1. "의미의 공간을 설계하는 법"
초기 임베딩은 단순히 단어를 숫자로 바꾸는 수준이었으나, 현재는 문맥과 지시사항(Instruction)을 이해하는 수준으로 발전했습니다.
- 손실 함수와 대비 학습:
- 과거: 앵커-긍정-부정 쌍을 학습했으나, 랜덤하게 뽑힌 '부정셋'은 변별력이 낮았습니다. (예: '사과'의 부정셋으로 '우주선'을 주면 학습이 너무 쉬움)
- 현재: '사과'와 비슷해 보이지만 다른 '배'나 '복숭아'를 부정셋으로 주어 모델이 미세한 차이를 구분하게 합니다.
- 발전된 기법:
- Instruction Embedding: "이 문장을 주제 분류를 위해 임베딩해"와 같이 지시어에 따라 벡터 추출 방식이 달라집니다.
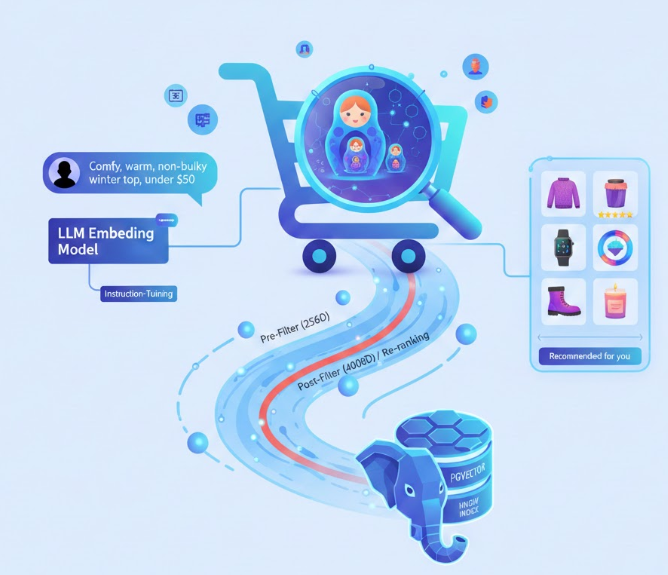
- MRL: 마트료시카처럼, 큰 벡터 안에 작은 벡터 정보가 중첩되게 설계합니다. 앞쪽 64차원만 잘라도 전체 의미의 핵심이 담기도록 학습합니다.
2. "인코더 vs 디코더"
모델의 구조에 따라 정보를 응축하는 방식이 다릅니다.
- 인코더 기반: 모든 토큰을 동시에 보고 서로의 연관성을 계산합니다. 모든 토큰 벡터의 평균을 내는 것이 효과적입니다.
- 디코더 기반: 이전 토큰이 다음 토큰만 보는 특성상, 마지막 토큰에 전체 문맥이 집약됩니다.
- NV-Embed-v2: Latent Attention Pooling이라는 특수 레이어를 추가해, 단순히 마지막 토큰만 쓰는 대신 중요한 정보만 '추출'하여 고성능을 냅니다.
3. "압축의 미학"
MRL은 검색 시스템의 비용과 속도를 혁신적으로 줄여줍니다.
- 작동 원리: 3072차원의 큰 벡터를 학습시킬 때, 64, 128, 256차원 등 구간별로 손실 값을 계산하여 합산합니다. 결과적으로 앞부분 차원일수록 더 많은 정보와 가중치를 갖게 됩니다.
- 효과: * Qwen3 8B 예시: 4096차원을 다 쓰면 성능이 73.5점이지만, 256차원만 써도 70.8점이 나옵니다.
- 실무: 먼저 256차원으로 빠르게 후보군을 추리고, 상위 10개만 4096차원으로 정밀 재정렬할 수 있습니다.
4. 키워드 검색 vs 벡터 검색
전통적인 키워드 검색은 '정확한 단어 일치'에 집착하며, 이를 위해 문장을 쪼개는 토크나이징이 핵심입니다.
-
토크나이저의 진화: 공백 분리 → 형태소 분석 → LLM용 BPE.
-
BM25 알고리즘: 단어가 문서에 얼마나 자주 나오는지와 얼마나 흔한 단어인지를 계산해 점수를 매깁니다.
-
예시: "사과를 먹었다"에서 '사과'는 중요하지만 '먹었다'는 흔하므로 낮은 점수를 부여.
5. "맥락의 벽"
키워드 검색은 "배가 아프다"와 "배가 바다 위에 있다"를 구분하지 못합니다.
이를 보강하기 위한 기법들은 다음과 같습니다.
- Query Expansion: 사용자가 '자동차'를 검색하면 '차량', '승용차'도 함께 검색합니다.
- NER : 문장에서 '삼성전자'가 회사명임을 미리 인식하여 검색 범위를 좁힙니다.
- 엔트로피 문제: 자연어의 모호함은 정보 부족이 아니라 문맥에 따른 해석 가능성이 높기 때문입니다. 이를 해결하기 위해 검색 히스토리를 결합합니다.
