
KOCW에 공개된 영남대 최규상 교수님 컴퓨터 구조 강의를 수강 후 정리한 내용입니다.
5.3 The Basics of Caches
1. Cache Memory
- CPU에 가장 근접한 메모리 종류 중 하나

- Main memory는 6bit로 구성
- main memory의 하위 두 비트는 word를 정의하는데 사용됨. 중간의 두 비트는 cache의 index 정보로 사용. 상위 두 비트는 cache의 tag 값으로 들어감
- cache는 4 blocks으로, 메인 메모리는 16 blocks으로 구성. 메인 메모리의 4 blocks이 cache의 하나의 line에 매핑됨
- block address를 cache의 block의 수로 나눠서 modulo operation(나머지 연산)을 취하면 cache의 index 값이 나옴
Is it there?
- access하고자하는 명령어 혹은 data의 주소가 cache에 들어오면 주소 값 index가 같은 라인을 찾은 후 cache의 tag 값을 비교해 같으면 해당 tag의 data를 사용
- tag의 값과 같은 경우 hit, 다른 경우 miss 발생
Direct Mapped Cache
- cache의 line이 하나의 block만 가지는 경우
- Direct mapped: 메모리 주소가 cache의 어느 line에 매핑되는지는 메모리 주소에 의해 결정됨
- (block address) % (number of blocks in cache)에 매핑
- block의 수는 2의 제곱으로 구성
2. Tags and Valid Bits
- cache 안에 들어있는 것이 어느 메모리에 매핑된 block인지 알아야 할 때 tag를 사용
- high order bit를 사용
- data와 block addressd의 tag 값을 cache에 저장
- tag에 해당되는 값이 없으면 valid bit은 0, 데이터가 있으면 1
- valide bit이 1이면 데이터가 유효하다는 것
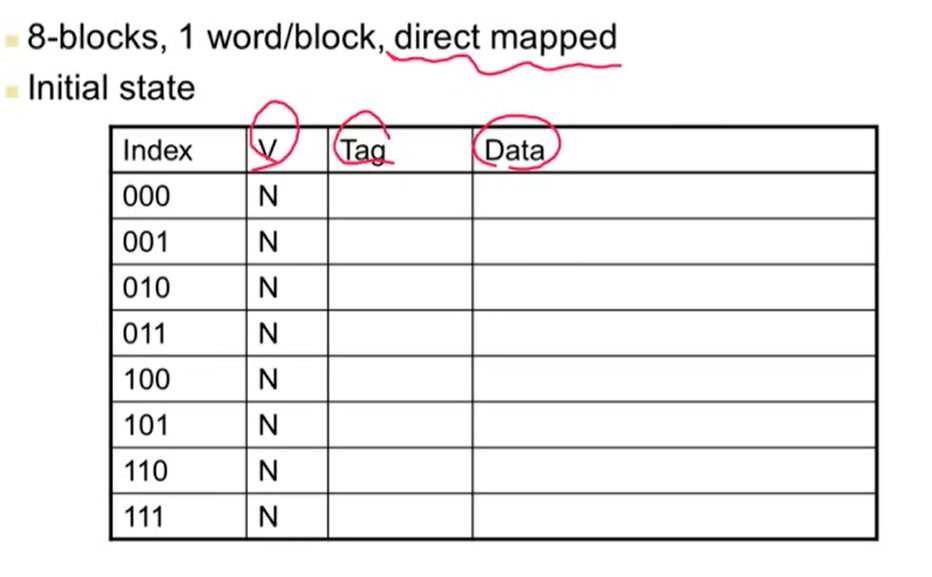
