
2026.04.20. 월요일
머신러닝
- 기본 개념 복습
- Decision Tree 분류 모델 실습 - 당뇨병 여부 분류
- Decision Tree 분류 모델의 주요 매개변수 정리
- 모델 평가 방법의 개선
- GridSerchCV를 이용한 모델 성능 최적화
- 평가 방법 개선과 GridSerchCV를 이용한 Decision Tree 분류 모델 실습
은행 캠페인 성과 예측 데이터 탐색 및 EDA (내용 생략)
[ 당뇨병 여부 분류 ]
- 데이터 불러오기
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 임포트
import pandas as pd
# DataFrame 생성
## 파일 경로 설정
file_path="/content/drive/MyDrive/KDT/diabetes_binary_5050split_health_indicators_BRFSS2015.csv"
## pd.read_csv() 함수 호출
df = pd.read_csv(file_path)
## 결과 확인하기
display(df)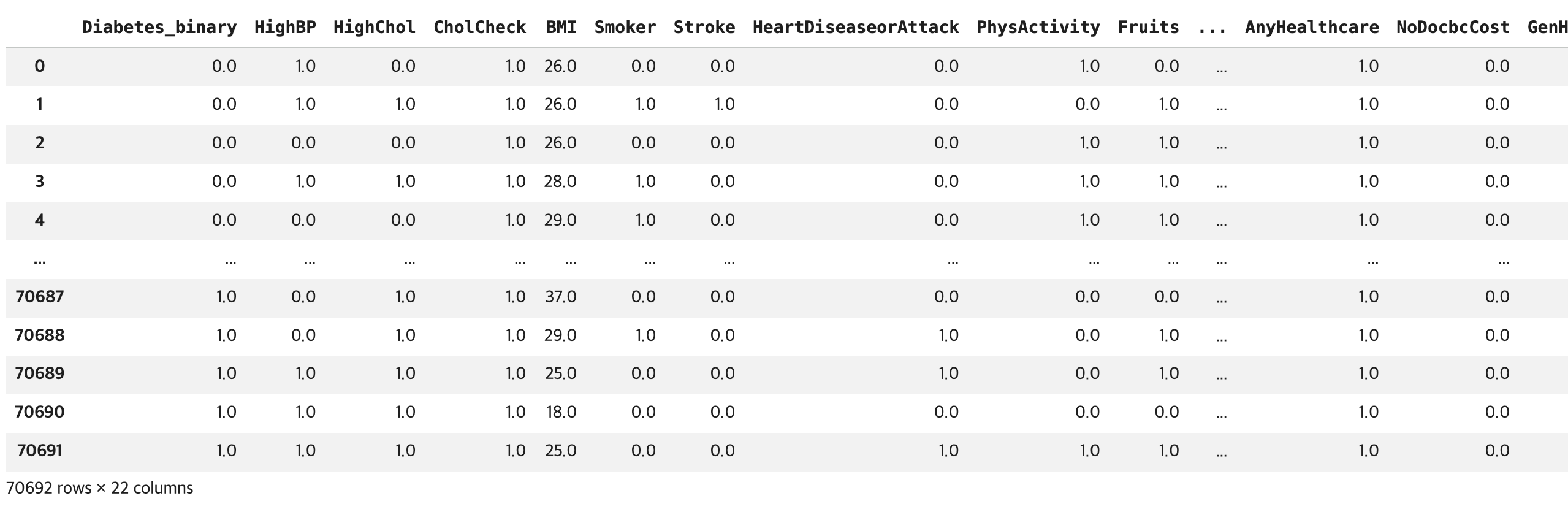
# DataFrame에 대한 기본 정보 확인
df.info()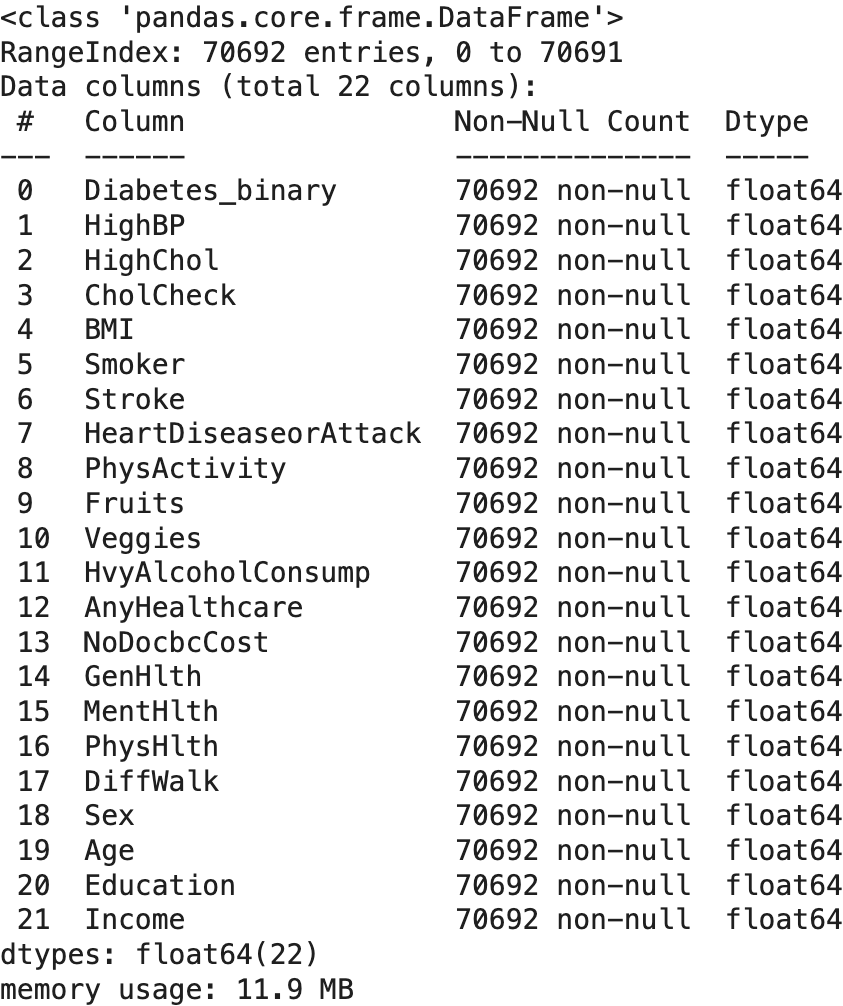
- 학습용과 평가용 데이터 생성
# 필요한 라이브러리 설치 -> 터미널 설치 -> colab 설치 완료
# pip install scikit-learn
# 필요한 함수 임포트
from sklearn.model_selection import train_test_split
