
💡 1. 단항 논리회귀(Logistic Regression)
- 분류를 할 때 사용하며, 선형 회귀 공식으로부터 나왔기 때문에 논리회귀라는 이름이 붙여짐
- 회귀 분석을 기반으로 하지만 분류 문제에 사용
- 주로 시그모이드 함수를 사용
x = torch.tensor([1.0, 2.0, 3.0]) w = torch.tensor([0.1, 0.2, 0.3]) b = torch.tensor(0.5)
z = w1x1 + w2x2 + w3x3 + b
z = torch.dot(w, x) + b # dot: 내적
z
tensor(1.9000)
sigmoid = nn.Sigmoid()
output = sigmoid(z)
outputtensor(0.8699)
🐹 시그모이드 함수란?
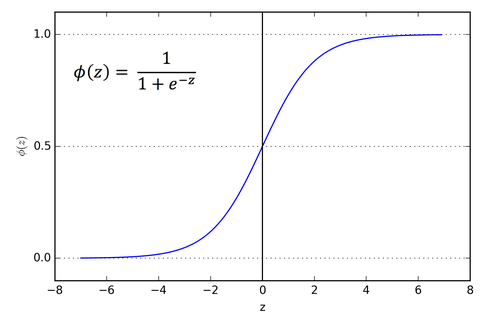
- 입력 데이터 X에 대한 선형 결합으로 계산된 결과를 0과 1 사이의 값으로 변환하는 함수
- 0과 1 사이의 연속된 값을 출력으로 하기 때분에 임계값(보통 0.5)를 기준으로 특정 클래스에 속할 확률을 계산
- S자 곡선을 그리므로 미분 가능한 형태를 가지고 있어 최적화가 용이
import torch
import torch.nn as nn
x = torch.tensor([1.0, 2.0, 3.0])
w = torch.tensor([0.1, 0.2, 0.3])
b = torch.tensor(0.5)
z = torch.dot(w, x) + b # dot: 내적
z> tensor(1.9000)sigmoid = nn.Sigmoid()
output = sigmoid(z)
output> tensor(0.8699)import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(2024)
x_train = torch.FloatTensor([[0], [1], [3], [5], [8], [11], [15], [20]])
y_train = torch.FloatTensor([[0], [0], [0], [0], [1], [1], [1], [1]])
print(x_train.shape)
print(y_train.shape)> torch.Size([8, 1])
> torch.Size([8, 1])plt.figure(figsize=(8,5))
plt.scatter(x_train, y_train)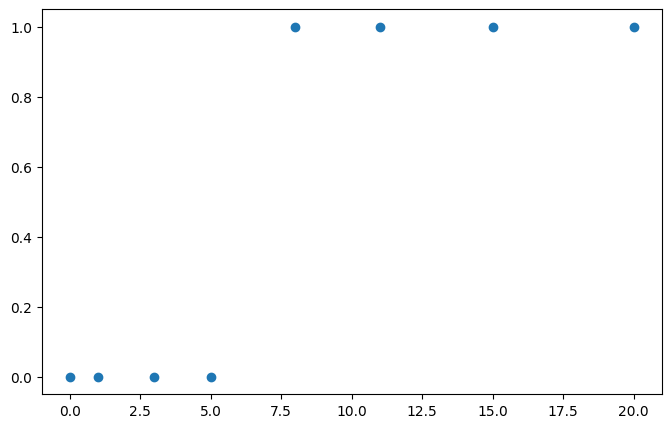
model = nn.Sequential(
nn.Linear(1, 1),
nn.Sigmoid()
)
model> Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): Sigmoid()
)list(model.parameters()) # W: 0.0634 b: 0.6625> [Parameter containing:
tensor([[0.0634]], requires_grad=True),
Parameter containing:
tensor([0.6625], requires_grad=True)]💡 2. 비용함수(Binary Cross Entropy)
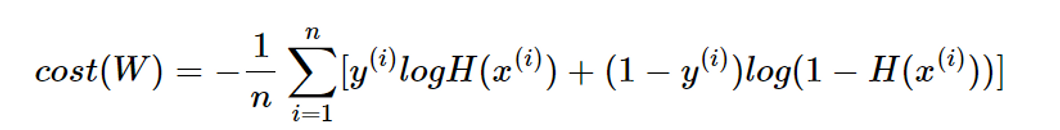
- 논리회귀에서는 nn.BCELoss() 함수를 사용하여 Loss 계산
- 1번 시그마, 2번 시그마 중에서 1번 시그마는 정답이 참이었을 때 부분, 2번 시그마는 정답이 거짓이었을 때 부분
y_pred = model(x_train)
loss = nn.BCELoss()(y_pred, y_train)
loss> tensor(0.6901, grad_fn=<BinaryCrossEntropyBackward0>)optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.BCELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs} Loss: {loss:.6f}')> Epoch: 0/1000 Loss: 0.690111
> Epoch: 100/1000 Loss: 0.612832
> Epoch: 200/1000 Loss: 0.550762
> Epoch: 300/1000 Loss: 0.498473
> Epoch: 400/1000 Loss: 0.454446
> Epoch: 500/1000 Loss: 0.417278
> Epoch: 600/1000 Loss: 0.385753
> Epoch: 700/1000 Loss: 0.358851
> Epoch: 800/1000 Loss: 0.335734
> Epoch: 900/1000 Loss: 0.315727
> Epoch: 1000/1000 Loss: 0.298285list(model.parameters())> [Parameter containing:
tensor([[0.2875]], requires_grad=True),
Parameter containing:
tensor([-1.2444], requires_grad=True)]x_test = torch.FloatTensor([[10]])
y_pred = model(x_test)
y_pred> tensor([[0.8363]], grad_fn=<SigmoidBackward0>)# 임계치 설정하기
