✏️ 오늘 학습한 내용
1. Spark 데이터 처리
2. Spark 데이터 구조
3. Spark 프로그램
4. Spark 개발 환경
🔎 Spark 데이터 처리
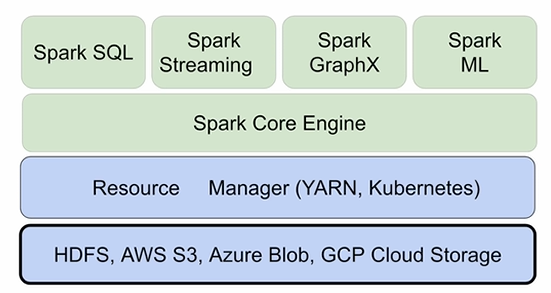
Spark 데이터 시스템 아키텍처
Spark는 별도로 파일 시스템을 가지고 있지 않기에
기존의 분산 파일 시스템을 사용합니다.
( HDFS, AWS S3, Azure Blob, ... )
데이터가 사용하는 분산 파일 시스템 내부에 있다면,
이미 최적화가 되어있기에 문제가 없지만
외부 데이터(관계형 DB, NoSQL)같은 경우에는
주기적으로 ETL을 통해서 내부로 옮겨서 처리하거나
혹은
Direct로 처리하는 방법이 있습니다.
데이터 병렬처리가 가능하려면?
-
조건 : 데이터가 먼저 분산되어야함
-
하둡 Map의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128MB)
hdfs-site.xml에 있는dfs.block.size프로퍼티가 이를 결정
-
Spark에서는 이 분산 과정을 파티션 (Partition)이라 부름
( 파티션의 기본크기 : 128MB )spark.sql.files.maxPartitionBytes로 파티션의 크기를 조정 가능,
단, HDFS에서 읽어오는 입력 데이터에만 적용됨
-
-
분산된 데이터를 각각 따로 동시(병렬) 처리
-
MapReduce의 경우,
N개의 데이터 블록으로 구성된 파일 처리시 N개의 Map 태스크가 실행 -
Spark의 경우,
Partition 단위로 메모리에 로드되어 Executor가 배정됨
-
데이터 분산 -> 파티션 -> 병렬 처리
-
HDFS의 데이터 처리
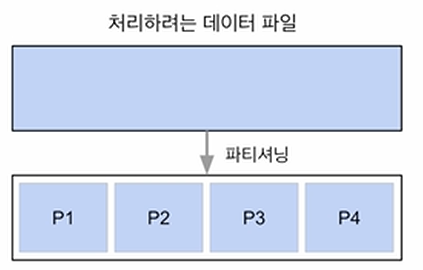
파티셔닝 방법은 데이터 소스에 따라 달라집니다.
위의 경우는 HDFS 상의 데이터 처리로 파티션이 4개가 만들어졌지만,
MySQL, PostgreSQL 등에서 데이터를 읽어야한다면 JDBC에 연결을 해야합니다. 이 경우, 기본적으로 하나의 파티션만 만들어집니다.
-
병렬 처리
Spark의 Executor가 2개라면,
동시에 실행 가능한 최대 태스크의 수가 2개
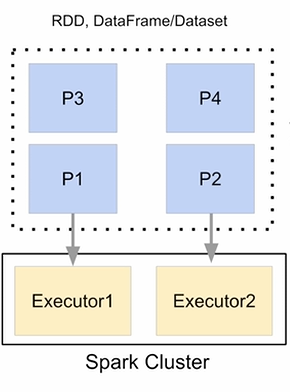
-
병렬성을 최대화 하려면?
적절한 파티션의 수 = Executor의 수 x Executor 당 CPU의 수
Spark 데이터 처리 흐름
-
데이터프레임은 작은 파티션들로 구성됨
-
데이터프레임은 한번 만들어지면 수정 불가
(Immutable)
-> 수정을 하려면 새로 만들어야함 -
입력 데이터프레임을 원하는 결과를 도출 할때까지 다른 데이터 프레임으로 계속 변환하는 방식
( sort, group by, filter, map, join, ... )
-
데이터 프레임은 파티션의 집합,
각 파티션은 하나의 executor 안의 태스크가 처리
-> 병렬성 유지이 과정이 빠를 것 같지만 이 모든 작업이 파티션 간의 데이터 이동 없이는 이루어질 수 없습니다.
