✏️ 오늘 학습한 내용
1. Dag Dependencies
2. Sensor & Extra Dag Dependencies
3. Task Grouping
🔎 Dag Dependencies
📃 Dag를 실행하는 방법
-
주기적으로 실행하는 방법
( schedule로 지정 ) -
다른 Dag에 의해 트리거되는 방법
-
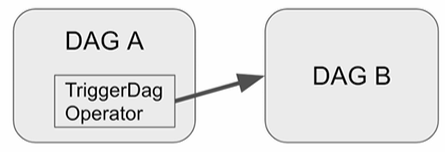
Explicit Trigger : Dag A가 명시적으로 Dag B를 트리거
->TriggerDagOperator -
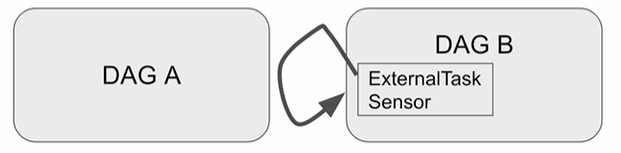
Reactive Trigger : Dag B가 Dag A의 태스크가 끝나기를 기다림
( DAG A는 이 사실을 알 수 없음 )
->ExternalTaskSensor
-
-
Task level의 방법들
-
조건에 따라 다른 태스크로 분기
( 지금 상황에 맞추어 어떤 태스크를 실행할 지 동적으로 결정 )
BranchPythonOperator -
과거 데이터 Backfill시 불필요한 태스크는 실행하지 않음
( 테스크가 실행이 될때 그 시점을 따져보고 과거의 데이터를 Backfill하기 위해 사용된다고 판단되면 실행이 중단됨 )
LatestOnlyOperator -
Trigger Rule
일반적으로, 앞단의 테스크들이 모두 성공해야 뒷단의 테스크들이 실행됩니다.
그러나 앞단의 실패 여부와 상관없이 무조건 태스크를 실행하기를 원하거나 앞단의 태스크가 하나라도 성공했을 때 실행하기를 원한다는 등등,
Trigger하는 규칙이 융통성이 있어야하는 때가 존재합니다.
-
TriggerDagOperator
DAG A의 태스크를 TriggerDagRunOperator로 구현
ex)
### DAG A
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
trigger_B = TriggerDagRunOperator(
task_id="trigger_B",
trigger_dag_id="트리거하려는DAG이름"
)
TriggerDagOperator의 Reference를 보면,
(templated)로 표기된 파라미터들이 있습니다.
이 파라미터들은 Template을 지원하기 때문에
Jinga Template 표현을 통해 시스템 변수 등을 사용할 수 있습니다.
-
trigger_dag_id : Trigger 대상이 되는 Dag의 id
-
conf : Trigger 대상이 되는 Dag에게 넘겨주는 정보 (Dictionary)
-
logical_date(=execution_date) : Trigger 대상이 되는 Dag에게 넘겨주는 날짜 정보
ex)
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
trigger_B = TriggerDagRunOperator(
task_id="trigger_B",
trigger_dag_id="Trigger 대상이 되는 Dag 이름",
conf={ 'path': '/opt/ml/conf' },
execution_date="{{ ds }}", # Jinja 템플릿을 통해 DAG A의 execution_date을 전달
reset_dag_run=True, # True일 경우 해당 execution_date에 해당하는 날짜에 실행되었던 기록이 있더라도 다시 재실행
wait_for_completion=True # DAG B가 끝날 때까지 기다릴지 여부를 결정. 디폴트값은 False
)여기서 conf로 전달한 정보를 Trigger 대상이 되는 dag에서 읽으려면?
( 필수 조건 :airflow.cfg의 dag_run_conf_overrides_params=True가 설정되어 있어야함 )
Trigger 대상이 되는 dag가 PythonOperator를 사용하는 경우
kwargs['dag_run'].conf.get('path')이런 식으로 접근 가능값을 받는 파라미터가 Template 형식을 지원하는 경우
Jinja템플릿{{ dag_run.conf["path"] }}이런 식으로 접근 가능
Jinja Template이란?
-
Jinja 템플릿은 Python에서 많이 사용되는 템플릿 엔진
-
Django 템플릿 엔진에서 영감을 받아 개발
-
Jinja를 사용하면 프레젠테이션 로직(사람 눈에 보이는 것, HTML)과 애플리케이션 로직(비즈니스 로직)을 분리하여 동적으로 HTML 생성
Jinja 템플릿을 사용함으로써 단순히 프레젠테이션 레이어에 속하는 HTML에 변수 및 로직을 넣어 다양한 형태의 케이스를 동적으로 처리할 수 있습니다.
