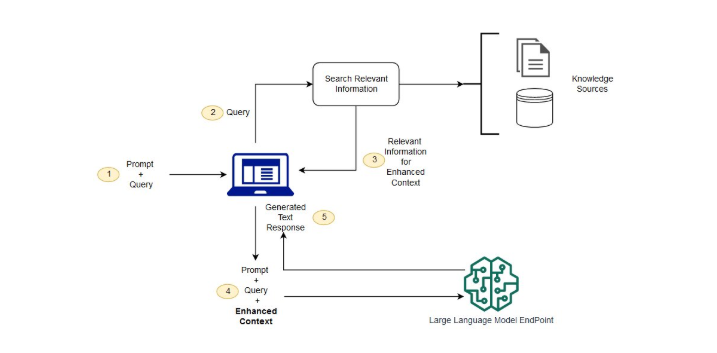
1. 정형에서 비정형으로
정형 데이터
-
특징: 관계형 데이터베이스처럼 엄격한 스키마에 따라 저장된 데이터입니다.
컴퓨터가 해석하기 매우 쉽고 대규모 처리가 용이합니다. -
한계: 현실 데이터의 80%는 정형화하기 어려운 비정형 상태입니다.
정형화 과정에서 중요한 정보가 버려지거나, 초기 설계에 갇혀 변화에 대응하기 어렵습니다.
비정형 데이터와 벡터화
- 해결책: NoSQL이나 벡터화 방법론을 사용합니다.
- 벡터화의 핵심: 사람이 데이터를 이해하는 방식을 통계적으로 흉내 냅니다. 예를 들어, '사과'라는 단어를 단순 텍스트가 아니라
[당도, 색상, 식감]이라는 차원으로 나누어[5, 9, 8]과 같은 수치로 표현하는 것입니다.
2. 밀집 벡터와 정규화
임베딩 모델은 의미를 압축하여 밀집 벡터로 만듭니다. 이때 계산의 편의와 정확도를 위해 L2 정규화를 수행합니다.
L2 정규화
- 목적: 벡터의 방향은 유지하되, 길이를 1로 맞추는 작업입니다.
- 계산법: 각 원소를 벡터의 전체 길이()로 나눕니다.
- 결과: 정규화된 벡터의 L2 Norm을 계산하면 항상 이 됩니다.
3. 코사인 유사도
벡터 간의 "의미적 유사성"을 측정할 때 가장 많이 쓰이는 방식입니다.
- 핵심 원리: 두 벡터 사이의 각도를 측정합니다.
- 특징: L2 정규화가 된 벡터라면, 복잡한 분모 계산 없이 내적만으로 유사도를 구할 수 있습니다.
- 값이 1에 가까울수록 (0도): 매우 유사 (예: "강아지"와 "개")
- 값이 0에 가까울수록 (90도): 관계없음
- 값이 -1에 가까울수록 (180도): 반대 의미
예시:
A [0.6, 0.8]와B [0.8, 0.6]의 내적 = (매우 유사, 약 16도)A [0.6, 0.8]와C [0.6, -0.8]의 내적 = (낮은 유사도, 약 106도)
4. 모델의 벡터 학습
AI 모델은 어떻게 유사한 데이터끼리 가깝게 배치할까요? 바로 손실함수를 이용한 학습입니다.
- 데이터 구조:
- Anchor: 기준 데이터 (예: "강아지가 공을 쫓는다")
- Positive: 유사한 데이터 (예: "개 한 마리가 장난감을 따라간다")
- Negative: 관련 없는 데이터 (예: "주식 시장 폭락")
- 학습 목표: 앵커와 포지티브는 가깝게(), 앵커와 네거티브는 멀게 수치가 나오도록 모델의 가중치를 조정합니다.
5. 벡터 데이터베이스와 HNSW 인덱싱
수억 개의 벡터 중에서 유사한 것을 빠르게 찾기 위해 HNSW 알고리즘을 사용합니다.
HNSW의 작동 원리
- 그래프 구조: 벡터들을 노드로 연결합니다. 이때 가까운 노드끼리 링크를 형성합니다.
