
2026.04.13. 월요일
광고 성과 분석 과제 수행
- 분석을 통한 데이터에 대한 이해
- 개인별 데이터 분석 코드 생성 지시서 생성
- 생성형 AI를 이요한 분석 코드 생성 및 실행
- 개인별 보고서 생성 지시서 생성
- 생성형 AI를 이용한 보고서 생성
저번 주 금요일에도 수업 시간에 데이터 분석 과제를 했는데, 그 때 평균의 함정에 대해 이야기했는데 사실 그걸 이번 분석 처음에 까먹고 적용하지 못했어요.. 으아아아.. 강사님이랑 이야기하고 생각나서 코드 바꾸는 중.. 긁적..
저는 광고 성과를 ROAS 같은 결과만 보면 그 이유를 알기 어렵다고 생각했어요. 그래서 노출, 클릭, 전환 과정을 나눠서 어디에서 이탈이 발생하는지 확인하려했고 그걸 바탕으로 수익성을 어떻게 개선할 수 있을지 보려고 했어요.
First Try..
# =========================================================
# [Google Colab용] 광고 퍼널 분석 (채널별 병목 구간 분석)
# =========================================================
# -------------------------------
# 0. 구글 드라이브 마운트
# -------------------------------
from google.colab import drive
drive.mount('/content/drive')
# -------------------------------
# 1. 라이브러리 import
# -------------------------------
import pandas as pd
import numpy as np
import plotly.express as px
# -------------------------------
# 2. 데이터 불러오기
# -------------------------------
# ⚠️ 본인 CSV 경로에 맞게 수정
file_path = '/content/drive/MyDrive/KDT/ad_campaign_performance.csv'
df = pd.read_csv(file_path)
# -------------------------------
# 3. KPI 계산 (0 나누기 방지 포함)
# -------------------------------
# CTR: 노출 대비 클릭 비율 (광고 매력도)
df['CTR'] = np.where(df['impressions'] != 0,
(df['clicks'] / df['impressions']) * 100,
0)
# CVR: 클릭 대비 전환 비율 (구매 유도력)
df['CVR'] = np.where(df['clicks'] != 0,
(df['conversions'] / df['clicks']) * 100,
0)
# ROAS: 광고비 대비 수익
df['ROAS'] = np.where(df['spend'] != 0,
(df['total_revenue'] / df['spend']) * 100,
0)
# CPA: 전환 1건당 비용
df['CPA'] = np.where(df['conversions'] != 0,
df['spend'] / df['conversions'],
0)
# CPC: 클릭 1회당 비용
df['CPC'] = np.where(df['clicks'] != 0,
df['spend'] / df['clicks'],
0)
# AOV: 평균 주문 금액
df['AOV'] = np.where(df['conversions'] != 0,
df['total_revenue'] / df['conversions'],
0)
# -------------------------------
# 4. 채널별 그룹화 (퍼널 분석 핵심)
# -------------------------------
# KPI 평균
kpi_mean = df.groupby('channel')[['CTR', 'CVR', 'ROAS', 'CPA', 'CPC', 'AOV']].mean()
# 퍼널 흐름 확인을 위한 합계
funnel_sum = df.groupby('channel')[['impressions', 'clicks', 'conversions', 'spend']].sum()
# 합치기
result = pd.concat([kpi_mean, funnel_sum], axis=1).reset_index()
# -------------------------------
# 5. Markdown 테이블 출력
# -------------------------------
print("\n📊 채널별 퍼널 성과 요약 테이블\n")
print(result.to_markdown(index=False))
# -------------------------------
# 6. 시각화 1: 채널별 CTR / CVR 비교
# -------------------------------
# Melt 형태로 변환 (Plotly용)
melt_df = result.melt(id_vars='channel', value_vars=['CTR', 'CVR'],
var_name='Metric', value_name='Value')
fig1 = px.bar(
melt_df,
x='channel',
y='Value',
color='Metric',
barmode='group',
title='채널별 퍼널 전환율 비교 (CTR vs CVR)'
)
fig1.show()
# -------------------------------
# 7. 시각화 2: 퍼널 차트 (채널별)
# -------------------------------
# channel별로 개별 funnel 출력
for ch in result['channel']:
temp = result[result['channel'] == ch]
fig2 = px.funnel(
x=[temp['impressions'].values[0],
temp['clicks'].values[0],
temp['conversions'].values[0]],
y=['Impressions', 'Clicks', 'Conversions'],
title=f'{ch} 채널 퍼널 구조'
)
fig2.show()
# -------------------------------
# 8. 시각화 3: ROAS + Spend (이중축 그래프)
# -------------------------------
import plotly.graph_objects as go
# ROAS 기준 정렬 (가독성 향상)
result_sorted = result.sort_values(by='ROAS', ascending=False)
fig3 = go.Figure()
# ROAS (막대)
fig3.add_trace(go.Bar(
x=result_sorted['channel'],
y=result_sorted['ROAS'],
name='ROAS (%)'
))
# Spend (라인 - 보조축)
fig3.add_trace(go.Scatter(
x=result_sorted['channel'],
y=result_sorted['spend'],
name='Spend',
yaxis='y2',
mode='lines+markers'
))
# 레이아웃 설정 (이중축)
fig3.update_layout(
title='채널별 ROAS 및 광고비 비교 (효율 + 규모)',
xaxis=dict(title='채널'),
yaxis=dict(title='ROAS (%)'),
yaxis2=dict(
title='광고비 (Spend)',
overlaying='y',
side='right'
)
)
fig3.show()[ 광고 채널 퍼널 성과 분석 보고서 ]
본 분석은 광고 성과 데이터가 기록된 CSV 파일을 기반으로 수행되었으며, 분석 대상 데이터는 일정 기간 동안 수집된 채널별 광고 집행 결과를 포함하고 있다. 주요 컬럼으로는 channel, impressions, clicks, conversions, spend, total_revenue가 포함되어 있으며, 이를 바탕으로 CTR, CVR, ROAS, CPA, CPC, AOV 등의 핵심 KPI를 산출하였다.
본 분석의 핵심 목표는 노출(Impressions) → 클릭(Clicks) → 전환(Conversions)으로 이어지는 퍼널 구조 내에서 채널별 성과 차이를 비교하고, 이탈이 발생하는 병목 구간을 식별하는 데 있다. 이를 위해 CTR과 CVR을 중심으로 퍼널 효율을 분석하고, 최종적으로 ROAS를 통해 수익성과 연결되는 구조를 검증하였다.
이와 같은 분석 접근은 단순 성과 비교를 넘어, 각 채널이 퍼널 내에서 수행하는 역할과 한계를 파악하고, 효율적인 예산 배분 및 성과 개선 방향을 도출하기 위해 채택되었다. 분석은 Google Colab 환경에서 Python(pandas, plotly)을 활용하여 진행되었다.
1. 현황 분석
채널별 퍼널 성과를 비교한 결과, 유입 단계(CTR)와 전환 단계(CVR)의 성격이 채널별로 명확히 구분되는 구조가 나타났다. Instagram은 CTR 2.99%로 가장 높은 클릭 유도력을 보였으나 CVR 1.45%로 가장 낮아 클릭 이후 전환 단계에서 큰 이탈이 발생하고 있다. 반면 Google은 CTR 1.68%로 가장 낮은 수준이지만 CVR 3.01%로 가장 높아 유입 대비 전환 효율이 매우 높은 구조를 보인다. Facebook은 CTR 2.71%, CVR 1.57%로 유입 대비 전환 효율이 낮은 중간 퍼널 병목 구조이며, Naver는 CTR 1.90%, CVR 2.54%로 상대적으로 균형 잡힌 퍼널을 형성하고 있다.
수익성 측면에서는 Naver가 ROAS 272.77%로 가장 높고, Facebook 253.82%, Google 221.47%, Instagram 180.08% 순으로 나타났다. 반면 광고비는 Google이 약 11.76억으로 가장 높은 투자 규모를 보였고, Facebook 약 8.45억, Instagram 약 7.41억, Naver 약 6.04억 순이다. 이를 종합하면 상단 퍼널은 Instagram과 Facebook이, 하단 퍼널은 Google과 Naver가 상대적으로 강점을 가지며, 채널별 역할이 분리된 구조로 해석된다.
2. 가설 검증
“CTR이 높은 채널이 반드시 ROAS도 높은가”라는 가설을 검증한 결과, 해당 가설은 성립하지 않는 것으로 확인된다. Instagram은 CTR 2.99%로 가장 높지만 ROAS는 188.08%로 가장 낮은 수준이다. 반대로 Google은 CTR 1.68%로 가장 낮지만 ROAS는 221.47%로 상대적으로 높은 성과를 보인다. 또한 Naver는 CTR 1.90% 수준임에도 ROAS 272.77%로 가장 높은 수익성을 기록하였다.
이러한 결과는 CTR과 ROAS 간 직접적인 비례 관계가 존재하지 않음을 의미한다. 대신 CVR이 성과에 더 큰 영향을 미치는 것으로 나타난다. 실제로 Google은 CVR 3.01%로 가장 높은 전환율을 보이며 ROAS 또한 높은 수준을 유지하고 있고, Instagram은 CVR 1.45%로 가장 낮으며 ROAS 역시 가장 낮은 수준이다. 따라서 최종 성과는 클릭 유도력보다 전환 효율에 의해 결정되는 구조로 판단된다.
3. 채널별 제안
Instagram은 CTR 2.99% 대비 CVR 1.45%로 클릭 이후 전환 단계에서 큰 이탈이 발생하고 있어 전환 개선이 우선 과제이다. 전환 중심 메시지 강화 및 랜딩페이지 개선을 통해 CVR을 높이는 전략이 필요하며, 예산 확대는 전환율 개선 이후 검토하는 것이 적절하다.
Google은 CTR 1.68%로 유입 단계에서 제한이 있지만 CVR 3.01%로 가장 높은 전환 효율을 보이고 있으며 ROAS 221.47%와 함께 가장 큰 광고비가 집행되고 있다. 따라서 CTR 개선을 통해 유입을 확대할 경우 전체 성과 상승이 기대되며, 현재 전환 구조를 유지하는 범위 내에서 추가 예산 확대를 고려할 수 있다.
Facebook은 CTR 2.71% 대비 CVR 1.57%로 중간 퍼널에서 이탈이 발생하고 있다. 전환 단계 개선을 위해 타겟 정교화 및 소재와 랜딩 간 일관성 강화가 필요하며, 현재 ROAS 253.82% 수준을 유지하는 범위 내에서 안정적 운영 전략이 적절하다.