-
Flask에서 사용됨
-
-
변수는 이중 중괄호
{{}}로 감싸서 사용 가능
ex)<h1>hi, {{name}}!</h1> -
제어문은 퍼센트 기호
{% %}로 표시<ul> {% for item in items %} <li>{{item}}</li> {% endfor %} </ul>
Jinja Template + Airflow
-
Airflow에서 Jinja 템플릿을 사용하면 작업 매개변수를 템플릿화된 문자열로 정의 가능
-
작업 매개변수 : 작업 이름, 파라미터 또는 SQL 쿼리와 같은 변수
-
이를 통해 재사용 가능하고 사용자 정의 가능한 워크플로우를 생성
-
Jinja Template의 사용되는 예시)
-
execution_date와 같은 태스크를 실행할 때 주어지는 파라미터를 쉽게 reference 가능 -
Airflow variables 및 connections 정보도 쉽게 읽을 수 있음
-
Task의 이름, Dag의 이름을 액세스 가능
-> 이러한 코딩을 통해 추출해야하는 작업들을 Jinja Template을 통해 쉽게 액세스할 수 있음
-
-
ex 1) execution_date - {{ ds }}
ds : execution_date과 동일하게 계산된 날짜 변수
# BashOperator를 사용하여 템플릿 작업 정의
# Jinja Template을 어디에서나 사용할 수 있는 것은 아님
# BashOperator 같은 경우는 bash_command에서 사용 가능!
task1 = BashOperator(
task_id = 'task1',
bash_command='echo "{{ ds }}"',
dag = dag
)ex 2) 파라미터로 받은 변수 사용
task2 = BashOperator(
task_id='task2',
bash_command='echo "안녕하세요, {{ params.name }}!"',
params={'name': 'John'}, #
dag=dag
)Airflow에서 사용 가능한 Jinja 변수
참조 : https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
-
{{ ds }}
->execution_date의 연도월일에 중간에 '_'를 두고 읽어옴 -
{{ ds_nodash }}
->execution_date의 연도월일에 중간에 '_'를 제거하고 읽어옴 (8자리) -
{{ ts }}
->execution_date에 연도월일 + 시분초 (timestamp) -
{{ dag }} -
{{ task }} -
{{ dag_run }} -
{{ var.value }}: {{ var.value.get('my.var', 'fallback') }}
-> 저장된 값이 json이 아닐 때, 읽고 싶은 variable이 있어옴, 존재하지 않을 경우 fallback을 반환 -
{{ var.json }}: {{ var.json.my_dict_var.key1 }}
-> 저장된 값이 json일 때, variable 값의 key를 지정 -
{{ conn }}: {{ conn.my_conn_id.login }}, {{ conn.my_conn_id.password }}
ex)
bash_command='echo "{{ ds }}"'
# 결과 : 2024-06-08
bash_command="""echo "{{ dag }},{{ var.value.get('csv_url') }}" """
# 결과 : <DAG: dag_name>, https://s3.../name_gender.csv 🔎 Sensor & Extra Dag Dependencies
Sensor란?
Sensor는 특정 조건이 충족될 때까지 대기하는 Operator입니다.
Sensor는 외부 리소스의 가용성이나 특정 조건을 완료할 때와 같은 상황 동기화에 유용한 편입니다.
Airflow는 몇 가지 내장 Sensor를 제공하고 있습니다.
- FileSensor: 지정된 위치에 파일이 생길 때까지 대기
- HttpSensor: HTTP 요청을 수행하고 지정된 응답이 대기
- SqlSensor: SQL 데이터베이스에서 특정 조건을 충족할 때까지 대기
- TimeSensor: 특정 시간에 도달할 때까지 워크플로우를 일시 중지
- ExternalTaskSensor: 다른 Airflow DAG의 특정 작업 완료를 대기
( DAG와 연관되어 사용하는 Sensor )
이러한 Sensor들의 동작 방식은 2가지 방식이 있습니다. ( poke, reschedule )
mode의 값은 reschedule 혹은 poke가 되는데 기본 값은 poke입니다.
reschedule와 poke 모두 주기적으로 파일이 있는지 체크를 합니다.
