
파이썬 싸이킷런의 의사 결정 나무를 사용해서 붓꽃(iris)를 분류해봅시다.
1. 라이브러리
# 데이터프레임을 사용해 데이터를 보기위해 판다스를 사용합니다.
import pandas as pd
# 사이킷런에 내장되어 있는 붓꽃 데이터를 가져옵니다.
from sklearn.datasets import load_iris
# 사이킷런의 의사결정나무 모델을 가져옵니다.
from sklearn.tree import DecisionTreeClassifier
# 데이터를 1) 훈련, 2) 검증 데이터셋으로 분리하기 위해 사용합니다.
from sklearn.model_selection import train_test_split
# 모델의 성능을 평가하기 위해 사용합니다.
from sklearn.metrics import accuracy_score
# 사이킷런의 버전 확인 - 저는 0.21.3 입니다.
import sklearn
print(sklearn.__version__)2. 붓꽃 데이터 가져오기
1) load_iris()
load_iris 설명 을 보면 load_iris는 함수이고 1) 붗꽃 데이터를 반환, 2) 데이터의 자료형은 파이썬의 딕셔너리와 유사하다고 합니다.
# type 함수를 통해 자료형을 확인할 수 있습니다.
print("load_iris의 자료형: ", type(load_iris))
# 딕셔너리 형태의 붓꽃 데이터를 iris 변수에 넣어줍니다.
iris = load_iris()
# 붓꽃 데이터 출력
print(iris)
2) 파이썬 딕셔너리
딕셔너리는 1. 키, 2. 값으로 이루어져있습니다.
keys() 함수 또는 반복문을 사용해서 키를 확인할 수 있습니다.
# 1) keys() 함수를 이용한 키 확인
print("파이썬 딕셔너리 키: ", iris.keys(), "\n")
# 2) for문을 이용한 키 확인
for item in iris:
print(item)
값은 data.key 형식을 사용해서 확인할 수 있습니다.
# 붓꽃
iris.data
# 붗꽃 라벨
iris.target
# 붗꽃의 타겟 이름
iris.target_names
...3) 판다스 데이터프레임
이렇게 확인하면 힘들기 때문에 pandas의 dataframe을 사용해서 확인해봅시다.
# 1) 데이터, 2) 칼럼이름을 넣어서 데이터프레임 생성
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 2) 생성된 데이터프레임에 label이라는 시리즈 생성
df["label"] = iris.target
# 3) 확인
df.head()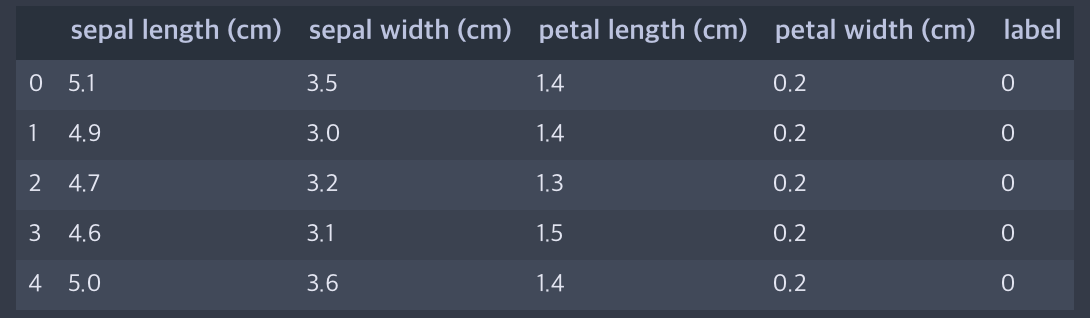
3. 훈련, 검증 데이터 분리
생성된 모델의 성능을 평가하기 위해서는 검증용 데이터가 필요합니다. 그렇기 때문에 모델 생성전 미리 1) 훈련, 2) 검증 데이터를 분리합니다.
즉, 훈련 데이터로 학습하고, 검증 데이터로 모델의 성능을 평가합니다
# 데이터프렘의 데이터를 분리합니다.
# x는 훈련을 위한 feature 이고
x = df.drop(columns=["label"], axis=1)
# y는 모델을 사용해 분류할 타켓입니다.
y = df["label"]train_test_split 함수를 사용해서 훈련, 검증 데이터를 분리합니다.
train_test_split의 인자값을 살펴보면
- 첫번째는 feature
- 두번째는 target
- test_size는 검증 데이터의 백분률 크기, 전체가 150이고 0.2면 검증 데이터 크기는 30입니다.
- random_state는 난수 생성을 위한 seed
seed를 주지않으면 매번 분리할때 다른 데이터셋이 나옵니다. 사실 크게 상관없습니다.
train_test_split의 반환값은 리스트입니다.
# 다음 4개가 순서대로 할당됩니다.
# 1. 훈련 feature, 2. 훈련 target, 3. 검증 feature, 4. 검증 target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)2) 참고, 파이썬 구조분해 할당(Destructuring Assignment)
왜 리스트가 4개의 변수에 할당되는지 궁금해하실 수 있습니다.
원래, train_test_split는 다음과 같이 길이가 4인 리스트를 반환합니다.
[ [], [], [], [] ]
다음 순서로 데이터가 할당된다는 것만 알고 계시면 됩니다.
1. 훈련 feature, 2. 훈련 target, 3. 검증 feature, 4. 검증 target
# 구조분해 할당으로 4개의 변수에 순서대로 할당됩니다.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)4. 의사결정나무 생성, 학습
1) 생성
# random_state는 난수 생성을 위한 seed입니다. 신경안쓰셔도 괜찮습니다.
dt = DecisionTreeClassifier(random_state=1)2) 학습
# .fit() 함수를 통해 쉽게 모델을 학습시킬 수 있습니다.
# 1. 첫번째 인자는 feature, 2. 두번째인자는 target입니다.
dt.fit(x_train, y_train)5. 예측
# predict() 함수를 통해 분류할 수 있습니다. 인자값은 feature입니다.
result = dt.predict(x_test)6. 평가
accuracy_score를 사용해서 얼마나 정확한지 평가할 수 있습니다.
print("테스트 정확도: {0: .4f}".format(accuracy_score(y_test, result)))

callmeskye