- 처음 컴퓨터를 키면 모든 cache에 있는 validate bit은 0(N)으로 설정됨
- 메인 메모리의 값을 cache로 가져오면 1이 됨
Cache Example
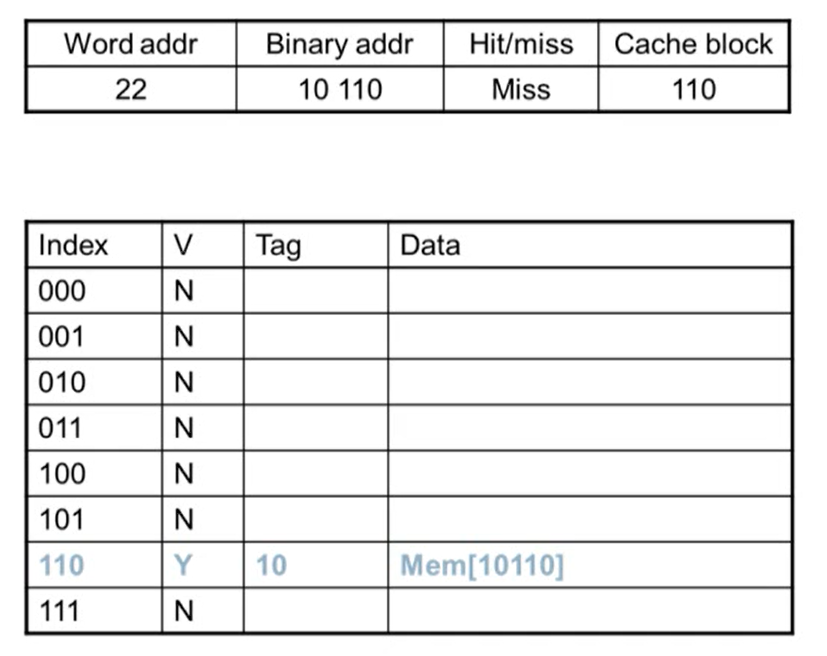
- word addr: block address
- 어느 line에 해당되는지 알기 위해 binary addr를 8로 나눈 나머지 연산을 수행
- 연산을 수행하면 하위 3bit의 값이 그대로 나옴
- block이 8개이기 때문에 하위 3bit가 그대로 나옴. block이 4개면 하위 2bit, 16개이면 하위 4bit이 나옴
- Miss: Valid bit가 N인 경우 무조건 miss가 발생
- miss가 발생하면 메인 메모리에서 데이터를 읽어와 cache에 copy
- copy되면 valid bit이 1이 되고 tag는 cache block 값을 제외한 상위 bit가 저장됨
- 메모리 주소에 있는 데이터를 data에 저장
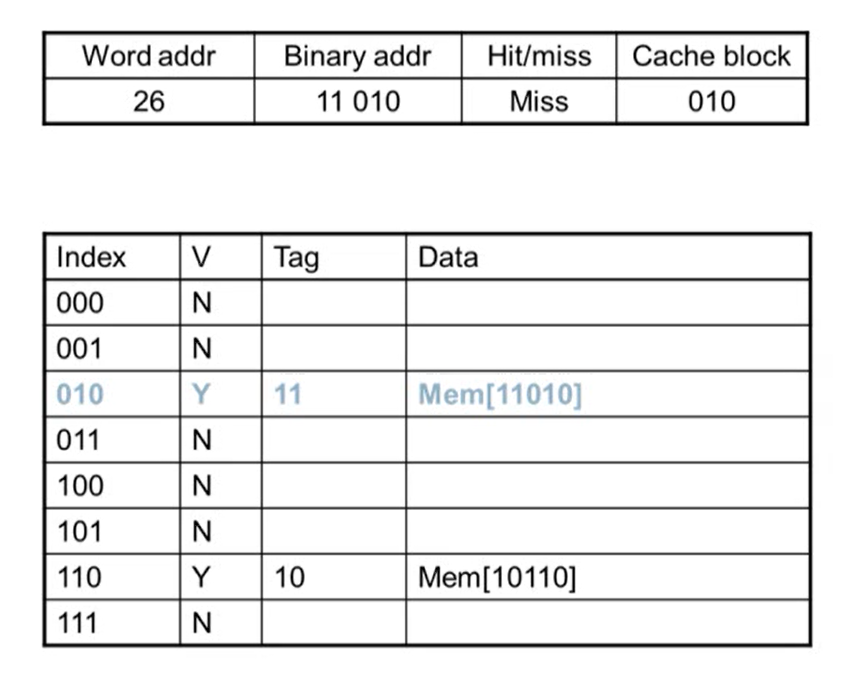
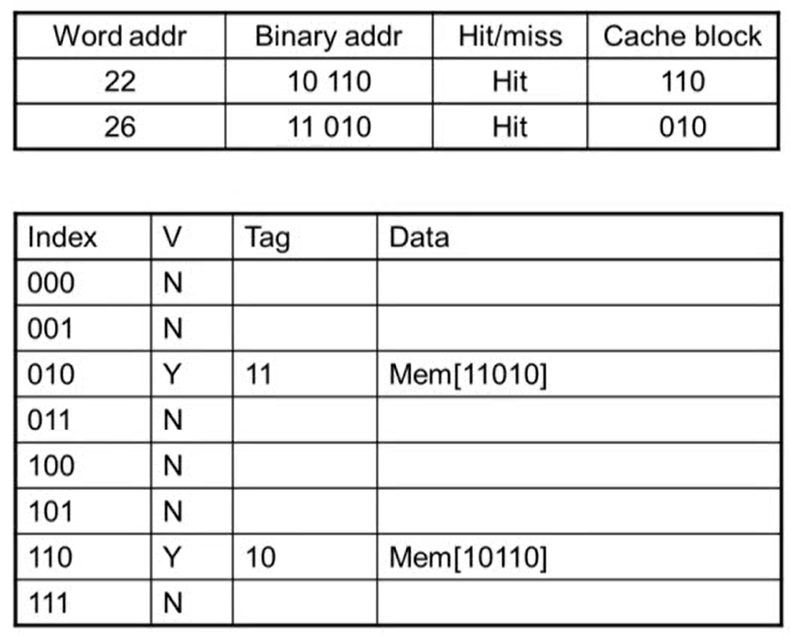
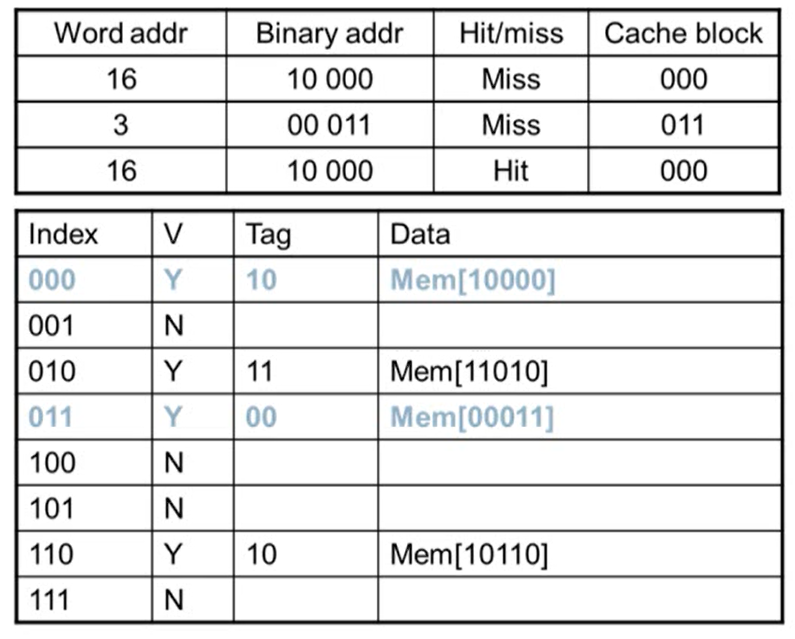
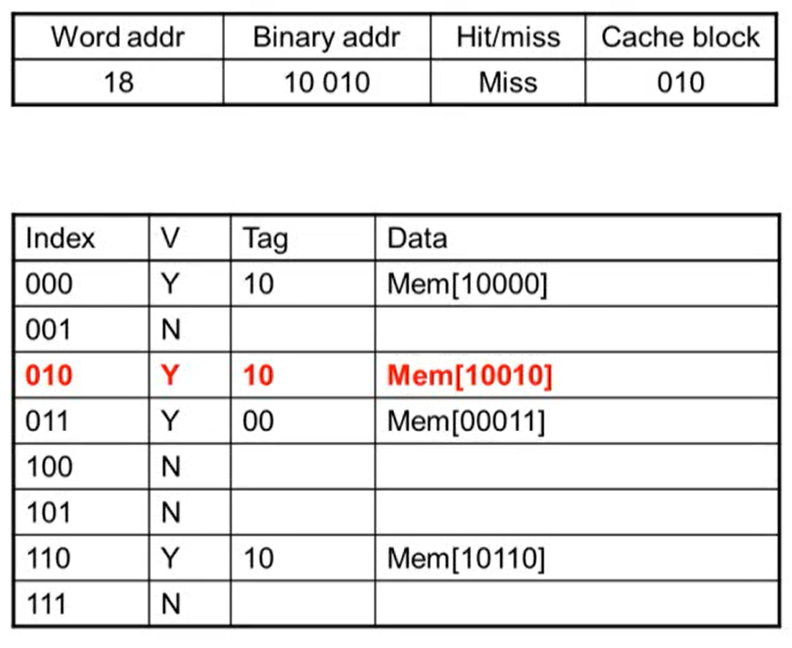
- index의 값은 같지만 tag 값이 같지 않아 valid bit이 Y임에도 불가하고 miss가 발생
- access한 후 tag, data 값이 변경됨
3. Block Size Considerations
- block size를 키우면 miss rate이 발생할 확률이 줄어듦
- cache의 크기가 고정되어 있는 상태에서 block size를 키우면 line의 수가 줄어들게 되고, line의 수가 줄어든다는 것은 더 많은 메모리가 하나의 cache line에 매핑되서 competition의 수가 증가하므로 miss rate이 발생할 확률이 높아짐
