markitdown과 LLM을 이용해 pdf를 markdown으로 변환하기

연구 동기
지난 포스팅 PDF만 던져주면 끝날줄 알았다 - GPTs RAG 적용 실패기에서 마크다운과 json이 LLM이 검색하기 적합한 포맷이라는 것을 밝혔다. 그러나 해당 포스팅에서 제안한 pandoc을 이용한 변환은 pdf에 적용하기에는 한계가 있다. pandoc은 마크다운을 pdf로 변환하는 기능은 지원하지만 pdf를 마크다운으로 변환하는 기능은 지원하지 않기 때문이다. 당시에도 pdf 문서는 수동으로 복사 붙여넣기 해서 텍스트로 변환했다.
그러나 문제는 아직까지 세상에 마크다운보다 pdf로 작성된 자료가 훨씬 많다는 사실이다. 관련된 자료가 pdf 밖에 없는 경우 LLM의 조회, 검색 성능이 대폭 감소할 것을 감수해야 한다.
그런데 얼마 전 마이크로소프트에서 pdf를 마크다운으로 변환할 수 있는 markitdown을 오픈소스로 공개했다는 점을 알게 되었다. pdf를 markdown으로 자동 변환할 수 있다면 LLM 학습 자료를 만들기가 훨씬 수월해지므로 성능을 직접 실험해보게 되었다.
markitdown의 한계
markitdown이 얼마나 효과적으로 문서를 변환하는지 테스트하기 위해 이슬비 님의 무료 저자책 '미적분학 첫걸음(2022년판)'을 테스트 자료로 정했다. 수학을 주제로 고른 이유는 수식이 많이 포함되어 있는 텍스트를 잘 변환하는지 보기 위해서이다. 서문 변환 결과를 원본 pdf와 비교해보자.


변환이라고 말하기 민망할 정도로 알아보기가 어렵다.
추측컨대 markitdown은 OCR 기술을 이용해 텍스트를 추출하는 방식으로 문서를 변환했을 것이다. 문제는 pdf는 순수한 텍스트와는 거리가 너무 먼 포맷이라는 것이다. 변환 결과를 보면 페이지 숫자 같은 내용과 무관한 텍스트를 추출하고, 순서를 엉망으로 배치하는 등 원본과는 매우 다른 결과물이 나왔다. 이런 텍스트를 LLM의 검색용 자료로 줄 수 있는지 의구심이 든다.
물론 LLM이 판단하는 가독성은 사람과 그 기준이 다를 수 있다. 그러나 지난 포스팅에서 살펴본 결과 LLM은 pdf 자료에 대한 이해도가 상대적으로 낮았다. ChatGPT 내부에서 markitdown과 유사한 변환 도구를 사용할 가능성이 높다는 점을 생각해보면, 사람이 읽기 좋은 잘 정돈된 텍스트를 주는 것이 더 나을 것이다.
LLM을 이용한 보완 방법
LLM의 언어 능력을 이용하면 결과물을 상당히 개선할 수 있다. 다음의 캡처를 보면 설명과 수식을 원본에 가깝게 변환하고 마크다운의 헤딩이나 볼드체 같은 문법을 적극 활용해 가독성을 높인 것을 알 수 있다.