Naver는 CVR 2.54%와 ROAS 272.77%로 가장 높은 수익성을 보이는 채널임에도 광고비는 약 6.04억으로 가장 낮은 수준이다. 따라서 예산 확대를 통한 성과 극대화가 가장 우선적으로 고려되어야 하며, 현재의 전환 구조를 유지하는 것이 중요하다.
종합적으로, 고효율 채널인 Naver와 Google은 확장 전략을, 전환 병목이 존재하는 Instagram과 Facebook은 퍼널 개선 전략을 적용하는 것이 전체 성과 향상에 유효한 접근이다.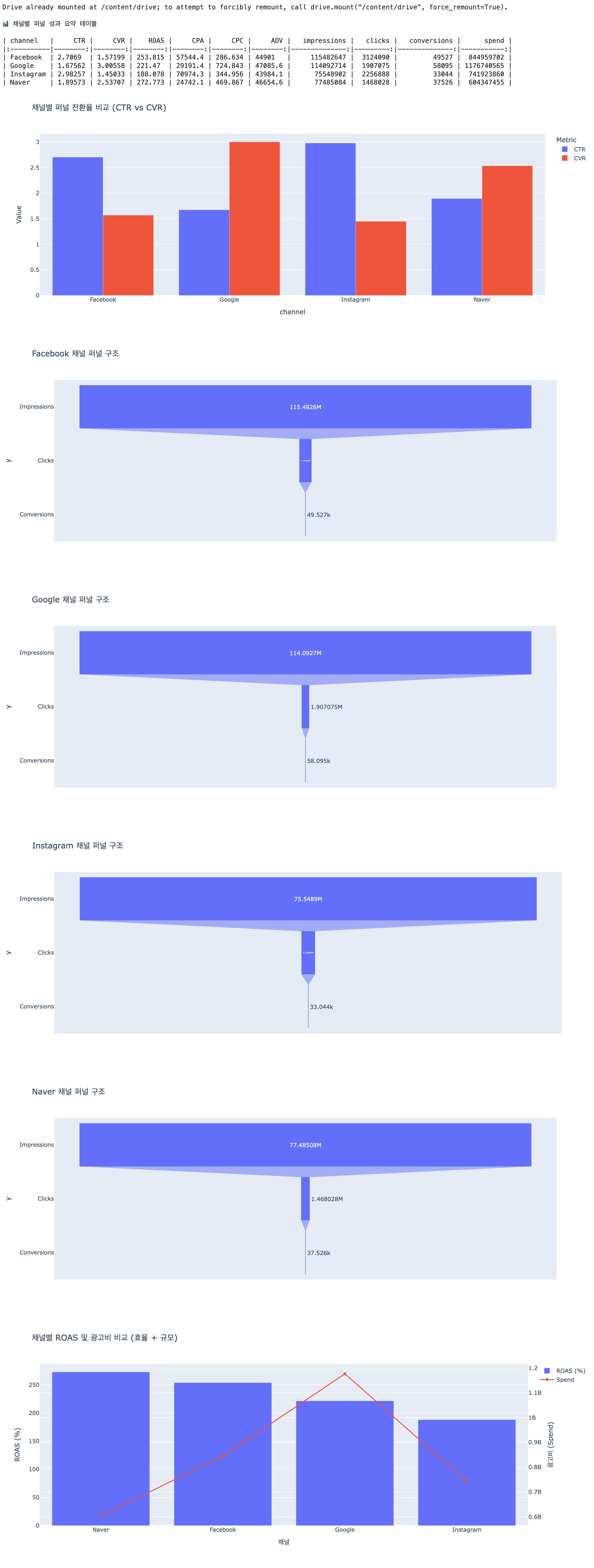
이게 처음에 썼던 보고서랑 코드인데, 코드 보면 각 행의 CTR/CVR을 구한 다음에 평균을 내버림.. 이렇게 되면 왜곡이 생김..
예를 들어
캠페인 A (impressions: 100 / clicks: 10 → CTR = 10%)
캠페인 B (impressions: 10,000 / clicks: 100 → CTR = 1%)
→ 단순 평균 : (10% + 1%) / 2 = 5.5%
→ 실제 전체 CTR : (110 / 10,100) ≈ 1.09%
⇨ 차이 엄청 큼 😱
그리고 보고서 자체에 대해서 코멘트를 부탁드렸는데.. 구체적으로 누구에게 보여줄 보고서인지 대상을 정해서 마지막에 결론을 쓰면 좋다고 하셨어요..
음.. 그러니까 예를 들어 경영자들에게 보여는 용도인지, 아니면 고객에게 보여주는 용도(증권사에서 분기별로 고객에게 공개하는 분기별 보고서 같은거)인지 대상을 확실히 하라는 것..!
Second Try..
# =========================================================
# [Google Colab용] 광고 퍼널 분석 (평균의 함정 제거 버전)
# =========================================================
# -------------------------------
# 0. 구글 드라이브 마운트
# -------------------------------
from google.colab import drive
drive.mount('/content/drive')
# -------------------------------
# 1. 라이브러리 import
# -------------------------------
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
# -------------------------------
# 2. 데이터 불러오기
# -------------------------------
file_path = '/content/drive/MyDrive/KDT/ad_campaign_performance.csv'
df = pd.read_csv(file_path)
# -------------------------------
# 3. 채널별 집계 (🔥 핵심: 먼저 합계)
# -------------------------------
grouped = df.groupby('channel').agg({
'impressions': 'sum',
'clicks': 'sum',
'conversions': 'sum',
'spend': 'sum',
'total_revenue': 'sum'
}).reset_index()
# -------------------------------
# 4. KPI 재계산 (🔥 평균 X, 합계 기반 계산)
# -------------------------------
# 안전한 나눗셈 함수
def safe_divide(a, b):
return np.where(b == 0, 0, a / b)
grouped['CTR'] = safe_divide(grouped['clicks'], grouped['impressions']) * 100
grouped['CVR'] = safe_divide(grouped['conversions'], grouped['clicks']) * 100
grouped['ROAS'] = safe_divide(grouped['total_revenue'], grouped['spend']) * 100
grouped['CPA'] = safe_divide(grouped['spend'], grouped['conversions'])
grouped['CPC'] = safe_divide(grouped['spend'], grouped['clicks'])
grouped['AOV'] = safe_divide(grouped['total_revenue'], grouped['conversions'])
# 보기 좋게 반올림
grouped = grouped.round(2)
# -------------------------------
# 5. Markdown 테이블 출력
# -------------------------------
print("\n📊 채널별 퍼널 성과 요약 테이블 (합계 기반)\n")
print(grouped.to_markdown(index=False))
# -------------------------------
# 6. 시각화 1: CTR vs CVR 비교
# -------------------------------
melt_df = grouped.melt(
id_vars='channel',
value_vars=['CTR', 'CVR'],
var_name='Metric',
value_name='Value'
)
fig1 = px.bar(
melt_df,
x='channel',
y='Value',
color='Metric',
barmode='group',
title='채널별 퍼널 전환율 비교 (CTR vs CVR)'
)
fig1.show()
# -------------------------------
# 7. 시각화 2: 퍼널 차트 (채널별)
# -------------------------------
for ch in grouped['channel']:
temp = grouped[grouped['channel'] == ch]
fig2 = px.funnel(
x=[temp['impressions'].values[0],
temp['clicks'].values[0],
temp['conversions'].values[0]],
y=['Impressions', 'Clicks', 'Conversions'],
title=f'{ch} 채널 퍼널 구조'
)
fig2.show()
# -------------------------------
# 8. 시각화 3: ROAS + Spend (이중축)
# -------------------------------
grouped_sorted = grouped.sort_values(by='ROAS', ascending=False)
fig3 = go.Figure()
fig3.add_trace(go.Bar(
x=grouped_sorted['channel'],
y=grouped_sorted['ROAS'],
name='ROAS (%)'
))
fig3.add_trace(go.Scatter(
x=grouped_sorted['channel'],
y=grouped_sorted['spend'],
name='Spend',
yaxis='y2',
mode='lines+markers'
))
fig3.update_layout(
title='채널별 ROAS 및 광고비 비교 (합계 기반)',
xaxis=dict(title='채널'),
yaxis=dict(title='ROAS (%)'),
yaxis2=dict(
title='광고비 (Spend)',
overlaying='y',
side='right'
)
)
fig3.show()[ 광고 채널 퍼널 성과 분석 보고서 ]
본 분석은 광고 성과 데이터가 기록된 CSV 파일을 기반으로 수행되었으며, 분석 대상 데이터는 일정 기간 동안 수집된 채널별 광고 집행 결과를 포함하고 있다. 주요 컬럼으로는 channel, impressions, clicks, conversions, spend, total_revenue가 포함되어 있으며, 이를 바탕으로 CTR, CVR, ROAS, CPA, CPC, AOV 등의 핵심 KPI를 산출하였다.
본 분석의 핵심 목표는 노출(Impressions) → 클릭(Clicks) → 전환(Conversions)으로 이어지는 퍼널 구조 내에서 채널별 성과 차이를 비교하고, 이탈이 발생하는 병목 구간을 식별하는 데 있다. 이를 위해 CTR과 CVR을 중심으로 퍼널 효율을 분석하고, 최종적으로 ROAS를 통해 수익성과 연결되는 구조를 검증하였다.
이와 같은 분석 접근은 단순 성과 비교를 넘어, 각 채널이 퍼널 내에서 수행하는 역할과 한계를 파악하고, 효율적인 예산 배분 및 성과 개선 방향을 도출하기 위해 채택되었다. 분석은 Google Colab 환경에서 Python(pandas, plotly)을 활용하여 진행되었다.
1. 현황 분석
채널별 퍼널 성과를 비교한 결과, 유입 단계(CTR)와 전환 단계(CVR)의 성격이 채널별로 명확히 구분되는 구조가 나타났다. Instagram은 CTR 2.99%로 가장 높은 클릭 유도력을 보였으나 CVR 1.46%로 가장 낮아 클릭 이후 전환 단계에서 큰 이탈이 발생하고 있다. 반면 Google은 CTR 1.67%로 가장 낮은 수준이지만 CVR 3.05%로 가장 높아 유입 대비 전환 효율이 매우 높은 구조를 보인다. Facebook은 CTR 2.71%, CVR 1.59%로 유입 대비 전환 효율이 낮은 중간 퍼널 병목 구조이며, Naver는 CTR 1.89%, CVR 2.56%로 상대적으로 균형 잡힌 퍼널을 형성하고 있다.
