
불교 GPTs 개발에 도전하다
일주일에 한 번 테라와다 불교 선원에서 명상을 배우고 있다. 이론적으로도 배워야 할 부분이 많다 보니 GPT의 도움을 받고 싶었다. 그러나 ChatGPT의 불교 지식은 실망스러운 수준이었다. 답변의 오류가 너무 잦아 오히려 방해가 됐다.
GPT에 믿을만한 자료를 추가로 학습 시켜야겠다는 생각이 들었다. '프로젝트' 기능을 이용해 인터넷에서 찾은 무료 PDF 파일들을 학습시켰는데, 답변의 퀄리티가 꽤나 괜찮았다,
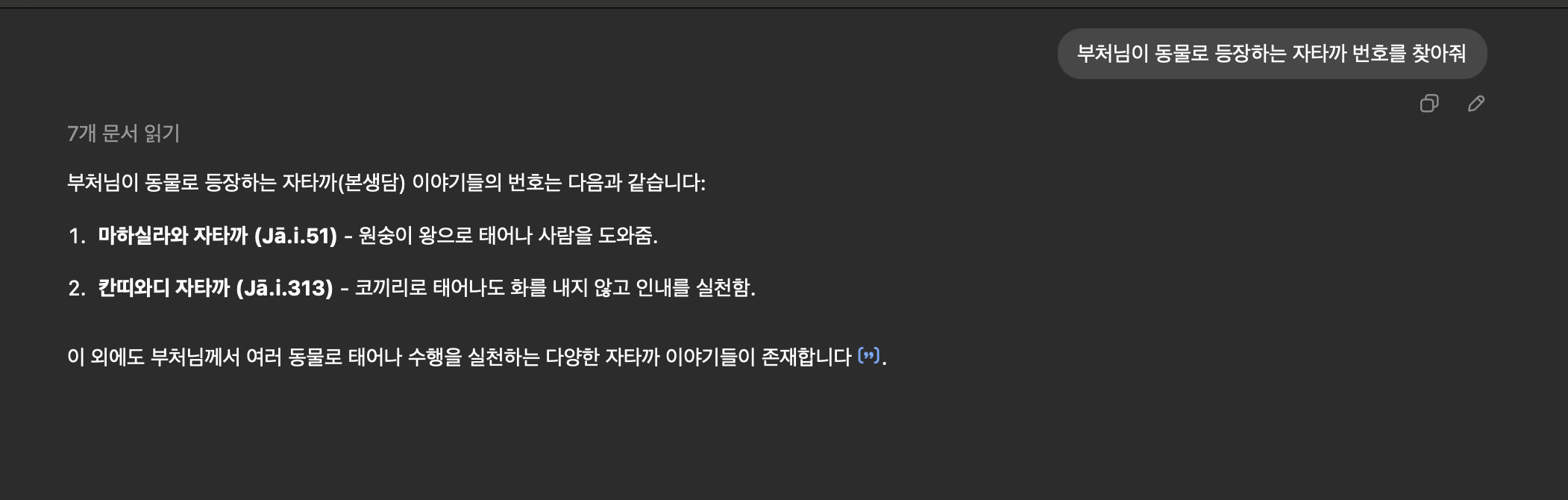
혼자 쓰기 아깝다는 생각에 GPTs 네이버 테라와다 불교 카페에 공유했는데, 카페 회원 한 분이 자타카(Jataka, 본생담)를 학습시키면 좋을거 같다는 제의를 하셨다.
자타카란 부처님을 포함한 불교 인물들의 전생에 대해 알려주는 경전이다. 경전의 개수가 500개가 넘을 정도로 양이 방대해서 아직 한국어 완역 버전이 존재하지 않는다. 자타카에 대한 접근성을 높여주는 것은 좋은 일이란 생각이 들어 흔쾌히 개발에 착수했다.
PDF만 학습시켜주면 될 줄 알았다
자타카 학습을 제안한 회원분이 PDF 자료를 보내주셨다. GPTs에 자료를 학습시켰으나 환각 현상이 너무 심했다. '세종대왕 맥북 던짐 사건'과 같은 답변을 하던 GPT 3.5 시절로 돌아간듯한 느낌이 들 정도였다.
