
세 번째 커리어도 데이터 분석과 관련된 커리어지만,
AARRR이나 Cohort 분석을 다루지는 않는 건 매한가지긴 하다.
그렇지만 언젠가는 도움이 될 수 있으니 간단하게만 정리해야겠다.
01. AARRR 의미
- AARRR은 스타트업, 특히 그로스 해킹(Growth Hacking)이나 제품 성과 분석에 자주 쓰이는 대표적인 퍼널 기반 지표 모델
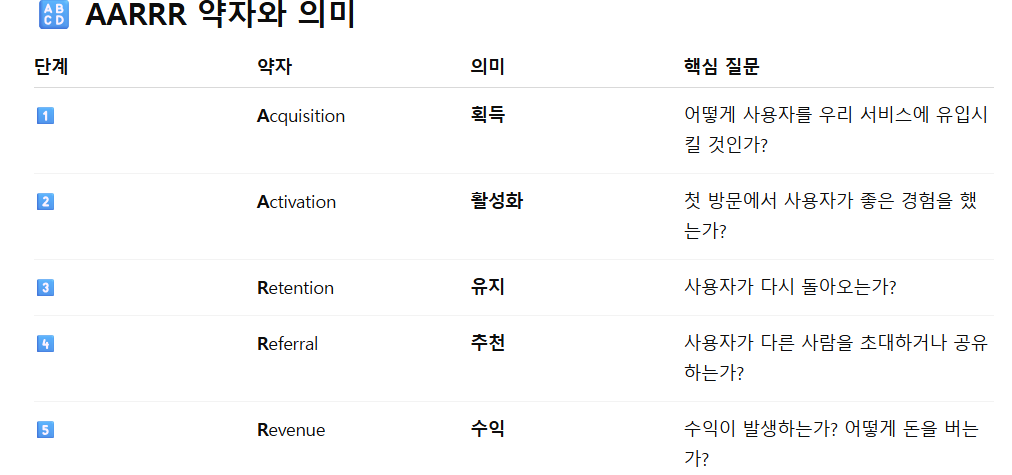
- 고객 여정에 따라 아래와 같이 정리해 볼 수 도 있다.
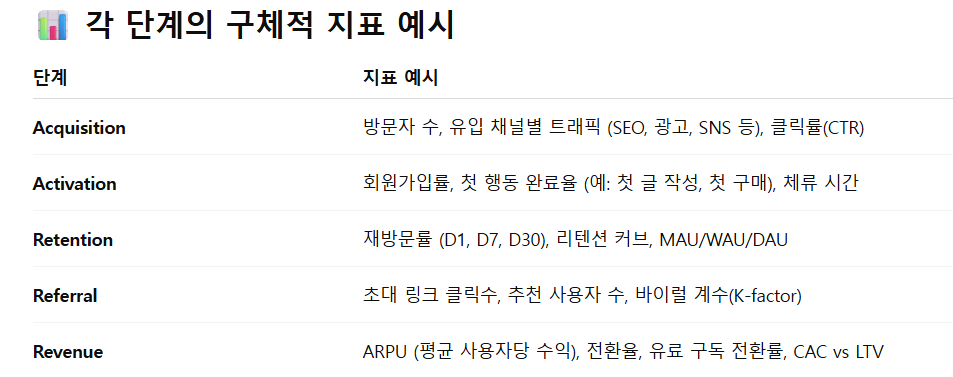
02. Acquision-실습
- 실습을 위해 가상 데이터를 만들어보자
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 가상의 데이터 생성
np.random.seed(42)
num_users = 200
# Acquisition 채널 종류
channels = ['SEO', 'Paid Ads', 'Social Media', 'Email', 'Referral']
data = {
'user_id': range(1, num_users + 1),
'acquisition_channel': np.random.choice(channels, size=num_users, p=[0.3, 0.25, 0.2, 0.15, 0.1]),
'signup_date': pd.date_range(start='2024-10-01', periods=num_users, freq='D'),
'converted': np.random.choice([0, 1], size=num_users, p=[0.6, 0.4]) # 40% 전환율 가정
}
# 데이터프레임 생성
df = pd.DataFrame(data)
df.head(3)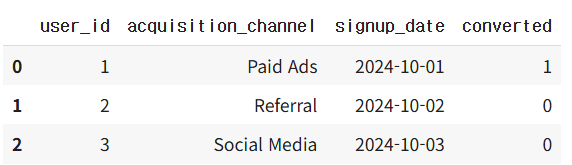
Q01) 채널별 사용자 수 구하기
# 2. Acquisition 채널별 사용자 수 분석
channel_counts = df['acquisition_channel'].value_counts()
print("Acquisition 채널별 사용자 수:")
print(channel_counts)Q02) 채널별 사용자 수/ 시각화
# 2. 데이터 시각화 - Acquisition 채널별 사용자 수
plt.figure(figsize=(8, 5))
sns.countplot(data=df, x='acquisition_channel', order=channel_counts.index)
plt.title('Acquisition user by channel')
plt.xlabel('Acquisition Channel')
plt.ylabel('User Count')
plt.xticks(rotation=45)
plt.show()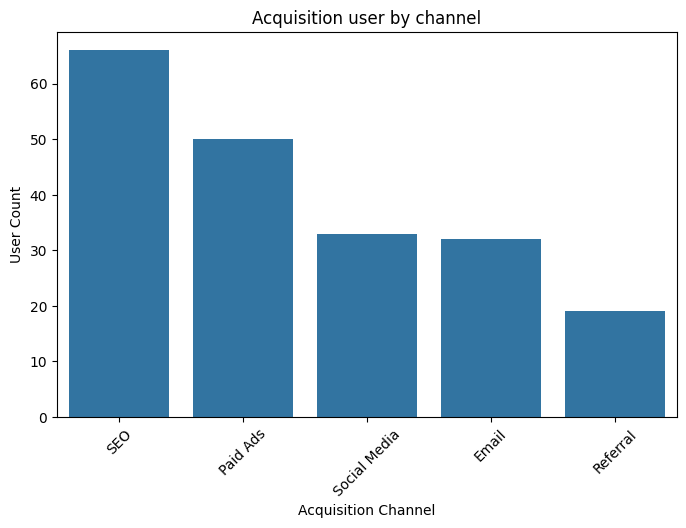
Q03) Acquisition 채널별 전환율
# 3. Acquisition 채널별 전환율 분석
conversion_rate = df.groupby('acquisition_channel')['converted'].mean()
print("Acquisition 채널별 전환율:")
print(conversion_rate)Q04) 채널별 전환율
# 4. 데이터 시각화 - Acquisition 채널별 전환율
plt.figure(figsize=(8, 5))