6. Pre-Filter vs Post-Filter
벡터 검색과 메타데이터 필터(예: '2025년 작성된 문서만')를 결합할 때의 전략입니다.
| 전략 | 설명 | 장점 | 단점 |
|---|---|---|---|
| Pre-Filter | 미리 대상을 줄이고 벡터 검색 | 정확한 결과 보장 | 인덱스 최적화가 깨져 속도가 느려질 수 있음 |
| Post-Filter | 벡터 검색 후 결과에서 제외 | 인덱스 속도 빠름 | 검색 결과 10개가 필터에 다 걸려 0개가 될 수 있음 |
| AllowList | 벡터 검색 엔진 내부에서 '허용 목록'을 대조하며 탐색 | 균형 잡힌 성능 | 비트셋 생성 및 비교 비용 발생 |
7. Chroma vs PGVector
🔹 Chroma
- 특징: 내부적으로 SQLite와 hnswlib을 사용합니다.
- 장점: 설정이 매우 쉽고 임베딩 모델 포함 가능.
- 단점: 한국어 형태소 분석기 지원이 부실하여 키워드 검색 시 한국어 성능이 급감합니다. 사전 필터링 시 ID 비트셋을 매번 생성하므로 대규모 데이터에서 병목이 생깁니다.
🔹 PGVector
- 필드 전략: *
embedding_small: 빠른 인덱싱 및 HNSW용. embedding_full: 최종 유사도 검증용.
- 인덱스: * HNSW: 고성능, 높은 메모리 사용.
- IVFFLAT: 데이터 클러스터링 기반, 메모리 효율적이지만 데이터 추가 시 재학습 필요.
- 강점: PostgreSQL의 모든 기능을 그대로 씁니다.
JSONB로 메타데이터를 인덱싱하고,textsearch_ko등을 통해 강력한 한국어 키워드 검색 + 벡터 검색을 한 테이블에서 구현할 수 있습니다.
8. 임베딩 모델 학습 및 활용 전략
- 상품 임베딩: 상품명, 상세 설명, 카테고리뿐만 아니라 '함께 구매한 상품' 데이터를 활용해 학습합니다.
MRL을 적용하여 앞쪽 차원에는 카테고리 정보를, 뒤쪽에는 세부 디자인 정보를 담습니다. - 고객 임베딩: 최근 구매 및 조회 이력을 바탕으로 고객의 취향을 벡터화하여 개인화된 추천을 제공합니다.
- 검색어 임베딩: 사용자가 "편안한 신발"이라고 검색했을 때 실제 클릭한 상품들과 검색어 벡터를 일치시켜 의미론적 검색을 가능케 합니다.
9. 트랜스포머 기반 모델 및 MRL 최적화
- 모델 선정: Qwen3-Embedding-8B 또는 NV-Embed-v2를 활용해 이커머스 도메인에 맞는 Instruction Tuning을 실시합니다.
- 압축의 미학: - 저차원: 대규모 상품 데이터에서 초고속으로 후보군을 추출할 때 사용.
- 고차원: 최종 상위 결과의 순위를 정밀하게 재조정(Re-ranking)할 때 사용.
10. 하이브리드 검색 전략
- 키워드 검색: 브랜드명, 사이즈, 가격대 등 명확한 조건은 PostgreSQL의 풀텍스트 인덱스와 JSONB 필드로 먼저 걸러냅니다.
- 벡터 검색: 키워드로 필터링된 결과 내에서 "캠핑 갈 때 입기 좋은"과 같은 추상적 질의를 벡터 유사도로 계산합니다.
- 효과: 검색 결과가 0개가 되는 현상을 방지하고, 고객의 모호한 의도까지 정확히 파악합니다.
11. PGVector 기반 실무 구축 로드맵
- 테이블 구성:
VECTOR(256)과VECTOR(4096)필드를 동시에 유지하여 성능과 정밀도를 모두 잡습니다. - 인덱스: HNSW 인덱스를 통해 코사인 유사도 검색 속도를 극대화합니다.
- 쿼리 최적화: RDB의 강점을 살려 메타데이터 필터와 벡터 검색을 하나의 쿼리로 결합, 운영 복잡도를 낮춥니다.
느낀점
과거에는 모델이 커지면 속도가 느려지는 것이 당연한 상식이었지만, 마트료시카 학습의 등장은 이 상식을 뒤집었습니다.
고차원 데이터의 정밀함을 유지하면서도 필요에 따라 저차원만 잘라 쓸 수 있는 유연함은, 리소스가 한정된 실무 환경에서 AI를 어떻게 적용해야 하는지에 대한고민을 하게되는 시간이 었습니다.
임베딩 기술의 진화는 검색 엔진을 단순한 '색인 도구'에서 고객의 의도를 읽는 '지능형 큐레이터'로 격상시켰으며
단순히 좋은 AI 모델을 쓰는 것을 넘어, DB 전략이 왜 중요한지 깨달았습니다.

레거시를 이해하면서도 새로운 기술을 현실적으로 적용할 수 있는 백엔드 개발자가 되는 것이 목표입니다.