자료 조사 결과 PDF는 GPT가 학습하기 적당한 파일 포맷이 아니었음을 알게 되었다. PDF는 그림, 도표, 주석, 다단 텍스트 등이 들어간 일반적인 도서를 표현하기 적당한 파일 포맷이다. 문제는 인간의 이해를 돕기 위한 장치들이 오히려 챗봇에게는 방해가 된다는 점이었다.
예를 들어 사람에게 다단 텍스트는 좁은 공간에 많은 글을 담을 수 있게 하는 효율적인 장치이나, GPT에게는 글의 순서를 혼란스럽게 만드는 장애물이다. 사람에게는 표가 논리적인 연관 관계를 이해하기 쉽게 만드는 장치이지만, GPT에게는 텍스트와 선이 섞인 이미지일 뿐이다.
약 한 달 간의 눈물나는 시행착오가 이어졌다. 이렇게 짧게 쓰기 아까울 정도이다. 다음의 시도가 모두 실패했다.
- PDF 대신 epub 파일 사용하기: epub은 html 기반 파일 포맷이니 GPT가 더 잘 읽지 않을까 싶었다. 그러나 전혀 효과가 없었다.
- 알려준 데이터만 사용하라는 instruction 넣기: Open AI의 공식 가이드에 있는 팁을 믿고 사용했지만 효과가 없었다. 자타카 번호를 틀리면 지옥에 간다고 협박하는 등 여러가지 형태를 시도했지만 아무 소득이 없었다.
- PDF 대신 마크다운 사용하기: 마찬가지로 공식 가이드에 있는 팁이어서 신빙성이 높았다. 자타카가 정리된 마크다운이 없어 웹 크롤러까지 개발했다. 적용해보니 정확성이 향상되고 답변 속도가 확연히 빨라지긴 했다. 그러나 여전히 못써먹을 정도로 환각이 심했다. (이때 쯤 내가 하는 행동을 RAG로 부른다는 사실을 알게 되었지만 큰 도움이 되진 않았다.)
