✏️ 오늘 학습한 내용
1. Spark SQL
2. JOIN, UDF
3. Hive 메타스토어 사용하기
4. 유닛 테스트
🔎 Spark SQL
Spark SQL이란?
-
Spark SQL은 구조화된 데이터 처리를 위한 Spark 모듈
-
데이터프레임 작업을 SQL로 처리 가능
-
데이터프레임에 테이블 이름을 지정한 후 sql함수 사용가능
-> 판다스에도pandasql모듈의sqldf함수를 이용하는 동일한 패턴이 존재함 -
HQL(Hive Query Language)과 호환 제공
-> Hive 테이블들을 읽고 쓸 수 있는 것이 가능 (Hive Metastore)
-
Spark SQL vs. DataFrame
SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없을 정도로
Spark SQL의 장점이 더 많습니다.
( 두 개를 동시에 사용할 수 있다는 점 )
-
Familiarity/Readability
( SQL이 가독성이 더 좋고 더 많은 사람들이 사용 가능 ) -
Optimization
( Spark SQL 엔진이 최적화하기 더 좋음 (SQL은 Declarative) )
-> Catalyst Optimizer와 Project Tungsten -
Interoperability(상호운용성)/Data Management
( SQL이 포팅도 쉽고 접근권한 체크도 쉬움 )
Spark SQL 사용법 - SQL 사용 방법
-
데이터 프레임을 기반으로 테이블 뷰를 생성
-
createOrReplaceTempView:
이를 통해 테이블 뷰를 생성하면 spark Session이 살아있는 동안 존재 -
createOrReplaceGlobalTempView:
테이블 뷰가 Spark 드라이버가 살아있는 동안 존재
-
-
Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
ex)
# namegender라는 이름의 테이블 뷰를 생성
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("""
SELECT gender, count(1) FROM namegender GROUP BY 1
""")
print(namegender_group_df.collect())SparkSession - 외부 데이터베이스와 연결
- Spark Session의 read 함수를 호출
( 로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정 )
-> 결과가 데이터 프레임으로 리턴됨
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://HOST:PORT/DB?user=ID&password=PASSWORD") \
# 테이블을 호출하는 부분에 SELECT 구문을 사용 가능
.option("dbtable", "raw_data.user_session_channel") \
.load()🔎 JOIN, UDF
📃 JOIN
-
SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 Merge
-
스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용
최적화 관점에서 본 JOIN의 종류들
데이터 셋의 크기가 큰 경우 파티션이 여러개로 구성이 될 것이고,
이 JOIN을 하는 Key를 바탕으로 Shuffling이 이루어질 텐데,
그 결과, 만들어지는 파티션에 skew가 발생할 것이기에 처리 시간도 오래 걸릴 것입니다.
( Shuffling을 최소화하는 것이 성능에서 중요! )
-
Shuffle JOIN
-
일반 조인 방식이 바로 Shuffle JOIN
-
Bucket JOIN :
JOIN 키를 바탕으로 새로 파티션을 미리 만들어 JOIN을 실행할 때,
Suffling이 발생하지 않도록 하는 방식
-
-
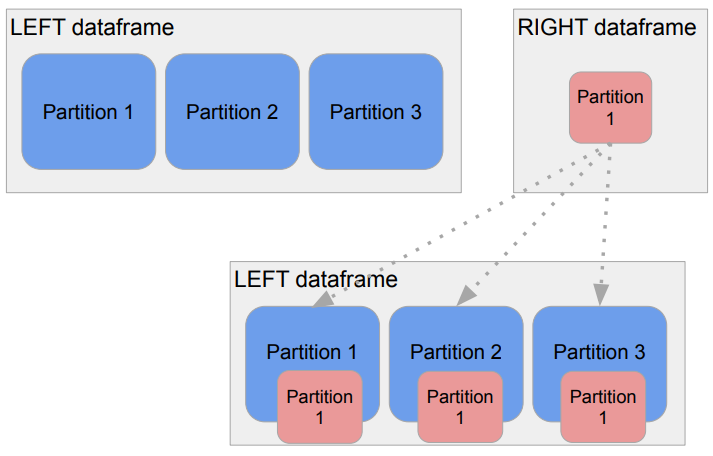
Broadcast JOIN
-
큰 데이터와 작은 데이터 간의 조인
( 테이플의 크기 차이가 심한 조인 )데이터프레임 하나가 충분히 작으면,
JOIN 키를 바탕으로 JOIN을 하는 것이 아니라
작은 데이터프레임 전체를 다른 데이터프레임이 있는 파티션들로 뿌리는 것
( broadcasting )
-> Suffling 없이 JOIN이 가능 -
작은 데이터프레임의 기준
->spark.sql.autoBroadcastJoinThreshold파라미터로 충분히 작은지 여부 결정
-
📃 UDF
UDF란?
