KFold 교차검증에 대해 알아봅시다.
1. KFold 교차검증
K개의 데이터 셋을 만든 후 K번 만큼 1) 학습, 2) 검증을 수행하는 방법
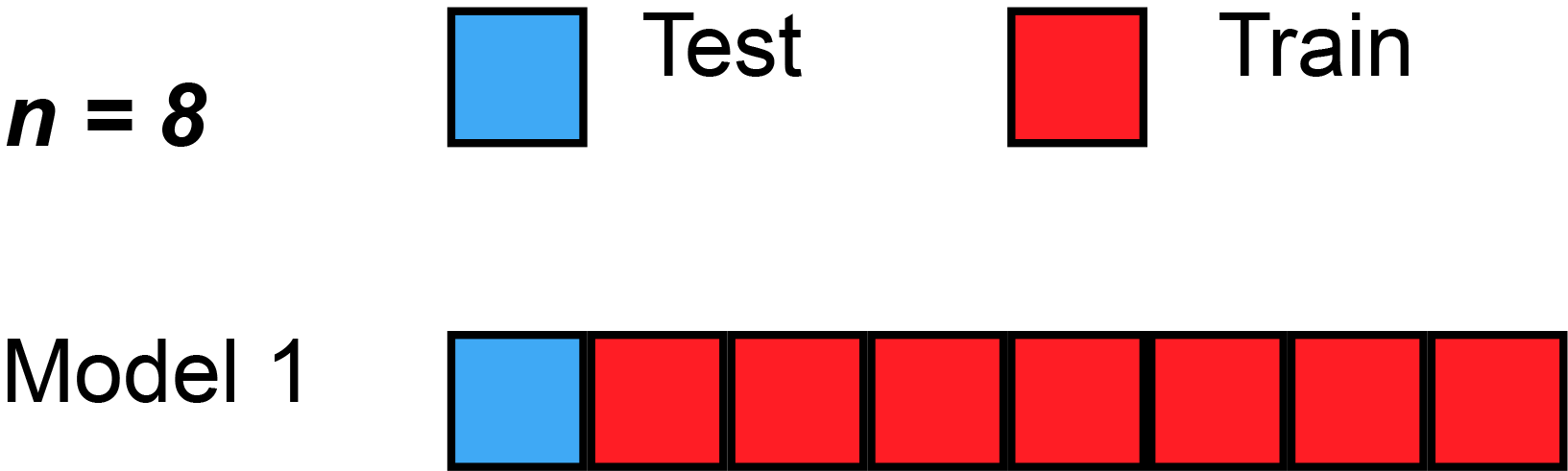