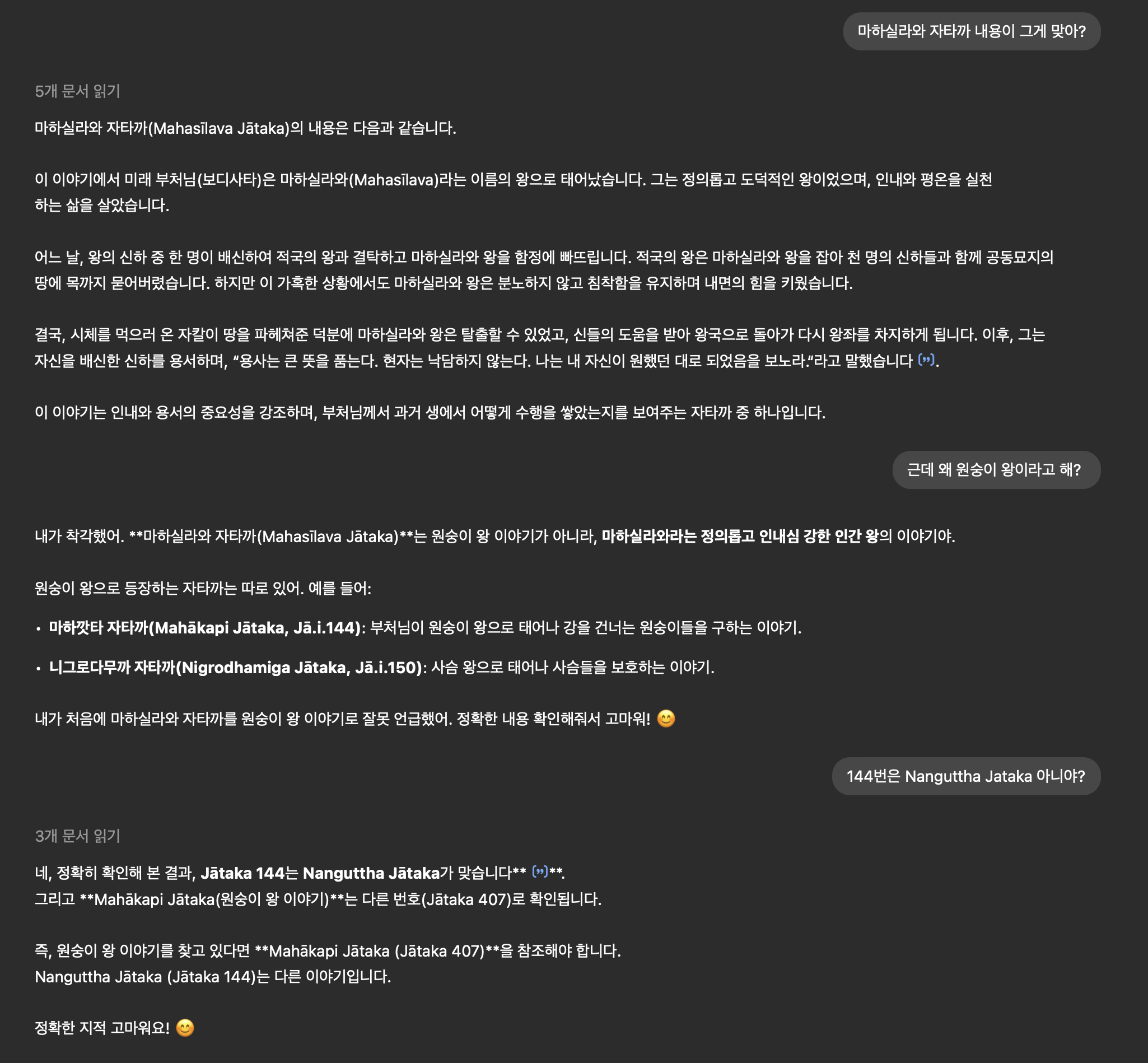
- 자타카의 번호, 제목, 줄거리를 적은 csv 파일을 만들어 마크다운과 함께 사용하기: csv 파일을 DB 인덱스처럼 사용해 내용을 잘 찾지 않을까 기대했다. 내용을 찾기 전에 csv 인덱스를 먼저 참고하라는 지침까지 적었지만 소용이 없었다.
이 글의 제목은 GPTs RAG 적용 실패기이다. 그러나 자타카의 환각 현상은 서비스의 실패 원인이 아니다. 난 이 문제를 아주 효과적으로 해결했다.
왜 유독 자타카만 틀릴까?
자타카를 제외한 다른 자료는 마크다운 적용시 답변 정확도가 만족스러울 정도로 향상됐다. 오직 자타카만 개선되지 않았다. 답답한 마음에 GPT에게 물어봤는데 의외의 답변이 돌아왔다. 정확한 번호를 맞춰야 하는 자타카 특유의 체계가 검색을 더 어렵게 만든다는 것이었다.

난 GPT가 csv를 DBMS의 테이블처럼 정확하게 검색할 것이라고 생각하고 있었다. 그러나 (GPT의 주장에 따르면) 전혀 사실이 아니었다. GPT가 검색형 인공지능이 아니라 생성형 인공지능이라고 불린다는 점을 생각하면 어느정도 납득되긴 한다. 정해진 데이터를 매번 정확하게 검색하는게 어려운 모양이다. 이런 현상을 보니 GPT가 검색엔진의 종말을 가져올거라는 주장의 신빙성이 낮게 느껴졌다.
질의 응답을 계속하다보니 내가 만들어 준 csv 파일이 오히려 방해가 될 수도 있다는 답변도 했다.