-
UDF (User Defined Function)
-
DataFrame이나 SQL에서 적용할 수 있는 사용자 정의 함수
UDF 사용해보기
-
데이터프레임의 경우
.withColumn함수와 같이 사용하는 것이 일반적- Spark SQL에서도 사용 가능
-
Aggregation용 UDAF(User Defined Aggregation Function)도 존재
-
ex) GROUP BY에서 사용되는 SUM, AVG와 같은 함수를 만드는 것
-
PySpark에서는 지원되지 않음
( Scalar / Java를 사용해야함 )
-
UDF 예시 - DataFrame
import pyspark.sql.functions as F
from pyspark.sql.types import *
# pyspark의 udf 함수를 통해서 주어진 문자열을 대문자로 바꾸는 함수 등록
upperUDF = F.udf(lambda z:z.upper())
# df에 있는 "Name" 컬럼을 대문자로 바꾸는 "Curated Name" 컬럼을 추가
df.withColumn("Curated Name", upperUDF("Name"))
#------------------------------------------------
data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
# Direct로 함수 지정도 가능
# c = a+b라는 컬럼 추가
df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b"))UDF 예시 - SQL
# 대문자로 바꾸는 파이썬 함수
def upper(s):
return s.upper()
# spark.udf.register로 위에서 만든 함수를 등록,
# 그 이름이 "upper" -> spark.sql에는 이 이름으로 사용
# upperUDF는 DataFrame에서 .withColumn에 넣을 때 사용
upperUDF = spark.udf.register("upper", upper)
spark.sql("SELECT upper('aBcD')").show()
# DataFrame 기반 SQL에 적용
# SparkSQL에서 사용하기 위해
# test란 이름의 테이블 뷰로 생성
df.createOrReplaceTempView("test")
spark.sql("""SELECT name, upper(name) "Curated Name" FROM test""").show()
#------------------------------------------------
def plus(x, y):
return x + y
# UDF 생성
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2)").show()
# c = a+b 컬럼 추가
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) c FROM test").show()UDF 예시 - Pandas UDF Scalar 함수
위의 Python Lambda함수 혹은 일반 함수보다,
Pandas UDF로 만든 경우가 일일히 처리하지 않고 벌크로 처리하기 때문에 성능이 더 좋습니다.
from pyspark.sql.functions import pandas_udf
import pandas as pd
# pandas_udf라고 알림
@pandas_udf(StringType())
# pandas의 Series 타입으로 들어오고
# 처리 후, Series 타입으로 리턴
def upper_udf2(s: pd.Series) -> pd.Series:
return s.str.upper()
upperUDF = spark.udf.register("upper_udf", upper_udf2)
df.select("Name", upperUDF("Name")).show()
spark.sql("""SELECT name, upper_udf(name) `Curated Name` FROM test""").show()UDF 예시 - Pandas UDF Scalar - Aggregation
UDF의 Aggregation의 경우
PySpark에서는 지원되지 않으므로
Scalar/Java를 사용해야합니다.
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(FloatType())
# float 리턴
def average(v: pd.Series) -> float:
# pandas Series의 mean함수 사용
return v.mean()
averageUDF = spark.udf.register('average', average)
spark.sql('SELECT average(b) FROM test').show()
df.agg(averageUDF("b").alias("count")).show()spark session에 등록한 UDF 확인
for f in spark.catalog.listFunctions():
print(f[0])이 방법은 UDF뿐 아니라 Native function도 전부 출력
🔎 Hive 메타스토어
Spark 데이터베이스와 테이블
기본적으로 Spark에는 인메모리 카탈로그가 있습니다.
인메모리 카탈로그란?
Spark Session 하위에 존재하는 Catalog로,
Session이 사라지면 같이 사라집니다.