# 전체 데이터 -> 학습용: 평가용 = 80: 20으로 분할
## X_data(feature) 생성: 전체 DataFrame 정답 컬럼 삭제
X_data = df.drop(columns=['Diabetes_binary'])
display(X_data)
print('-'*80)
## y_data(정답 y) 생성: Diabetes_binary 컬럼 인덱싱
y_data = df['Diabetes_binary']
print(y_data)
print('-'*80)
## train_test_split() 함수 호출 -> 생성용, 평가용 데이터 생성
X_train, X_test, y_train, y_test = train_test_split(X_data,
y_data,
test_size=0.2,
random_state=0,
stratify=y_data)
# 학습용 데이터 확인
## 인덱스 확인
print(X_train.index)
print('-'*80)
## 정답의 항목별 빈도수
print(y_train.value_counts())
- Decision Tree 분류 모델을 이용한 당뇨병 여부 분류 (모델 생성 / 모델 학습 / 모델 학습 시 생성된 의사결정 트리 구조 시각화)
-- 모델 생성
# 필요한 함수 임포트
from sklearn.tree import DecisionTreeClassifier
# DecisionTreeClassifier 함수 호출, 모델 생성
dt = DecisionTreeClassifier(random_state=0, max_depth=5)
print(dt)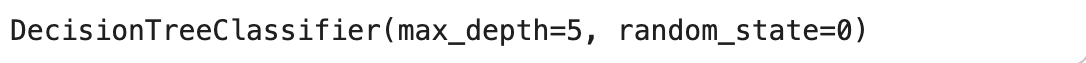
random_state: 재현성
max_depth: 의사 결정의 총 단계 수 (최대 깊이)