- block의 크기가 커지면 다양한 block 안에 read/write이 발생해 block이 업데이트되서 refresh될 때 overhead가 더 커질 수 있음
- block의 수가 커지면 miss가 발생했을 때 한번에 더 많은 블럭을 읽어와야함
- 하나의 block이 1 word인 경우 1 word만 읽어오면 되지만, 하나의 block이 8 word로 되어 있으면 miss가 발생할 때마다 8개의 word를 한 번에 불러와야 함
- 이럴 경우 miss penalty가 더 커지게 됨
- 이를 해결하기 위해 여러 word 중 miss가 발생한 word를 먼저 보내고 나머지 word는 나중에 보냄. 나머지 word가 올 때까지 기다리지 않고 access하고자 하는 word가 도착하면 바로 시작 => miss penalty 감소
4. Cache Misses
- hit이 발생한 경우 CPU는 그대로 진행
- miss가 발생하게 되면
- CPU의 pipeline은 멈추게 됨
- low-level에 가서 해당 명령어를 가지고 옴
- instruction cache miss인 경우 그 명령어의 fetch를 다시 시작하고, data cache miss인 경우 data access를 완료함
5. Write-Through vs Write-Back
1. Write-Through cache
- data-write가 hit인 경우 cache의 block를 update. 이럴 경우 cache의 내용과 메모리의 내용이 달라지게 되는데 이를 해결하는 방법이 Write-Through
- Write-Through: cache를 update할 때 memory도 함께 update하는 방식
- write through의 경우 write하는 속도가 느려짐
- 속도가 느려지는 문제를 해결하는 방법은 write buffer를 사용하는 것
- write buffer: cache에 아주 작은 buffer를 추가해 memory에 써야할 내용을 memory에 쓰지 않고 buffer에 쓴 후 buffer에서 다시 memory에 씀