휘발성이 아닌 보존이 되는 디스크 기반의 테이블도 필요하기 때문에,
이 경우, Spark 테이블에 Hive의 메타스토어를 사용하게 되었습니다.
-
카탈로그
( 테이블과 뷰에 관한 메타 데이터 관리 )-
기본으로 메모리 기반 카탈로그 제공
-> 세션이 끝나면 사라짐 -
Hive와 호환되는 카탈로그 제공
-> Persistent
-
-
스토리지 기반 테이블
-
기본적으로 HDFS와 Parquet 포맷을 사용
-
Hive와 호환되는 메타스토어 사용
-
두 종류의 테이블이 존재 (Hive와 동일한 개념)
-
Managed Table
-> Spark이 실제 데이터와 메타 데이터 모두 관리 -
Unmanaged (External) Table
-> Spark이 메타 데이터만 관리
-
-
-
메타 데이터 예시)
- 테이블 이름
- 테이블 스키마
- 테이블 데이터 위치
- ...
Spark SQL - 스토리지 기반 카탈로그 사용 방법
-
Hive와 호환되는 메타스토어 사용
-
SparkSession 생성시
enableHiveSupport()호출
-> 기본으로 “default”라는 이름의 데이터베이스 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \
# default라는 이름의 데이터베이스가 생성됨 (=schema)
.enableHiveSupport() \
.getOrCreate()Spark SQL - Managed Table 사용 방법
성능이나 여러가지 측면에서 Managed Table이 좋기 때문에 가능하면 External Table 보다는 Managed Table을 사용하는 것이 좋습니다.
-
두 가지 테이블 생성방법
-
dataframe.saveAsTable("테이블이름")사용 -
SQL 문법 사용 (
CREATE TABLE, CTAS )
-
-
spark.sql.warehouse.dir가 가리키는 위치에 데이터가 저장됨- parquet이 기본 데이터 포맷
-
선호하는 테이블 타입
-
Spark 테이블(Managed Table)로 처리하는 것의 장점
- JDBC/ODBC 등으로 Spark을 연결해서 접근 가능 (태블로, 파워BI)
Spark SQL - External Table 사용 방법
-
이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용
LOCATION이란 프로퍼티 사용
-
메타데이터만 카탈로그에 기록됨
- 데이터는 이미 존재.
- External Table은 삭제되어도 데이터는 그대로임
( 실제 데이터는 Spark이 관리하지 않음 )
ex)
CREATE TABLE table_name (
column1 type1,
column2 type2,
column3 type3,
…
)
USING PARQUET
LOCATION 'hdfs_path';Managed Table 생성 예제
from pyspark.sql import SparkSession
# Session 생성과 동시에 스토리지 기반 카탈로그 사용
# 즉, 현재 spark은 Hive 메타스토어를 사용!
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \
.enableHiveSupport() \
.getOrCreate()
# 설치된 Database 확인
spark.sql("SHOW DATABASES").show()
# -> 결과는 default
# Database 추가
spark.sql("CREATE DATABASE IF NOT EXISTS TEST_DB")
# 이제 default Database는 TEST_DB로 지정
spark.sql("USE TEST_DB")
df = spark.read.csv("orders.csv", inferSchema=True, header=True, sep ='\t')
# df를 Managed Table로 생성
df.write.saveAsTable("TEST_DB.orders", mode="overwrite")
# Table 종류 확인 -> tableType="MANAGED"
spark.catalog.listTables()
# 혹은 CTAS로 Managed Table 생성
spark.sql("""
CREATE TABLE TEST_DB.orders_count AS
SELECT order_id, COUNT(1) as count
FROM TEST_DB.orders
GROUP BY 1""")🔎 유닛 테스트
-
코드 상의 특정 기능 (보통 메소드의 형태)을 테스트하기 위해 작성된 코드
-
보통 정해진 입력을 주고 예상된 출력이 나오는지 형태로 테스트
-
CI/CD를 사용하려면 전체 코드의 테스트 커버러지가 굉장히 중요해짐
-
각 언어별로 정해진 테스트 프레임웍을 사용하는 것이 일반적
JUnitfor JavaNUnitfor .NETunittestfor Python
커맨드라인에서 유닛 테스트 실행하는 명령어
python -m unittest 테스트_파일.py
