RAG 검색 증강 생성의 모든 것
RAG(Retrieval-Augmented Generation)는 최근 AI 분야에서 가장 주목받는 기술 중 하나입니다.
하지만 많은 사람들이 RAG의 정확한 작동 원리와 구현 방법에 대해 혼동하고 있습니다.
이번 포스팅에서는 RAG의 핵심 개념부터 실제 구현까지 상세히 다뤄보겠습니다.
RAG란 무엇인가?
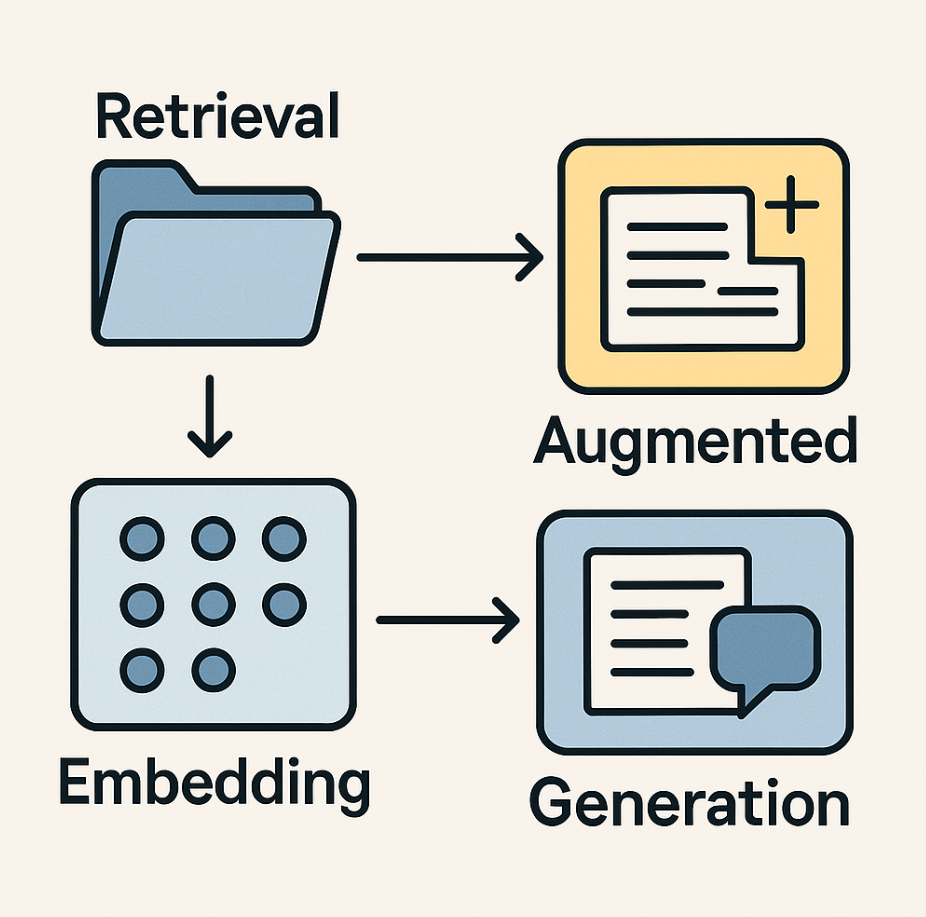
RAG는 세 단어의 조합입니다
- Retrieval(검색): 어디선가 관련 정보를 끌어오는 것
- Augmented(증강): 기존 것을 강화하고 향상시키는 것
- Generation(생성): 새로운 내용을 만들어내는 것
즉, RAG는 "관련 정보를 검색해서 생성 과정을 향상시키는 기술" 입니다.
RAG의 핵심 구성 요소
1. Retrieval: 정보 검색 과정
검색 과정은 다음과 같이 진행됩니다.
