드디어 LLM에 대한 이론을 배우는 주차가 되었다. 이번 주, 다음 주는 회식이나 외부 약속(vLLM 관련 초청 강연이 있더라) 등으로 한 번씩 결석할 예정이니까 최대한 미루지 말고 정리해야겠다.
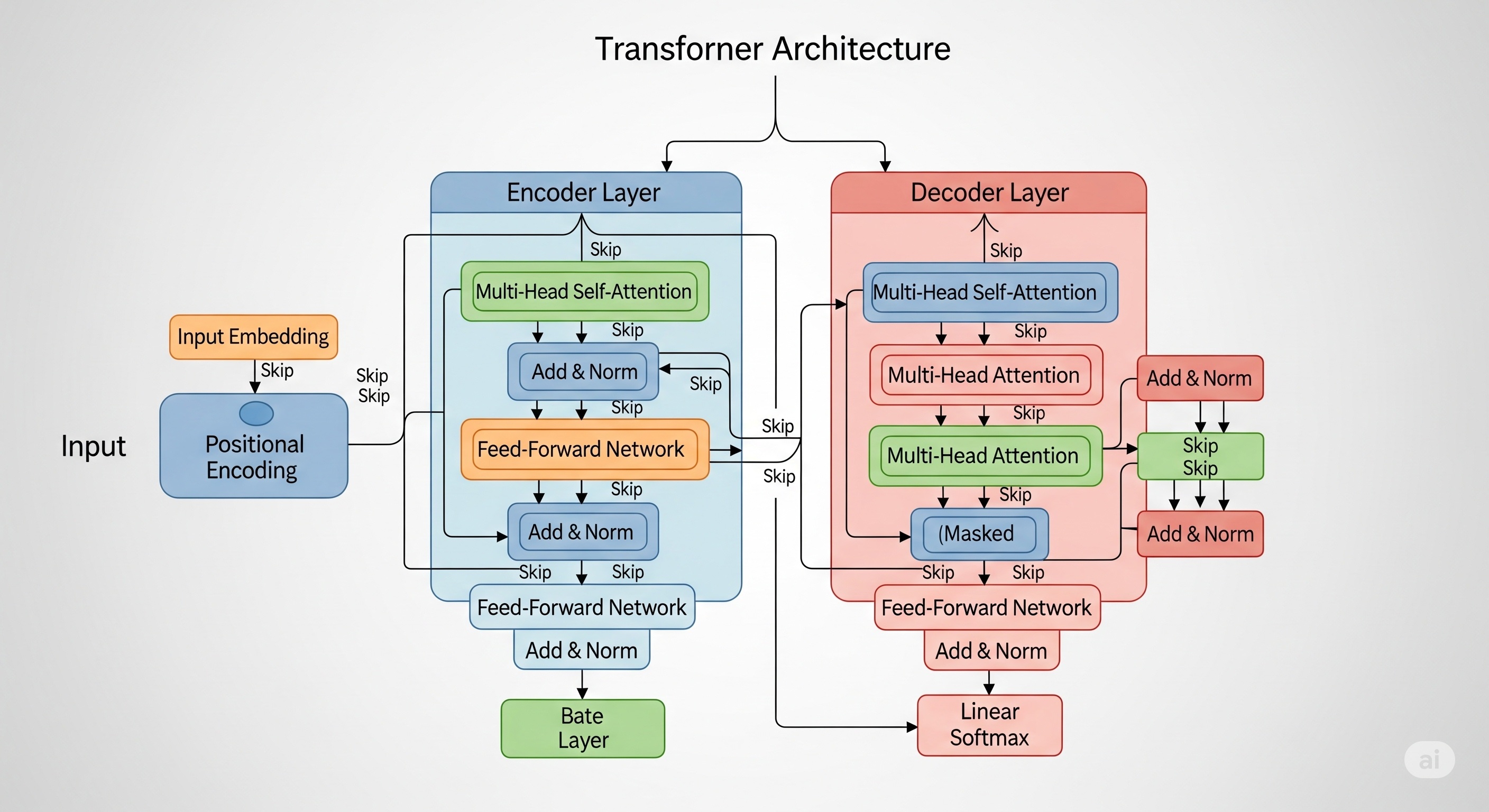
01. Attention의 등장 배경
- 초기 : Attention은 Seq2Seq 모델의 단순한 보조 모듈에 불과
- 문제점(RNN)
- 순차적 연산 → 병렬 연산 불가
- 긴 시퀀스에서 Long-term Dependency 학습 어려움
- 계산 효율 낮음
- 혁신: "Attention is All You Need" (Vaswani et al., 2017)
- RNN, CNN 제거
- Self-Attention + Feed Forward 구조로만 언어 모델링
02. Transformer 핵심 구성 요소
- Self-Attention
- Multi-Head Attention
- Positional Encoding
- Feed Forward Network (FFN)
- Residual Connection + LayerNorm
03. Self-Attention 수식
-
주어진 입력 시퀀스 에서 Query(Q), Key(K), Value(V) 계산:
-
Attention Score (Scaled Dot Product):
04. Multi-Head Attention
-
여러 개의 Self-Attention을 병렬 수행:
-
각 Head:
05. Positional Encoding
- 순서를 알 수 있도록 사인/코사인 함수를 사용:
06. Feed Forward Network
- 각 시퀀스 위치에 독립적으로 적용되는 MLP:
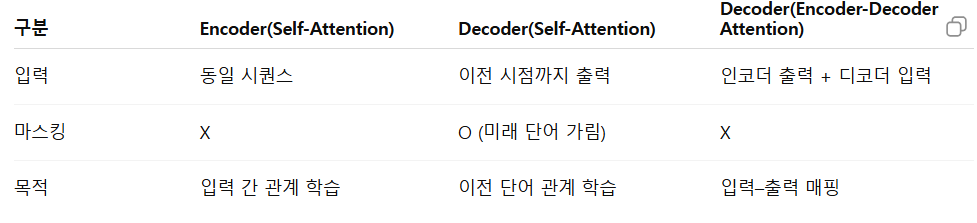
07. Encoder vs Decoder의 Attention
08. Transformer 장점 & 단점
- 장점
- 병렬처리 가능 → 학습 속도 ↑
- Long-term Dependency 문제 완화
- 다양한 도메인 확장 가능
- 단점
- 연산량 많음 (O(n²) 복잡도)
- 시퀀스 길이 제한
- 포지셔널 인코딩의 한계
09. 실습예시
- 코딩 실습 예제(영→독 번역기) 코드
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import spacy
# =========================
# 1. 데이터 전처리
# =========================
spacy_ger = spacy.load("de_core_news_sm")
spacy_eng = spacy.load("en_core_web_sm")
def tokenize_ger(text):
return [tok.text.lower() for tok in spacy_ger.tokenizer(text)]
def tokenize_eng(text):
return [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
SRC = Field(tokenize=tokenize_eng, init_token="<sos>", eos_token="<eos>", lower=True)
TRG = Field(tokenize=tokenize_ger, init_token="<sos>", eos_token="<eos>", lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.en', '.de'), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
# =========================
# 2. 모델 정의
# =========================
class TransformerTranslator(nn.Module):
def __init__(self, src_vocab_size, trg_vocab_size, src_pad_idx, embed_size=512, num_heads=8, num_encoder_layers=3, num_decoder_layers=3, forward_expansion=4, dropout=0.1, max_len=100):
super(TransformerTranslator, self).__init__()
self.src_word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.src_position_embedding = nn.Embedding(max_len, embed_size)
self.trg_word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.trg_position_embedding = nn.Embedding(max_len, embed_size)
