✏️ 오늘 학습한 내용
1. 데이터 실시간 처리
2. 실시간 데이터 종류와 사용 사례
3.실시간 데이터 처리 챌린지
🔎 데이터 실시간 처리
처리량(Throughput) vs. 지연시간(Latency)
Throughput은 주어진 단위 시간 동안 처리할 수 있는 데이터의 양을 뜻합니다.
이 Throughput이 클수록 처리할 수 있는 데이터의 양이 커진다는 것을 의미하고,
이는 배치 시스템에서 더 중요한 개념입니다.
ex) Data Warehouse
또한,
Latency는 데이터를 처리하는 데 걸리는 시간을 뜻합니다.
Latency가 작을수록 응답이 빠름을 의미하며
이는 실시간 시스템에서 더 중요한 개념입니다.
ex) Production DB
대역폭 (Bandwidth) = 처리량 x 지연시간
데이터 실시간 처리란
초 단위의 계속적인 데이터를 처리하는 것을 의미하며, 배치 처리 다음의 고도화 단계입니다.
( 시스템 관리 복잡도의 증가 )
이러한 초 단위의 데이터를 Event라 부르며,
Event의 특징은 한번 생성되면 내용이 바뀌지 않는 데이터라는 것입니다. ( Immutable )
계속해서 발생하는 Event들을 Event Stream이라 부르며 Kafka에서는 이를 Topic이라 부릅니다.
Event : 초 단위의 계속적으로 들어오는 데이터
Event의 특징 : 한번 생성되면 내용이 바뀌지 않는 실시간 데이터
Event Stream : 계속해서 발생하는 Event들의 집합
처리 시스템 구조

먼저, Producer에서 데이터가 지속적으로 생성됩니다.
이렇게 생성되는 데이터들을 메세지 큐와 같은 시스템에 넣어두고,
( Kafka, Kinesis, PubSub 등 )
Consumer가 이 메세지 큐로부터 데이터를 읽어서 처리를 진행합니다.
( 이때, Consumer마다 별도의 포인터를 유지하며, 다수의 Consumer가 데이터 읽기를 공동으로 수행하기도 합니다. )
람다 아키텍처
tmi
구글의 검색엔진은 초기에 3~6달 사이에 한번씩 검색 인덱스를 업데이트하는 인덱싱 작업을 해왔었습니다.
즉, 배치 처리 방식으로 페이지 랭크 계산을 하여 이 인덱싱 작업을 진행해왔던 것인데 몇 달에 한번씩 페이지들의 중요도가 확 바뀌었기 때문에 이용자들이 불편함을 느끼곤 했습니다.
이를 해결하기 위해 배치 처리 방식으로 실시간 처리 방식으로 옮겼는데 구글은 이 방법을 공개하지 않았지만 개발자들이 추측한 실시간 처리 방법 중 하나가 바로 람다 아키텍처입니다.
아키텍처 동작 방식
람다 아키텍처는 배치 레이어와 실시간 레이어 두 개를 가지고 별도로 운영합니다.
배치 레이어가 주기적으로 데이터를 모두 읽어 Rebuilding을 진행하고,
실시간 레이어가 배치 업데이트 사이에 생긴 변화만 읽어서 처리를 진행합니다.
