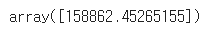Polynomial Regression
Importing the libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltImporting the dataset
dataset = pd.read_csv('/content/Position_Salaries.csv')
X = dataset.iloc[:,1:-1].values # X의 행렬특성(변경하려는 부분)
# 두번째 열부터 시작해서 마지막 열을 제외한 모든 열을 출력
y = dataset.iloc[:,-1].valuesTraining the Linear Regression model on the whole dataset
#선형회귀 모델을 전체 데이터 세트에 훈련시킴
#데이터 세트에 대해 훈련된 모델을 갖게 됨
from sklearn.linear_model import LinearRegression
# 이 클래스의 객체 생성 --> 회귀자(선형회귀 / 다항회귀)
lin_reg = LinearRegression() # 매개변수x (선형회귀모델에서 튜닝할 부분 많지 않기 때문)
lin_reg.fit(X,y) # test_set와 train_set로 나누지 않는 이유 (특성행렬 X 전체와 전체 종속 변수 벡터 y를 취함)lin_reg,fit(X,y) 선형회귀모델을 훈련시킴
데이터를 훈련 및 테스트 세트로 나누지 않고 전체 데이터에 대해 훈련
Training the Polynomial Regression model on the whole dataset (다항회귀모델)
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 2)
# x1만 포함된 단순한 행렬 특성을 변환
X_poly = poly_reg.fit_transform(X) #괄호 안 : 변환하려는 특성행렬. 즉, 제곱된 특성들의 행렬
lin_reg_2 = LinearRegression()
lin_reg_2.fit(X_poly, y)
-
poly_reg = PolynomialFeatures(degree=2)
: 다항 특성을 만들 때 사용되며degree매개변수는 생성할 다항 특성의 최고차수를 지정하며 2차 다항 특성 생성 -
X_poly = poly_reg.fit_transform(X)
:fit_transform메서드를 사용해 입력 변수 행렬X를 다항 특성 행렬X_poly로 변환
-
lin_reg_2 = LinearRegression()
: 선형 회귀 모델 생성 위해LinearRegression클래스의 인스턴스lin_reg_2생성 -
lin_reg_2.fit(X_poly, y)
: 다항 특성 행렬X_poly와 종속 변수 벡터y를 사용해 선형 회귀 모델을 훈련
--> 다항 특성을 사용해 더 복잡한 데이터 패턴 모델링 시도,,
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 4)
# x1만 포함된 단순한 행렬 특성을 변환
X_poly = poly_reg.fit_transform(X) #괄호 안 : 변환하려는 특성행렬. 즉, 제곱된 특성들의 행렬
lin_reg_2 = LinearRegression()
lin_reg_2.fit(X_poly, y)** 4차 다항 특성을 사용하여 더 복잡한 데이터 패턴을 모델링
-
X_poly = poly_reg.fit_transform(X)
:fit_transform메서드를 사용해 입력 변수 행렬X를 4차 다항 특성 행렬X_poly로 변환 -
lin_reg_2.fit(X_poly, y)
: 4차 다항 특성 행렬X_poly와 종속 변수 벡터y를 사용해 선형 회귀 모델을 훈련
--> 4차 다항 특성을 사용해 데이터의 복잡한 비선형 패턴 모델링 시도,,
degree매개변수를 2에서 4로 바꾼 이유
1. 데이터가 비선형 패턴을 가지고 있거나 2차 다항식으로는 잘 설명되지 않는 경우, 고차 다항 특성을 사용하여 모델이 데이터에 더 잘 적합되도록 할 수 있음
2. 2차 다항 회귀 모델은 데이터를 충분히 설명하지 못할 수 있으며, 이로 인해 과소적합(underfitting) 문제가 발생할 수 있습니다. 따라서degree를 높여 더 복잡한 모델을 사용하여 이를 해결
Visualising the Linear Regression results
#lin_reg_2 : 다항회귀모델
#lin_reg : 선형회귀모델
# 선형회귀가 적합하지 않음
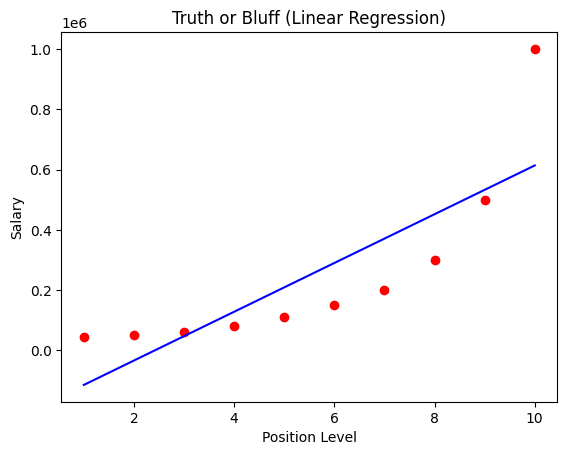
plt.scatter(X, y, color = 'red')
plt.plot(X, lin_reg.predict(X), color = 'blue')
plt.title('Truth or Bluff (Linear Regression)')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()<결과> 잘못됨
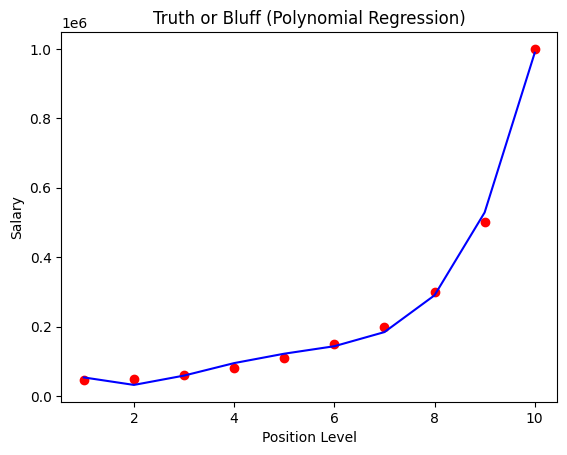
plt.scatter(X, y, color='red')
plt.plot(X, lin_reg_2.predict(poly_reg.fit_transform(X)), color = 'blue')
plt.title("Truth or Bluff (Polynomial Regression)")
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()<결과> 적합
🔥🔥 다항 회귀는 선형 회귀보다 더 복잡한 비선형 데이터 패턴을 캡처할 수 있는 모델
- 데이터의 비선형성
- 데이터의 차수와 모델의 복잡성 :
degree매개변수를 높일수록 모델의 복잡성 증가.
데이터가 다항식과 유사한 패턴을 따를 때, 높은 차수의 다항 회귀 모델이 데이터를 더 정확하게 모델링
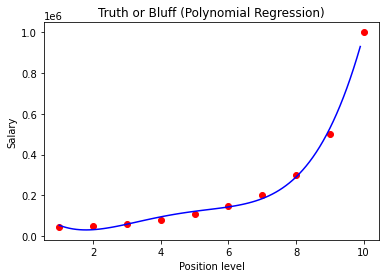
Visualising the Polynomial Regression results (for higher resolution and smoother curve)
X_grid = np.arange(min(X), max(X), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, lin_reg_2.predict(poly_reg.fit_transform(X_grid)), color = 'blue')
plt.title('Truth or Bluff (Polynomial Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()<결과>
Predicting a new result with Linear Regression
💡 사람은 16만 달러의 연봉을 요구함
lin_reg.predict([[6.5]])<결과>
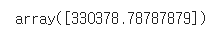
- 결과는 잘못된 예측
Predicting a new result with Polynomial Regression
lin_reg_2.predict(poly_reg.fit_transform([[6.5]]))<결과>