conversion_rate.sort_values().plot(kind='bar', color='skyblue')
plt.title('Acquisition - CVR by channel')
plt.xlabel('Acquisition Channel')
plt.ylabel('Conversion Rate')
plt.xticks(rotation=45)
plt.ylim(0, 1)
plt.show()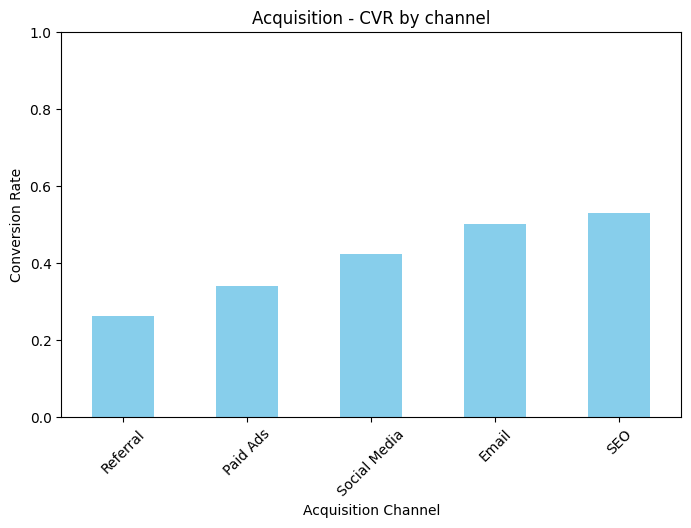
03. Activation-실습
- 가상의 데이터를 만들어보면
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 가상의 데이터 생성
np.random.seed(42)
num_users = 100
data = {
'user_id': range(1, num_users + 1),
'signup_date': pd.date_range(start='2024-10-01', periods=num_users, freq='D'),
'first_search_date': pd.date_range(start='2024-10-02', periods=num_users, freq='D') + pd.to_timedelta(np.random.randint(0, 10, size=num_users), unit='D'),
'purchase_amount': np.random.randint(0, 100000, size=num_users)
}
df = pd.DataFrame(data)
df.head(3)Q05) Activation 여부 컬럼
# 1. Activation 여부 컬럼 추가 (첫 검색이 회원가입 후 7일 이내면 활성화로 간주)
# 2. Activation 지표 분석
df['is_activated'] = (df['first_search_date'] - df['signup_date']).dt.days <= 7
total_users = len(df)
activated_users = df['is_activated'].sum()
activation_rate = activated_users / total_users
print(f"총 사용자 수: {total_users}")
print(f"Activation된 사용자 수: {activated_users}")
print(f"Activation Rate: {activation_rate:.2%}")Q06) Activation-시각화
# Activation 분석 결과 시각화
plt.figure(figsize=(8, 5))
df['is_activated'].value_counts().plot(kind='bar', color=['skyblue', 'orange'])
plt.title('Activation Status')
plt.xticks(ticks=[0, 1], labels=['Not Activated', 'Activated'], rotation=0)
plt.ylabel('Number of Users')
plt.xlabel('Activation Status')
plt.show()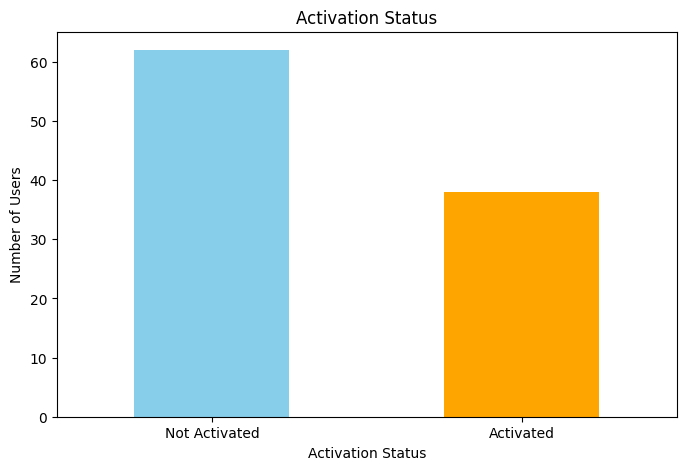
Q07) 구매금액 분석
# Activation된 사용자들의 구매 금액 분석
activated_df = df[df['is_activated'] == True]
non_activated_df = df[df['is_activated'] == False]