-- 모델 학습
# 학습 결과: 모델 내부에 저장
dt.fit(X_train, y_train)
-- 모델 학습 시 생성된 의사 결정 트리 구조 시각화
# 학습 시 생성된 의사 결정 트리의 최대 깊이 추출
max_depth = dt.get_depth()
print(f'학습된 모델의 최대 깊이: {max_depth}')
# 필요한 함수 임폴트
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 이미지의 크기 재설정
plt.figure(figsize=(20,10))
# plot_tree() 함수 호출
plot_tree(
decision_tree=dt,
max_depth=3,
feature_names=X_train.columns,
filled=True
)
plt.show()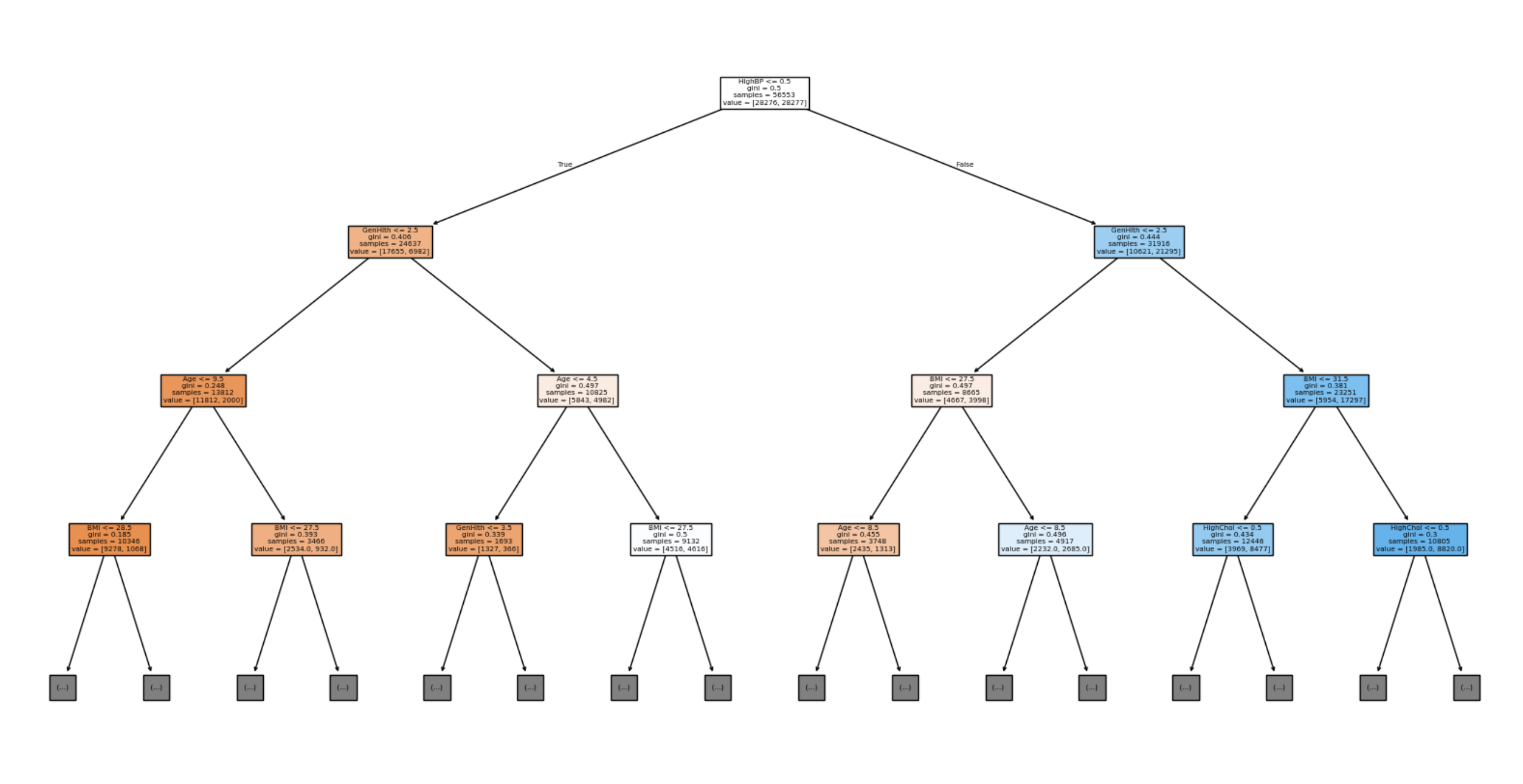
⭐️ Decision Tree 해석 ⭐️
① 박스 구조
조건 (feature ≤ 기준값)
gini = 불순도
samples = 데이터 개수
value = [클래스0, 클래스1]
② 루트 노드 기준으로 해석
HighBP <= 0.5
→ 고혈압 여부 (0 = 없음, 1 = 있음)
해석: 고혈압 없는 사람 vs 있는 사람으로 첫 분기
gini = 0.5
→ 완전 섞임 (50:50), 아직 구분 잘 안 된 상태
samples = 56553
value = [28276, 28277]
→ 거의 반반
③ 왼쪽 가지 vs 오른쪽 가지
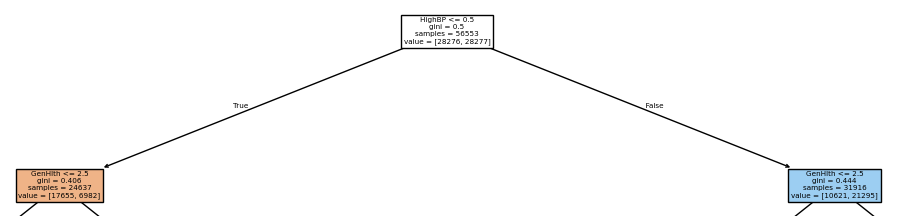
왼쪽 (True)
→ HighBP ≤ 0.5
→ 고혈압 없는 사람
오른쪽 (False)