-
poke
기본적으로 Worker를 하나 붙잡고 그 Worker에서 체크 한번하고 Sleep해서 기다렸다가 체크 한번 하는 방식단, 이 방법은 Sensor를 사용할 때, Worker 하나가 Sensor에 전담이 되기 때문에 Worker가 낭비되는 느낌이 강합니다.
-
reschedule
Worker를 하나 잡아서 체크해보고 Worker를 릴리스하고 다시 잡아서 체크하는 방식즉, reschedule가 Worker의 utilization 측면에서 보다 유리하다고 볼 수 있습니다.
단, Sleep 이후에 Worker를 다시 잡을 수 있을지가 명확하지가 않다는 단점이 존재합니다.
( 상황에 따라 늦게 잡힐 수 있음 )
정리하자면,
poke를 사용하면 체크 주기를 명확하게 잡을 수 있고,
reschedule을 사용하면 Worker의 utilization 측면을 보완할 수 있습니다.
ExternalTaskSensor
ExternalTaskSensor는 위에서 다뤘듯이
DAG A, B가 있다고 가정할 때,
DAG B의 ExternalTaskSensor 태스크가 DAG A의 특정 태스크가 끝났는 지 체크하는 센서입니다.
단, 조건이 있습니다.
( 조건 )
- DAG가 서로 동일한 schedule_interval을 사용해야합니다.
- ExternalTaskSensor 태스크와 특정 태스크 모두 Execution Date이 동일해야합니다.
이 조건들을 하나라도 만족하지 못하면 매칭이 되지 않기 때문에 사용하기 까다롭다고 볼 수 있습니다.
또한, ExternalTaskSensor는 일반적으로 poke 모드를 많이 사용하기 때문에 Worker 하나가 낭비된다는 단점도 있습니다.
( 따라서, 그렇게 사용이 추천되는 Sensor는 아닙니다. )
사용 예제 )
from airflow.sensors.external_task import ExternalTaskSensor
waiting_for_end_of_dag_a = ExternalTaskSensor(
task_id='waiting_for_end_of_dag_a',
external_dag_id='DAG이름',
external_task_id='end',
timeout=5*60, # 5분마다 체크
mode='reschedule' # 5분마다 worker를 잡고 릴리스 함
)BranchPythonOperator
BranchPythonOperator는 뒤에 Trigger해야할 Task가 여러개 있는 경우, 상황에 따라서 그 중에 일부만 Trigger하는 Operator입니다.
-> 상황에 따라 뒤에 실행되어야할 태스크를 동적으로 결정해주는 오퍼레이터
미리 정의되지 않은 태스크를 아무 제약 없이 실행할 수 있는 것이 아니라,
미리 정의된 태스크들을 선택하여 실행하도록 동적으로 결정할 수 있는 기능
TriggerDagOperator 앞에 이 Operator를 사용하는 경우도 있습니다.
사용 예제 )
from airflow.operators.python import BranchPythonOperator
# 상황에 따라 뒤에 실행되어야 하는 태스크를 리턴
# 상황 :
# "mode"라는 Variable의 값이 "dev"이면
# trigger_b 태스크를 스킵
def skip_or_cont_trigger():
if Variable.get("mode", "dev") == "dev":
return []
else:
return ["trigger_b"]
branching = BranchPythonOperator(
# BranchPythonOperator도 Task
task_id='branching',
# 실행할 함수를 정의
python_callable=skip_or_cont_trigger,
)다른 예제)
현재 시간을 기준으로 특정 task가 종료되면
12시 전이면 morning_task로, 12시 후면 afternoon_task로 브랜치
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.operators.python import BranchPythonOperator
from datetime import datetime
default_args = {
'start_date': datetime(2023, 1, 1)
}
dag = DAG(
'Learn_BranchPythonOperator',
schedule='@daily',
default_args=default_args)
def decide_branch(**context):
current_hour = datetime.now().hour
print(f"current_hour: {current_hour}")
if current_hour < 12:
return 'morning_task'
else:
return 'afternoon_task'
branching_operator = BranchPythonOperator(
task_id='branching_task',
python_callable=decide_branch,
dag=dag
)
morning_task = EmptyOperator(
task_id='morning_task',
dag=dag
)
afternoon_task = EmptyOperator(
task_id='afternoon_task',
dag=dag
)
branching_operator >> morning_task
branching_operator >> afternoon_taskLatestOnlyOperator
LatestOnlyOperator는 Time-sensitive한 태스크들이 과거 데이터의 backfill시 실행되는 것을 막기 위한 Operator입니다.