수익성 측면에서는 Naver가 ROAS 274.98%로 가장 높고, Facebook 256.64%, Google 223.87%, Instagram 191.61% 순으로 나타났다. 반면 광고비는 Google이 약 11.76억으로 가장 높은 투자 규모를 보였고, Facebook 약 8.45억, Instagram 약 7.41억, Naver 약 6.04억 순이다. 이를 종합하면 상단 퍼널은 Instagram과 Facebook이, 하단 퍼널은 Google과 Naver가 상대적으로 강점을 가지며, 채널별 역할이 분리된 구조로 해석된다.
2. 가설 검증
“CTR이 높은 채널이 반드시 ROAS도 높은가”라는 가설을 검증한 결과, 해당 가설은 성립하지 않는 것으로 확인된다. Instagram은 CTR 2.99%로 가장 높지만 ROAS는 191.61%로 가장 낮은 수준이다. 반대로 Google은 CTR 1.67%로 가장 낮지만 ROAS는 223.87%로 상대적으로 높은 성과를 보인다. 또한 Naver는 CTR 1.89% 수준임에도 ROAS 274.98%로 가장 높은 수익성을 기록하였다.
이러한 결과는 CTR과 ROAS 간 직접적인 비례 관계가 존재하지 않음을 의미한다. 대신 CVR이 성과에 더 큰 영향을 미치는 것으로 나타난다. 실제로 Google은 CVR 3.05%로 가장 높은 전환율을 보이며 ROAS 또한 높은 수준을 유지하고 있고, Instagram은 CVR 1.46%로 가장 낮으며 ROAS 역시 가장 낮은 수준이다. 따라서 최종 성과는 클릭 유도력보다 전환 효율에 의해 결정되는 구조로 판단된다.
3. 채널별 제안
Instagram은 CTR 2.99% 대비 CVR 1.46%로 클릭 이후 전환 단계에서 큰 이탈이 발생하고 있어 전환 개선이 우선 과제이다. 전환 중심 메시지 강화 및 랜딩페이지 개선을 통해 CVR을 높이는 전략이 필요하며, 예산 확대는 전환율 개선 이후 검토하는 것이 적절하다.
Google은 CTR 1.67%로 유입 단계에서 제한이 있지만 CVR 3.01%로 가장 높은 전환 효율을 보이고 있으며 ROAS 223.87%와 함께 가장 큰 광고비가 집행되고 있다. 따라서 CTR 개선을 통해 유입을 확대할 경우 전체 성과 상승이 기대되며, 현재 전환 구조를 유지하는 범위 내에서 추가 예산 확대를 고려할 수 있다.
Facebook은 CTR 2.71% 대비 CVR 1.59%로 중간 퍼널에서 이탈이 발생하고 있다. 전환 단계 개선을 위해 타겟 정교화 및 소재와 랜딩 간 일관성 강화가 필요하며, 현재 ROAS 256.64% 수준을 유지하는 범위 내에서 안정적 운영 전략이 적절하다.
Naver는 CVR 2.56%와 ROAS 274.98%로 가장 높은 수익성을 보이는 채널임에도 광고비는 약 6.04억으로 가장 낮은 수준이다. 따라서 예산 확대를 통한 성과 극대화가 가장 우선적으로 고려되어야 하며, 현재의 전환 구조를 유지하는 것이 중요하다.
종합적으로, 고효율 채널인 Naver와 Google은 확장 전략을, 전환 병목이 존재하는 Instagram과 Facebook은 퍼널 개선 전략을 적용하는 것이 전체 성과 향상에 유효한 접근이다.
4. 결론 및 경영진 제안
본 분석 결과, 채널별 성과는 단일 지표가 아닌 퍼널 구조 내 역할에 따라 차별적으로 나타나는 것으로 확인되었다. 특히 CTR과 ROAS 간 직접적인 상관관계는 확인되지 않았으며, 최종 수익성은 CVR과 같은 전환 효율에 의해 더 크게 좌우되는 구조를 보인다.
이에 따라 향후 광고 운영 전략은 채널별 역할을 명확히 구분하여 접근할 필요가 있다. Google과 Naver는 높은 CVR과 ROAS를 기반으로 수익 창출에 직접 기여하는 채널로, 성과 유지 및 예산 확대를 통해 전체 매출 증대에 기여할 수 있다. 반면 Instagram과 Facebook은 상대적으로 높은 CTR을 기반으로 유입을 확대하는 역할을 수행하고 있으나, 전환 단계에서의 이탈이 확인되므로 퍼널 하단 개선을 통한 효율 보완이 필요하다.
따라서 단기적으로는 고효율 채널(Naver, Google)에 대한 예산 확대를 통해 즉각적인 수익 극대화를 도모하고, 중장기적으로는 Instagram과 Facebook의 전환율 개선을 통해 전체 퍼널 효율을 향상시키는 전략이 적절하다.
종합적으로, 본 분석은 채널별 성과를 단순 비교하는 것이 아니라 역할 기반으로 재해석함으로써, 효율적인 예산 배분과 성과 개선 방향 수립에 실질적인 근거를 제공한다.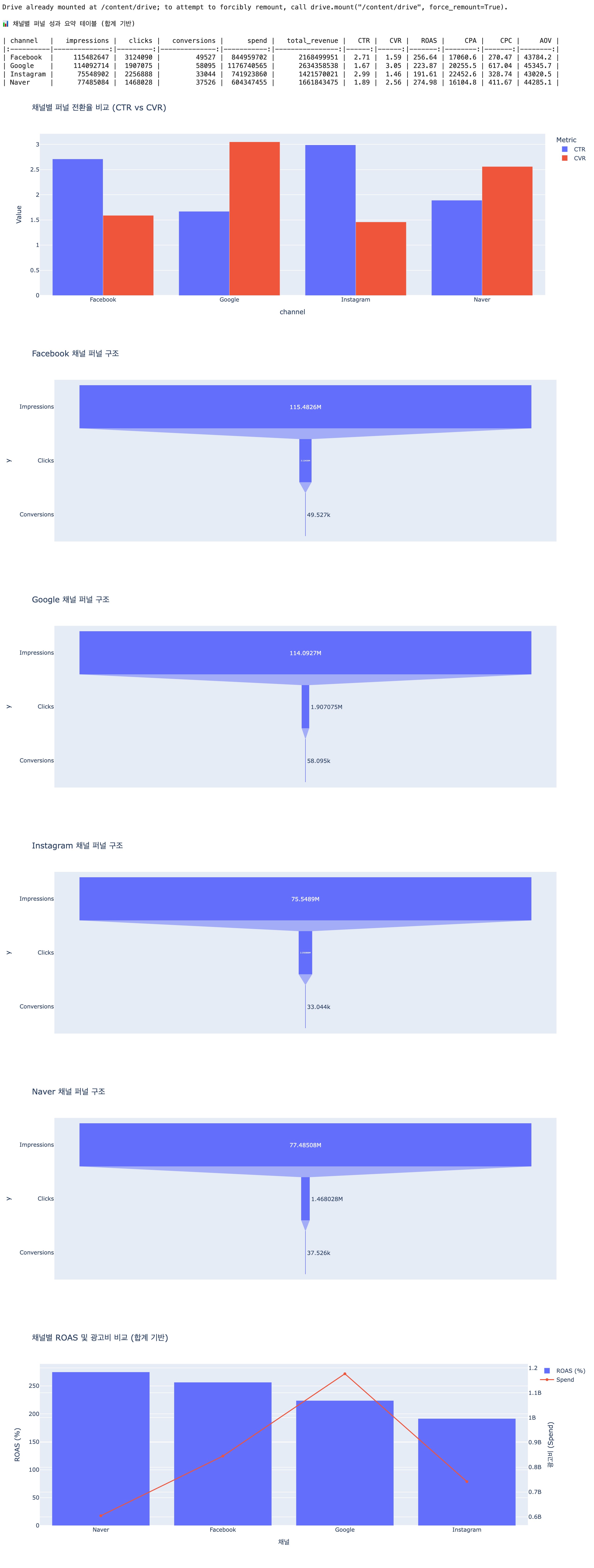
다행히도 수치 차이가 많이 없어서 수치 조금 수정하고 경영인을 대상으로 생각하고 4번 결론과 제안을 추가했습니다~~!
2026.04.14. 화요일
미니 프로젝트 1일차
이전까지 사용한 데이터들은 대부분 고객 기본 정보(성별, 나이 등)랑 성과 지표(CTR, 전환율 등)위주의 데이터로 구성되어 있어서 그런 분석 밖에 못해봐서 아쉬웠는데 이번 데이터는 웹사이트 행동 데이터(WevsiteVisits, PagesPerVisit, TimeOnSite)랑 마케팅 반응 데이터(SocialShares, EmailOpens, EmailClicks)이 있어서 새로운 걸 해볼 수 있었어요!
그런데 이 데이터는 비교적 현실 데이터? 같았어요.. 방문 횟수가 0인데 방문당 페이지 수랑 체류시간이 양수인 경우도 있고.. 그래서 이걸 사용해서 분석하진 않으려고 했어요.

➀ 고객 행동 기반 전환 퍼널 분석
➁ 이메일 마케팅 실효성 분석
➂ 기존 고객 vs 신규 고객 가치 분석
이 세 개중에 쓰려고 고민하다가.. 첫 번째꺼는 최근에 다른 데이터로 퍼널 분석해서 뺐고, 두 번째랑 세 번째 합쳐서 고객 유형(신규/기존)에 따른 이메일 마케팅 반응과 전환 성과 분석으로 주제를 정하고 코드 생성했습니다.
아 기존 고객이랑 신규 고객은 PreviousPurchases가 0보다 크면 기존 고객, 0이면 신규 고객으로 새로운 컬럼 만들었어요!
코드에 문제 없는지.. (특히 평균의 함정 같은거..) 몇 번 확인하고 기업 경영인에게 보여준다고 생각하고 보고서를 발표형 ppt 형식으로 만들 계획까지하고 월요일이 끝났어요.
2026.04.15. 수요일
미니 프로젝트 2일차
결과로 보고서 만들고 있었는데.. 분석을 통해서 낸 결론이 너무 당연한거라 뭔가 부족하다 생각했어요..