avg_purchase_activated = activated_df['purchase_amount'].mean()
avg_purchase_non_activated = non_activated_df['purchase_amount'].mean()
print(f"\nActivation된 사용자의 평균 구매 금액: {avg_purchase_activated:.2f} 원")
print(f"Activation되지 않은 사용자의 평균 구매 금액: {avg_purchase_non_activated:.2f} 원")04. Retention-실습
- 데이터 다운로드(kaggle hub)
import kagglehub
import os
# Download latest version
path = kagglehub.dataset_download("mkechinov/ecommerce-events-history-in-electronics-store")
df = pd.read_csv(path + '/' + os.listdir(path)[0] )
df.head(3)- 날짜 데이터 전처리
- event_time컬럼을 문자형으로 변경 2020-09-01 형태로 변환 후 current_month로 변경
- 유저별 기준으로 집계하여 최소값으로 변경 -> 코호트 시작 날짜로 통일
df['current_month'] = pd.to_datetime(df['event_time']).dt.year.map(str) + "-" + pd.to_datetime(df['event_time']).dt.month.map(str) + "-" '01'
df['current_month'] = pd.to_datetime(df['current_month']).dt.date
df["cohort_month"] = df.groupby("user_id")["current_month"].transform("min")def months_diff(df, col1, col2):
current_month = pd.to_datetime(df[col1]).dt.month
cohort_month = pd.to_datetime(df[col2]).dt.month
return current_month - cohort_month
df['months_diff'] = months_diff(df, 'current_month', 'cohort_month')
print(df.head(3))
def years_diff(df, col1, col2):
current_year = pd.to_datetime(df[col1]).dt.year
cohort_year = pd.to_datetime(df[col2]).dt.year
return current_year - cohort_year
df['years_diff'] = years_diff(df, 'current_month', 'cohort_month')
print(df.head(3))
def cohort_index(df, col1, col2):
return df[col1] * 12 + df[col2]
df['cohort_index'] = cohort_index(df, 'years_diff', 'months_diff')
df.head(3)
- cohort-index 생성
cohort_counts = df.groupby(['cohort_month', 'cohort_index'])['user_id'].nunique()