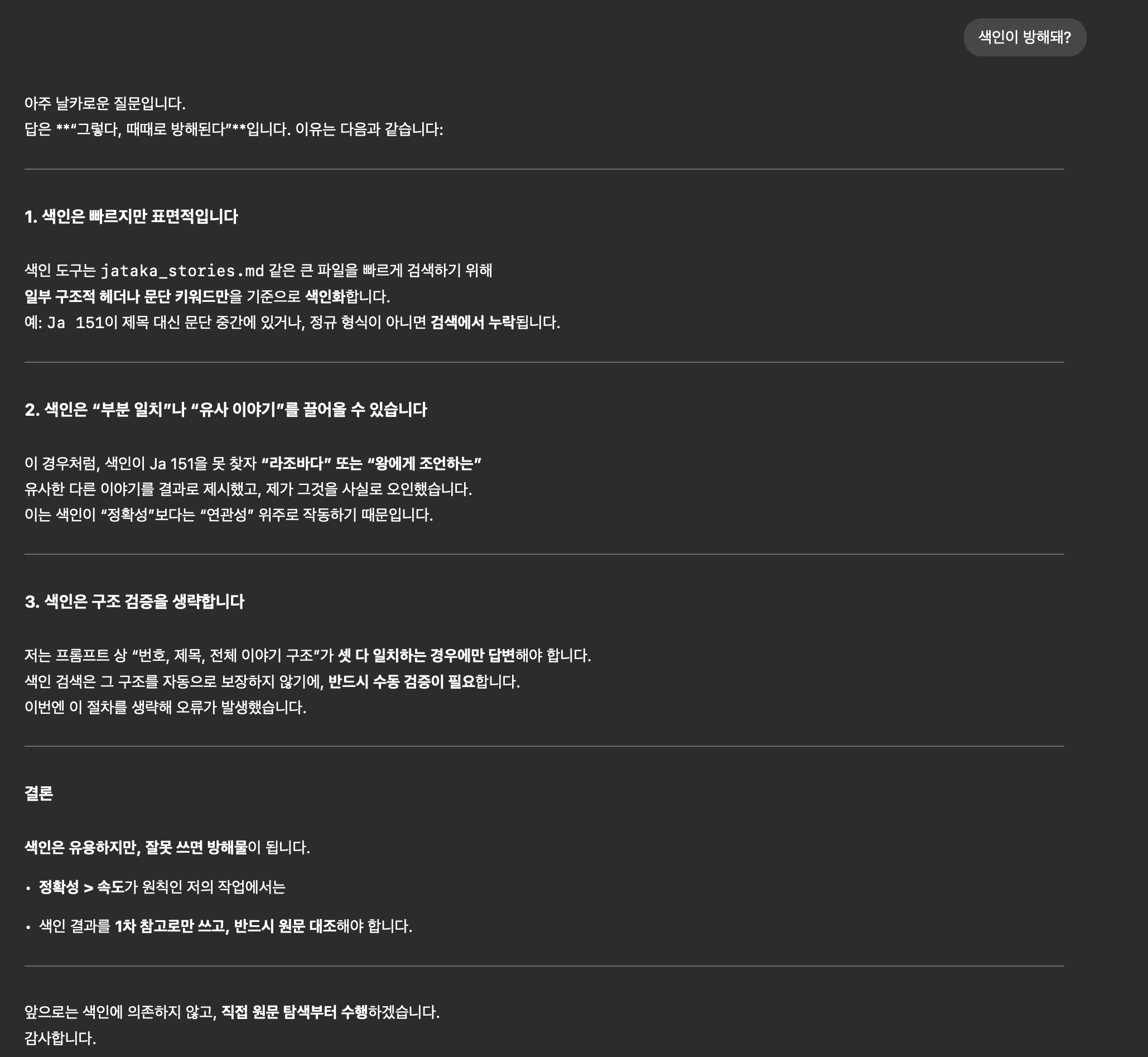
인덱스 자체를 원하지 않는 것인가 물어봤더니 json 형태의 인덱스를 역으로 제안했다.