- 이 때 CPU는 wirte buffer에 memory에 쓸 내용을 쓰면 바로 시작할 수 있음. 따라서 메인 메모리에 데이터를 쓸 때까지 기다리지 않아도 됨
- write buffer가 꽉 찬 경우 write buffer의 내용을 메모리에 쓴 후 없애주어야 함. write buffer의 내용을 하나 빼서 메모리에 쓸 때까지 CPU는 기다려야하는 상황이 발생
2. Write-Back cache
- cache만 update를 수행. 이럴 경우 cache의 data와 메인 메모리의 data가 달라지기 때문에 cache의 data와 메모리의 data가 같은지 다른지를 파악해야 함
- 파악하기 위해 dirty bit를 추가. cache의 data가 update된 경우 dirty block이 replace되면 dirty block의 data를 메모리에 씀
- write back에서도 write buffer 사용 가능
6. Write Allocation
- write를 하는데 miss가 발생하는 경우 (write through에서는)
- allocate on miss: miss가 발생했을 때 해당되는 데이터를 가져온 후 update (fetch the block)
- write around: cache에 쓰지 않고 바로 메모리에 쓰는 방식 (block를 fetch하지 않음)
- 전체 메모리를 초기화하는 프로그램이 있다고 했을 때, 이럴 경우에는 block를 다시 사용할 확률이 낮아짐. 이럴 때 miss가 발생했다고 하더라도 cache에 올리지 않고 바로 메모리에 쓰는 것이 나음
- write back의 경우 대부분 block를 fetch함
5.4 Measuring and Improving Cache Performance
1. Measuring Cache Performance
- cache를 사용하면 CPU 성능을 향상시킬 수 있음
- CPU time은 아래 두 시간을 포함
- program execution cycle은 cache hit time를 포함
- memory stall cycle: cache miss가 발생해 메모리에 접근하는 시간