- 텍스트 임베딩: 텍스트를 특정 차원의 벡터로 변환
- 유사도 검색: 기존에 저장된 벡터들 중 유사한 것을 찾음
- 정보 추출: 검색된 벡터와 연결된 원본 정보를 가져옴
2. Augmented: 진짜 증강 대상은?
많은 사람들이 오해하는 부분입니다.
RAG에서 실제로 증강되는 것은 생성(Generation) 자체가 아니라 컨텍스트(Context)입니다.
- 시스템 프롬프트나 사용자 질의에 추가 정보를 보강
- 비슷한 개념으로 Tool AC(Tool-Augmented Context), Memory AC(Memory-Augmented Context) 등이 있음
- 실제로는 "Retrieval Augmented Context"라고 부르는 것이 더 정확
일반적인 LLM 사용 vs RAG 활용
기존 LLM 사용 방식
질의 → LLM 투입 → 결과 수령
"리트리버란?" → invoke(질의) → print(result)RAG를 활용한 LLM 사용
질의 → 임베딩 → 벡터DB 검색 → 관련 자료 취합 → 질의 내용 보강 → LLM 투입실제 구현 예시
질의 = "리트리버란?"
임베딩 = [0.12, 0.34, -0.12, ...]
result = db.search([0.12, 0.34, -0.12, ...])
info = result.join(lambda x: x.data)
보강된_질의 = 질의 + "추가정보: " + info
invoke(보강된_질의)임베딩(Embedding): RAG의 핵심 기술
임베딩 과정
- 토큰화: 문장을 개별 토큰으로 분해하여 리스트 생성
- 정수 변환: 각 토큰을 어휘 사전을 통해 정수로 변환
- 벡터 변환: 정수 리스트를 특정 차원의 벡터로 변환
임베딩 모델의 중요성
임베딩 모델 선택 시 주의사항
- 호환성 문제: 다른 모델로 만든 임베딩 결과는 서로 호환되지 않음
- 일관성 유지: RAG DB 구축 시 사용한 모델과 사용자 질의 임베딩 시 같은 모델 사용 필수
- 마이그레이션 비용: 모델 교체 시 전체 RAG DB를 재임베딩해야 함
따라서 임베딩 모델은 신중하게 선택해야 합니다.
고급 RAG 기법 질의 분해
왜 질의 분해가 필요한가?
실제 RAG 시스템에서 자주 발생하는 문제점
- 소유 데이터: 대부분 사실 기반 정보 (A는 B다)
- 사용자 질의: 의도나 배경이 포함된 복잡한 문맥
예를 들어,
"삼성은 최근 비메모리 분야에서 크게 뒤쳐지고 있으며 샤오미를 비롯한 후발주자에게 조차 밀린다.
모바일 AP 분야 외에도 AI 칩셋도 개발하지 못했다"라는
질의는 여러 사실을 포함하고 있습니다.
질의 분해 전략
LLM을 활용해 복잡한 질의를 여러 개의 단순한 질의로 분해
- 삼성전자의 최근 비메모리 반도체 분야 성과
- 비메모리 반도체 시장에서 삼성과 경쟁사 간 비교
- 샤오미의 반도체 분야 기술적 진전
- 삼성이 후발주자에게 밀리는 분야
- 삼성전자의 모바일 AP 경쟁력
- 삼성의 AI 칩셋 개발 현황
- 삼성 AI 칩셋의 경쟁사 대비 수준
질의 분해의 장점
- 높은 일치율: 사실 기반 검색으로 벡터 유사도 매칭 확률 증가
- 효율성: 여러 질의 처리가 GPU 자원을 크게 소비하지 않음
- 정확성: 컨텍스트를 배제한 순수한 사실 추출로 검색 정확도 향상
프롬프트 캐시 최적화
프롬프트 캐시의 현실
- 벤더마다 제공 여부가 다름
- OpenAI는 특정 모델에서만 지원하며 입력 토큰만 대상
- 캐시 유지 시간과 범위는 벤더 재량
OpenAI 프롬프트 캐시 작동 원리
- Prefix 일치: 기존 질의와 새 질의가 앞부분부터 일치하는 구간까지 캐시
- 엄격한 일치: system과 user 순서만 바뀌어도 캐시 무효
- 특정 크기 이상: 일정 크기 이상의 입력에서만 작동
캐시 최적화 전략
- 공통 부분은 최대한 동일하게 유지
- 변경되는 부분은 맨 마지막에 배치
- 책에서 흔히 보는 <WANT_TO_CACHE_HERE> 같은 표기는 의미 없음
- 실제로는 마지막 부분을 {}로 처리하여 캐시 활용
랭체인 도구인가 장애물인가?