태스크들 중에는 Time-sensitive한 태스크들이 있습니다.
예를 들어,
incremental하게 어제 데이터를 읽어와서 이를 바탕으로 뉴스레터를 보낸다던지 등 처리를 한다고 했을 때,
incremental update이므로 데이터 이슈가 있는 경우, Backfill을 해줘야합니다.
그런데 Backfill을 할 때마다 뉴스레터를 보내게된다면 문제가 됩니다.
( 뉴스레터같은 경우는 전송 시점이 중요한 것이기 때문에 과거의 뉴스레터를 또 보내는 것은 사용자에게 불편함만 주는 일이기 때문 )
이를 막기 위해 LatestOnlyOperator를 중간에 놔두면 현재 시간을 기준으로 운영이 되려고 호출이 되는 경우에만 뒤로 넘깁니다.
즉, 현재 시간보다 과거의 데이터로 호출이 된 경우에는 Operator가 실행되는 지점에서 작업을 중단합니다.
( Incremetal Update -> LatestOnlyOperator -> Time-sensitive한 작업 )
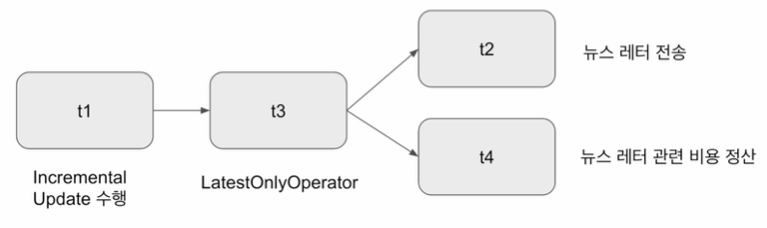
현재 시간이 지금 태스크가 처리하는 execution_date보다 미래이고 다음 execution_date보다는 과거인 경우에만 뒤로 실행을 이어가고 아니면 여기서 중단됨
from airflow import DAG
from airflow.operators.latest_only import LatestOnlyOperator
from airflow.operators.empty import EmptyOperator
from datetime import datetime
from datetime import timedelta
with DAG(
dag_id='latest_only_example',
schedule=timedelta(hours=48), # 매 48시간마다 실행되는 DAG로 설정
start_date=datetime(2023, 6, 14),
catchup=True) as dag: # catchup을 활성화하여 과거 날짜들의 Backfill이 실행되게끔 만듬
t1 = EmptyOperator(task_id='task1')
t2 = LatestOnlyOperator(task_id = 'latest_only')
t3 = EmptyOperator(task_id='task3')
t4 = EmptyOperator(task_id='task4')
t1 >> t2 >> [t3, t4]Trigger Rules
지금까지의 살펴본 Operator들은 보통 앞의 Task가 실패하면 뒤의 Task가 실행이 되지 않습니다.
그러나 앞의 Task가 실패해도 뒤의 Task가 무조건 실행되야하는 경우도 있기 때문에,
그 경우 Operator가 가진 Trigger Rules이란 파라미터를 사용합니다.
즉, Upstream 태스크의 성공,실패 상황에 따라 뒷단 태스크의 실행 여부를 결정하고 싶은 경우 trigger_rule 파라미터를 사용
trigger_rule는 태스크에 주어지는 파라미터로 다음과 같은 값이 가능합니다.
-
all_success(default) :
모든 Upstream 태스크가 성공해야 뒷단의 태스크를 실행 -
all_failed :
모든 Upstream 태스크가 실패해야 뒷단의 태스크를 실행 -
all_done :
모든 Upstream 태스크가 성공이든 실패든 무관하게 종료되면 뒷단의 태스크를 실행 -
one_failed :
하나라도 앞의 태스크가 실패하면 뒷단의 태스크를 실행 -
one_success :
하나라도 앞의 태스크가 성공하면 뒷단의 태스크를 실행 -
none_failed :
모든 태스크들이 모두 성공하거나 스킵되는 경우 (실패하지 않는 경우) 뒷단의 태스크를 실행 -
none_failed_min_one_success :
아무것도 실패하지 않은 상태에서 태스크가 하나라도 성공하면 뒷단의 태스크를 실행
사용 예시
# TriggerRule을 사용하기 위해 import
from airflow.utils.trigger_rule import TriggerRule
with DAG("trigger_rules", default_args=default_args, schedule=timedelta(1)) as dag:
t1 = BashOperator(task_id="print_date", bash_command="date")
t2 = BashOperator(task_id="sleep", bash_command="sleep 5")
t3 = BashOperator(task_id="exit", bash_command="exit 1")
t4 = BashOperator(
task_id='final_task',
bash_command='echo DONE!',
trigger_rule=TriggerRule.ALL_DONE
# 모든 태스크가 성공 여부와 무관하게 종료되면 t4를 실행
)
[t1, t2, t3] >> t4🔎 Task Grouping
태스크 그룹핑의 필요성
태스크 수가 많은 DAG라면 태스크들을 성격에 따라 관리하고 싶은 니즈가 분명 생길 것입니다.