그래서 처음엔 기존 고객과 신규 그룹에 대한 어쩌구저쩌구 분석 이렇게 했는데 확장해서 구매 그룹을 다시 구매 횟수에 따라 몇 개의 그룹으로 나눠서 다시 그룹 그룹에 대한 어쩌구저쩌구 분석 이렇게 다시 했고 보고서 ppt도 다시 만들었어요
2026.04.16. 목요일
미니 프로젝트 3일차
제가 앞에 핵심요약 페이지 + 중간에 각 그래프에 대한 설명 + 마지막에 성과 극대화 전략 구조(?)로 썼는데 뭔가 같은 내용이 자꾸 반복되는 느낌이 들었거든요.. 중간에 그래프에 대한 설명 부분에 그래프 사진이랑 해석이랑 전략까지 같이 썼고, 전략 페이지에도 전략을 쓰고, 핵심요약에도 전략 내용이 포함되니까 같은 내용 세 번 말한 사람되어 버렸어요..
그래서 강사님께 말씀드렸더니 제가 생각했던 거랑 비슷한 방법 알려주셨어요. 중간쪽 내용에서 전략을 빼고 마지막에 몰아썼고, 앞쪽 핵심요약은 없애고, 분석 설계 및 접근 방법 페이지 만들었습니다~!

여기 다 올리기도 좀 그렇구 뭔가 부끄러워서 다 보이긴하지만 블러 처리했어요 ㅋㅋ 조만간 따로 포트폴리오용으로 정리할지도..?!
2026.04.17. 금요일
머신러닝
- 기본 개념
지도 학습
정답(라벨)이 있는 데이터로 학습
입력(X) + 정답(Y)
목표: 정답 맞추기
분류, 회귀
비지도학습
입력(X)만 있음
목표: 구조/패턴 발견
군집화, 차원 축소, 연관 규칙, 이상치 탐지
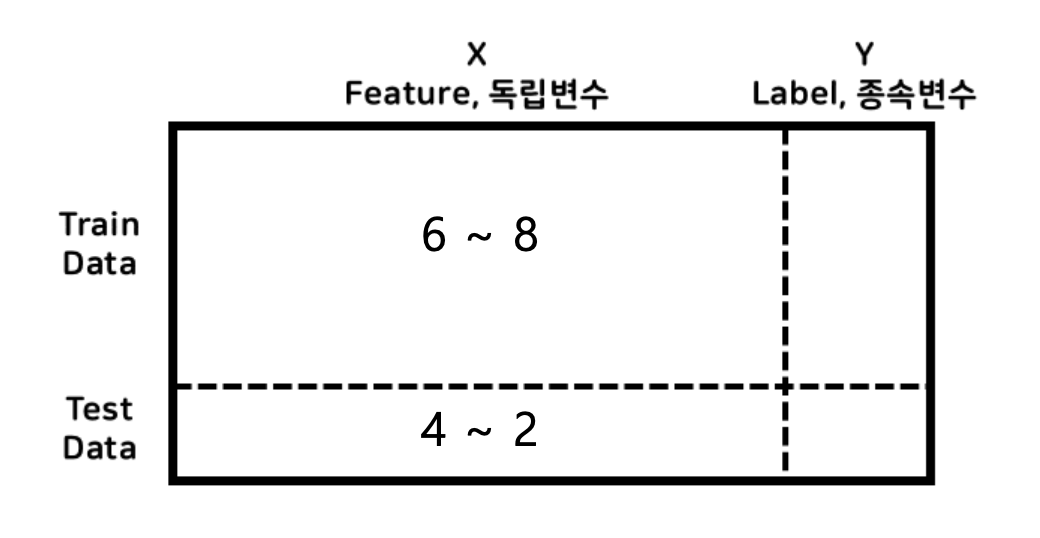
학습용 데이터와 평가 데이터로 분할
모델 평가 척도
① accuracy(정확도)
② recall(재현율)
③ precision(정밀도)
④ f1 score
⑤ MSE / RMSE
⑥ R2 score
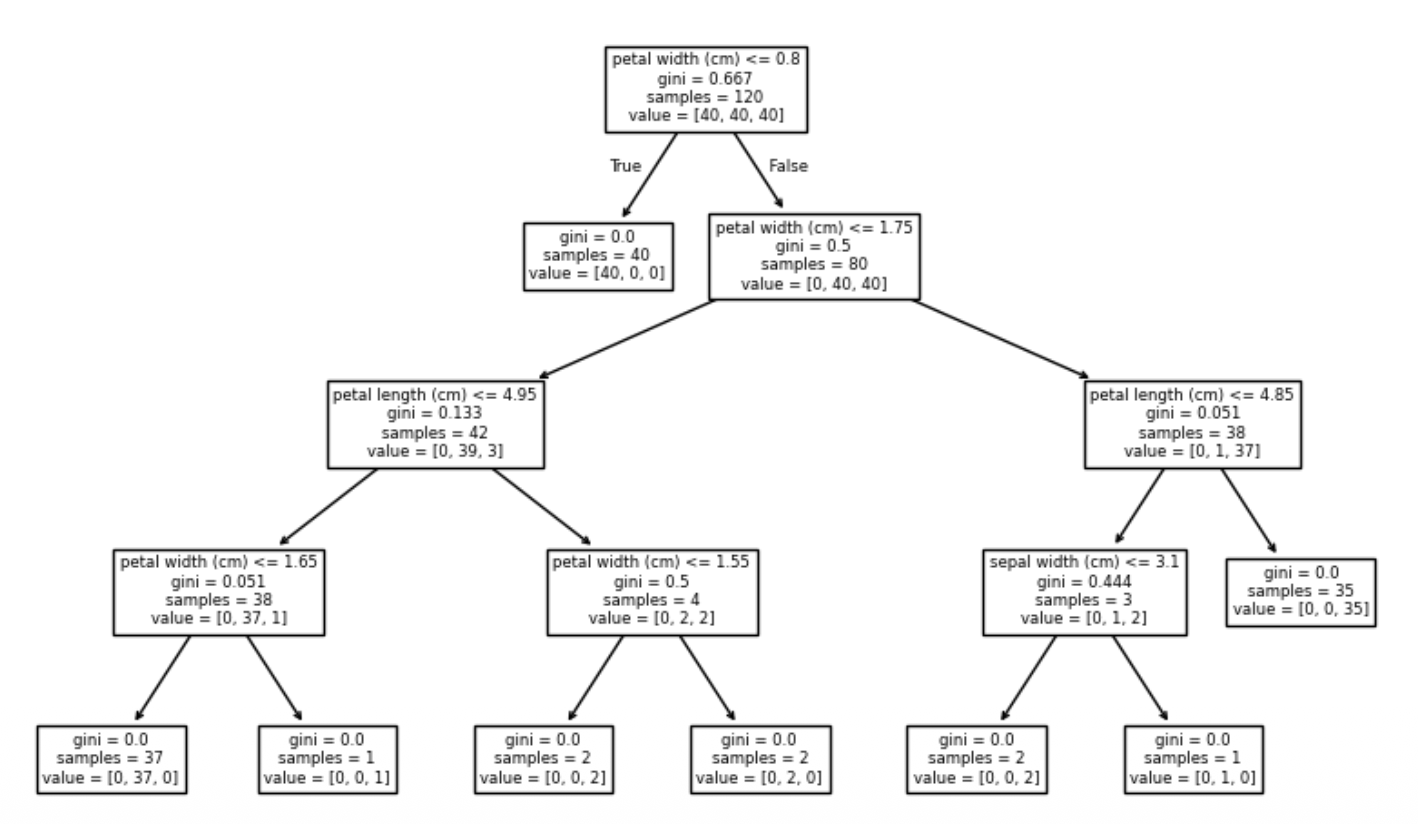
- Decision Tree 분류 모델
Decision Tree: 지도 학습의 기본 모델
직관적 의사결정
AI가 하는 스무고개
- 고객 이탈 데이터 전처리, 탐색 및 EDA (1)
- 용어 정리
Node: Root Node, Intermediate Node(Decision Node), Leaf Node
Tree Depth
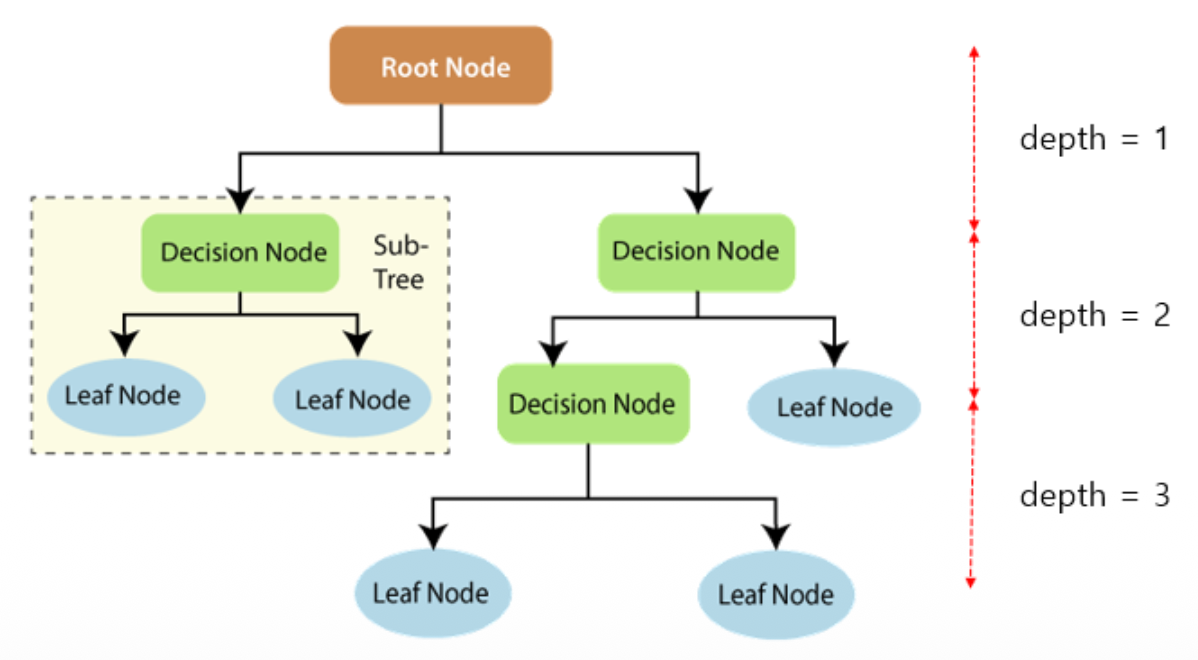
- Decision Tree 분류 모델 실습 - 당뇨병 여부 분류
- 고객 이탈 데이터 전처리, 탐색 및 EDA (2)
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/Telco-Customer-Churn.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
display(df)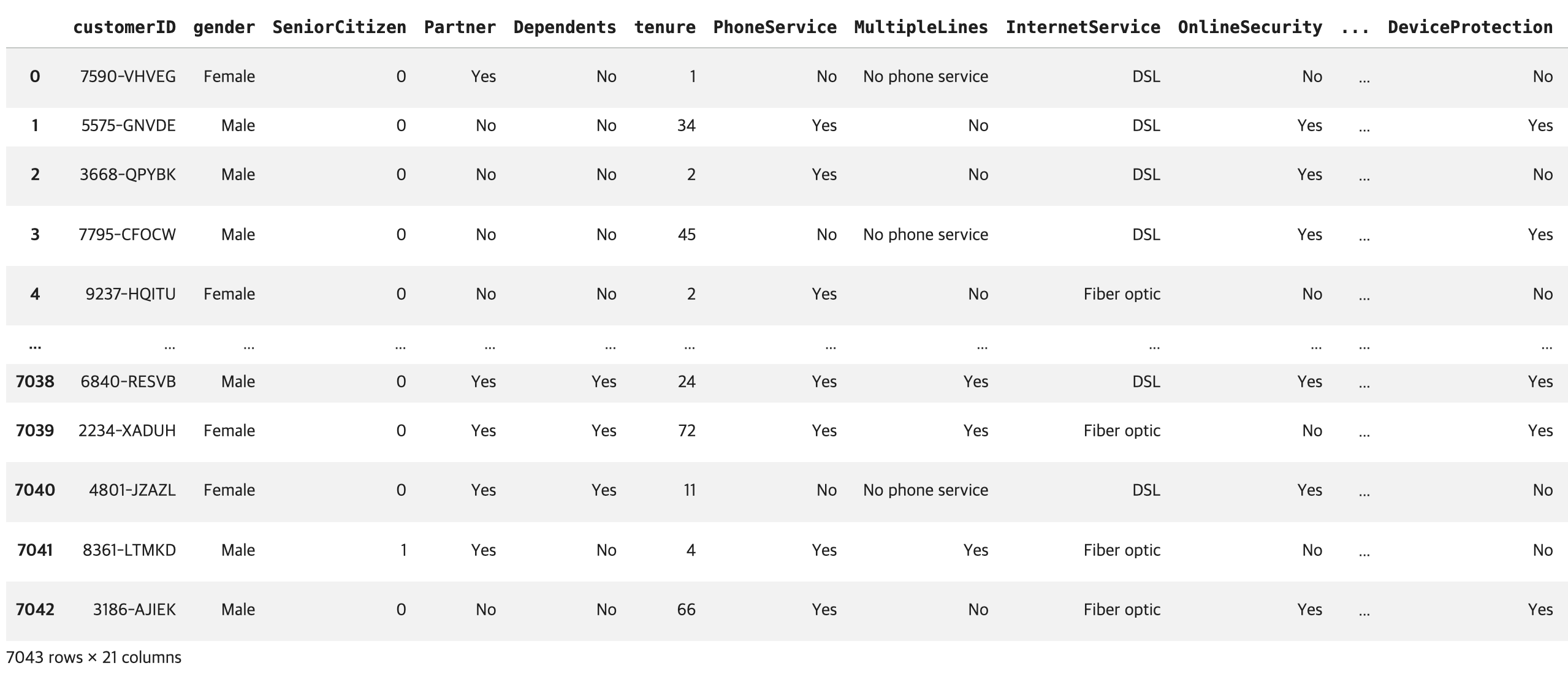
# DataFrame 기본 정보 확인
df.info()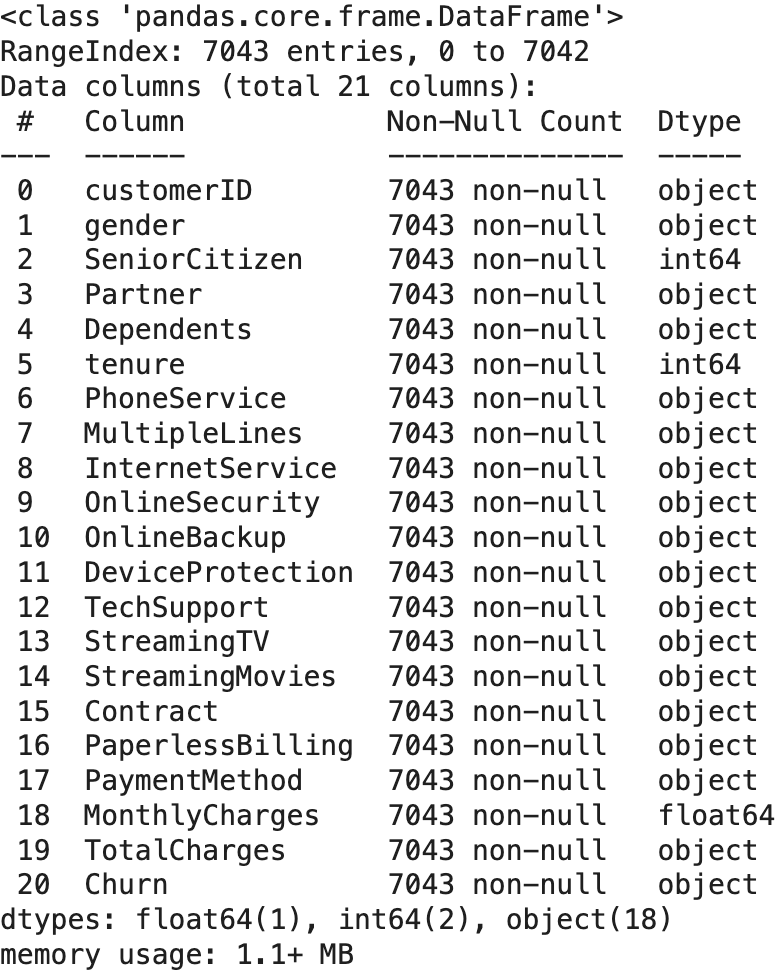
Churn : 고객이 서비스를 떠나는 것 (이탈)
# 문제점: TotalCharges 컬럼 데이터 -> 공백(" ")과 같은 숫자로 변환할 수 없는 문자열로 된 데이터가 있어 object로 인식
## 전처리 방법: TotalCharges 컬럼 데이터 -> 수치형으로 변환,숫자로 변환할 수 없는 문자열 -> 에러 발생, 누락 처리
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce')
## 누락 데이터의 수 확인
null_count = df['TotalCharges'].isnull().sum()
print(f"TotalCharges 컬럼 누락 데이터의 수: {null_count}개")
# 누락 데이터 제거 전 DataFrame 기본 정보 확인
df.info()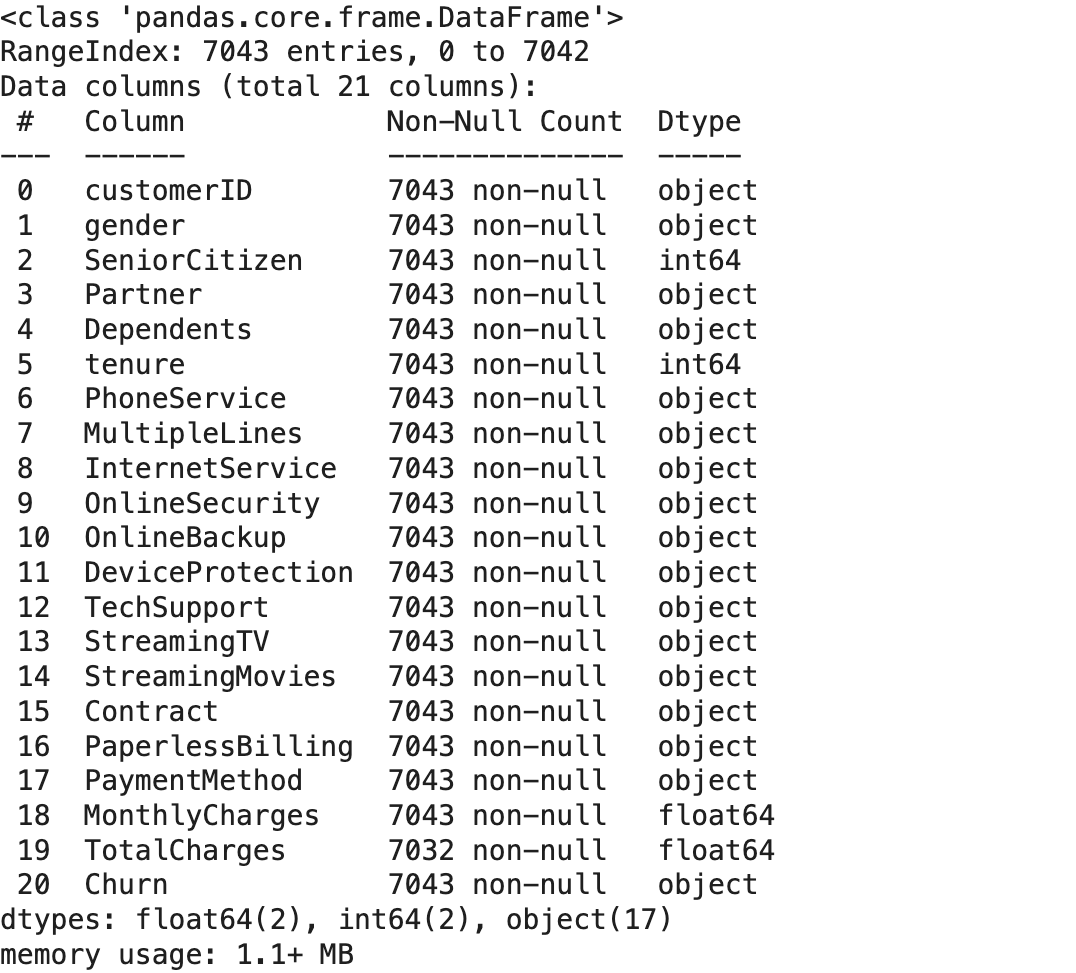
# 누락 데이터 제거
df1 = df.dropna(subset='TotalCharges', ignore_index=True)
display(df1)
print('-'*80)
df1.info()