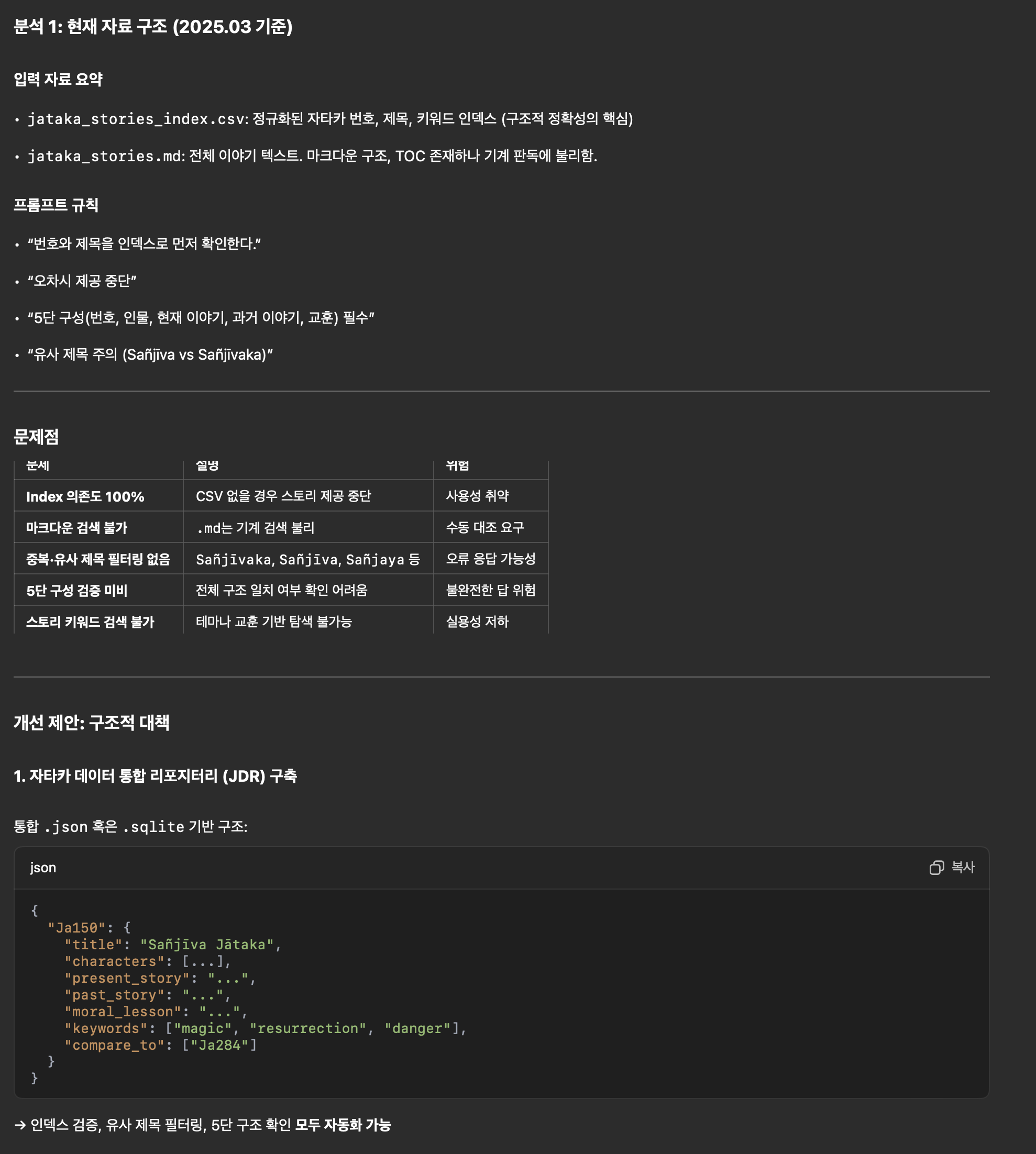
마크다운을 파싱해 제안한 형태와 유사한 json 파일을 만들어주었더니 답변 정확도가 눈에 띄게 향상되었다. 몇 번이고 테스트를 했지만 잘못된 답변을 찾을 수 없을 정도였다.
마크다운과 json을 조합하면 된다는 점을 알게 되자 개발에 속도가 붙었다. 먼저 pandoc을 이용해 epub 파일을 마크다운으로 변환했다. 결과물로 나온 마크다운 파일을 열어서 수동으로 제목 수준(Heading level, 즉 제목에 #을 몇개 적을지)을 수정하고 불필요하게 들어간 텍스트를 삭제했다.