예전에는 SubDAG라는 것으로 사용되다가 Airflow 2.0에서 Task Grouping이 나와 이를 통해 태스크들을 한번에 관리할 수 있게되었습니다.
예시

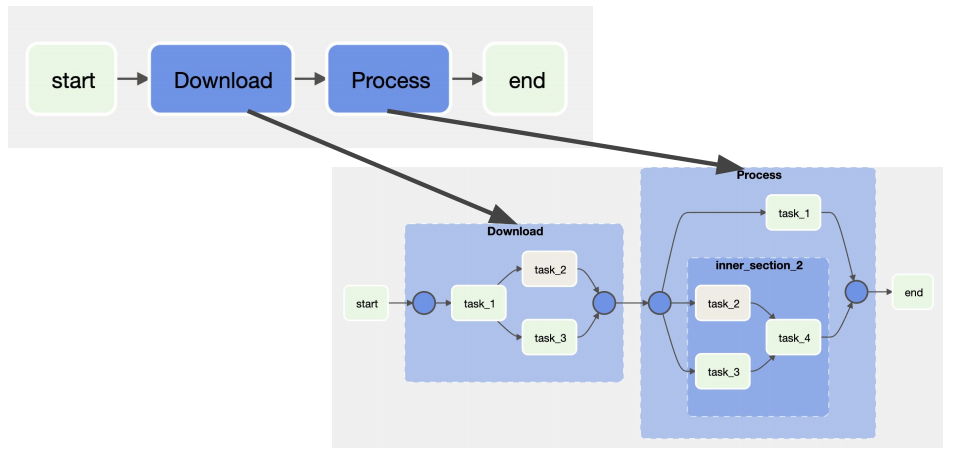
위 그림과 같이 다수의 파일을 처리하는 DAG가 있다고 했을 때,
Task Grouping을 통해 파일 다운로드 태스크들과 데이터 처리 태스크들을 각각 성격이 같은 그룹으로 묶어줄 수 있습니다.
TaskGroup은 TaskGroup 안에 Task Group nesting을 할 수 있습니다.
TaskGroup도 태스크처럼 실행 순서를 정의할 수 도 있습니다.
from airflow.models.dag import DAG
from airflow.operators.empty import EmptyOperator
from airflow.operators.bash import BashOperator
from airflow.utils.task_group import TaskGroup
import pendulum
with DAG(dag_id="Learn_Task_Group", start_date=pendulum.today('UTC').add(days=-2), tags=["example"]) as dag:
# start라는 이름의 operator 생성
start = EmptyOperator(task_id="start")
# section1이라는 TaskGroup을 생성
# 하나의 태스크 처럼 실행
with TaskGroup("Download", tooltip="Tasks for downloading data") as section_1:
task_1 = EmptyOperator(task_id="task_1")
task_2 = BashOperator(task_id="task_2", bash_command='echo 1')
task_3 = EmptyOperator(task_id="task_3")
task_1 >> [task_2, task_3]
# Task Group #2
with TaskGroup("Process", tooltip="Tasks for processing data") as section_2:
task_1 = EmptyOperator(task_id="task_1")
# TaskGroup nesting
with TaskGroup("inner_section_2", tooltip="Tasks for inner_section2") as inner_section_2:
task_2 = BashOperator(task_id="task_2", bash_command='echo 1')
task_3 = EmptyOperator(task_id="task_3")
task_4 = EmptyOperator(task_id="task_4")
[task_2, task_3] >> task_4
end = EmptyOperator(task_id='end')
# 태스크 처럼 사용
start >> section_1 >> section_2 >> end