Map이나 Filter 같은 경우는 파티션 안의 데이터 만으로 충분한 Operation이기 때문에 데이터의 서버 간 이동이 필요없지만,
Sort 혹은 Group By를 하는 경우는 새로운 파티션이 만들어져야하므로 서버 간 데이터의 이동이 필수적입니다.
📃 Suffling이란?
기존의 파티션만으로는 안되서 새로운 파티션을 만들고,
그에 맞게 데이터의 이동이 이뤄져 네트워크 송수신이 발생하는 것을 뜻합니다.
-
셔플링이 발생하는 경우는?
-
명시적으로 파티션 수를 바꾸는 경우
(예: 파티션 수를 줄이기) -
시스템에 의해 이뤄지는 셔플링
- 개발자가 데이터프레임에 적용하는 오퍼레이션의 특징에 따라 새로운 파티션을 만들어야하는 경우
- ex) Group By, Sort
-
-
셔플링이 발생할 때 네트워크을 타고 데이터가 이동
-
몇 개의 파티션이 결과로 만들어질까?
-
spark.sql.shuffle.partitions에 의해 결정
(default : 200, 최대 파티션 수) -
오퍼레이션에 따라 파티션 수가 결정
ex) random, hashing partition, range partition 등-> sorting의 경우 range partition을 사용
-
-
-
Range Partitioning의 동작 방식
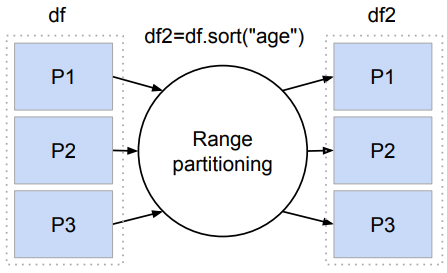
데이터프레임의 key값 "age"의 분포를 확인,
Sampling을 통해 분포를 확인하고 그 Range에 맞추어 파티션을 새로 생성 (최대 200개)예를 들어, 3개의 파티션이 만들어졌다고 하면
Sampling을 통해 확인한 분포대로 데이터를 분배이때, Sampling을 잘못되었다면 Data Skew가 발생!
( 특정 파티션에 데이터가 치우치는 현상 발생 )
Suffling : hashing partition
Hashing partition은 Group By와 같은
Aggregation 오퍼레이션을 사용할 때 사용됨!
- Aggregation 오퍼레이션
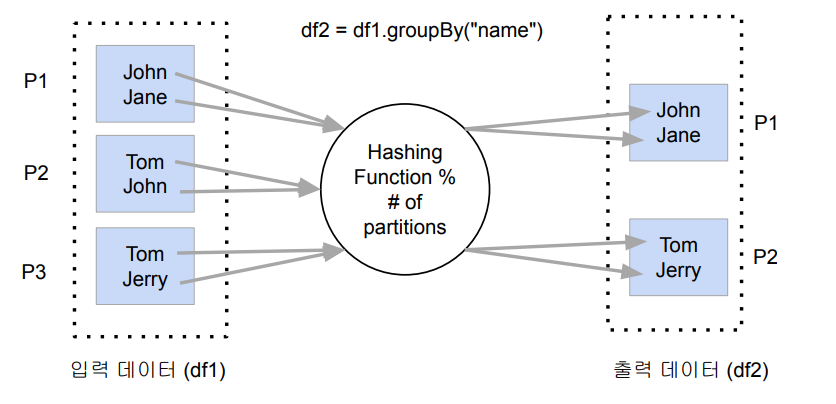
name 필드를 Key 값으로 Hashing Function에 넘기면,
그 결과를 파티션의 수로 나누어 그 나머지에 맞는 번호로 파티션에 전달예를 들어, "John Jane"의 해시 결과를 2(=파티션의 수)로 나누어 1이 나왔다면? -> P1 파티션으로 전달
Data Skewness
-
Data partitioning은 데이터 처리에 병렬성을 주지만 단점도 존재
-
이는 데이터가 균등하게 분포하지 않는 경우 (Data skew)
- 주로 데이터 셔플링 후에 발생
-
셔플링을 최소화하는 것이 중요하고 파티션 최적화를 하는 것이 중요
-
( 셔플링을 많이하면 Data Skew로 인해 성능이 낮아질 가능성이 높아짐 )
🔎 Spark 데이터 구조
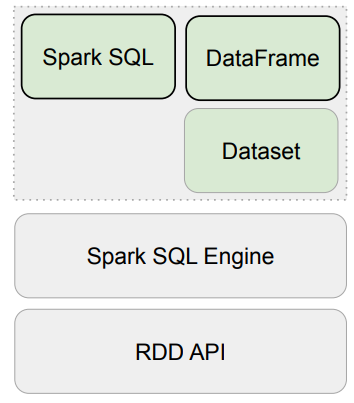
