✏️ 오늘 학습한 내용
1. Spark ML이란?
2. Spark ML 피쳐 변환
3. Spark ML Pipeline
🔎 Spark ML이란?
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리 입니다.
Classification, Regression, Clustering, Collaborative Filtering, Dimensionality Reduction 등의 머신러닝 작업을 지원하며 아직 딥러닝 지원은 아직 미약하다고 볼 수 있습니다.
-
RDD 기반과 데이터프레임 기반의 두 버전이 존재합니다.
-
spark.mllib vs. spark.ml
-
spark.mllib가 RDD 기반,
spark.ml이 데이터프레임 기반 -
spark.mllib는 더 이상 업데이트가 안됨
-
-
항상 spark.ml을 사용할 것!
->import pyspark.ml
-
Spark ML의 장점
Spark ML의 가장 큰 장점은 원스톱 ML 프레임워크라는 것입니다.
-
데이터프레임과 SparkSQL 등을 이용해 전처리
-
Spark MLlib를 이용해 모델 빌딩
-
ML Pipeline을 통해 모델 빌딩 자동화
-
MLflow로 모델 관리하고 서빙
-
대용량 데이터도 처리 가능!
Spark ML 소개: MLflow
MLflow는 모델의 관리뿐만 아니라 서빙을 위한 MLOps 관련 기능도 제공합니다.
-
모델 개발과 테스트와 관리와 서빙까지 제공해주는 End-to-End 프레임워크
-
MLflow는 파이썬, 자바, R를 지원
( 그 외는 API 형태로 지원 ) -
MLflow는 트래킹(Tracking), 모델(Models), 프로젝트(Projects)를 지원
Spark ML 제공 알고리즘
-
Classification:
- Logistic regression, Decision tree, Random forest, Gradient-boosted tree, …
-
Regression:
- Linear regression, Decision tree, Random forest, Gradient-boosted tree, …
-
Clustering:
- K-means, LDA(Latent Dirichlet Allocation), GMM(Gaussian Mixture Model), ...
-
Collaborative Filtering
( 가능하면 명시적인 피드백을 사용하는 것이 좋음 )- 명시적인 피드백과 암묵적인 피드백 기반
- 명시적인 피드백 예시) 리뷰 평점
- 암묵적인 피드백 예시) 클릭, 구매 수 등
Spark ML 기반 모델 빌딩의 기본 구조
-
여느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않음
( 트레이닝셋이 있다고 가정 )- 트레이닝셋 전처리
- 모델 빌딩
- 모델 검증 (confusion matrix)
-
Scikit-Learn과 Spark ML 비교
-
차이점은 결국 데이터의 크기
-
Scikit-Learn은 하나의 컴퓨터에서 돌아가는 모델 빌딩
-
Spark MLlib는 여러 서버 위에서 모델 빌딩
-
-
트레이닝셋의 크기가 크면 전처리와 모델 빌딩에 있어 Spark이 큰 장점을 가짐
-
Spark은 ML 파이프라인을 통해 모델 개발의 반복을 쉽게 해줌
-
🔎 Spark ML 피쳐 변환
📃 Feature 추출과 변환
Feature 값들을 모델 훈련에 적합한 형태로 추출하고 변환하는 방법에는 크게 두 가지 방법이 있습니다.
Feature Extractor와 Feature Transformer
Feature Transformer
Feature의 형태를 모델 훈련에 적합한 형태로 변환하는 것을 의미합니다.
조건 : 피쳐 값들은 숫자 필드이어야함
( 텍스트 필드 (카테고리 값들)를 숫자 필드로 변환해야함 )
-
숫자 필드 값의 범위 표준화
-
숫자 필드라고 해도 가능한 값의 범위를 특정 범위 (0부터 1)로 변환해야 함
-
이를 피쳐 스케일링 (Feature Scaling) 혹은 정규화 (Normalization)
-
-
비어있는 필드들의 값을 어떻게 채울 것인가?
- Imputer. 앞서 타이타닉 승객 생존 분류기에 써봤음
Feature Extractor
기존 피쳐에서 새로운 피쳐를 추출하는 것을 의미합니다.
- TF-IDF, Word2Vec, …
-> 대부분의 경우, 텍스트 데이터를 어떠한 형태로 인코딩하는 것이 이 경우에 해당
📃 Feature 변환 예시
텍스트 카테고리를 숫자로 변환
ex) Red -> 1, Blue -> 2, Orange -> 3, ...
Sparrk MLlib에는 pyspark.ml.feature 모듈 밑에 텍스트를 숫자로 변경해주는 두 개의 인코더가 존재합니다.
