 후 품질 검사
# 12개 보다 작으면 Error
'sql': 'SELECT COUNT(1) FROM {schema}.temp_{table}',
'count': 12
} ],
}새로운 Operator와 helper 함수 구현
위와 같은 summary 환경설정 파일들을 DAG에 매번 일일히 호출하여 사용하지 않고 보다 편리하게 사용하기 위해,
다수의 환경변수 파일을 관리하는 redshift_summary.py 란 파일을 만들 것입니다.
환경 설정 파일의 CTAS를 실행해주는 Operator를 새로 만들어주고,
( RedshiftSummaryOperator )
새로 생성한 Operator가 config 폴더 안에 있는 모든 환경 설정 파일들을 일일히 호출하지 않고 한번에 읽어올 수 있도록 도와주는 helper 함수를 만들어줍니다.
( build_summary_table )
RedshiftSummaryOperator
# PythonOperator를 계승한 Operator
class RedshiftSummaryOperator(PythonOperator):
@apply_defaults
# summary.py에 들어간 dictionary의 key값들이 전부 포함됨
def __init__(self,
schema,
table,
redshift_conn_id,
input_check,
main_sql,
output_check,
# overwrite=TRUE이면 기존 테이블 삭제 후 추가
# FALSE이면 데이터를 추가하는 방식
overwrite,
params={},
pre_sql="",
after_sql="",
attributes="",
*args,
**kwargs
):
self.schema = schema
self.table = table
self.redshift_conn_id = redshift_conn_id
self.input_check = input_check
self.main_sql = main_sql
self.output_check = output_check
# compose temp table creation, insert into the temp table as params
if pre_sql:
main_sql = pre_sql
if not main_sql.endswith(";"):
main_sql += ";"
else:
main_sql = ""
main_sql += "DROP TABLE IF EXISTS {schema}.temp_{table};".format(
schema=self.schema,
table=self.table
)
# CTAS
main_sql += "CREATE TABLE {schema}.temp_{table} {attributes} AS ".format(
schema=self.schema,
table=self.table,
attributes=attributes
) + self.main_sql
if after_sql:
self.after_sql = after_sql.format(
schema=self.schema,
table=self.table
)
else:
self.after_sql = ""
# Operator override
super(RedshiftSummaryOperator, self).__init__(
python_callable=redshift_sql_function,
params={
"sql": main_sql,
"overwrite": overwrite,
"redshift_conn_id": self.redshift_conn_id
},
provide_context=True,
*args,
**kwargs
)
# 원본 테이블을 삭제하고 임시테이블의 이름을 원본 테이블로 변경
def swap(self):
sql = """BEGIN;
DROP TABLE IF EXISTS {schema}.{table} CASCADE;
ALTER TABLE {schema}.temp_{table} RENAME TO {table};
GRANT SELECT ON TABLE {schema}.{table} TO GROUP analytics_users;
END
""".format(schema=self.schema,table=self.table)
self.hook.run(sql, True)
def execute(self, context):
self.hook = PostgresHook(postgres_conn_id=self.redshift_conn_id)
# input_check, 정의했던 count보다 작으면 error
for item in self.input_check:
(cnt,) = self.hook.get_first(item["sql"])
if cnt < item["count"]:
raise AirflowException(
"Input Validation Failed for " + str(item["sql"]))
# 메인 쿼리문 실행 - 임시 테이블 생성
return_value = super(RedshiftSummaryOperator, self).execute(context)
# output_check
for item in self.output_check:
(cnt,) = self.hook.get_first(item["sql"].format(schema=self.schema, table=self.table))
if item.get("op") == 'eq':
if int(cnt) != int(item["count"]):
raise AirflowException(
"Output Validation of 'eq' Failed for " + str(item["sql"]) + ": " + str(cnt) + " vs. " + str(item["count"])
)
else:
if cnt < item["count"]:
raise AirflowException(
