✏️ 오늘 학습한 내용
1. Spark 파일 포맷
2. Execution Plan
3. Bucketing과 File System
🔎 Spark 파일 포맷
Spark이 데이터를 처리한다면 일반적으로 HDFS에서 읽어오게 될텐데,
처리하려는 데이터가 어떤 파일 포맷으로 저장되어있는 지에 따라 성능에 큰 영향을 미칩니다.
( 비구조화, 반구조화, 구조화 )

Spark의 주요 파일 타입
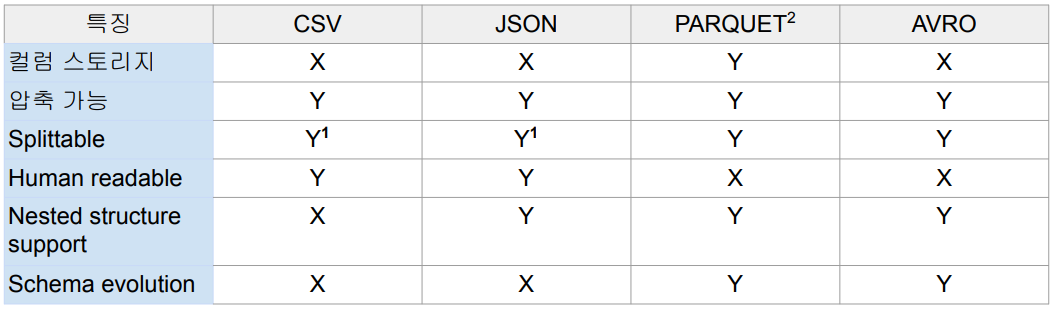
-
Splittable :
단, 압축이 가능하고 Splittable(블록 단위로 나누기)이 가능하다고 해도,
CSV와 JSON은 압축 후에는 Splittable하지 않습니다. -
Human readable :
PARQUET와 AVRO는 binary형식이기 때문에 사람이 직접 읽을 수는 없습니다. -
Schema evolution :
컬럼이 존재하지 않다가 새로운 컬럼이 생겨도 문제 없이 이런 파일을 사용할 수 있는 경우
Parquet (Spark의 기본 파일 포맷)
발음 : 팔퀘잇
- 기준 테이블
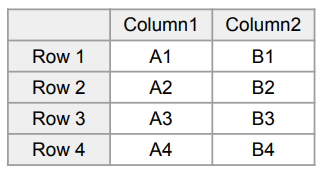
-
저장 방식
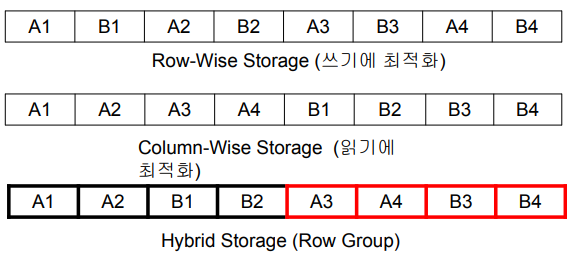
-
Row-Wise Storage
-> 레코드 순으로 저장 -
Column-Wise Storage
-> 컬럼 순으로 저장 -
Hybrid Storage (Row Group)
( 이게 Parquet 방식 )Row-Wise, Column-Wise의 각 강점을 동시에 가지는 관점에서 나온 저장 방식
데이터 블록 단위로 하나의 Row Group을 구성!
같은 Row Group 안에서는 Column-Wise로 저장즉, 정리하면
데이터 블록 단위로 저장하지만(row-wise),
그 데이터 블록 내부는 column-wise로 저장하는 방식
-
Schema Evolution 예시
다음과 같이 Parquet 파일 3개가 있다고 가정하겠습니다.
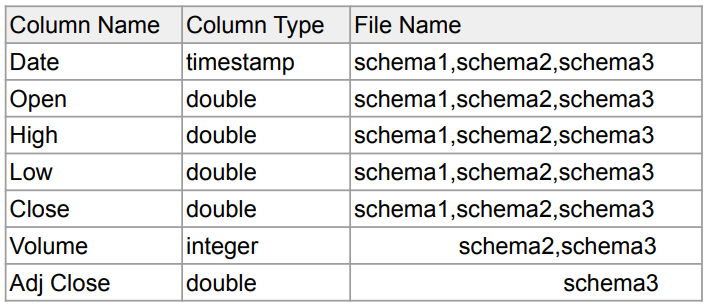
- schema1.parquet
- schema2.parquet
- schema3.parquet
이때, 가장 처음에 schema1으로 파일을 저장했다고 가정하고 다음으로 schema2,3을 저장했다고 가정하겠습니다.