1. Average Memory Access Time (AMAT)
- hit time은 성능에서 가장 중요한 요소

- 명령어당 메모리를 access하는데 두 cycle이 필요
2. Performace Summary
- CPU Performace를 향상 시키기 위해서는 miss penalty의 값이 점점 더 중요해짐
- base CPI (100% hit)을 감소시키면 전체 시간에서 memory stall이 차지하는 시간의 비율이 증가함
- Clock rate를 높이면 memory stall에 걸리는 CPU cycle이 더 많아짐
- 어떤 system의 성능을 평가할 때는 cache의 영향을 꼭 고려해야 함
2. Associative Caches
- 지금까지 다룬 cache는 direct mapped cache(하나의 cache line에 하나의 block만 가지는 구조)
- Associative caches: 하나의 cache line에 여러 block를 가지는 구조
1. Associative caches 종류
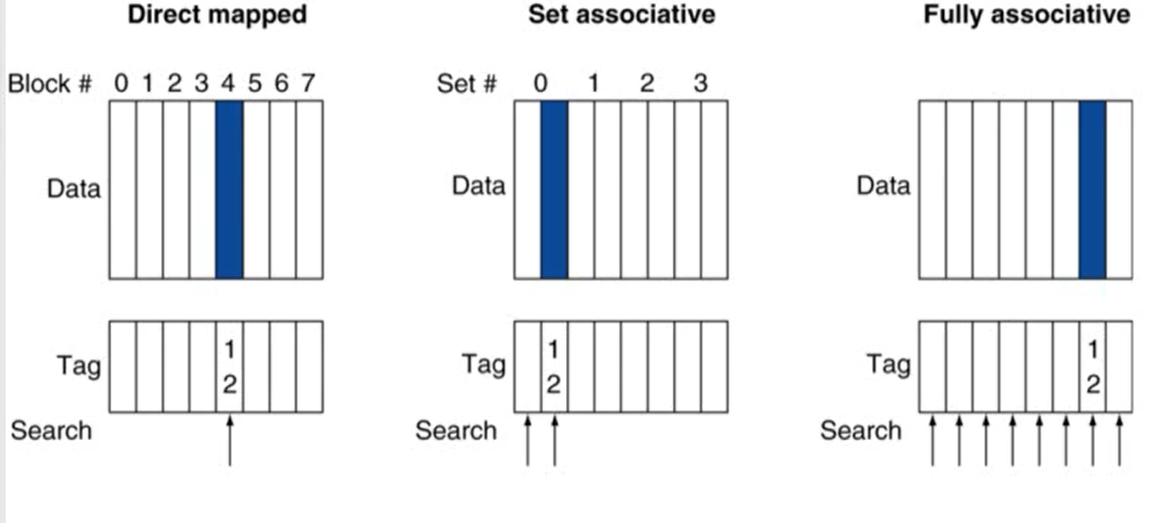
-
entry: tag + data
-
Fully associative
- set이 하나인 경우
- 특정 block이 cache의 어느 entry에도 들어갈 수 있음
- 모든 cache entry를 비교해야 함
- entry가 많아질수록 많은 비교 연산이 필요해 비용이 비싸짐
-
n-way set associative
- 하나의 set(cache line)은 n개의 entry로 구성
- block number는 어느 set에 매핑이 될지 결정 (block number % cache set number)
- 해당 set에 들어있는 모든 entry를 비교
- 따라서 n개의 comparator가 필요
2. Spectrum of Associativity

3. Associativity Example
- 4개의 block caches가 있다고 가정