랭체인의 본질
- 파이프라이닝 라이브러리: Runnable로 정의된 Task들을 연결하여 실행
- 동시성 라이브러리: 멀티프로세스 기반 동시 실행 (하지만 성능이 낮음)
- 사전 정의된 태스크 제공: LLM 관련 작업들을 미리 구현해서 제공
랭체인의 한계
- 주로 노트북 환경의 실험용으로 적합
- 상용 서비스 도입 시 성능 문제로 대부분 포기
- 동시성 성능이나 최적화에 대한 개선 의지 부족
랭그래프와 Langroid 대안
- 랭그래프: 태스크 체인을 순수하게 데이터로 표현하고 실행기는 별도 선택
- Langroid: 고성능 asyncio 기반으로 랭체인과 유사한 기능을 훨씬 빠르게 제공
랭체인 사용 권장사항
- 깊이 파고들 필요 없음
- 동시성 라이브러리로는 부적합
- Task 실행 라이브러리로서의 기능에만 집중
- 사전 정의된 LLM Task 활용에 초점
RAG의 우아한 구현 함수형 파이프라이닝
RAG 시스템은 여러 단계의 데이터 변환 과정입니다.
이를 함수형 프로그래밍 패러다임으로 구현하면 더욱 깔끔한 코드를 작성할 수 있습니다.
타입 안전한 파이프라이닝
from typing import TypeVar, Callable
A = TypeVar('A')
B = TypeVar('B')
C = TypeVar('C')
def combine(f: Callable[[A], B], g: Callable[[B], C]) -> Callable[[A], C]:
def composed(x: A) -> C:
return g(f(x))
return composed
def tokenize(text: str) -> list[str]:
return text.split()
def embed(tokens: list[str]) -> list[float]:
return [hash(token) % 100 / 100.0 for token in tokens]
# 파이프라인 구성
text_to_embedding = combine(tokenize, embed)
result = text_to_embedding("안녕하세요 RAG입니다")
print(result) # [0.32, 0.45, 0.78]이런 방식으로 구현하면 각 단계가 명확히 분리되고, 타입 안정성도 보장됩니다.
결론
RAG는 단순히 "검색해서 생성을 도와주는 기술"이 아닙니다.
효과적인 RAG 시스템을 구축하려면
- 정확한 개념 이해: Context를 증강하는 기술임을 인식
- 신중한 임베딩 모델 선택: 한 번 선택하면 변경 비용이 큼
- 질의 분해 기법 활용: 복잡한 질의를 단순한 사실 검색으로 분해
- 프롬프트 캐시 최적화: 공통 부분은 앞에, 변경 부분은 뒤에
- 적절한 도구 선택: 랭체인의 한계를 이해하고 대안 고려
- 함수형 파이프라이닝: 타입 안전하고 조합 가능한 구조로 설계
RAG는 이제 선택이 아닌 필수가 되었습니다.
하지만 올바른 이해와 구현 없이는 오히려 성능 저하를 가져올 수 있습니다.
이번 포스팅이 여러분의 RAG 여정에 도움이 되기를 바랍니다.

레거시를 이해하면서도 새로운 기술을 현실적으로 적용할 수 있는 백엔드 개발자가 되는 것이 목표입니다.