"Output Validation Failed for " + str(item["sql"]) + ": " + str(cnt) + " vs. " + str(item["count"])
)
# 임시 테이블에 문제가 없었으면 원본 테이블로 스왑
self.swap()
if self.after_sql:
self.hook.run(self.after_sql, True)
return return_valuebuild_summary_table
config 폴더를 뒤져서 거기에 있는 파일을 대상으로 그 정보를
RedshiftSummaryOperator로 넘겨주는 역할을 수행
def build_summary_table(dag_root_path, dag, tables_load, redshift_conn_id, start_task=None):
logging.info(dag_root_path)
# 지정한 dag 경로의 /config 폴더 내부의 모든 파일 스캔
# 각 dictionary 형태가 모인 list로 반환
table_confs = load_all_jsons_into_list(dag_root_path + "/config/")
if start_task is not None:
prev_task = start_task
else:
prev_task = None
for table_name in tables_load:
# find 함수의 경우 직접 생성한 함수로 table이름이 일치하는 dictionary를 반환
table = find(table_name, table_confs)
summarizer = RedshiftSummaryOperator(
table=table["table"],
schema=table["schema"],
redshift_conn_id=redshift_conn_id,
input_check=table["input_check"],
main_sql=table["main_sql"],
output_check=table["output_check"],
overwrite=table.get("overwrite", True),
after_sql=table.get("after_sql"),
pre_sql=table.get("pre_sql"),
attributes=table.get("attributes", ""),
# 지정한 부모 dag
dag=dag,
task_id="anayltics"+"__"+table["table"]
)
if prev_task is not None:
prev_task >> summarizer
prev_task = summarizer
return prev_taskDAG 파일에 CTAS 환경변수 추가
Build_Summary_v2.py
from airflow import DAG
from airflow.macros import *
import os
from glob import glob
import logging
import subprocess
from plugins import redshift_summary
from plugins import slack
DAG_ID = "Build_Summary_v2"
dag = DAG(
DAG_ID,
schedule_interval="25 13 * * *",
max_active_runs=1,
concurrency=1,
catchup=False,
start_date=datetime(2021, 9, 17),
default_args= {
'on_failure_callback': slack.on_failure_callback,
'retries': 1,
'retry_delay': timedelta(minutes=1),
}
)
# this should be listed in dependency order (all in analytics)
tables_load = [
# nps_summary.py 환경변수 추가
'nps_summary'
]
dag_root_path = os.path.dirname(os.path.abspath(__file__))
# redshift_summary.py 사용
redshift_summary.build_summary_table(dag_root_path, dag, tables_load, "redshift_dev_db")
-> 이러한 방식보다 좋은건 dbt를 사용하는 것!
🔎 Slack 연동
DAG가 실패할 시 Slack으로 에러를 보내도록 연동하겠습니다.
-
목적 :
DAG 실행 중에 에러가 발생하면 지정된 Slak workspace의 채널로 보내기 -
목표 :
-
Slack workspace에 App 생성
-
연동을 위한 함수 생성
plugins/slack.py -
함수를
default_args의on_failure_callback에 지정default_args : DAG를 만들 때, 그 DAG에 속한 모든 task에 지정이 되는 기본 속성이 세팅이 되는 Dictionary
from plugins import slack … default_args= { 'on_failure_callback': slack.on_failure_callback, } -
정리,
DAG가 실패할 때마다,on_failure_callback에 지정된 함수slack.py가 실행되고slack.py에서 에러 메세지를 만들어서 연동이 되어있는 Workspace 채널로 메세지를 전송.
📃 Slack workspace에 App 생성
Slack workspace 밑에 data-alert라는 채널을 public으로 생성했습니다.
App 생성
Incoming Webhooks App을 생성하면 Endpoint를 받을 수 있는데, 그 Endpoint로 메세지를 보내면 그 Endpoint에 연결이 되어있는 Slack 채널에 메시지가 가는 방식입니다.
- https://api.slack.com/messaging/webhooks
- 위 링크의 가이드를 따라 Incoming Webhooks App을 생성합니다.