# 0.5보다 크거나 같으면 1
# 0.5보다 작으면 0
y_bool = (y_pred >= 0.5).float()
y_bool> tensor([[1.]])💡 3. 다항 논리회귀
x_train = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 4, 5, 9],
[1, 7, 7, 7],
[2, 8, 7, 8]]
# 변수 4개
y_train = [0, 0, 0, 1, 1, 1, 2, 2]
# 클래스 3
x_train = torch.FloatTensor(x_train)
y_train = torch.LongTensor(y_train)
print(x_train.shape)
print(y_train.shape)> torch.Size([8, 4])
> torch.Size([8])model = nn.Sequential(
nn.Linear(4, 3) # 입력 4개 출력 3개
# 앞에 단항에서 출력이 1인 이유는 Sigmoid로 0또는 1이 될 확률을 반환히기 때문에
# 이번에는 각각의 출력에 대한 확률을 반환(확률 총 합은 1)
)
model> Sequential(
(0): Linear(in_features=4, out_features=3, bias=True)
)y_pred = model(x_train)
y_pred> tensor([[-0.3467, 0.0954, -0.5403],
[-0.3109, -0.0908, -1.3992],
[-0.1401, 0.1226, -1.3379],
[-0.4850, 0.0565, -2.1343],
[-4.1847, 1.6323, -0.7154],
[-3.6448, 2.2688, -0.0846],
[-5.1520, 2.1004, -0.9593],
[-5.2114, 2.1848, -1.0401]], grad_fn=<AddmmBackward0>)3-1. CrossEntropyLoss
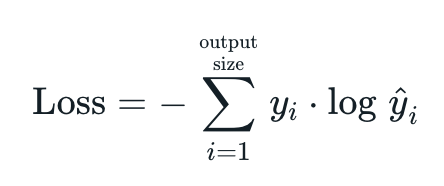
- 교차 엔트로피 손실 함수는 Pytorch에서 제공하는 손실 함수 중 하나로 다중 클래스 분류 문제에 사용
- 소프트맥스 함수와 교차 엔트로피 손실 함수를 결합한 형태
- 소프트맥스 함수를 적용하여 각 클래스에 대한 확률 분포를 얻음
- 각 클래스에 대한 로그 확률을 계산
- 실제 라벨과 예측 확률의 로그값 간의 차이를 계산
- 계산된 차이의 평균을 계산하여 최종 손실 값을 얻음
3-2. SoftMax
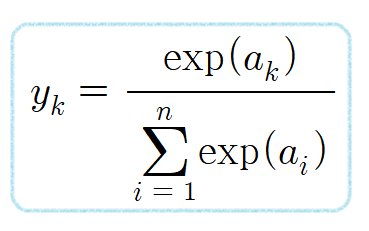
- 다중 클래스 분류 문제에서 사용되는 함수로 주어진 입력 벡터의 값을 확률 분포로 변환
- 각 클래스에 속할 확률을 계산할 수 있으며, 각 요소를 0과 1사이의 값으로 변환하여 이 값들의 합은 항상 1이 되도록 함
- 각 입력 값에 대해 지수함수를 적용
- 지수 함수를 적용한 모든 값의 합을 계산한 후, 각 지수의 합으로 나누어 정규화
- 정규화를 통해 각 값은 0과 1사이의 확률 값으로 출력
loss = nn.CrossEntropyLoss()(y_pred, y_train)
loss> tensor(1.2760, grad_fn=<NllLossBackward0>)optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 10000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs} Loss: {loss: .6f}')> Epoch: 0/10000 Loss: 1.276001
> Epoch: 100/10000 Loss: 0.701097
> Epoch: 200/10000 Loss: 0.658791
> Epoch: 300/10000 Loss: 0.634072
...
> Epoch: 9700/10000 Loss: 0.285849
> Epoch: 9800/10000 Loss: 0.284502
> Epoch: 9900/10000 Loss: 0.283167
> Epoch: 10000/10000 Loss: 0.281846x_test = torch.FloatTensor([[1, 7, 8, 7]])
y_pred = model(x_test)
y_pred> tensor([[-10.6285, 1.0027, 4.9401]], grad_fn=<AddmmBackward0>)# nn.Softmax(1)
# 소프트맥스 함수를 적용할 차원을 지정
# dim=0일 경우 첫 번째 차원을 따라 소프트 맥스를 계산 (행끼리 계산)
# dim=1일 경우 두 번째 차원을 따라 소프트 맥스를 계산 (열끼리 계산)
y_prob = nn.Softmax(1)(y_pred)
y_prob> tensor([[1.6993e-07, 1.9127e-02, 9.8087e-01]], grad_fn=<SoftmaxBackward0>)print(f'0일 확률: {y_prob[0][0]:.2f}')
print(f'1일 확률: {y_prob[0][1]:.2f}')
print(f'2일 확률: {y_prob[0][2]:.2f}')> 0일 확률: 0.00
> 1일 확률: 0.02
> 2일 확률: 0.98torch.argmax(y_prob, axis=1) # 확률이 가장 높은 값> tensor([2])
어떻게 햄스터가 개발자