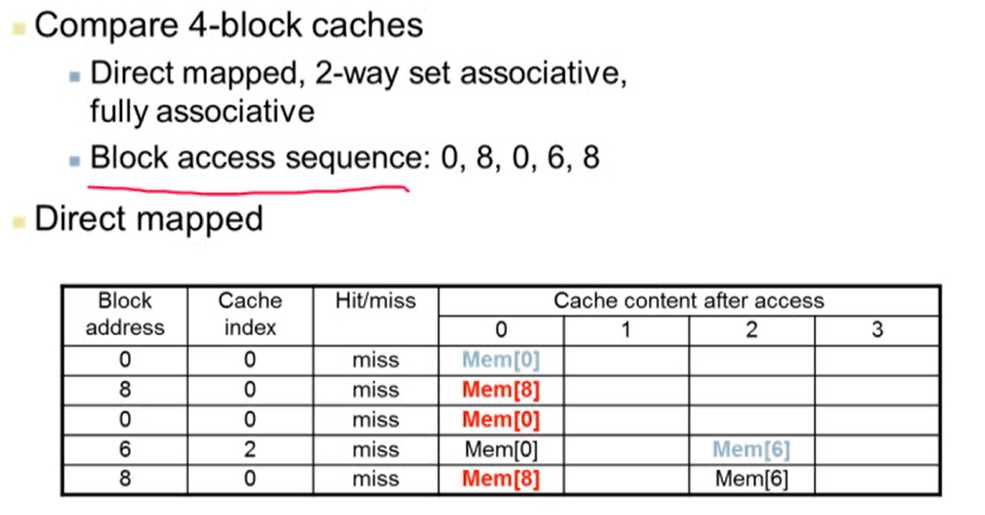
- Cache index는 (block address % 4)를 계산한 값
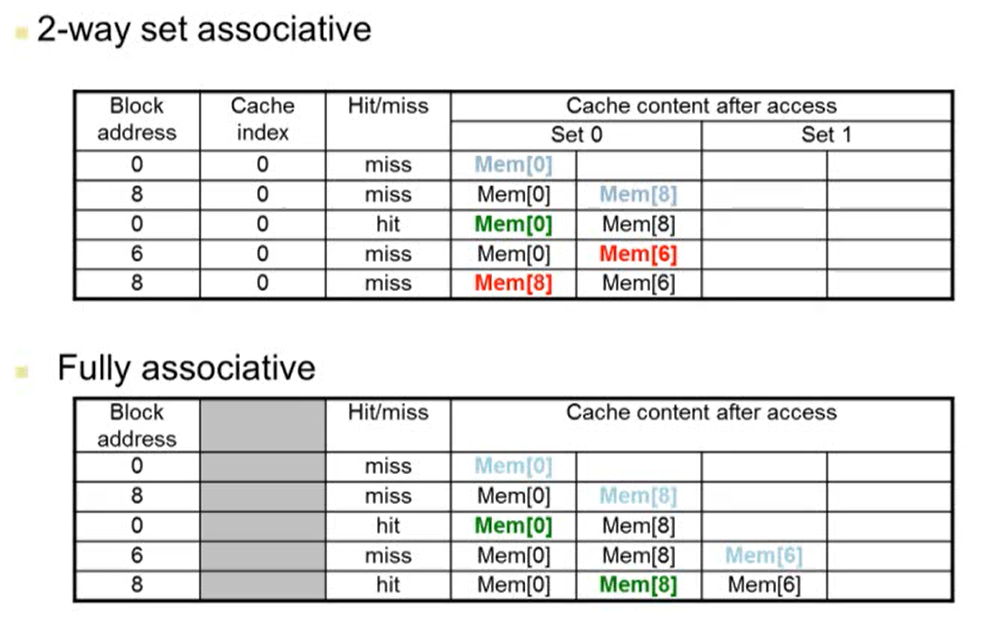
- 2way set associative에서 Cache index는 (block address % 2)를 계산한 값
- 2way set associative에서 block address 6의 값을 cache에 넣을 때 MEM[8]이 바뀌는 이유는 오래된 것을 replace하기 때문
4. How Much Associativity
- associativity를 증가시키면 miss rate는 감소하게 됨
4. Replacement Policy
- cache miss가 발생할 경우 어떤 block를 replacement할지에 대한 규칙
1. direct mapped: 다른 선택권이 없음
2. set associative
- non-valid entry가 있으면 이것을 replace
- entry가 모두 valid인 경우 하나의 entry를 선택해야하는데 이 때 가장 많이 사용하는 알고리즘이 LRU
- least-recently used (LRU): 사용한지 가장 오래된 entry를 선택
- 실제 구현할 때 쉽지 않음. 2way와 4way의 경우 구현 가능하지만 그 이상은 힘듦
- Random: entry를 random하게 선택
- 구현하기 쉬움
- 8way 이상부터는 LRU와 유사한 성능을 보임
5. Interactions with Advanced CPUs
- out of order CPU의 경우 cache miss가 발생한 동안 다른 명령어 실행이 가능
- cache miss와 관련된 명령어는 reservation station에서 대기하고 관련 없는 명령어는 계속 실행
- miss는 program의 data flow에 따라 달라짐
12주차 강의 끝!!!
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자