✏️ 오늘 학습한 내용
1. Kafka란
2. Kafka 아키텍처
🔎 Kafka란
Kafka는 실시간 데이터를 처리하기 위해 설계된 오픈소스 분산 스트리밍 플랫폼으로,
다수의 서버에 로그가 분산되어 저장되기에,
데이터 재생이 가능한 분산 커밋 로그 입니다.
( Distributed Commit Log )
이는 2008년 LinkedIn에서 내부 실시간 데이터 처리를 위해 개발됐습니다.
Kafka의 특징
-
Scalability와 Fault Tolerance를 제공하는 Producer-Consumer 메시징 시스템
Scalability :
Streaming이 되는 데이터들을 저장할 때, Partition으로 데이터를 나눠 다수의 서버에 저장합니다.Fault Tolerance :
Topic 데이터를 Partition으로 나눠 저장할 떄,
Partition이 저장된 브로커(서버)가 고장이 나면 그 데이터가 유실이 되기 때문에 이를 막기 위해서 3개의 다른 브로커에 같은 데이터를 저장합니다.Producer : 데이터를 생성하는 프로세스,
Consumer : 생성된 데이터를 큐에 저장하고 그 큐에 저장된 데이터를 소비하는 프로세스( Publish-Subscription을 Kafka에서는 Producer-Consumer로 사용, 둘은 동의어 )
-
High Throughput과 Low Latency 실시간 데이터 처리에 맞게 구현됨
-
분산 아키텍처를 따르기 때문에 Scale Out이란 형태로 스케일 가능
-> 브로커(서버)를 추가함으로써 Scalability 달성 -
정해진 보유기한 (retention period) 동안 메시지를 저장
-> 특정 기한이 지나면 큐에서 삭제가 됨
( default : 일주일 )
기존 메시징 시스템 및 데이터베이스와의 비교
카프카는 메시지를 정해진 보유 기간 동안 저장
기존 메시징 시스템과 다르게, 카프카는 메시지를 정해진 보유 기간(retention period) 동안 저장합니다.
( 이를 통해, Consumer가 오프라인 상태일 때에도 내구성과 내결함성을 보장할 수 있습니다. )
-> 꼭 보유 기간만이 아니라 Topic이 최대로 보유할 수 있는 크기를 설정할 수도 있습니다.
Kafka는 메시지 생산과 소비를 분리
Kafka는 큐를 별개로 만들어,
Producer의 데이터 생성과 Consumer의 행동을 tight하게 couple 하지않음으로써,
메세지 생성과 소비를 분리했습니다.
이렇게 함으로써,
생산자와 소비자가 각자의 속도에 맞춰 독립적으로 작업이 가능하도록 하였습니다.
-> 시스템 안정성을 높일 수 있음
( Backpressure 이슈가 덜 심각해짐 )
Kafka는 높은 처리량과 저지연 데이터 스트리밍을 제공
Scale-Out 아키텍처를 지원하기 때문에,
Throughput이 상대적으로 높을 수 있고,
Latency가 아주 짧지는 않지만 reasonable한 정도로 짧게 유지할 수 있습니다.
한 파티션 내에서는 메세지 순서를 보장해줌
Topic이란,
하나의 Producer가 만들어준 event stream, 연속된 event의 집합을 뜻하고
하나의 Topic은 다수의 파티션으로 나눠서 관리가 됩니다.
한 Partition 내에서는 Message 순서가 데이터가 생성된 순서로 보장이 됩니다.
-
다수의 파티션에 걸쳐서는 “Eventually Consistent”
다수의 Partition에 걸쳐서는 순서가 즉각적으로 보장이 되진 않지만 “Eventually Consistent”한 형태로 '몇 백 ms' 안에는 순서가 보장이 됩니다.
-
토픽을 생성할 때 지정 가능
(Eventual Consistency vs. Strong Consistency)몇 개의 Partition으로 지금 생성하는 Topic을 관리할 것인지,
Partition 별로 몇 개의 복제 번호를 만들 것인지를 지정해야하는데,이때, Consistency를 어떻게 가져갈 지를 결정할 수가 있습니다.
두 가지 방법이 있습니다.