# 필요한 모듈 임폴트
import plotly.express as px
# 분석 목표: 원 그래프 이용 -> 고객의 이탈 여부 분포 확인
## Churn 컬럼 항목별 빈도수 파악
churn_counts = df1['Churn'].value_counts()
print(churn_counts)
print('-'*80)
## Churn 컬럼 항목별 비율 파악
churn_ratio = df1['Churn'].value_counts(normalize=True)
print(churn_ratio)
print('-'*80)
## Churn 컬럼 항목별 비율 -> reset_index() 함수 -> DataFrame 변환
df_churn_raio = churn_ratio.reset_index()
print(df_churn_raio)
# ## 시각화
fig1 = px.pie(
data_frame=df_churn_raio,
names='Churn',
values='proportion',
title='[차트1] 고객 이탈 비율 ',
hole=0.3
)
fig1.show()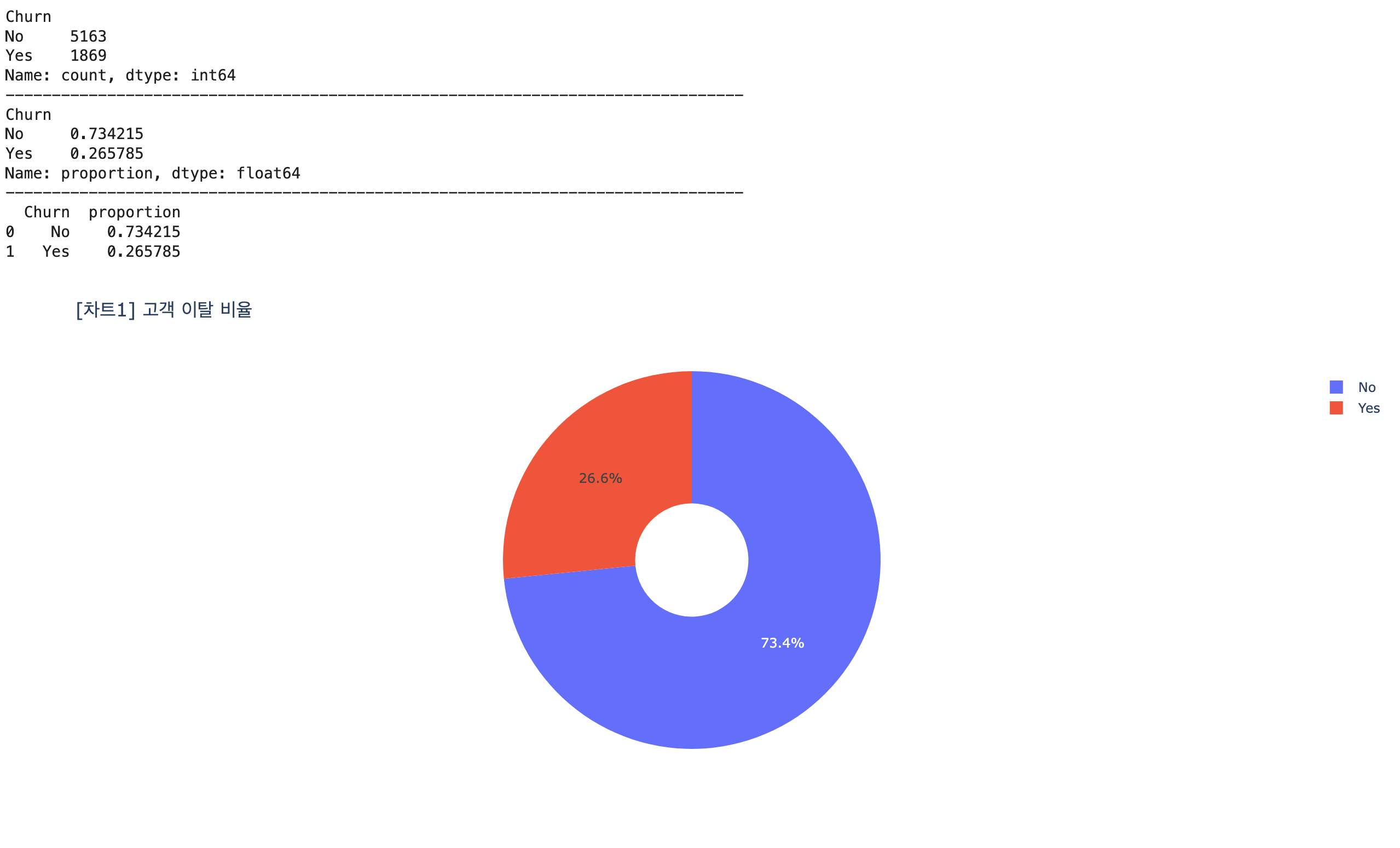
# 분석 목표: 막대 그래프 -> 계약 형태(Contract)와 고객 이탈의 관계 확인
## 계약 형태별 고객 이탈 컬럼의 항목별 데이터의 수(건 수) 추출 -> DataFrame으로 변환
contract_churn_count = df1.groupby(['Contract', 'Churn']).size().reset_index(name='Count')
display(contract_churn_count)
print('-'*80)
## 시각화
fig2 = px.bar(data_frame=contract_churn_count,
x='Contract',
y='Count',
color='Churn',
title='[차트 2] 계약 형태별 고객 이탈 항목별 고객 수 비교',
barmode='group',
text_auto=True)
fig2.show()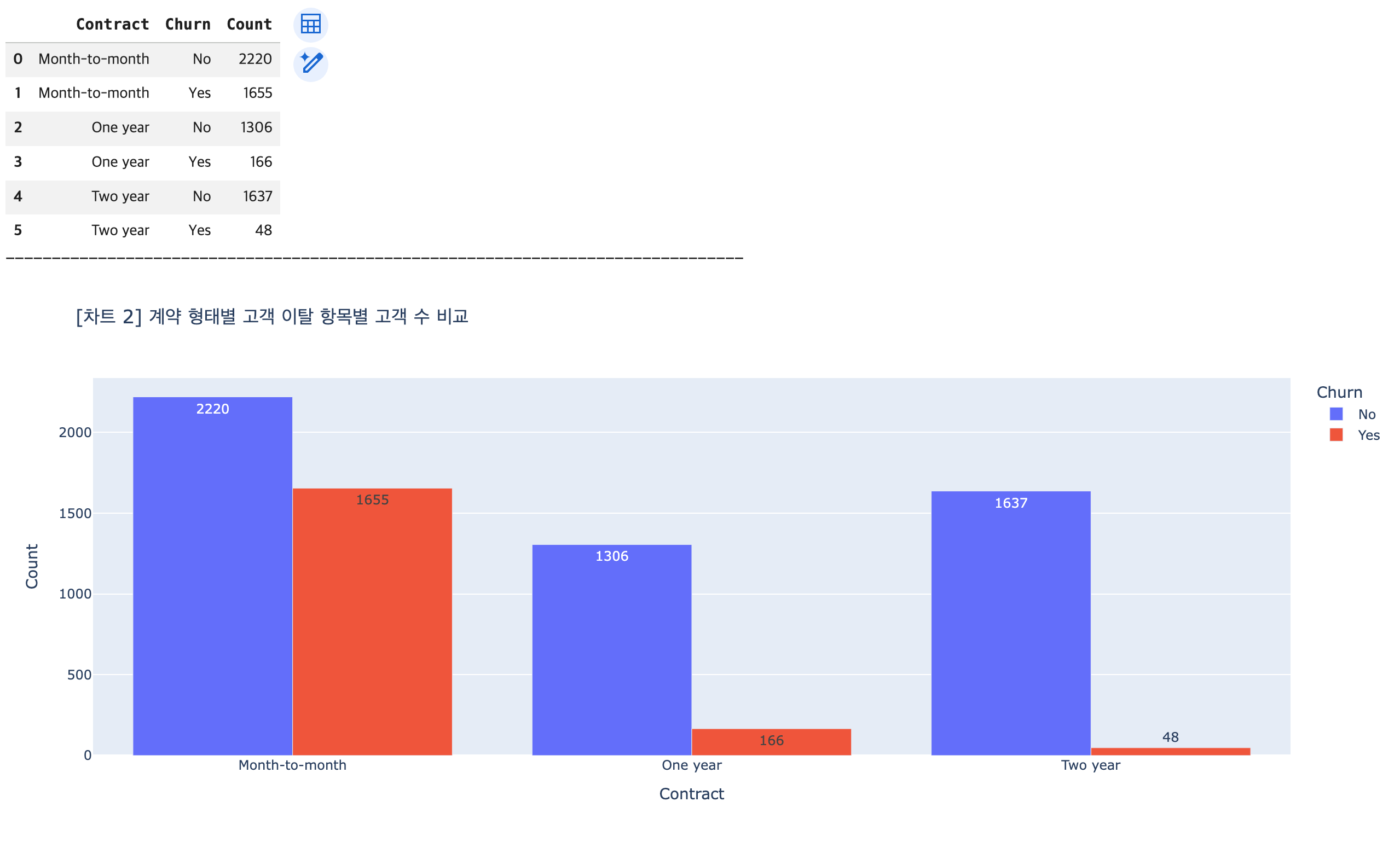
# 분석 목표: 히스토그램 -> 가입 기간(tenure)과 고객 이탈의 관계 확인
## 시각화
fig3 = px.histogram(data_frame=df1,
x="tenure",
color="Churn",
title='[차트 3] 가입 기간(Tenure)에 따른 이탈 분포',
barmode='overlay',
marginal='box')
fig3.show()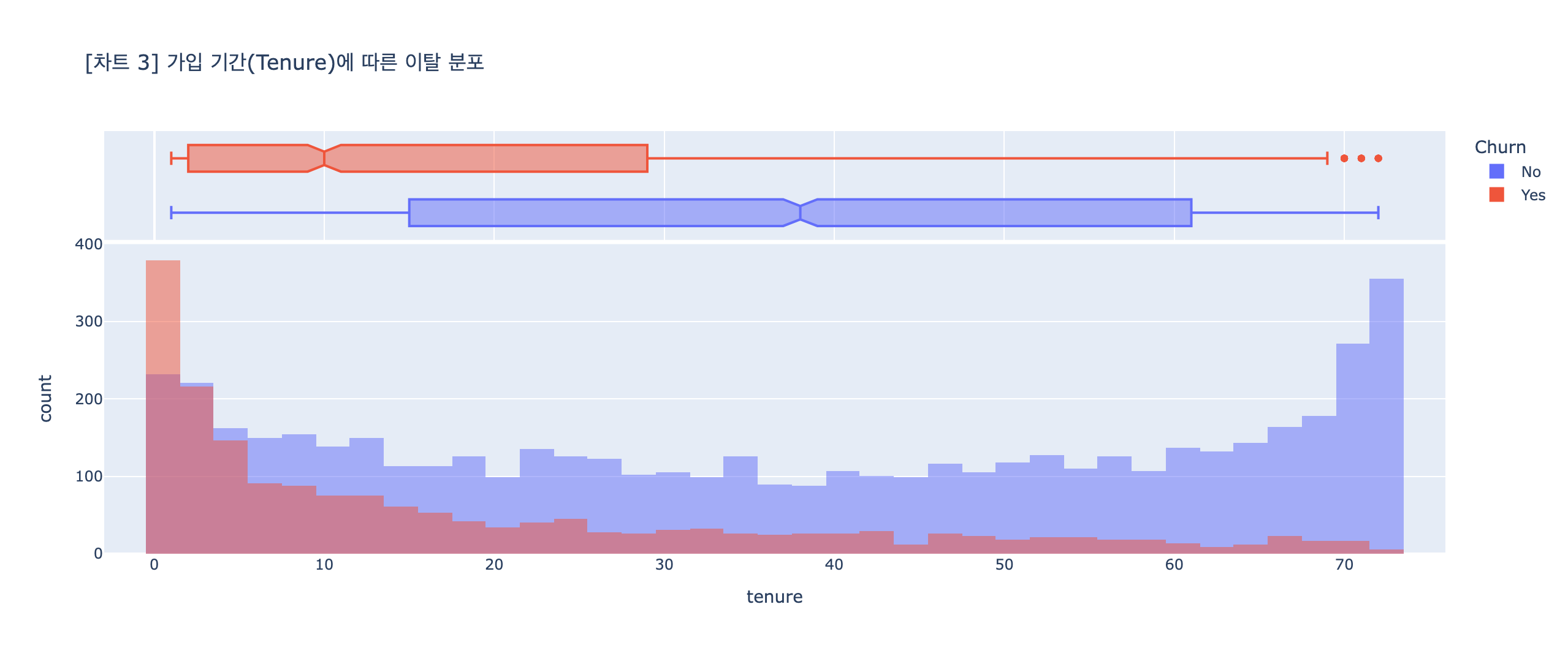
marginal='box' : 데이터를 요약해서 보여줌 (중앙값, 범위, 사분위수, 이상치) ← 전체 구조를 빠르게 파악할 수 있음
# 월 단위 계약이면서 가입 기간이 1년 미만인 고객 데이터 추출 -> 이탈자와 이탈하지 않은 사람의 빈도수
result1 = df1.query("Contract=='Month-to-month' and tenure<12")['Churn'].value_counts()
display(result1)
print('-'*80)
result2 = df1.query("Contract=='Month-to-month' and tenure>=12")['Churn'].value_counts()
display(result2)
# 분석 목표: 히스토그램 -> MonthlyCharges(월 요금)과 고객 이탈의 관계 확인
## 시각화
fig4 = px.histogram(data_frame=df1,
x="MonthlyCharges",
color="Churn",
title="[차트 4] 월 사용 요금(MonthlyCharges)과 고객 이탈 관계",
barmode='overlay',
marginal="rug")
fig4.show()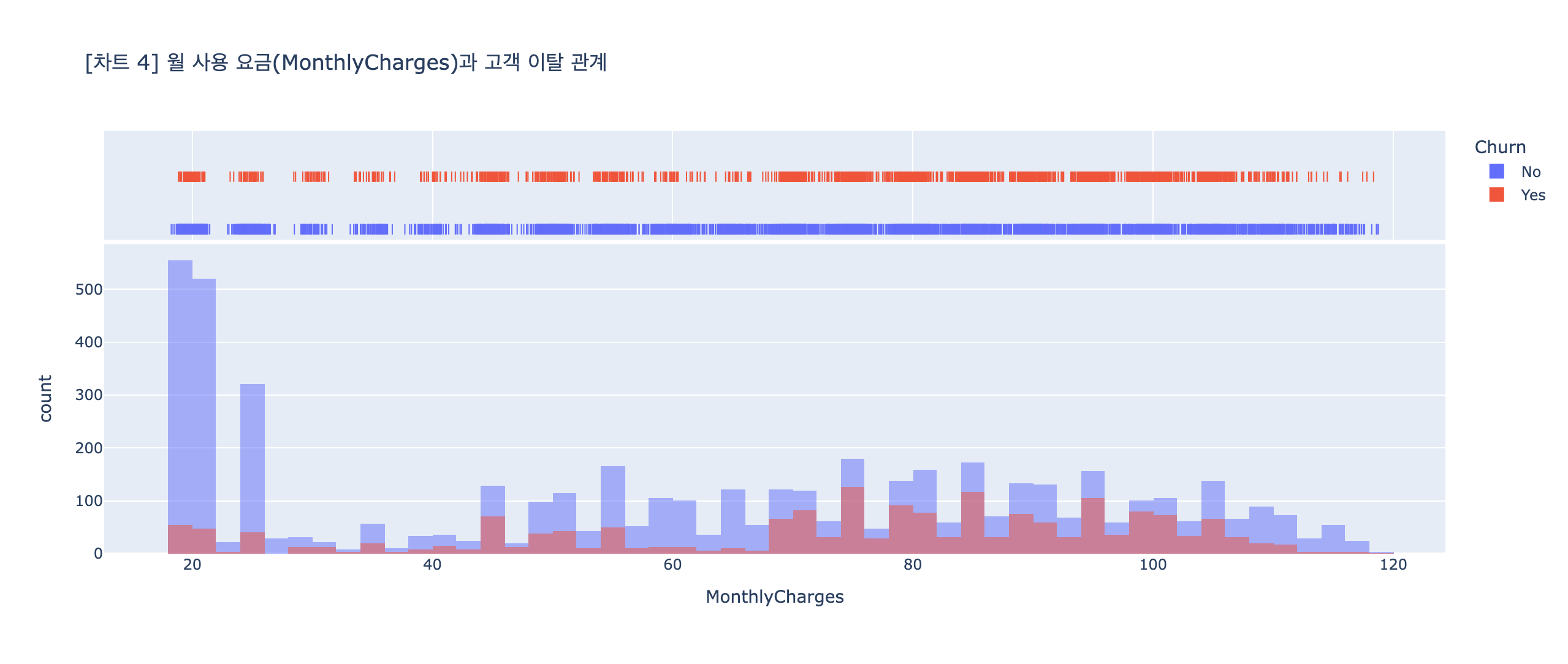
marginal="rug" : 데이터 하나하나 위치 표시 (선 하나 = 데이터 1개) ← 진짜 데이터 분포를 그대로 보여줌