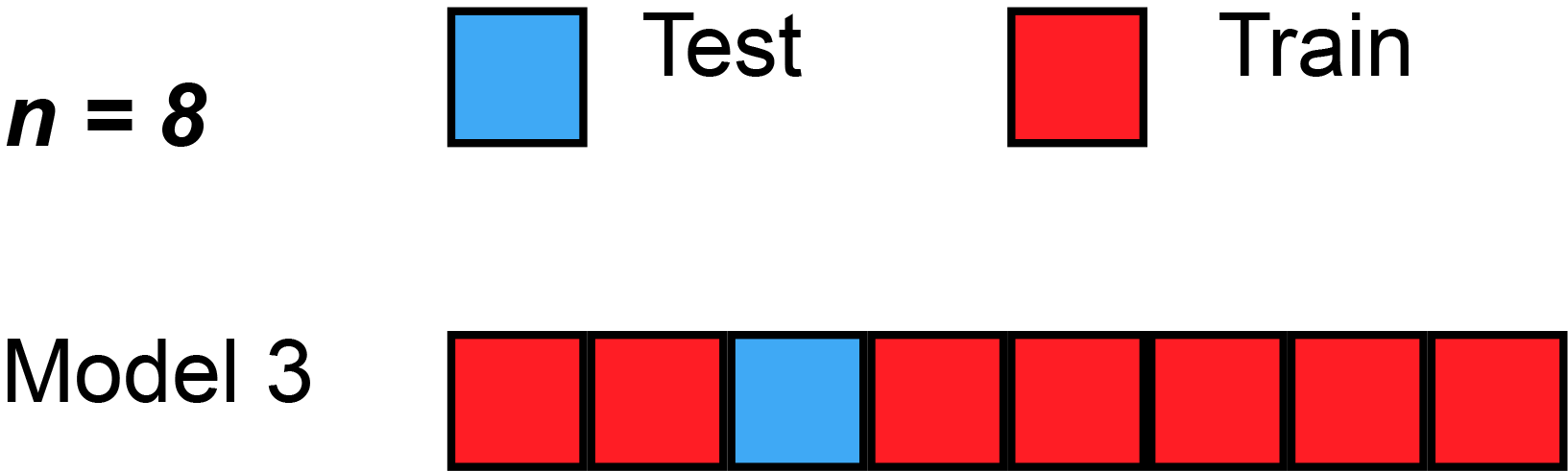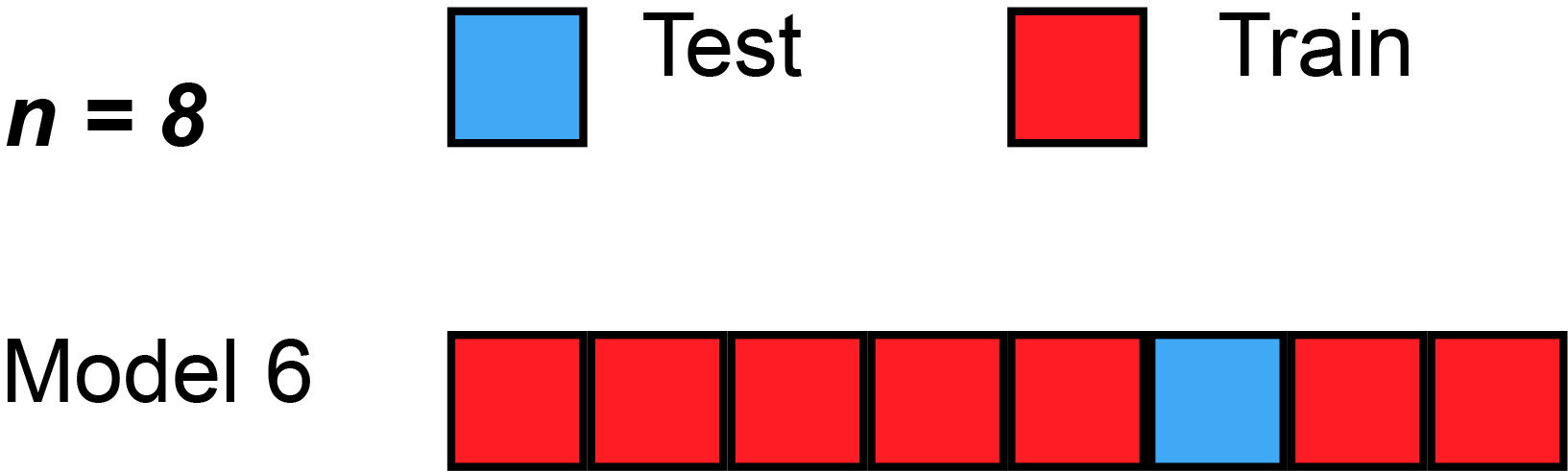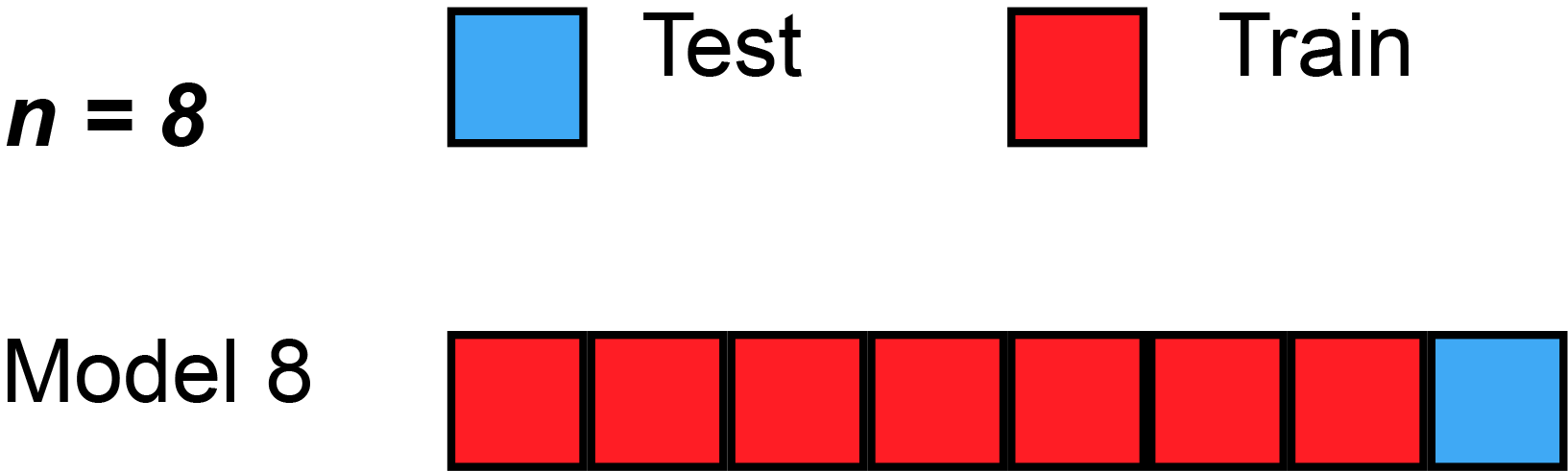
2. 교차검증을 하면 모델의 성능이 향상되는가?