Eventual Consistency와 Strong ConsistencyStrong Consistency :
내가 어떤 Topic의 event를 Producer에서 생성하는 경우, 이 정보가 복제본(Replica) 모두 한테 전달이 될 때까지 기다렸다가 return을 하는 것입니다.Eventual Consistency :
위와 같이 event가 생성될 때,
설정 한 수 만큼의 복제본에게 전달이 될 떄까지 기다렸다가 return을 하는 것입니다.
즉, Consistency 이슈를 정리하자면,
분산 시스템에서는 다수의 서버에 데이터가 나눠서 관리되고 Fault Tolerance로 인해 여러 서버에 복제본이 존재하게 되는데,사용자가 write를 했을 경우, 어디까지 전파가 되는 것을 기다릴 것이냐에 따라 write하자마자 return이 될 수도 있고 오래 기다려야할 수도 있습니다.
어떻게 세팅을 하는 것이 가장 좋은 방법이냐면?
내가 이 Topic을 소비하는 관점에서 생각해보고 Consistency Level을 설정해줘야합니다.
Strong Consistency ->
Write하는데 시간이 좀 걸리지만 Read하는 관점에서는 항상 완전한 데이터를 읽을 수 있습니다.
( 모든 Replica에 전달하므로 전달이 오래걸리는 만큼 많은 곳에 저장되어 있으니 꺼내오기가 쉬움 )Eventual Consistency ->
Producer 관점에서는 Write하자마자 return이 되니까 빠르게 데이터를 생성을 완료할 수 있지만, Read하는 관점에서는 약간 늦게, 혹은 덜 완전한 정보를 받을 수 있습니다.
( 제한적으로 Replica에 전달하므로 전달이 빠르나, Replica의 위치 상황에 따라 꺼내오는 데에 문제가 생길 수 있음 )
사내 내부 데이터 버스로 사용되기 시작
Kafka가 Throughput이 좋은 Scale-Out Approach를 사용므로,
어떤 시스템에서 다른 시스템으로 넘겨주는 buffer역할을 해주는데도 아주 적합하다는 것을 사람들이 알게 되었습니다.
이러한 역할을 데이터 버스라고 부릅니다.
-> 워낙 데이터 처리량이 크고 다수 소비자를 지원하기에 가능
Eventual Consistency에 대해
"100대 서버로 구성된 분산 시스템에 레코드를 하나 썼다고 (Write) 가정했을 때, 그 레코드를 바로 읽을 수 있을 까?" 에 대해 생각해보겠습니다.
이를 결정하는 것이 바로 Consistency입니다.
보통 하나의 데이터 블록이 여러 서버에 나눠 저장이 되기 때문에 데이터를 새로 쓰거나 수정하게되면 전파되는데 시간이 걸립니다.
( Replication Factor )
Replication Factor는 데이터를 보호한다는 의미도 있지만, 다수의 서버에서 데이터를 읽어온다는 의미도 강합니다.
( 데이터 병렬 처리의 효율 증가)
Strong Consistency는 데이터를 쓸 때 복제가 완료되는 시간이 길지만 끝나자마자 바로 읽어올 수 있다는 장점이 있고,
Eventual Consistency는 데이터를 쓸 때 빠르게 복제되어 바로 리턴이 된다는 장점이 있지만 읽어오는 데 걸리는 시간이 좀 걸릴 수 있다는 단점이 있습니다.
일반적으로, 특별한 경우를 제외하면 바로 읽어올 필요는 없기에 Eventual Consistency가 선호되는 편입니다.
( 금융 관련 데이터인 경우에는 즉각적으로 읽을 수 있어야하기에 Strong Consistency를 사용 )
예시
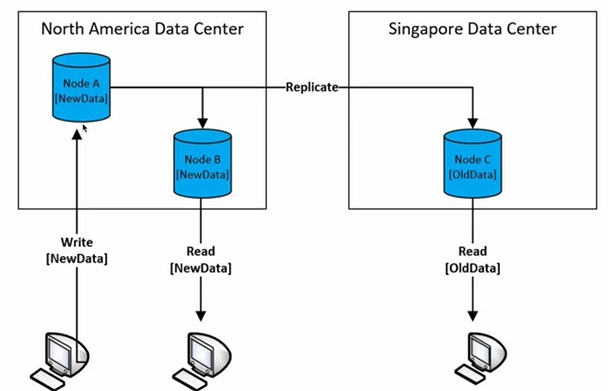
Eventual Consitency를 사용한다면
North America와 Singapore에 서버를 가지고 있고 이것들 간의 데이터 복제가 이루지고 있다고 할 때,
사용자가 north america에 있는 A 서버에 Write를 하면 데이터 블럭의 복제본이 B와 C 서버에 저장이 될 것입니다.