CSV, JSON 같은 경우라면 schema2,3이 들어왔을 때 새로운 컬럼이 추가되야하므로 이를 처리하지 못하고 에러가 발생했을 것입니다.
그러나 Parquet은 Schema Evolution이 가능하므로 새로운 컬럼이 추가되도 문제 없이 저장이 됩니다.
AVRO 파일 읽어오는 예제 코드
from pyspark.sql import *
from pyspark.sql.functions import *
# Spark session 생성
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Spark Writing Demo") \
.master("local[3]") \
# Spark에서 기본 값으로 avro를 지원하지 않으므로
# config를 통해 별도 등록이 필요
.config("spark.jars.packages", "org.apache.spark:spark-avro_2.12:3.3.1") \
.getOrCreate()
# 파일 읽어오기
!wget https://pyspark-test-sj.s3.us-west-2.amazonaws.com/appl_stock.csv
df = spark.read \
.format("csv") \
.load("appl_stock.csv")
# 데이터프레임 내 partition 수 확인
# 초기 값이라 1개
df.groupBy(spark_partition_id()).count().show()
# partition 재실행
df2 = df.repartition(4)
df2.groupBy(spark_partition_id()).count().show()
# partition 줄이기
# ( Suffling을 최소화하는 방향으로 진행 )
df3 = df2.coalesce(2)
df3.groupBy(spark_partition_id()).count().show()
# 저장
df.write \
.format("avro") \
.mode("overwrite") \
.option("path", "dataOutput/avro/") \
.save()🔎 Execution Plan
Spark은 개발자가 만든 코드를 변환해서 실행합니다.
그 과정에서 Transformation, Action, ... 등이 수행되게 됩니다.
데이터 프레임 연산 예제
spark.read.option("header", True).csv(“test.csv”). \
where("gender <> 'F'"). \
select("name", "gender"). \
groupby("gender"). \
count(). \
show()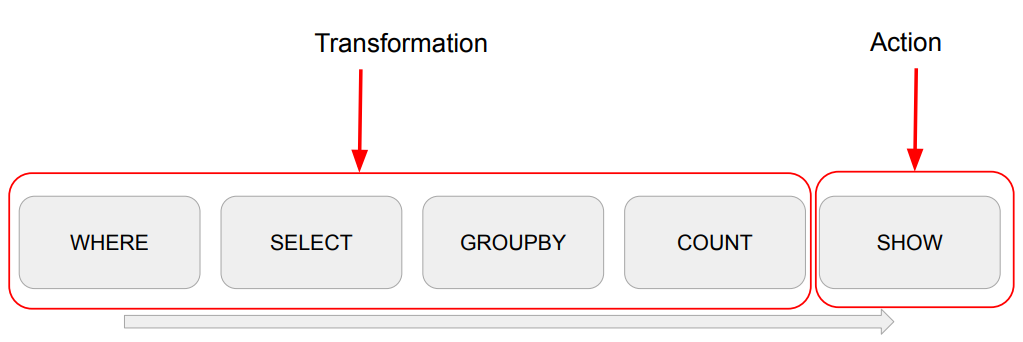
-
Action :
앞의 Transformation과 같은 작업들을 실제 수행시키는 역할Spark는 WHERE, SELECT, ... 등의 작업을 지정한다고 해서 바로 실행하는 것이 아니고 Action이라고 부르는 특정 작업이 수행이 될 때 그 때서야 연산이 수행이 됩니다.
대표적인 Action이 SHOW
-
Transformation : 2가지 종류가 존재
-
Narrow Transformation :
Partition 안에서 독립적인 작업이 가능 -
Wide Transformation :
GROUP BY처럼 Shuffling이 이뤄지는 작업
-
Transformations and Actions
-
Transformations
-
Narrow Dependencies:
독립적인 Partition level 작업
-> select, filter, map 등등 -
Wide Dependencies:
Shuffling이 필요한 작업
-> groupby, reduceby, partitionby, repartition, coalesce 등등
-
-
Actions
-
Read, Write, Show, Collect
-> Job을 실행시킴
( Job : Action을 통해 실행되는 연산들 ) -
Lazy Execution
- 장점 : 더 많은 오퍼레이션( 여러 transformation 작업들 )을 볼 수 있기에 최적화를 더 잘할 수 있음
( 따라서, SQL이 더 선호됨, 연산해야할 정의들이 한번에 주어지기 때문 )
- 장점 : 더 많은 오퍼레이션( 여러 transformation 작업들 )을 볼 수 있기에 최적화를 더 잘할 수 있음
-
-
정리
하나의 Job에는 다수의 Transformation로 구성이 되고.