초기 람다 아키텍처
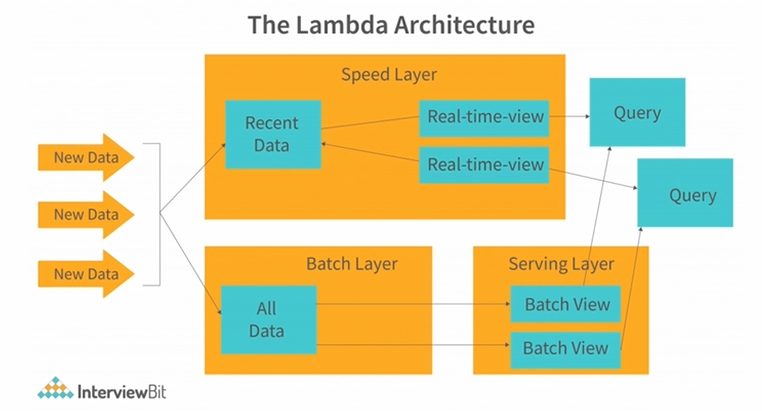
기본적인 아이디어는 동일하게 한쪽에는 배치 레이어,
한쪽에는 실시간 레이어를 두어 각자 잘하는 일을 수행
IoT & Big Data를 위한 람다 아키텍처
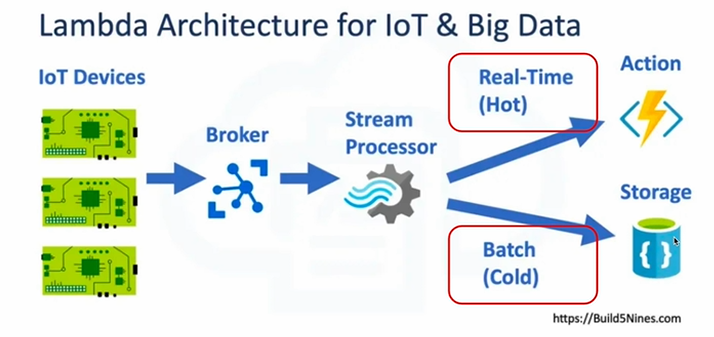
데이터 수집 자체를 별도로 하지 않고 Kafka와 같은 메세지 큐 (Stream Processor)에다 저장하는 것
배치 레이어(Cold)로 HDFS와 같은 스토리지에 저장하고,
실시간 레이어(Hot)으로 Spark Streaming같은 기술을 사용하여 짧은 시간을 주기로 데이터를 저장
Realtime vs. Semi-Realtime
Realtime의 특징
-
짧은 Latency
-
연속적인 데이터 스트림
-
이벤트 중심 아키텍처: 수신 데이터 이벤트에 의해 작업이나 계산이 트리거되는 구조
-
동적 및 반응형: 데이터 스트림의 변화에 동적으로 대응하여 실시간 분석, 모니터링 및 의사결정을 수행
Semi-Realtime의 특징
-
합리적인 Latency
-
배치와 유사한 처리 (Micro-batch)
-
적시성과 효율성 사이의 균형: 처리 용량과 리소스 활용도를 높이기 위해 일부 즉각성을 희생하기도 함
( 데이터를 모아서 처리하기 때문에 적시성은 떨어지지만 효율성은 높음 ) -
주기적인 업데이트
🔎 실시간 데이터 종류와 사용 사례
IoT (Internet of Things)
-
센서 판독값
IoT 장치에서 수집한 온도, 습도, 압력 등 측정값 기록 이벤트 -
장치 상태 업데이트
온라인/오프라인 상태 또는 배터리 잔량과 같은 장치 상태 이벤트 -
알람 이벤트
동작 감지나 임계값 초과하는 등 특정 조건에 의해 트리거되는 이벤트
사용 사례
-
Real-time Reporting (실시간 분석 및 대시보드)
- A/B Test Analytics
- Marketing Campaign Dashboard
- Infrastructure Monitoring
-
Real-time Alerting (실시간 경보)
- Fraud Detection
- Real-time Bidding
- Remote Patient Monitoring
-
Real-time Prediction (ML Model)
- Personalized Recommendation
🔎 실시간 데이터 처리 챌린지
실시간 데이터 처리 단계는 다음과 같습니다.
1. 이벤트 데이터 모델 결정
2. 이벤트 데이터 전송 / 저장
3. 이벤트 데이터 처리
이벤트 데이터 모델 결정
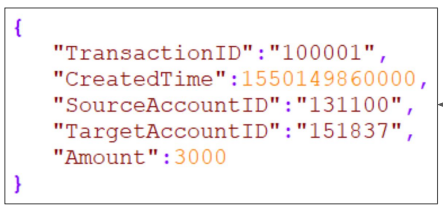
기본적으로 실시간 Event Stream으로 들어오는 데이터들은 꼭 필요한 정보가 2개가 있습니다.
언제 생성되었는 지에 대한 정보 Timestamp,
이 Timestamp를 구분할 수 있는 ID 정보 (관계형 DB로 치면 Primary Key) 가 필요합니다.
그리고 기타 세부 정보들이 필요합니다.
온라인 서비스라고 가정한다면,
Event 이름, 어느 사용자에서 발생했는지 사용자ID, DeviceID 등과 같은 정보들이 들어갑니다.
이러한 정보들이 Transaction이 생길 때마다 생길 것입니다.