-
App 생성
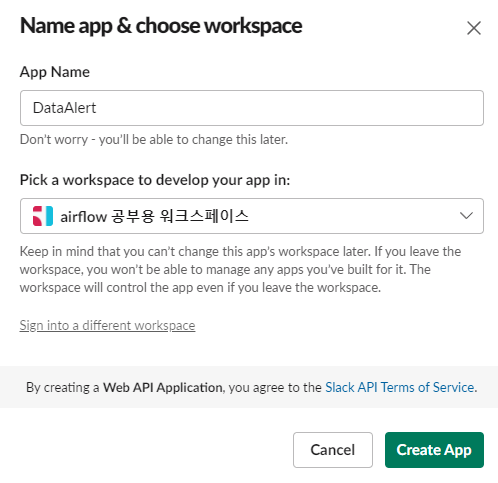
-
Incoming Webhooks 활성화

-
Endpoint 사용 방법 - Sample url
( "YOUR_WEBHOOK_URL_HERE" 부분에 개인이 할당받은 url 입력하면 사용 가능 )

-
채널 선택

-
Webhook URL (Endpoint)
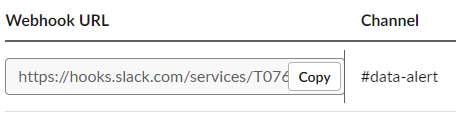
📃 Slack 연동
-
위에서 받은 webhook url을
slack_url변수로 저장보안을 위해 docker-compose.yml에 넣거나,
Airflow Web UI에서 특정 키워드를 넣어 노출이 안되도록 만드는 방법도 존재 -
slack에 에러 메세지를 보내는 모듈 개발 :
slack.py -
이를 DAG 인스턴스를 만들 때 에러 콜백으로 지정
Airflow Web UI에 변수 추가
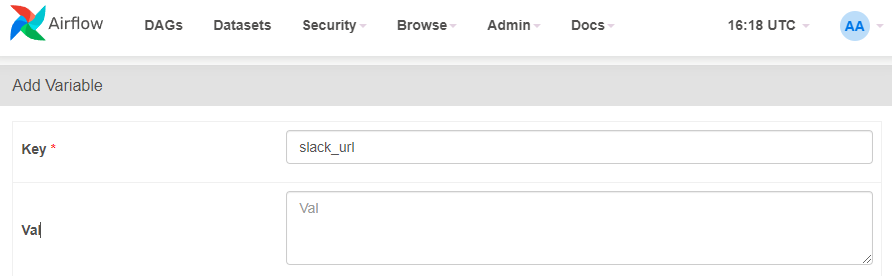
slack.py
중요한 점은 on_failure_callback에 에러 메세지를 전송 받고 싶은 dags의 task들이 지정이 되어야한다는 것입니다.
from airflow.models import Variable
import logging
import requests
def on_failure_callback(context):
# context로 주어진 인자에서 지금 실행된 task가 무엇인지
# 즉, 문제가 생긴 task가 무엇인지 추가
text = str(context['task_instance'])
# task가 실행이 될때 무슨 에러가 발생했는지 주석으로 추가
text += "```" + str(context.get('exception')) +"```"
# text를 slack으로 전송, ":scream:"은 이미지
send_message_to_a_slack_channel(text, ":scream:")
# def send_message_to_a_slack_channel(message, emoji, channel, access_token):
def send_message_to_a_slack_channel(message, emoji):
# 지정해둔 slack_url을 호출하여 붙임
url = "https://hooks.slack.com/services/"+Variable.get("slack_url")
headers = {
'content-type': 'application/json',
}
data = { "username": "data-alert", "text": message, "icon_emoji": emoji }
# slack으로 전송
r = requests.post(url, json=data, headers=headers)
return r
DAG 인스턴스를 만들 때 에러 콜백으로 지정
ex)
dag = DAG(
dag_id = 'name_gender_v4',
start_date = datetime(2023,4,6),
schedule = '0 2 * * *',
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 모든 task가 실패할 때마다 slack에 에러메세지 전송
'on_failure_callback': slack.on_failure_callback,
}
)임의로 Error를 발생시키고 확인
docker ps
# airflow-schduler shell 실행
docker exec -it airflow_scheduler_name sh
# Error가 발생할 예정인 dag 실행
(airflow)airflow dags test name_gender_v4 2023-06-09
Slack으로 Error 메세지가 전송된 것을 확인할 수 있습니다.