Transformation는 Narrow, Wide 두 종류가 나눠서 Stage로 재구성합니다.
Stage란?
Suffling 없이 독립적으로 병렬적으로 가능한 연산들을 뜻합니다.예를 들어, 하나의 Job에 Suffling이 생긴다면?
2개의 Stage로 그 Job이 구성이 됩니다.하나의 Stage는 다수의 태스크로 구성되고
각 태스크는 하나의 Narrow Dependencies Transformation를 실행합니다.
또한, Transformation 작업들을 들어오는 대로 실행을 하면 원활한 최적화가 될 수 없으므로,
Actions을 통한 Lazy Execution을 통해
전체적인 오퍼레이션을 확인 후에 최적화를 진행하는 것입니다.
Jobs, Stages, Tasks
Action -> Job -> 1+ Stages -> 1+ Tasks
-
Action
- Job을 하나 만들어내고 코드가 실제로 실행됨
-
Job
- 하나 혹은 그 이상의 Stage로 구성됨
- Stage는 Shuffling이 발생하는 경우 새로 생김
-
Stage
- DAG의 형태로 구성된 Task들 존재
- 여기 Task들은 병렬 실행이 가능
-
Task
- 가장 작은 실행 유닛으로 Executor에 의해 실행됨
예제로 살펴보기
spark.read.option("header", True).csv(“test.csv”). \
where("gender <> 'F'"). \
select("name", "gender"). \
groupby("gender"). \
count(). \
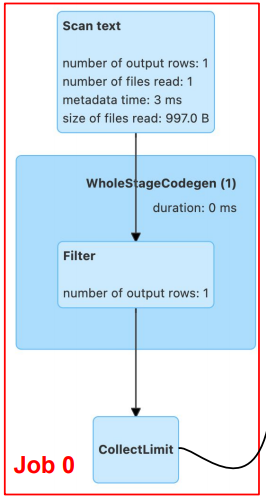
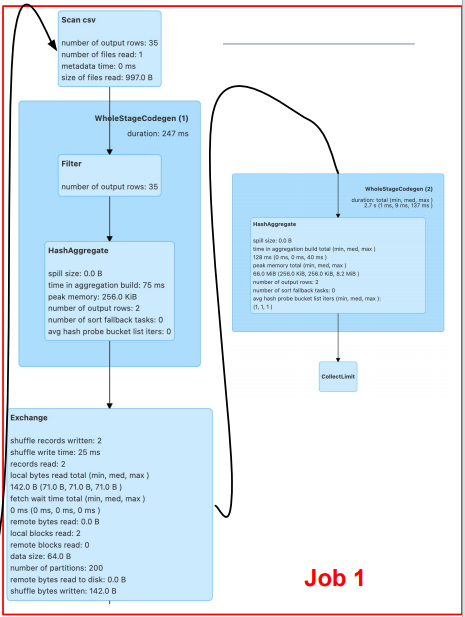
show()이 예제에는 2가지 Job이 있습니다.
첫 번째 Job은 Read 오퍼레이션에 header의 값을 True로 세팅했기 때문에 CSV 파일을 읽어와서 그 스키마를 파악해야하므로 발생했습니다
( csv를 읽을 때 header가 True인 경우에만 Action )두 번째 Job은 Show로 Transformation 작업들을 수행하는 Trigger 역할을 진행합니다.
여기서 각 파란색 블록은 Stage를 뜻하고.
Stage 내에는 하늘색 블록인 Task들이 있습니다.또한, Exchange는 Suffling을 의미하고,
Suffling이 발생했기에 한 개의 Job에서 Stage가 2개로 나뉜 것을 확인할 수 있습니다.