이벤트 데이터 전송 / 저장
들어오는 이벤트 데이터들을 어떻게 전송하고 저장할 것인가에 대한 두 가지 방법이 있습니다.
< Point to Point, Messaging Queue >
Point to Point
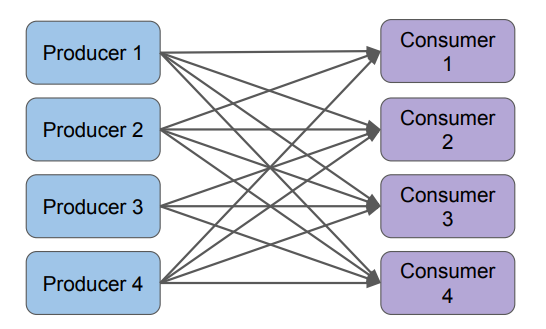
Producer와 Consumer가 바로 연결이 되는 것입니다.
중간에 Queue가 없기 때문에 Latency가 발생하지 않지만 Backpressure 문제가 생길 확률이 높습니다.
일반적으로, Throughput보다 Latency가 더 중요한 시스템에서 사용합니다.
많은 API 레이어들이 이런 식으로 동작합니다.
이때, 다수의 Consumer들이 존재하는 경우 데이터를 중복해서 보내야합니다.
얼마나 빠르게 처리해서 리턴하냐가 중요 (Backpressure에 취약)
Messaging Queue
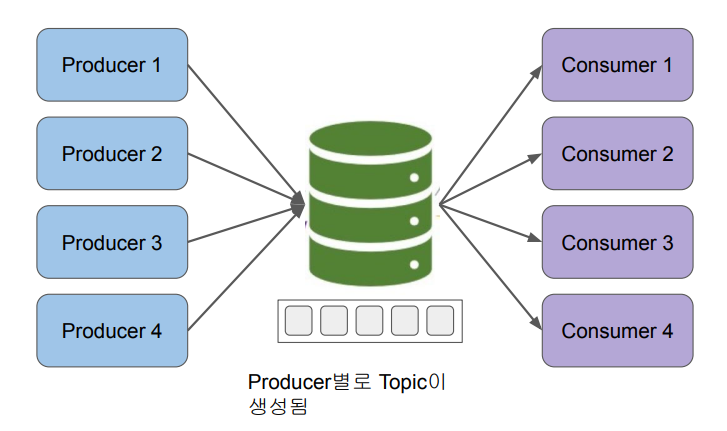
중간에 버퍼를 두고 Producer에서 Consumer로 데이터가 바로 가는 것이 아니라 버퍼(큐)에 시간 순으로 쌓이는 것입니다.
이 경우에도, 데이터가 너무 많이 들어와 처리 속도보다 들어오는 속도가 빠르면 Backpressure 문제가 발생하지만 그 확률은 상대적으로 훨씬 낮습니다.
또한, 장점으로
다수의 Consumer들이 공통의 데이터를 소비할 수 있습니다. ( 중간의 매개체(큐)가 있기 때문 )
Backpressure (배압)
데이터가 생성되는 속도를 데이터가 처리되는 속도가 따라잡지 못하는 경우 시스템에 데이터가 쌓여 지연되면서 사용량 증가 등으로 잠재적인 시스템 장애를 초래하는 결과가 발생합니다.
이를 Backpressure Issue라고 부릅니다.
point to point 방식에도 메모리 버퍼가 존재하지만 너무 작기에 버퍼의 크기가 금방 부족해집니다.
( Buffer Overflow )
그나마 Messaging Queue 방식을 통해 많이 줄일 순 있지만 완전히 해결할 수는 없습니다.
이벤트 데이터 처리
Point-to-Point 형태의 경우
Consumer쪽의 부담이 커지며 정말 바로바로 데이터가 처리되어야합니다. (Backpressure)
( 데이터 유실의 가능성이 큼 )
따라서, Low Throughput, Low Latency가 일반적입니다.
Messaging Queue의 경우
일반적으로 micro-batch라는 형태로 아주 짧은 주기로 데이터를 모아서 처리합니다.
( Spark Streaming )
장점으로는,
다수의 Consumer를 쉽게 만들 수 있다는 것이고,
Point-to-Point 보다는 운영이 용이합니다.