( StringIndexer, OneHotEncoder )
이 중 StringIndexer를 사용하는 방법은 :
Indexer 모델을 만들고 ( fit ),
만든 Indexer 모델로 데이터프레임을 변환하는 것입니다. ( transform )
e.g.)
from pyspark.ml.feature import StringIndexer
# StringIndexer 사용하여 컬럼 지정
gender_indexer = StringIndexer(inputCol='Gender', outputCol='GenderIndexed')
# fit을 사용해 해당 데이터에 적합한 모델 생성
gender_indexer_model = gender_indexer.fit(final_data)
# 생성한 모델 기반으로 transform을 적용해 데이터를 변형
final_data_with_transformed_gender_gender = gender_indexer_model.transform(final_data)숫자 필드 값의 범위 표준화
이를 Feature Scaling 혹은 Normalization이라 부릅니다.
ex) 0 ~ 1로 변환
( -20 -> 0, 100 -> 1, 40 -> 0.5, 25 -> 0.375 )
Spark MLlib에는 pyspark.ml.feature 모듈 밑에 두 가지 스케일러가 있습니다.
( StandardScaler, MinMaxScaler )
-
StandardScaler
각 값에서 평균을 빼고 이를 표준편차로 나눕니다.
( 값의 분포가 정규분포를 따르는 경우 사용 ) -
MinMaxScaler
모든 값을 0과 1사이로 스케일링하는 방식,
각 값에서 최소값을 빼고 (최대값-최소값)으로 나눕니다.
🔎 Spark ML Pipeline
모델을 빌딩할 때 흔하게 발생하는 여러 문제들이 있습니다.
모델 훈련 방법이 기록이 안되있거나,
모델 훈련이 자동화가 안된 경우 매번 매 스텝을 노트북에서 일일히 수행해야하는 일도 빈번하게 일어나죠.
이를 해결하기 위해 등장한 것이 ML Pipeline입니다.
주 목적은 자동화를 통해 에러 소지를 줄이고 반복된 훈련을 빠르게 해주는 것이죠.
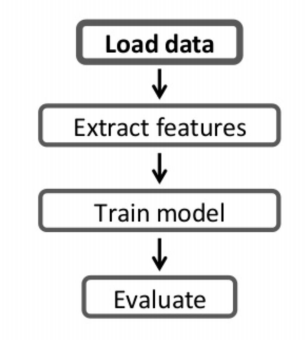
📃 ML 파이프라인이란?
데이터 과학자가 머신러닝 개발과 테스트를 쉽게 해주는 기능으로 데이터프레임를 기반으로 동작합니다.
머신러닝의 알고리즘에 관계없이 일관된 형태의 API를 사용하여 모델링이 가능하다는 장점이 있습니다.
주 역할은 ML 모델 개발과 테스트를 반복할 수 있도록 자동화를 해주는 것입니다.
ML 파이프라인의 4가지 요소로 구성이 됩니다.
( 데이터프레임, Transformer, Estimator, Paramter )
데이터 프레임
ML 파이프라인에서는 데이터프레임을 기본 데이터 포맷으로 사용합니다.
기본적으로 CSV, JSON, Parquet, JDBC(관계형 데이터베이스)를 지원합니다.
또한,
이미지 데이터소스 및 LIBSVM 데이터 소스도 지원해줍니다.
- LIMSVM 데이터 소스
label과 features 두 개의 컬럼으로 구성되는 머신러닝 트레이닝셋 포맷
( features 컬럼은 벡터 형태의 구조 )
Transformer
입력 데이터프레임을 다른 데이터프레임으로 변환해주는 기능입니다.
Feature Transformer와 Learning Model이라는 2 종류의 모듈이 존재하며 transform이 메인 함수입니다.
-
Feature Transformer
입력 데이터프레임의 컬럼으로부터 새로운 컬럼을 만들어내 이를 추가한 새로운 데이터프레임을 출력합니다. -
Learning Model
feature 데이터프레임을 입력으로 받아 예측값이 새로운 컬럼으로 포함된 데이터프레임을 출력합니다.
( 머신 러닝 모델에 해당됨 )
Estimator
트레이닝셋 데이터프레임을 입력으로 받아 머신러닝 모델(Transformer)을 만들어내는 기능을 제공합니다.
- 입력 : 데이터프레임 (트레이닝 셋)
- 출력 : 머신러닝 모델
ML Pipeline도 일종의 Estimator라고 볼 수 있습니다.
Estimator는 저장과 읽기 함수도 제공합니다.
Parameter
Transformer와 Estimator의 공통 API로 다양한 인자를 적용해주는 역할을 합니다.
- 두 종류의 파라미터가 존재합니다.
- Param : 하나의 이름 + 값
- ParamMap : Param 리스트
ex) ParamMap(lr.maxIter -> 10)
파라미터는 fit (Estimator) 혹은 transform (Transformer)에 인자로 지정이 가능합니다.