📕 Spark 내부 동작 실습
WordCount 코드
from pyspark.sql import *
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
# 코어 수 3개 지정
.master("local[3]") \
.appName("SparkSchemaDemo") \
# 자동 최적화 여부 : False
# 아직 최적화 처리 방식을 모르기에 해제
.config("spark.sql.adaptive.enabled", False) \
# shuffle에 사용할 Partition 3개
.config("spark.sql.shuffle.partitions", 3) \
.getOrCreate()
df = spark.read.text("shakespeare.txt")
# explode : 문자열을 분할하여 저장
df_count = df.select(explode(split(df.value, " ")).alias("word")).groupBy("word").count()
df_count.show()이 경우, read에 header = True라는 옵션이 없으므로 Job을 만들어 스키마를 파악할 필요가 없습니다.
따라서, show()에만 Action이 발생하므로.
Job이 1개만 생성되는 코드입니다.
또한, GROUP BY가 있으므로 Stage의 갯수는 2개입니다.
Suffle JOIN ( 일반적인 JOIN ) 코드
일반적인 JOIN (= Suffle JOIN )의 경우,
JOIN할 때 Suffling을 하여 Data Skew가 발생할 위험이 큽니다.
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("SparkSchemaDemo") \
.config("spark.sql.adaptive.enabled", False) \
.config("spark.sql.shuffle.partitions", 3) \
.getOrCreate()
df_large = spark.read.json("large_data/")
df_small = spark.read.json("small_data/")
join_expr = df_large.id == df_small.id
join_df = df_large.join(df_small, join_expr, "inner")
join_df.show()spark.read.json의 경우,
자동으로 JSON 파일의 스키마를 파악하기 위해 Job을 실행하게됩니다.
따라서, 이 코드에서 실행되는 Job의 수는 총 3개입니다.
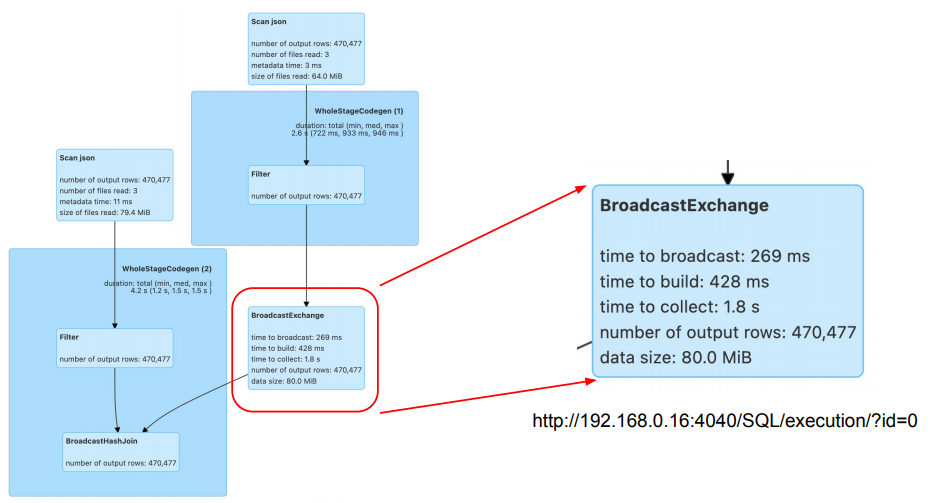
BROADCAST JOIN 코드
Suffling 없이 작은 데이터프레임을 큰 데이터프레임에 합치는 방식
# 달라진점 : broadcast
from pyspark.sql.functions import broadcast
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("SparkSchemaDemo") \
.config("spark.sql.adaptive.enabled", False) \
.config("spark.sql.shuffle.partitions", 3) \
.getOrCreate()
df_large = spark.read.json("large_data/")
df_small = spark.read.json("small_data/")
join_expr = df_large.id == df_small.id
# 달라진점 : broadcast를 명시적으로 호출
join_df = df_large.join(broadcast(df_small), join_expr, "inner")
join_df.show()위에서는 broadcast를 명시적으로 호출하여 사용했지만,
옵션을 주어 명시적인 호출 없이도 사용 가능하게 만들 수 있습니다.
.config("spark.sql.adaptive.autoBroadcastJoinThreshold")
🔎 Bucketing과 File System Partitioning
입력되는 데이터가 얼마나 최적화된 형태로 있느냐가 전체적인 처리시간과 리소스의 양을 결정!