RDD, DataFrame, Dataset
-
DataFrame과 Dataset은 하나의 API
-
모두 파티션으로 나뉘어 Spark에서 처리됨
📃 Spark 데이터 구조
-
RDD (Resilient Distributed Dataset)
-
low 레벨 데이터로 클러스터 내의 서버에 분산된 데이터를 지칭
-
레코드별로 존재하지만 스키마가 존재하지 않음
-> 구조화된 데이터나 비구조화된 데이터 모두 지원
-
-
DataFrame과 Dataset
-
RDD API 위에 만들어짐,
RDD와는 달리 필드 정보를 갖고 있음 (테이블) -
Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용가능
- 컴파일 언어: Scala/Java에서 사용가능
-
PySpark에서는 DataFrame을 사용
-
-
Spark SQL Engine의 역할
작성한 DataFrame 혹은 Spark SQL 코드를 RDD 오퍼레이션으로 만들고, 최종적으로 JVM 코드로 만드는 것
- Code Analysis
( 어떤 컬럼에 어떤 테이블이 쓰이는지 결정 ) - Logical Optimization ( Catalyst Optimizer )
( 이 코드를 실행할 수 있는 여러 방안 생성,
Catalyst Optimizer : 방안들 마다의 비용 계산 및 파악 ) - Physical Planning
( 비용이 가장 싼 방안을 골라 코드를 RDD 오퍼레이션으로 작성 ) - Code Generation (ProjectTungsten )
( 코드를 JVM으로 변경, ProjectTungsten 컴파일 기술을 사용하여 코드를 더 최적화 )
- Code Analysis
Spark 데이터 구조 - RDD

-
변경이 불가능한 분산 저장된 데이터
- RDD는 다수의 파티션으로 구성
- low 레벨의 함수형 변환 지원 (map, filter, flatMap 등등)
-
일반 파이썬 데이터는 parallelize 함수로 RDD로 변환
- RDD -> Python : collect로 파이썬 데이터로 변환가능
( 데이터가 큰 경우 에러 발생 )
- RDD -> Python : collect로 파이썬 데이터로 변환가능
Spark 데이터 구조 - 데이터 프레임
-
변경이 불가한 분산 저장된 데이터
-
RDD와는 다르게 관계형 데이터베이스 테이블처럼 컬럼으로 나눠 저장
-
Pandas의 데이터 프레임 혹은 관계형 데이터베이스의 테이블과 거의 유사
-
다양한 데이터소스 지원:
HDFS, Hive, 외부 데이터베이스, RDD 등등
-
-
스칼라, 자바, 파이썬과 같은 언어에서 지원
🔎 Spark 프로그램
Spark Session 생성
Spark 프로그램의 시작은 SparkSession을 만드는 것입니다.
Spark Cluster와 통신할 수 있는 EntryPoint 역할을 수행합니다.