교차검증의 목적은 모델의 성능 평가를 일반화하는것
모델의 성능을 직접적으로 향상시키지 않습니다.
다만, 하이퍼 파라미터 튜닝을 통해 최적의 성능을 발휘하는 파라미터를 찾을 수 있습니다.
3. sklearn - cross_val_score
cross_val_score을 사용해서 k-fold 교차검증을 수행합니다.
장점
1. 반복문을 사용하는 것 보다 쉽게 사용할 수 있습니다.
2. 내부적으로 StratifiedKFold를 사용하기 때문에 올바른 검증이 가능합니다.
(StratifiedKFold에 대해서는 뒤에서 알아봅시다.)
1) 라이브러리
# 사이킷런에서 붓꽃 데이터를 가져옵니다.
from sklearn.datasets import load_iris
# 사이킷런의 의사 결정 나무 모델을 가져옵니다.
from sklearn.tree import DecisionTreeClassifier
# cv는 분할 수, 섞을지 여부 등을 설정할 수 있습니다.
# cross_val_score는 k-fold 교차검증을 쉽게 사용하기 위한 함수입니다.
# cross_val_score는 내부적을 StratifiedKFold 을 사용합니다.
from sklearn.model_selection import KFold, cross_val_score2) 붓꽃 데이터 가져오기
# sklearn에 내장되어 있는 붓꽃 데이터를 가져옵니다.
iris = load_iris()
# 데이터의 크기를 출력합니다.
print("데이터의 크기", len(iris.data))
# 붓꽃 데이터의 키들을 출력합니다.
print("데이터의 키", iris.keys())
3) 모델 생성
# 의사 결정 나무 모델을 생성합니다.
dt = DecisionTreeClassifier()4) 분할 파라미터 설정
# n_splits 는 데이터 분할 수 입니다. 전체 데이터 수를 넘을 수 없습니다.
# shuffle은 매번 데이터를 분할하기전 섞을지 말지 여부를 선택합니다.
kfold = KFold(n_splits=20, shuffle=True)5) 교차검증 수행
cross_val_score는 여러 파라미터를 받습니다.
- 첫번째는 모델
- 두번째는 feature
- 세번째는 target
- cv는 분할 설정값
- scoring은 평가방법
score = cross_val_score(dt, iris.data, iris.target, cv=kfold, scoring="accuracy")
print(score.mean())
4. StratifiedKFold
StratifiedKFold는 k-fold가 label을 데이터와 학습에 올바르게 분배하지 못하는 경우를 해결해줍니다.
1) 일반적인 k-fold
다음처럼 label이 고르게 분포되지 못하는 현상이 발생합니다.
사실, 여기서 Fold(n_splits=3, shuffle=True) 하면 어느정도 해결되기는 합니다.
shuffle=True 로 설정하면 분할하기전에 섞기 때문에 아래처럼 편중될 확률이 줄어들기는 합니다.
그럼, cross_val_score 대신 kfold에 shuffle=True 사용하면 되지 않을까 싶기도 한데 for문 쓰기 귀찮으니까.
출처: 파이썬 머신러닝 완벽 가이드
# 분할 파라미터를 설정합니다. 3개로 나눕니다.
kfold = KFold(n_splits=3)
# 교차검증 횟수를 세기위한 변수입니다.
n_iter = 0
# 반복문을 통해 교차검증을 수행합니다.
for train_index, test_index in kfold.split(df):
n_iter += 1
label_train = df["label"].iloc[train_index]
label_test = df["label"].iloc[test_index]
print("교차검증 번호: {0}".format(n_iter))
print("학습 레이블 분포")
print(label_train.value_counts())
print("검증 레이블 분포")
print(label_test.value_counts())
print("")
2) shuffle=True
어느정도 고르게 나옵니다.

3) StratifiedKFold
더 고르게 분할됩니다.
# 분할 파라미터를 설정합니다. 3개로 나눕니다.
kfold = StratifiedKFold(n_splits=3)
# 교차검증 횟수를 세기위한 변수입니다.
n_iter = 0
# 반복문을 통해 교차검증을 수행합니다.
for train_index, test_index in kfold.split(df, df["label"]):
n_iter += 1
label_train = df["label"].iloc[train_index]
label_test = df["label"].iloc[test_index]
print("교차검증 번호: {0}".format(n_iter))
print("학습 레이블 분포")
print(label_train.value_counts())
print("검증 레이블 분포")
print(label_test.value_counts())
print("")
4. 정리
1) 교차검증의 목적은 모델의 성능 평가를 일반화하는것
2) sklearn의 kFold는 label을 고르게 분배하지 않음
3) sklearn의 cross_val_score 사용해서 kfold 교차검증 수행