여기서 Partitioning이란 지금까지의 Partition이 아니라 파일 시스템의 데이터를 특정 키를 중심으로 나눠서 저장하는 것을 의미
-
둘다 Hive 메타스토어의 사용이 필요:
saveAsTable -
향후 데이터 처리에 최적화된 방식으로 데이터를 저장하는 것
-
Bucketing
( 셔플링을 줄이는 것이 가장 큰 목적 )-
먼저 Aggregation이나 Window 함수나 JOIN에서 많이 사용되는 컬럼이 있는지?
( 셔플링을 자주 발생시키는 컬럼 찾기 ) -
이 특정 컬럼(들)을 기준으로 데이터들을 테이블 내에서 나눠 저장
-> 이 때, Bucket의 수 지정
-
-
File System Partitioning
-
원래 Hive에서 많이 사용
-
데이터의 특정 컬럼(들)을 기준으로 폴더 구조를 만들어 데이터 저장 최적화
-> 위의 기준이 되는 컬럼들을 Partition Key라고 부름
-
Bucketing
Bucketing을 통해 특정 ID를 기준으로 테이블 내에서 나눠논다면,
한번의 셔플링 작업이 필요하지만 그 후에 다수의 셔플링 작업을 막을 수 있습니다.
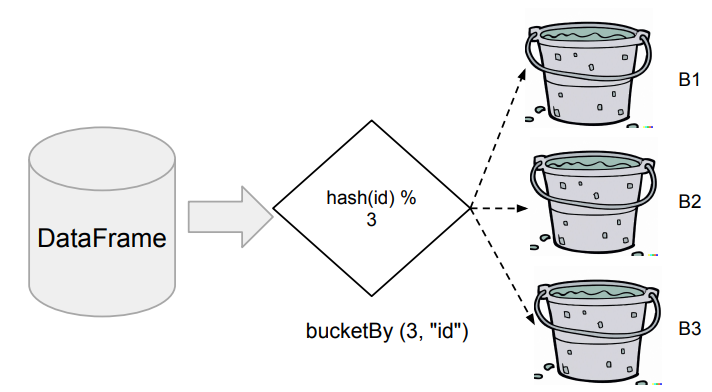
-
DataFrame을 특정 ID를 기준으로 나눠서 테이블로 저장
-
다음부터는 이를 로딩하여 사용함으로써 반복 처리시 시간 단축
- DataFrameWriter의 bucketBy 함수 사용
- Bucket의 수와 기준 ID 지정
-
데이터의 특성을 잘 알고 있는 경우 사용 가능
-
File System Partitioning
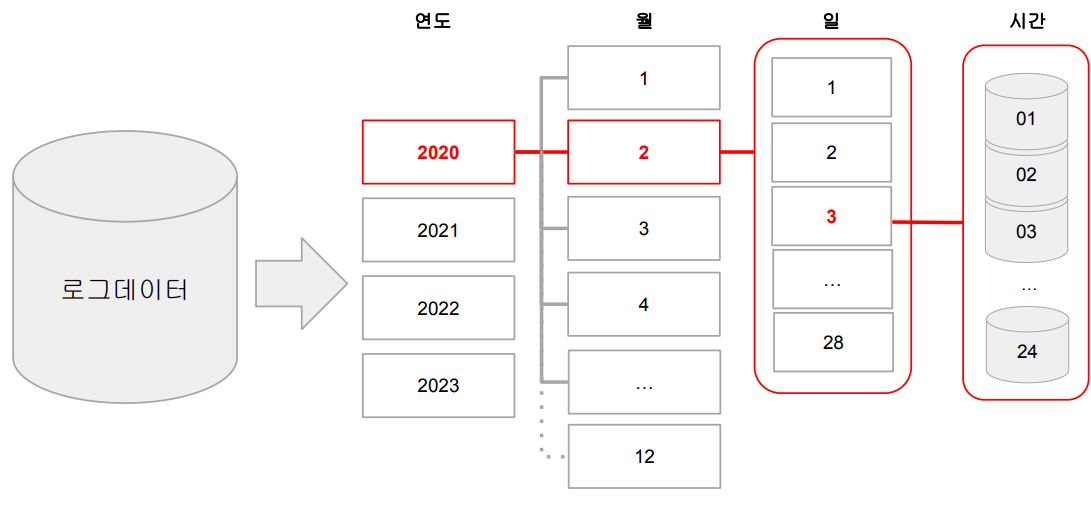
데이터를 Partition Key 기반 폴더 (“Partition") 구조로 물리적으로 나눠 저장하는 방식
-> Hive에서 사용하는 Partitioning을 말함
( DataFrame의 Partition과는 다르지만 매커니즘은 동일 )
-
Partitioning의 장점
ex)
굉장히 큰 로그 파일을 데이터 생성시간 기반으로 데이터 읽기를 많이 한다면?데이터 자체를 처음부터 연도-월-일의 폴더 구조로 저장하는 방식을 사용
( 최상위 폴더를 연도로, 그 하위를 월, 그 하위를 일 폴더로 지정하여 데이터를 나눠 저장하는 방식 )-
이를 통해 데이터를 읽기 과정을 최적화
( 스캐닝 과정이 줄어들거나 없어짐 ) -
데이터 관리도 쉬워짐
( Retention Policy 적용시 )1년 단위로 데이터를 저장한다고 했을 때,
1년이 지난 데이터를 날리는 과정에서 폴더 하나만 제거하면 되기 때문
-
-
DataFrameWriter의
partitionBy를 사용하여 저장
-> Partition key를 잘못 선택하면 엄청나게 많은 파일들이 생성됨!