# 분석 목표: 히스토그램 -> TotalCharges(총 누적 요금)과 고객 이탈의 관계 확인
## 시각화
fig5 = px.histogram(data_frame=df1,
x="TotalCharges",
color="Churn",
title="[차트 5] 총 누적 요금(TotalCharges)과 고객 이탈 관계",
barmode='overlay',
marginal="box")
fig5.show()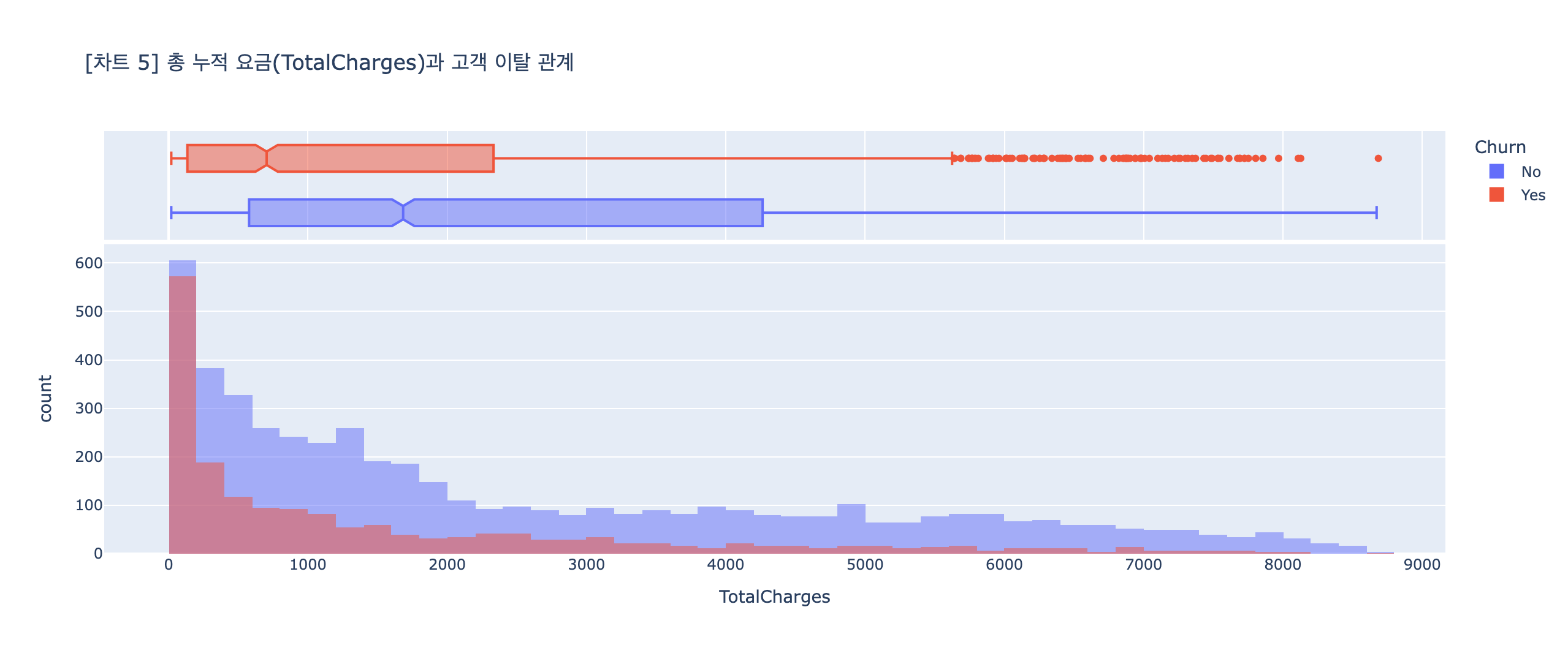
# 분석 목표: 막대 그래프 -> 'InternetService', 'PaperlessBilling', 'OnlineSecurity' 컬럼과 고객 이탈의 관계 확인
## 분석 대상 컬럼 리스트
name_cols = ['InternetService', 'PaperlessBilling', 'OnlineSecurity']
## 시각화: for문 이용
for col in name_cols:
### 각 항목별 이탈자 수 계산
df_churn = df1.groupby([col, 'Churn']).size().reset_index(name='Count')
display(df_churn)
### 시각화
fig = px.bar(data_frame=df_churn,
x=col,
y='Count',
color='Churn',
text_auto=True,
title=f"[차트] {col}에 따른 이탈 현황",
barmode='group')
fig.show()
print('-'*120)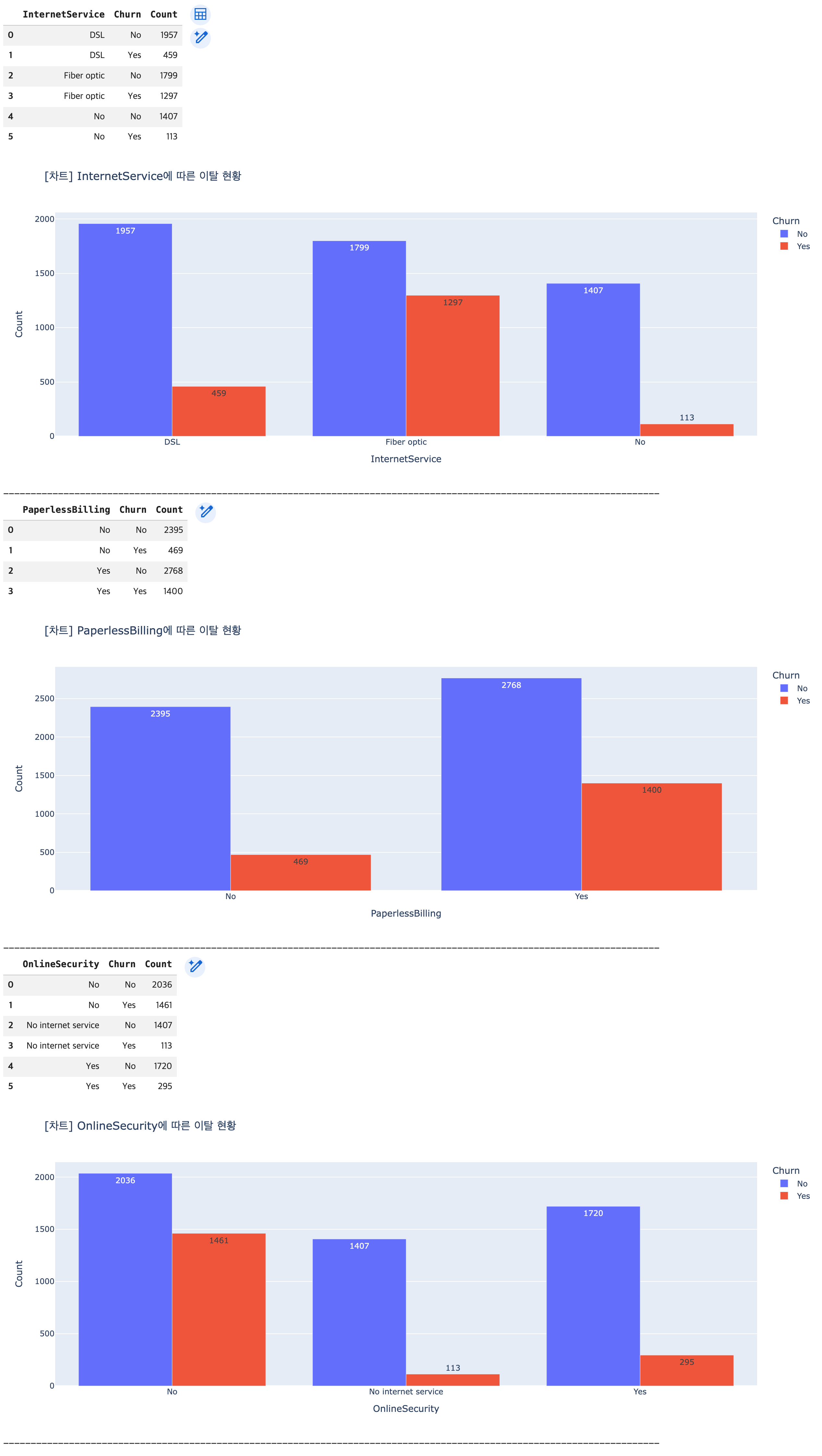
참고) DecisionTree 원리 시각화
from IPython.display import HTML
# 완성도 높은 이진 분할(Binary Split) 시뮬레이션
html_code = """
<div id="wrapper" style="background: #f8f9fa; padding: 25px; border-radius: 15px; font-family: sans-serif; border: 1px solid #dee2e6; max-width: 850px; margin: auto;">
<h3 style="text-align: center; color: #202124; margin-top: 0;">Decision Tree: Binary Split Visualization</h3>
<div style="text-align: center; margin-bottom: 25px;">
<button style="padding: 8px 16px; cursor: pointer; border-radius: 4px; border: 1px solid #ccc;">Reset</button>
<button id="btn1" style="padding: 8px 16px; cursor: pointer; border-radius: 4px; border: none; background: #1a73e8; color: white; font-weight: bold;">Step 1: Is Red?</button>
<button id="btn2" style="padding: 8px 16px; cursor: pointer; border-radius: 4px; border: none; background: #34a853; color: white; font-weight: bold; display: none;">Step 2: Is Blue?</button>
</div>
<div style="display: flex; flex-direction: column; align-items: center; gap: 30px;">
<div style="text-align: center;">
<div style="font-size: 13px; font-weight: bold; margin-bottom: 5px;">Root Node (Mixed)</div>