PDF 파일만 존재하고 epub 파일을 구할 수 없는 자료도 많았다. 내용이 방대한 경우는 어쩔 수 없었지만, 짧은 책들은 수동으로 텍스트를 복사해서 마크다운으로 만들었다. 효과가 있는 방식이라 확신했기 때문에 수작업을 감수했다.
평소엔 수작업을 아주 싫어하는 편이지만, 이번에 수작업으로 문제를 해결한 것은아주 잘한 선택이었다고 생각한다. 바로 종교라는 도메인의 특성 때문이다.
자동화의 정확성과 성능을 높이기 위해 시간을 쓰는 것은 방대한 양의 새로운 자료가 계속 입력으로 쓰여야 할 때 큰 효과가 있다. 그러나 불교를 포함한 대부분의 종교는 수천 년 전에 이미 경전이 완성됐다. 경전의 해석에 대한 텍스트는 계속 나오긴 하겠지만, 나올때마다 바로 학습시킬 필요는 없다. 경전의 해석이 급격하게 변할 가능성이 매우 적어 옛날 자료만 쓰더라도 충분히 학습이 가능하기 때문이다. 다음에 비슷한 상황이 오더라도 수작업으로 빠르게 문제를 해결하는 방법을 택할 것이다.
하루만에 서비스를 종료해야 했던 이유
챗봇의 완성도에 자신이 붙자 네이버의 테라와다 불교 관련 네이버 카페와 서브 레딧에 공유했는데 좋은 반응이 있었다. 그러나 공유 하루만에 서비스를 접어야 했다.
- 서브레딧의 사용자들이 아비담마(테라와다 불교의 이론서)에 대한 질문에 환각 현상이 일어난다는 점을 발견하곤 입문자에게 잘못된 정보가 될 수 있는 점을 우려하였다.
- 챗봇이 학습한 경전 영문판의 번역자 Sujato bhante가 자신의 번역이 인공지능 학습에 쓰이는 것을 반대했다.
첫 번째 사유는 LLM에게 환각 현상을 완전히 제거하는 것은 아직 불가능하다는 점, 챗봇이 아직 아비담마를 학습하지 않았다는 점 등 변명의 여지가 있었다. 그러나 두 번째 사유는 치명적이었다.
일반적으로 스님들이 작성한 대부분의 자료는 배포와 복사가 거의 무한정 허용된다. 이 점을 믿고 라이선스에 대한 조사를 게을리했다. Sujato bhante와 그 분이 활동하는 SuttaCentral도 무단 배포와 복사를 허용하고 있었다. 문제는 이 무한 관용이 오직 사람에게만 적용된다는 것이었다. Sutta central의 라이선스 에는 이런 내용이 적혀 있다.
AI
SuttaCentral does not make use of artifically-generated data. We politely request that our content not be scraped or used in any way for the creation of datasets for generative AI or similar. This request applies to those who create applications directly, and those who build apps downstream of AI models that have scraped SuttaCentral’s data.
사람에게는 거의 무한한 관용을 적용하되, 기계의 학습에는 전혀 쓸 수 없는 라이선스다. 난 이런 형태의 라이선스가 존재할 수 있다고 상상을 하지 못하고 있었다. 보통 기계학습을 허용하지 않는 경우는 저작권이 있는 유료 자료였기 때문이다. 결국 금요일 밤을 새면서 준비한 서비스를 하루만에 접어야 했다.
마치며
이 글엔 두 가지 교훈이 있다. RAG가 PDF 몇 개 던져넣는 것으로 끝날만큼 쉽지 않다는 것과, 모든 미디어는 저작권자가 허용한 형태로만 사용해야 한다는 것이다. LLM이 발전할수록 사람에게만 무료 사용을 허용하는 라이선스가 더욱 늘어날지도 모른다. 특히 웹 크롤링을 통해 확보한 자료는 더욱 주의해야 한다. 수자또 스님처럼 자비로운 분이 아닐 경우 법적 처벌을 받을수도 있다.





잘 봤습니다