한 프로그램 내에 하나만 만들면 되는 Singleton 객체
-
Spark Session을 통해 Spark이 제공해주는 다양한 기능을 사용 가능
-
DataFrame, SQL, Streaming, ML API
모두 이 Spark Session으로 통신 가능 -
config 메소드를 이용해 다양한 환경설정 가능
-
단, RDD와 관련된 작업을 할때는 SparkSession 밑의
sparkContext객체를 사용
-
Spark 세션 생성 - PySpark 예제
# pyspark.sql
# -> Spark SQL Engine이 중심으로 동작
from pyspark.sql import SparkSession
spark = SparkSession.builder\
# 어떤 리소스(Cluster) 매니저를 사용하는지 지정
# 이 경우, local standalone 모드로 동작하는 Spark Cluster를 사용
# * : CPU의 수, 최대치 사용
.master("local[*]")\
# Spark 프로그램의 이름을 지정
.appName('PySpark Tutorial')\
# Spark Session이 Singleton이라는 증거
# Spark Session이 없으면 생성하고 있으면 그 존재하는 Session을 리턴
# 여러 번 사용한다고 해도 여러 개가 생기는 것이 아니라 하나가 공유되는 방식
.getOrCreate()
…
# Spark Cluster에서 요청했던 모든 리소스들이 리턴되고 종료
spark.stop()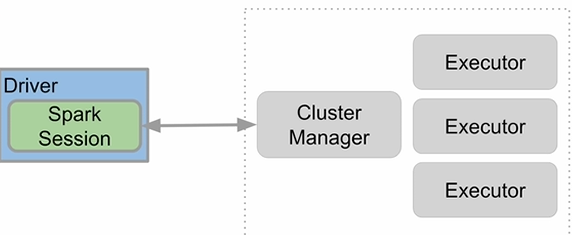
Spark Session 환경 변수
Spark Session을 만들 때 다양한 환경 설정이 가능합니다.
참조 : 공식문서
-
몇 가지 예시
-
executor별로 메모리를 할당하는 환경변수:
spark.executor.memory(기본값: 1g) -
executor별 CPU 수 할당:
spark.executor.cores(YARN에서는 기본값 1) -
driver 당 메모리 할당:
spark.driver.memory(기본값: 1g) -
Shuffle후 Partition의 수를 변경하고 싶은 경우:
spark.sql.shuffle.partitions(기본값: 최대 200)
-
-
사용하는 Resource Manager에 따라 환경변수가 많이 달라짐
-> 가능한 모든 환경변수 옵션
📃 Spark Session 환경 설정 방법 4가지
-
환경변수로 설정하는 방법
-
$SPARK_HOME/conf/spark_defaults.conf파일로 설정 하는 방법 -
spark-submit명령의 커맨드라인 파라미터 -
SparkSession을 만들때 지정
- SparkConf
이 4가지 방법 중 충돌시 우선순위는
아래일수록 높습니다.
SparkSession > spark-submit > ...
SparkSession 생성시 일일히 지정
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
# config라는 범용적인 메소드로 2개의 파라미터를 지정
# option : 환경 변수 이름, some-value : 환경 변수 값
.config("spark.some.config.option1", "some-value") \
.config("spark.some.config.option2", "some-value") \
.getOrCreate()SparkConf 객체에 환경 설정하고 SparkSession에 지정
from pyspark.sql import SparkSession
from pyspark import SparkConf
# SparkConf 객체 생성
conf = SparkConf()
# SparkConf에 환경설정 내용 담기
# .set(환경 변수 이름, 환경 변수 값)
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkConf 전달
spark = SparkSession.builder\
.config(conf=conf) \
.getOrCreate()전체적인 플로우
-
Spark 세션(SparkSession)을 만들기
( + 환경 설정 ) -
입력 데이터 로딩
( SparkSession API를 이용 ) -
데이터 조작 작업 (Pandas와 유사)
- DataFrame API나 Spark SQL을 사용
- 원하는 결과가 나올때까지 새로운 DataFrame을 생성
-
최종 결과 저장
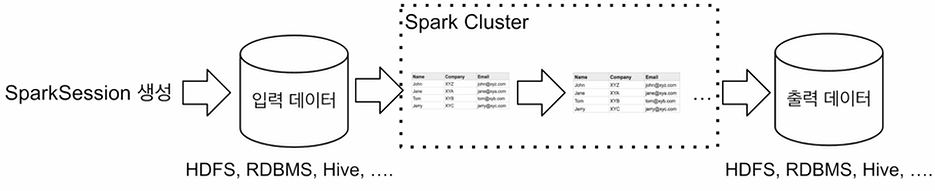
Spark Session이 지원하는 데이터 소스
-
spark.read를 사용하여 데이터프레임으로 로드
( DataFrameReader 인터페이스를 지원하는 경우 ) -
DataFrame.write을 사용하여 데이터프레임을 저장