cohort_counts_df = cohort_counts.to_frame().rename(columns={'user_id':'users'}).sort_values(by=['cohort_month'])
cohort_counts_df- 너무 길어서 뒷 부분은 생략했음
- Cohort-index로 묶으면 아래와 같이 그림이 나옴
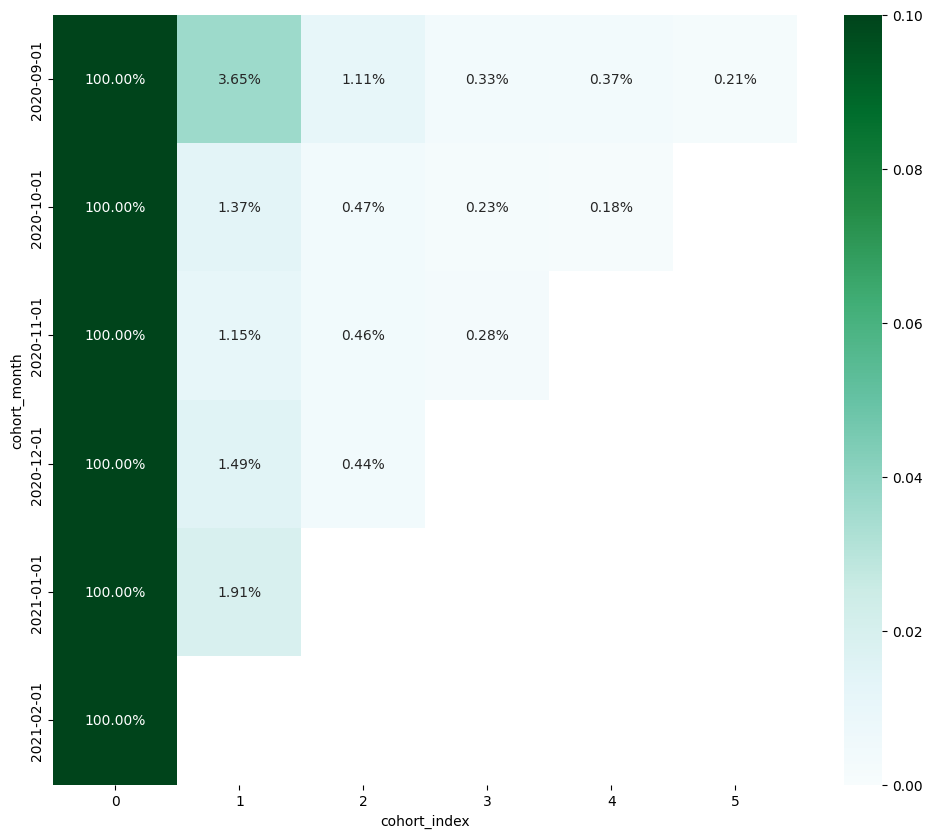
05. Referral-실습
- 가상의 데이터 생성
import pandas as pd
import numpy as np
# 가상의 데이터 생성
np.random.seed(42)
n_users = 1000
data = {
'user_id': range(1, n_users + 1),
'referral_source': np.random.choice(['Yes', 'No'], size=n_users, p=[0.3, 0.7]),
'referral_code_used': np.random.choice(['Yes', 'No'], size=n_users, p=[0.4, 0.6]),
'signup_date': pd.date_range(start='2024-01-01', periods=n_users, freq='D'),
'purchase_amount': np.random.randint(0, 1000, size=n_users)
}
# 데이터프레임 생성
df = pd.DataFrame(data)
df.head(3)Q08) 추천을 통해 유입된 사람의 비율
# 추천을 통해 유입된 사용자 비율 분석
referral_count = df['referral_source'].value_counts(normalize=True) * 100
print("추천 유입 사용자 비율:")
print(referral_count)Q09) 추천 코드 사용 비율 분석
# 2. 추천 코드 사용 비율 분석
referral_code_usage = df['referral_code_used'].value_counts(normalize=True) * 100
print("추천 코드 사용 비율:")
print(referral_code_usage)Q10) 추천 사용자의 구매 분석
# 3. 추천 사용자의 구매 금액 분석
referral_purchase = df[df['referral_source'] == 'Yes']['purchase_amount'].mean()
non_referral_purchase = df[df['referral_source'] == 'No']['purchase_amount'].mean()
print("추천 유입 사용자의 평균 구매 금액:", referral_purchase.round(3))
print("비추천 유입 사용자의 평균 구매 금액:", non_referral_purchase.round(3))06. Revenue-실습
import kagglehub
import os
# Download latest version
path = kagglehub.dataset_download("carrie1/ecommerce-data")
df = pd.read_csv(path + '/' + os.listdir(path)[0], encoding='ISO-8859-1')
df.head(3)Q11) CLV계산 - 생략
Q12) 히스토그램 시각화 - 생략
07. 기초적인 분포
학부 수리통계학 배울 때도 많이 했던 내용이라서, 교재 내용을
정리하지는 않고 간략하게 보고 넘어갔다.
-
균등분포

-
베르누이 분포

-
이항분포

-
정규분포


2025화이팅!