이 때, 같은 지역에 있는 B에는 빠르게 전파가 될 것이고 물리적으로 떨어져있는 C에는 전파가 느리게 될 것입니다.
그렇다면 동시간 대에 다른 client들이 Read를 했다고 하면,
North America Data Center에 요청을 한 경우,
Write한 데이터를 읽어올 가능성이 높을 것이고
Singapore Data Center에 요청을 한 경우,
그 데이터가 오지 않아 Write가 반영이 되지 않은 이전의 데이터를 보여줄 가능성이 높습니다.
이러한 상황이 문제가 된다면?
Strong Consistency를 사용하여 모든 시스템에 복제본이 전파가 될 때까지 기다리기 때문에 동시간 대 요청을 한 client들은 모두 같은 데이터를 볼 수 있을 것입니다.
의문점
Eventual Consistency가 읽어오는 데 시간이 좀 더 걸리는 이유?
개인적인 생각 :
Replica의 역할은 데이터 보호뿐 아니라 Consumer의 Read를 병렬로 처리해주는 역할도 있기에 상대적으로 Replica의 수가 적은 Eventual Consistency가 Read 하는데 시간이 더 걸린다.
혹은
제한적인 Replica 선택으로 인해 특정 지역에 저장해두지 않았다면, 그 특정 지역에서 데이터를 읽고 싶을 때 먼 지역의 서버에서 읽어와야하기 때문.
🔎 Kafka 아키텍처
데이터 이벤트 스트림
Kafka에서는 데이터 이벤트 스트림을 Topic이라고 부릅니다.
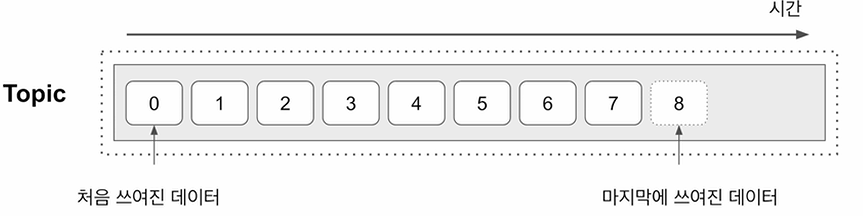
-
Producer는 Topic을 만들고 Consumer는 Topic에서 데이터를 읽어들이는 구조
-
다수의 Consumer가 같은 Topic을 읽어들이는 것이 가능
-
Topic에 보유 기간이 존재하며 기간이 종료될 때 삭제되는 구조
Message (Event) 구조
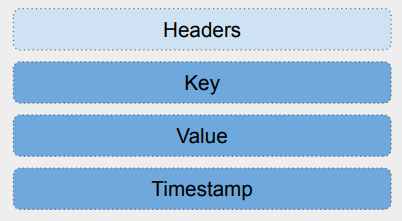
Event를 구성하는 구조는 크게 4가지가 있습니다.
1. Timestamp
2. Key
3. Value
4. Headers (Optional)
여기서 Key와 Value가 실제로 기록이 되는 Message가 됩니다.
그 Message의 생성 시간을 나타내는 Timestamp,
Optional한 선택적인 구성 요소로는 Headers가 있습니다.
( Headers : Key-Value에 대한 메타 데이터 )
-
Event의 최대 크기 : 1MB
-
Timestamp : 보통 데이터가 Topic에 추가된 시점
-
Key 자체도 복잡한 구조를 가질 수 있음
-> Key는 Topic 데이터를 Partitioning할 때 사용됨 -
Header는 선택적 구성요소로 경량 메타 데이터 정보 (key-value pairs)
Topic과 Partition
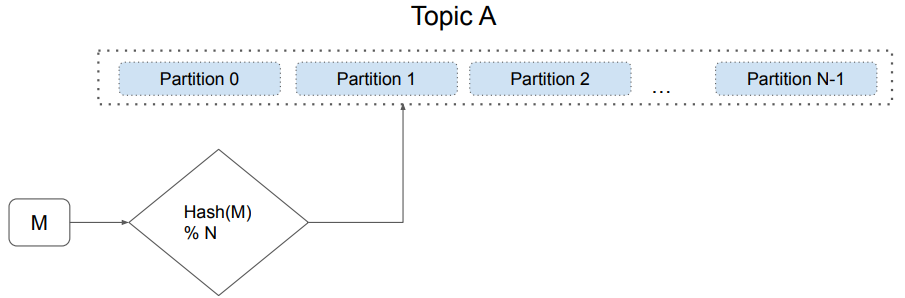
하나의 Topic은 확장성을 위해 다수의 Partition으로 나뉘어 저장됩니다.