핵심은 markitdown으로 1차 변환한 자료를 LLM에게 재가공할 것을 요청한 것이다. 프롬프트는 다음과 같다.
prompt = f"""Your task is to refine the following raw Markdown text extracted from a PDF. Your only job is to improve its structure and formatting for better readability.
**ABSOLUTE REQUIREMENT: You MUST NOT summarize, shorten, omit, or truncate any part of the original text. The output MUST contain 100% of the original content. This is a literal conversion, not a summary. Any form of content reduction is a failure.**
Raw Markdown to be refined:
{chunk}PoC LLM으로는 gemini를 이용했다. 성능을 높이기 위해 markitdown 결과를 작은 조각으로 잘라 병렬 요청 후 병합한다.
한계
실험 방법
단 하나의 pdf 변환 결과를 실험자의 주관적인 관점으로 평가했다.
변환의 품질
첫 페이지는 완벽하게 변환한 것으로 보이지만 보다보면 깨진 폰트가 나오는 등 수식 변환에는 한계가 있다.
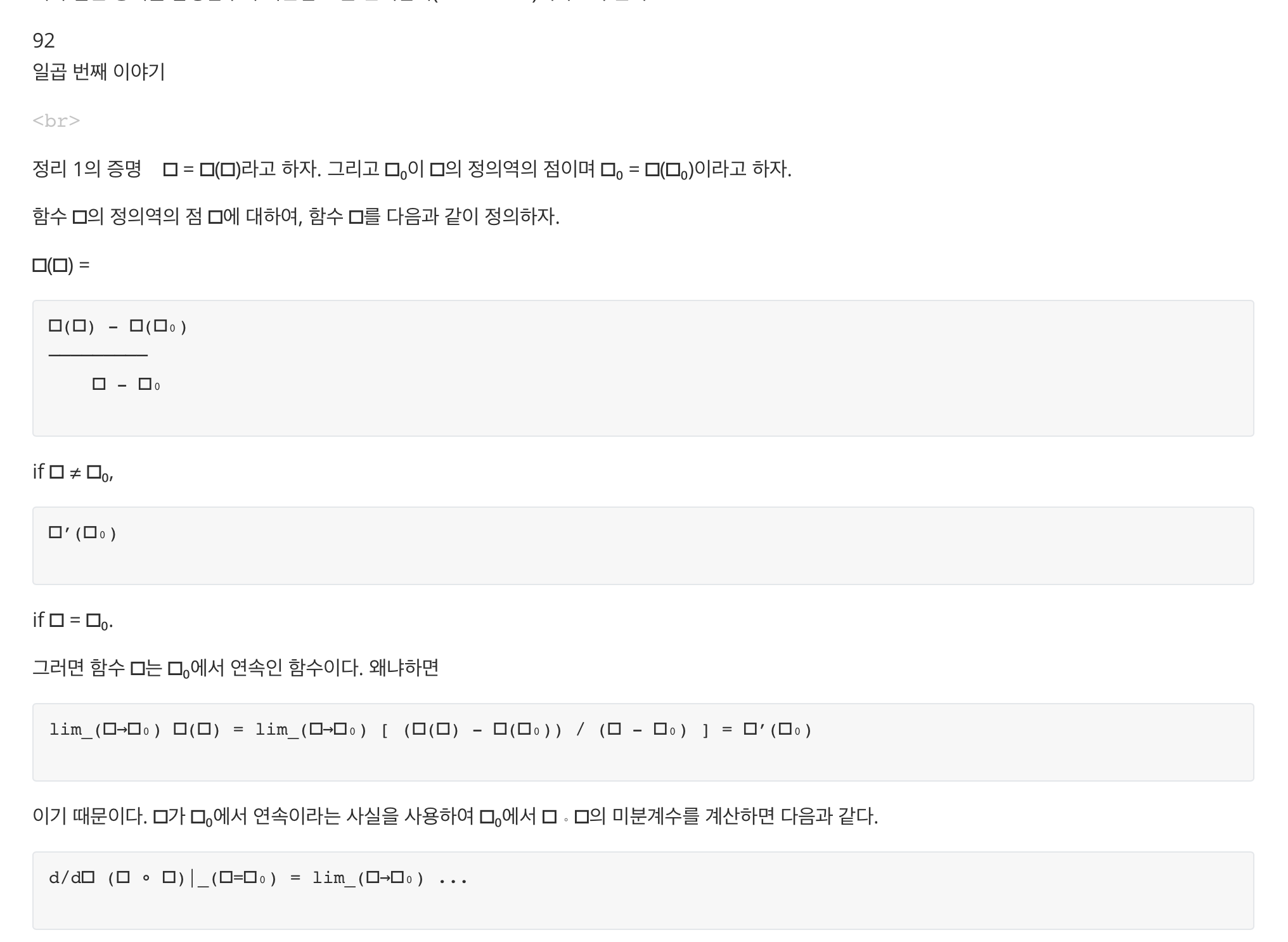
이미지도 담지 못한다. markdown이 순수 텍스트 포맷이라는 것을 감안하면 당연하다.
markdown 변환에 적합한 pdf는 다단 레이아웃이 없는, 순수 텍스트 위주의 문서이다. 각주가 일반 텍스트와 구분되지 않고 들어가므로, 각주보다는 미주를 사용한 자료가 더 자연스럽게 변환될 것이다.
소스코드
https://github.com/computerphilosopher/pdf-to-markdown-by-llm
(참고: 이 소스 코드는 100% gemini가 작성한 것이다. 질문도 나 대신 gemini에게 하는 것이 좋겠다.)