<div id="gini-root" style="color: #d93025; font-size: 12px; margin-bottom: 8px;">Gini: 0.667</div>
<div id="box-root" style="width: 240px; min-height: 80px; background: white; border: 2px solid #1a73e8; border-radius: 8px; display: flex; flex-wrap: wrap; gap: 4px; padding: 8px; justify-content: center;"></div>
</div>
<div id="lvl1" style="display: flex; gap: 40px; opacity: 0; transition: 0.5s; justify-content: center; width: 100%;">
<div style="text-align: center;">
<div style="color: #1a73e8; font-size: 13px; font-weight: bold;">True (Red)</div>
<div style="color: #d93025; font-size: 12px;">Gini: 0.000</div>
<div id="box-l1" style="width: 160px; min-height: 70px; background: white; border: 2px solid #1a73e8; border-radius: 8px; display: flex; flex-wrap: wrap; gap: 4px; padding: 8px; justify-content: center;"></div>
</div>
<div style="text-align: center;">
<div style="color: #5f6368; font-size: 13px; font-weight: bold;">False (Mixed)</div>
<div style="color: #d93025; font-size: 12px;">Gini: 0.500</div>
<div id="box-r1" style="width: 160px; min-height: 70px; background: white; border: 2px dashed #ccc; border-radius: 8px; display: flex; flex-wrap: wrap; gap: 4px; padding: 8px; justify-content: center;"></div>
</div>
</div>
<div id="lvl2" style="display: flex; gap: 40px; opacity: 0; transition: 0.5s; justify-content: flex-end; width: 100%; padding-right: 20px;">
<div style="text-align: center;">
<div style="color: #34a853; font-size: 13px; font-weight: bold;">True (Blue)</div>
<div style="color: #d93025; font-size: 12px;">Gini: 0.000</div>
<div id="box-l2" style="width: 160px; min-height: 70px; background: white; border: 2px solid #34a853; border-radius: 8px; display: flex; flex-wrap: wrap; gap: 4px; padding: 8px; justify-content: center;"></div>
</div>
<div style="text-align: center;">
<div style="color: #34a853; font-size: 13px; font-weight: bold;">False (Green)</div>
<div style="color: #d93025; font-size: 12px;">Gini: 0.000</div>