( 따라서, Partition key는 Cardinality가 낮은 것을 사용해야함!! )
Bucketing 예시
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL 저장하기") \
# 자동 최적화가 되지 않게 설정
.config("spark.sql.autoBroadcastJoinThreshold", -1) \
.config("spark.sql.adaptive.enabled", False) \
.enableHiveSupport() \
.getOrCreate()
# Redshift와 연결해서 DataFrame으로 로딩하기
url = "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
# 최적화가 되지 않은 JOIN
join_expr = df_user_session_channel.sessionid == df_session_timestamp.sessionid
df_join = df_user_session_channel.join(df_session_timestamp, join_expr, "inner")
df_join.show(10)
# 밑에 overwrite 명령이 테이블이 존재할 경우 작동하지 않기에 테이블 삭제
spark.sql("DROP TABLE IF EXISTS bk_usc")
spark.sql("DROP TABLE IF EXISTS bk_st")
# Bucketing 작업,
# 테이블 내에 데이터를 크게 3개의 bucket으로 나눔,
# sessionid를 기준으로 데이터를 분배
# 이때, write가 Action으로 Job을 생성
df_user_session_channel.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_usc")
df_session_timestamp.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_st")
df_bk_usc = spark.read.table("bk_usc")
df_bk_st = spark.read.table("bk_st")
# Bucketing 후의 JOIN
join_expr2 = df_bk_usc.sessionid == df_bk_st.sessionid
df_join2 = df_bk_usc.join(df_bk_st, join_expr2, "inner")
df_join2.show(10)
# Spark 웹 UI 확인용 -> 꺼지지 않도록
input("Waiting ...")Bucketing 이전의 JOIN은
데이터의 분포가 Random하게 되어있지만,
Bucketing 이후의 JOIN은
sessionid를 기준으로 같은 수의 bucket을 만들어놓았기 때문에 JOIN 시 overhead가 더 적습니다.
Partition 예시
from pyspark.sql import *
from pyspark.sql.functions import *
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Spark FS Partition Demo") \
.master("local[3]") \
.enableHiveSupport() \
.getOrCreate()
df = spark.read.csv("appl_stock.csv", header=True, inferSchema=True)
# df의 date를 기준으로 partitioning하기 위해,
# 구분을 위한 컬럼을 추가
df = df.withColumn("year", year(df.Date)) \
.withColumn("month", month(df.Date))
spark.sql("DROP TABLE IF EXISTS appl_stock")
# partitioning을 위한 구조로 나눠 저장
df.write.partitionBy("year", "month").saveAsTable("appl_stock")
# 결과 확인
!ls -tl spark-warehouse/appl_stock/year\=2010/month\=12/
# Partitioning Table을 읽어오는 방식
spark.sql("SELECT * FROM appl_stock WHERE year = 2016 and month = 12").show(10)Partitioning Table을 읽어올때,
전체를 다 읽어서 필터링 하지 않고,
원하는 것만 조건을 걸어 처음부터 읽어오기 때문에,
( 데이터가 폴더로 구분이 되어 있기 때문 )
스캐닝에 Overhead가 발생하지 않습니다.