- 계층 구조:
- 상위 레이어: 노드 수가 적고 간격이 넓어 "성긴 탐색"
- 하위 레이어: 노드 수가 많고 촘촘하여 "정밀 탐색"
- 탐색 과정: 마치 고속도로를 타고 근처 도시까지 간 뒤, 일반 도로로 내려와 목적지를 찾는 것과 같습니다.
6. 비정형 데이터 정제
벡터 DB를 제대로 활용하려면 데이터 정제가 필수입니다.
- 청킹: 방대한 문서를 의미 단위로 적절히 자르는 과정입니다.
- 메타데이터 보강: 소스 정보, 생성일, 태그 등을 추가하여 검색 정확도를 높입니다.
- AI 기반 정제: LLM을 사용하여 문서의 요약본을 만들거나 키워드를 추출하여 임베딩 품질을 높입니다.
7. 고속 탐색의 원리
HNSW는 Skip List의 계층 구조와 Navigable Small World 그래프의 특징을 결합한 알고리즘입니다.
계층적 구조
- Layer 0: 모든 데이터가 포함된 가장 촘촘한 그래프입니다.
- Upper Layers: 아래로 내려갈수록 데이터 밀도가 높아지며, 상위 레이어는 징검다리 역할을 합니다.
- 작동 방식: 상위 레이어에서 목적지와 가장 가까운 진입점을 찾은 후, 한 단계 아래 레이어로 내려가 그 지점부터 다시 근방을 탐색합니다.
탐색 알고리즘
- Greedy Search: 현재 노드의 인접 노드 중 와 가장 가까운 노드를 선택합니다.
- Stopping Condition: 인접한 모든 노드가 현재 노드보다 에서 더 멀어지면 해당 레이어에서의 탐색을 멈추고 하위 레이어로 이동합니다.
- 결과: 이 과정을 반복하여 Layer 0에 도달하면 최적의 근사 이웃을 반환합니다.
8. Bi-Encoder
최신 검색 모델에서 주로 사용하는 Bi-Encoder 구조는 두 문장을 각각 독립적으로 인코딩한 후 코사인 유사도를 계산합니다.
구조적 특징
- 인코딩: 문장 A와 문장 B를 동일한 가중치를 공유하는 BERT 모델에 입력합니다.
- 풀링: BERT의 출력 주로 CLS 토큰이나 토큰들의 평균을 하나의 고정된 크기의 벡터 로 변환합니다.
- 유사도: 두 벡터 사이의 코사인 유사도를 구합니다.
9. InfoNCE Loss
이미지 8번에서 언급된 손실 함수의 정식 명칭은 Information Noise Contrastive Estimation입니다.
모델이 "정답은 가깝게, 오답은 멀게" 학습하도록 강제하는 핵심 수식입니다.
수식 설명
- : 앵커와 포지티브 간의 코사인 유사도.
- : 앵커와 네거티브 간의 유사도.
- Temperature: 소프트맥스 분포의 선명도를 조절하는 하이퍼파라미터입니다. 값이 낮을수록 유사도 차이에 더 민감하게 반응합니다.
작동 원리: 이 수식은 분모중 분자가 차지하는 비중을 최대화하라는 의미입니다.
즉, 정답과의 유사도는 높이고, 오답들과의 유사도 합은 낮추도록 역전파가 일어납니다.
10. 추천 시스템
평균 벡터를 활용한 추천 시스템의 시나리오는 다음과 같습니다.
- 사용자 행동 수집: 사용자가 최근 구매한 상품 3개의 벡터가 라고 가정합니다.
- 사용자 프로필 생성: 로 사용자의 현재 취향을 대표하는 Mean 벡터를 만듭니다.
- 검색: 벡터 DB에서 과 코사인 유사도가 가장 높은 상품 벡터들을 검색합니다.
- 효과: 개별 상품 하나하나를 비교하는 것보다 연산량이 적으면서도, 사용자의 복합적인 취향(선형성)을 반영한 추천이 가능해집니다.