self.transformer = nn.Transformer(embed_size, num_heads, num_encoder_layers, num_decoder_layers, forward_expansion * embed_size, dropout)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
self.src_pad_idx = src_pad_idx
self.embed_size = embed_size
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask.to(src.device)
def forward(self, src, trg):
src_seq_length, N = src.shape
trg_seq_length, N = trg.shape
src_positions = (torch.arange(0, src_seq_length).unsqueeze(1).expand(src_seq_length, N).to(src.device))
trg_positions = (torch.arange(0, trg_seq_length).unsqueeze(1).expand(trg_seq_length, N).to(trg.device))
embed_src = self.dropout((self.src_word_embedding(src) + self.src_position_embedding(src_positions)))
embed_trg = self.dropout((self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions)))
src_mask = self.make_src_mask(src)
trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_length).to(trg.device)
out = self.transformer(embed_src, embed_trg, src_key_padding_mask=(src_mask.squeeze(1).squeeze(1) == 0), tgt_mask=trg_mask)
out = self.fc_out(out)
return out
# =========================
# 3. 학습 준비
# =========================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
src_pad_idx = SRC.vocab.stoi["<pad>"]
model = TransformerTranslator(len(SRC.vocab), len(TRG.vocab), src_pad_idx).to(device)
optimizer = optim.Adam(model.parameters(), lr=3e-4)
criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)
# =========================
# 4. 학습 함수
# =========================
def train_fn(model, iterator, optimizer, criterion):
model.train()
epoch_loss = 0
for batch in iterator:
src = batch.src.to(device)
trg = batch.trg.to(device)
optimizer.zero_grad()
output = model(src, trg[:-1])
output_dim = output.shape[-1]
output = output.reshape(-1, output_dim)
trg = trg[1:].reshape(-1)
loss = criterion(output, trg)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# =========================
# 5. 데이터 로더
# =========================
BATCH_SIZE = 32
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
# =========================
# 6. 학습 실행 예시
# =========================
EPOCHS = 5
for epoch in range(EPOCHS):
train_loss = train_fn(model, train_iterator, optimizer, criterion)
print(f"Epoch {epoch+1} Train Loss: {train_loss:.3f}")

2025화이팅!