메세지(event)가 어느 Partition에 속할 지 결정하는 방식은 두 가지가 있습니다.
-
Key가 있는 경우, Hashing 값으로 바꾸고 나서 Partition 수로 나눈 나머지로 결정하는 방식
-
Key가 없는 경우, Round-Robin으로 결정하는 방식
( 추천되지 않는 방식 )
Partition의 복제본 (Replica)
하나의 Partition은 Fail-over를 위해 Replication Partition을 가지게 됩니다.
( 실패했을 때의 유실을 방지하기 위한 복제본 )
-
Partition의 목적
이때, Replication Partition은 단순히 데이터 유실을 방지하기 위한 목적만이 아니라,
Consumer들에 대한 Read 병렬성을 높이기 위해서도 사용이 됩니다. -
각 Partition은 Leader와 Follower로 구성이 됩니다.
( 모든 Partition에는 하나의 Leader가 있고 하나 이상의 Follower들이 존재합니다. )- Write는 Leader를 통해 이뤄지고,
- Read는 Leader 혹은 Follower를 통해 이뤄집니다.
또한,
- Topic을 만들 때, Partition별로 Consistency Level을 설정이 가능합니다.
( Strong Consistency, Eventual Consistency )
-> ( in-sync replica - “ack” )

Topic 파라미터들
Topic을 생성할 때, 어떤 파라미터들을 지정할 수 있는 지 살펴보겠습니다.
-
Topic 이름 : "MyTopic"
-
Partition의 수 : 3
-
복제본의 수 : 3 (원본 포함)
-
Consistency Level ("acks"): "all"
"all" 인 경우 :
어떤 Event가 쓰여졌을 때, 모든 복제본으로 전파가 되어야한다.
-> Strong Cosistency"2" 인 경우,
어떤 Event가 쓰여졌을 때, 2개의 복제본으로만 전파가 되면 return한다.
-> Eventual Consistency -
데이터 보존 기한 : 일주일
-
메세지 압축 방식
-
...
Broker: 실제 데이터를 저장하는 서버
Kafka 클러스터는 기본적으로 다수의 Broker로 구성이 됩니다.
이 다수의 Brocker들을 원활하게 관리하고 부가 기능을 위한 다른 서비스들이 추가되었습니다.
(Zookeeper가 대표적)
또한, 한 클러스터는 최대 20만개까지 partition을 관리할 수 있습니다.
Topic의 Partition들을 실제로 관리해주는 것이 Broker
-
Broker들이 실제로 Producer/Consumer들과 통신을 수행합니다.
-
한 Broker는 최대 4000개의 partition을 처리할 수 있습니다.
Broker는 물리서버 혹은 VM 위에서 동작
해당 서버의 디스크에 Partition 데이터들을 기록합니다.
Scale Out
Broker의 수를 늘림으로써 클러스터 용량을 늘릴 수 있습니다.
위의 20만개, 4천개 제약은 Zookeeper를 사용하는 경우
-> 이 문제 해결을 위해서 Zookeeper를 대체하는 모드도 존재합니다. (KRaft)
메타 정보 관리

-
Broker 리스트 관리 (Broker Membership)
- 누가 Controller인가?
( Broker 중에 Controller를 선출하는 과정이 필요 )
- 누가 Controller인가?
-
Topic 리스트 관리 (Topic Configuration)
- Topic을 구성하는 Partition 관리
- Partition별 Replica 관리
이 Partition들을 관리해주는 역할을 하는 것이 Controller입니다.
-
Topic별 ACL (Access Control Lists) 관리
-
Quota 관리
이러한 전체적인 관리를
일반적으로 Zookeeper가 해왔으나,
요즘은 Kafka 자체 시스템인 KRaft (Kafka Raft) 프로토콜로 넘어가는 추세입니다.
