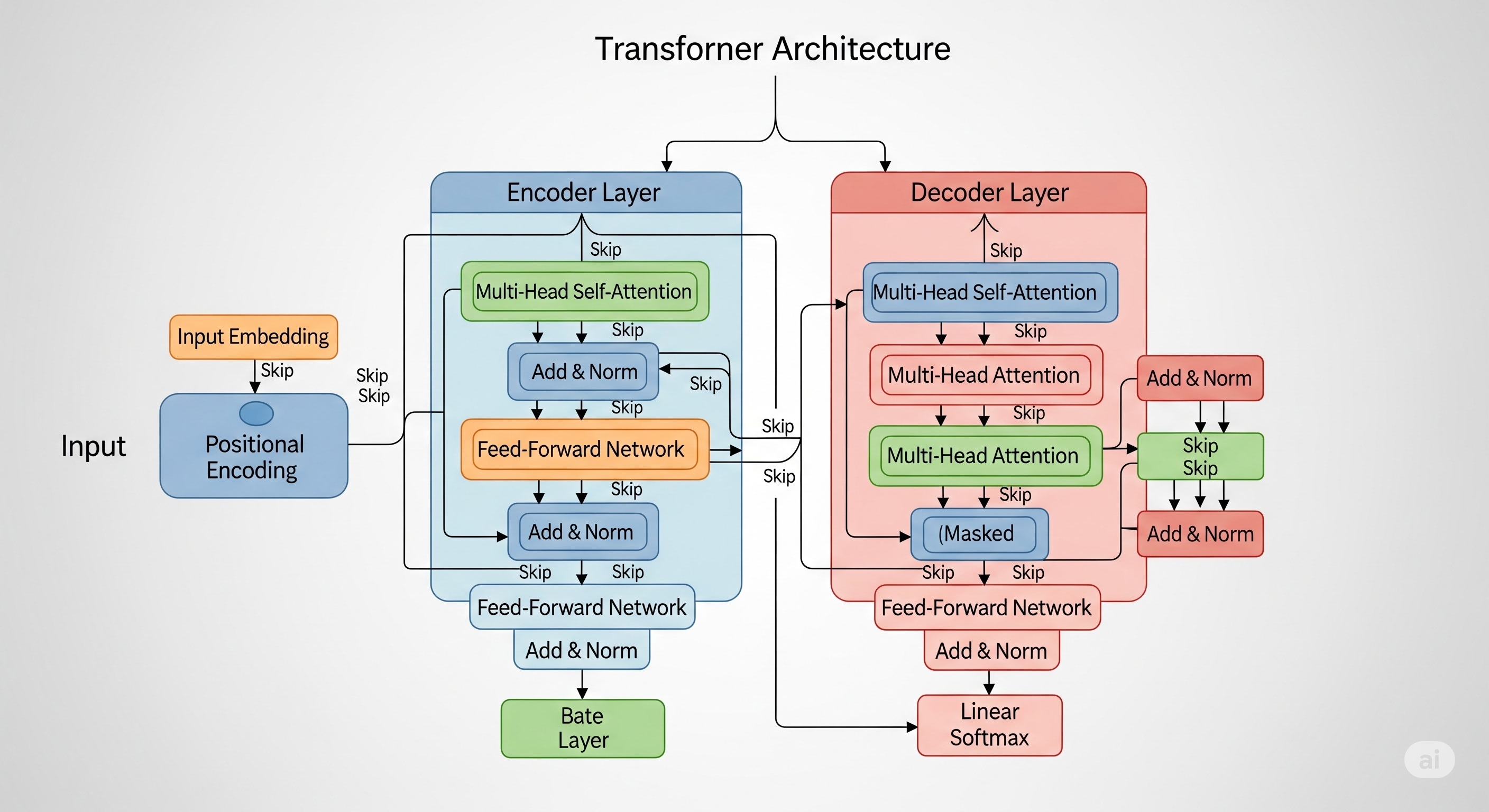
LLM에 대한 개념을 정리해보았다. 사실 데스크탑에 4080 이상 그래픽 카드 달고 연습하는게 제일 좋은 방법이지만 아직은 그럴만한 여유는 없으니까......(그리고 이 KDT심화과정도 거의 대부분 colab에서 실습을 한다.)