<div id="box-r2" style="width: 160px; min-height: 70px; background: white; border: 2px solid #34a853; border-radius: 8px; display: flex; flex-wrap: wrap; gap: 4px; padding: 8px; justify-content: center;"></div>
</div>
</div>
</div>
</div>
<style>
.m { width: 20px; height: 20px; border-radius: 50%; box-shadow: inset -2px -2px 4px rgba(0,0,0,0.2); transition: 0.5s; }
.r { background: #ea4335; } .b { background: #4285f4; } .g { background: #34a853; }
</style>
<script>
function initSim() {
const root = document.getElementById('box-root');
root.innerHTML = '';
const colors = ['r','b','g'];
let temp = [];
colors.forEach(c => { for(let i=0; i<6; i++) temp.push(c); });
temp.sort(() => Math.random() - 0.5);
temp.forEach((c, i) => {
const d = document.createElement('div');
d.className = 'm ' + c; d.id = 'm' + i; d.dataset.c = c;
root.appendChild(d);
});
document.getElementById('lvl1').style.opacity = '0';
document.getElementById('lvl2').style.opacity = '0';
document.getElementById('btn1').style.display = 'inline-block';
document.getElementById('btn2').style.display = 'none';
}
function step1() {
document.getElementById('lvl1').style.opacity = '1';
const root = document.getElementById('box-root');
const l1 = document.getElementById('box-l1');
const r1 = document.getElementById('box-r1');
Array.from(root.children).forEach(m => {
if(m.dataset.c === 'r') l1.appendChild(m);
else r1.appendChild(m);
});
document.getElementById('btn1').style.display = 'none';
document.getElementById('btn2').style.display = 'inline-block';
}
function step2() {
document.getElementById('lvl2').style.opacity = '1';
const r1 = document.getElementById('box-r1');
const l2 = document.getElementById('box-l2');
const r2 = document.getElementById('box-r2');
Array.from(r1.children).forEach(m => {
if(m.dataset.c === 'b') l2.appendChild(m);
else r2.appendChild(m);
});
document.getElementById('btn2').style.display = 'none';
}
initSim();
</script>
"""
display(HTML(html_code))