( DataFrameWriter 인터페이스를 지원하는 경우 ) -
많이 사용되는 데이터 소스들
-
HDFS 파일
- CSV, JSON, Parquet, ORC, Text, Avro
- Parquet/ORC/Avro
- Hive 테이블
- CSV, JSON, Parquet, ORC, Text, Avro
-
JDBC 관계형 데이터베이스
-
클라우드 기반 데이터 시스템
-
스트리밍 시스템
( Kinesis, Kafka )
-
🔎 Spark 개발 환경
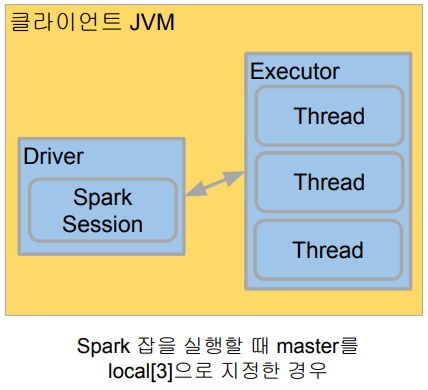
Local Standalone Spark
-
Spark Cluster Manager로 local[n] 지정
-
master를
local[n]으로 지정
( master로 리소스 매니저를 지정 가능, YARN으로 지정하면 YARN이 되고,local[n]으로 지정하면 현재 로컬 컴퓨터가 됨 ) -
master는 클러스터 매니저(리소스 매니저)를 지정하는데 사용
-
-
주로 개발이나 간단한 테스트 용도
-
하나의 JVM에서 모든 프로세스를 실행
-
하나의 Driver와 하나의 Executor가
실행됨 -
1+ 쓰레드가 Executor안에서 실행됨
-
-
Executor안에 생성되는 쓰레드 수
local: 하나의 쓰레드만 생성local[*]: 컴퓨터 CPU 수만큼 쓰레드를 생성
📃 구글 Colab에서 Spark 사용
-
PySpark + Py4J를 설치
-
구글 Colab 가상서버 위에 로컬 모드 Spark을 실행
-
개발 목적으로는 충분하지만 큰 데이터의 처리는 불가
-
Spark Web UI는 기본적으로는 접근 불가
-> ngrok을 통해 억지로 여는게 가능 -
Py4J
-> 파이썬에서 JVM내에 있는 자바 객체를 사용가능하게 해줌
-
!pip install pyspark==3.3.1 py4j==0.10.9.5
# 현재 CPU의 환경을 확인 (CPU 코어 수 등)
!lscpu
# 메모리 확인
!grep MemTotal /proc/meminfoRDD
name_list_json = [ '{"name": "keeyong"}', '{"name": "benjamin"}', '{"name": "claire"}' ]
# Python -> RDD로 변환
rdd = spark.sparkContext.parallelize(name_list_json)
import json
# JSON String 형태에서 JSON Structure로 파싱해서
# RDD를 하나 새로 생성
parsed_rdd = rdd.map(lambda el:json.loads(el))
# RDD -> Python
parsed_rdd.collect()
# 결과 : [{'name': 'keeyong'}, {'name': 'benjamin'}, {'name': 'claire'}]
parsed_name_rdd = rdd.map(lambda el:json.loads(el)["name"])
parsed_name_rdd.collect()
# 결과 : ['keeyong', 'benjamin', 'claire']DataFrame
from pyspark.sql.types import StringType
# py -> df
df = spark.createDataFrame(name_list_json, StringType())
# 모든 필드를 선택해서 df -> py
df.select('*').collect()
# rdd -> df
df_parsed_rdd = parsed_rdd.toDF()
# 예를 들어, grouby를 한다고 했을 때
# 단순히, df.groupby(["gender"]).count()만 한다면
# Spark 내부에서만 동작하기에 결과가 출력되지 않음
# .collect()로 Python으로 가져와야함
df.groupby(["gender"]).count().collect()
# df가 몇개의 Partition으로 구성되어있는지 확인
# df도 RDD에 속하기에 가능
df.rdd.getNumPartitions()SparkSQL
SparkSQL을 사용하기 위해선 데이터프레임들로 테이블을 만들어야합니다.
# df들로 테이블을 지정하는 함수
# df라는 데이터프레임을 테이블처럼 취급할 것이고
# 그 이름을 namegender로 지정
df.createOrReplaceTempView("namegender")
# SparkSQL로 sql문을 사용 가능
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1")
namegender_group_df.collect()
# 어떤 DF를 테이블로 사용이 가능한지 확인
spark.catalog.listTables()
# 파티션 수 확인
namegender_group_df.rdd.getNumPartitions()그 외 Spark 실습은 여기 Github를 참고하여 진행