01. LLM(Large Language Model) 개념
- 정의: 대규모 데이터셋을 학습한 인공지능 모델로, 텍스트 이해·생성·추론·요약·번역 등 범용 언어 작업 수행 가능
- 기반 기술: Transformer 구조
- 주요 특징
- 자기회귀(Autoregressive) 또는 마스킹(Masked) 기반 확률 모델링
- 사전학습(Pre-training) + 미세조정(Fine-tuning) 전략
- Few-shot, Zero-shot, Chain-of-Thought 등 다양한 추론 패턴 지원
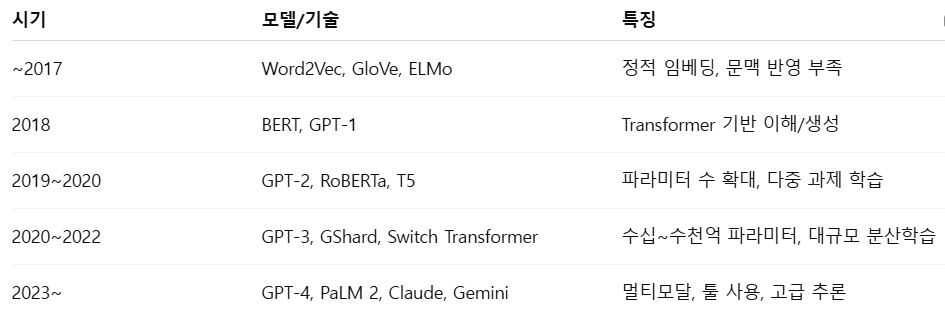
02. LLM 발전 과정
03. Scaling Law
-
정의: LLM 성능은 모델 크기(파라미터 수), 데이터 양, 연산량(FLOPs)의 함수
-
관계식: 로그-선형(Power Law) 형태
-
: 파라미터 수, 데이터 크기, 또는 연산량
-
: 감소율 지수
-
일정 시점 이후 비효율적 증가 구간 → Fine-tuning, RLHF 필요
04. Pre-training
-
목적: 범용 언어 지식(문법, 구조, 개념, 상식)을 대규모 텍스트로 학습
-
방식
-
Autoregressive: 다음 토큰 예측 (GPT)
-
Masked Language Modeling (MLM): 일부 토큰 마스킹 후 복원 (BERT)
-
Seq-to-Seq: 입력 시퀀스를 출력 시퀀스로 변환 (T5)
-
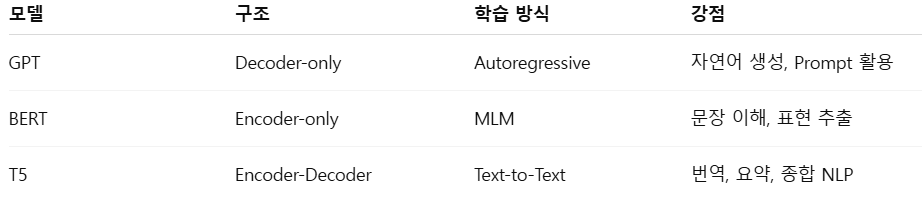
05. 주요 LLM 구조 비교
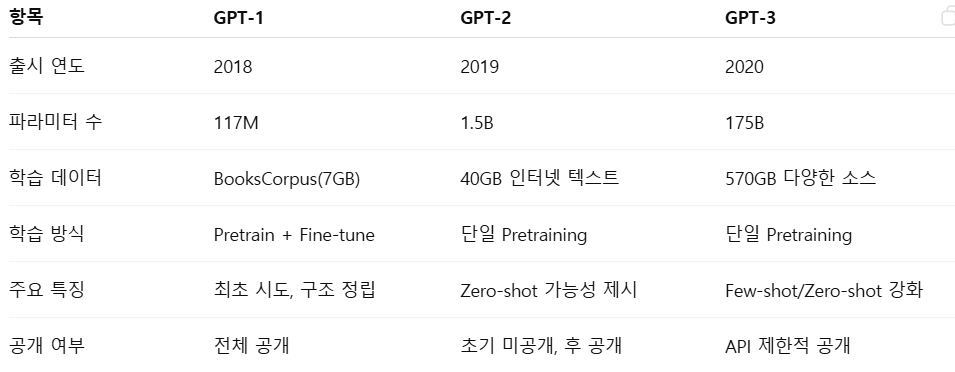
06. GPT 계열 발전
07. LLM 학습 개념 요약
- Self-supervised Learning: 레이블 없이 텍스트 자체로 학습
- Autoregressive Generation: 이전 토큰들을 기반으로 다음 토큰 생성
- Fine-tuning: 사전학습된 모델을 특정 태스크에 맞게 추가 학습
- RLHF: 인류 피드백을 통한 강화학습 기반 정렬(Alignment)

2025화이팅!