5주차 회고🤔
이번주는 강의 내용을 이해하려고 애쓰다보면 진도나가는 속도가 너무 늦어져서 걱정이 많았는데, 알고보니 막상 다른 사람들과 진도가 크게 다르지 않아서 위안이 되었다.🥹
그만큼 이번주 강의 내용을 습득하는데 어려움이 많았다.
신기한 건 그래도 저번주에 비해서 강의 내용을 이해하는 데에 요령이 생긴 것 같다.
저번주까지는 일단 강의를 쭉 듣고 나서 따로 복습을 하면서 정리를 했는데, 그렇게 하면 복습하면 분명 들었는데 강의 내용이 잘 생각이 안나고 이해도 안되어서 계속 강의를 돌려 듣곤 했었다.
그래서 이번주부터는 한 강의를 듣는데 시간이 다소 오래걸리더라도 들으면서 이해한 내용을 바로바로 정리했는데, 그렇게 하니 강의를 다 듣고 나면 좀 더 머릿속에서 정리가 되는 느낌이었다.
그리고 수식만 보면 얼어붙었던 것과 다르게 이제는 수식도 내가 증명을 할 수 있는 정도는 아니지만 유도 과정을 보면 왜 그렇게 유도가 되었는지는 어느 정도 이해가 되고 있다.
그날 하루만 돌아보면 실력이 늘었다거나 강의 내용을 완벽히 이해했다는 느낌이 없어서 힘들었는데, 일주일을 돌아보면 전에 비해 나아진 것이 느껴지는 게 신기하다.
피어세션 & 멘토링📃
이번주 멘토링 시간에는 3주간 읽었던 논문 Collaborative Filtering for Implicit Feedback Datasets을 팀원들과 맡은 부분에 대해 발표하고 멘토님께서 피드백을 해주셨다.
논문을 처음 읽어봐서 어려움이 많았는데 그만큼 좋은 경험이 된 것 같다. 특히 내가 발표해야한다는 생각 때문에 내가 맡은 부분을 다른 사람에게 설명할 수 있을만큼 숙지하려고 하다보니 시간은 오래걸렸지만 논문의 핵심적인 내용에 대해서 확실하게 이해할 수 있었다.
처음에 읽기 시작할 때는 영어만 가득한 논문이 막막하고 어렵기만 했는데 내용을 조금씩 이해해가는 과정이 뿌듯하기도 하고 논문 내용이 생각보다 흥미로워서 나중에는 재미가 붙었다.
멘토님께서 논문을 빨리 훑어봐야할 때 효율적으로 논문 내용을 파악하는 요령에 대해서도 알려주셨다. Title과 Abstract를 보고, Conclusion을 먼저 살펴본 뒤 Methodology와 Experiments에 대한 부분을 도표 위주로 가볍게 훑어보라고 하셨다. 논문을 꼼꼼히 다 읽을 시간은 없지만 논문 내용에 대해 파악해야할 때 유용하게 사용할 수 있을 것 같다.
한 주간 학습한 내용
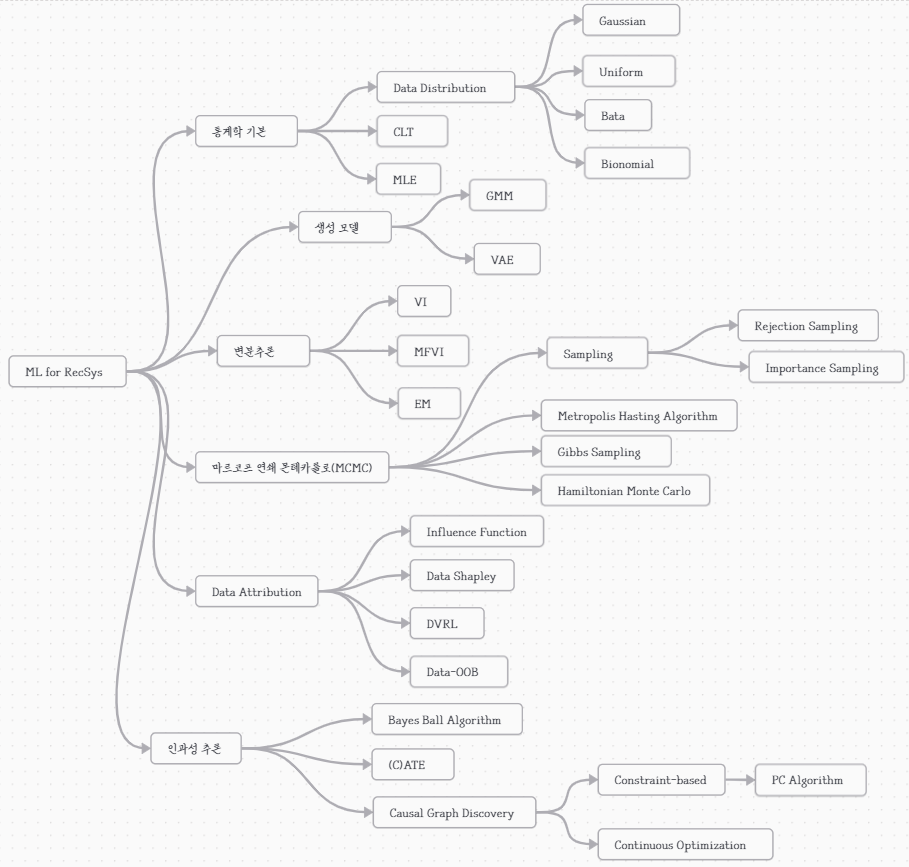
✒️중요한 내용 복습
📍Metropolis Hasting algorithm
MCMC의 가장 대표적인 알고리즘이다. MH 알고리즘이라고도 한다.
제안 분포 를 설정한 뒤, 제안 분포에서 랜덤하게 샘플링하여 해당 샘플을 수용 확률에 따라 reject할 것인지 accept할 것인지를 정한다. 이 때의 수용 확률은 아래와 같다.
샘플이 수용되면, 해당 샘플의 값을 평균으로 하는 제안 분포를 다시 설정하고 위 과정을 반복한다.
📍Influence Function
데이터의 가치를 평가할 때, 해당 데이터가 중요한지 여부를 판단할 수 있는 가장 직관적인 방법은 해당 데이터가 training data에 포함되어 있을 때의 test loss와, 그렇지 않을 때의 test loss를 비교하는 것이다. 만약 두 loss의 차이가 크다면 해당 데이터는 모델 학습에 큰 영향력을 가진 데이터라고 할 수있다. 제외했을 때 loss가 커진다면 모델 학습에 도움이 되는 데이터이고, loss가 작아진다면 noise 데이터이므로 해당 데이터를 제외하는 방식으로 모델 학습에 도움을 줄 수 있다.
다만, 해당 방식은 직관적인만큼 매우 비효율적이기 때문에 이를 효과적으로 처리하기 위한 가치 측정 방법론이 Influence Function이다. leave-one-out 기반 방법론이라고도 한다.
다음주 목표
🚩실습 코드, 과제 코드를 좀 더 꼼꼼하게 뜯어보기