→ HighBP > 0.5
→ 고혈압 있는 사람
⭐️ 트리는 항상 가장 잘 나눌 수 있는 기준을 먼저 선택
(= 각 노드에서 불순도가 최소화되는 방향으로 분할 기준을 결정)
→ 여기서는 고혈압이 가장 영향력이 큼
④ 다음 분기 해석 (왼쪽 가지, 오른쪽 가지 각각 해석)
왼쪽 가지
GenHlth <= 2.5
전반적 건강 상태 (1~5)
2.5 기준으로 나눔
→ 건강 좋음 vs 안 좋음
Age <= 28.5
→ 나이 기준으로 분리
BMI <= 28.5
→ 체질량지수 기준으로 분리
⇨ 고혈압 없음 → 건강상태 → 나이 → BMI ... 점점 더 세밀하게 나눔
오른쪽 가지
HighBP > 0.5 → GenHlth → BMI → Age → HighChol
⇨ 고혈압 있음 → 건강상태 → BMI → 나이 → 콜레스테롤로 더 세분화
⑤ Gini Impurity (지니 불순도)
데이터가 얼마나 섞여 있는지(혼잡도)를 나타내는 값
의사결정트리에서 분기 기준으로 사용
값의 의미 (이진 분류 기준)
0에 가까움 → 한 클래스만 있음 (깔끔하게 분류됨)
0.5에 가까움 → 반반 섞임 (분류 안 됨)
ex.
gini = 0.0497
value = [4667, 398]
→ 거의 다 0번 클래스 → 매우 잘 나뉜 상태
⑥ Value 해석
value = [11812, 2000]
0번 클래스: 11812
1번 클래스: 2000
→ 이 노드는 0으로 예측
⑦ 색깔 의미
🔵 파랑 → 클래스 1 많음
🟠 주황 → 클래스 0 많음
색 진할수록 → 확신 높음
⑧ “왜 저 기준으로 나눴냐?”
→ Gini impurity를 가장 많이 줄이는 기준 선택
⑨ 실제 해석 방법
1️⃣ HighBP ≤ 0.5
→ 고혈압 없음
2️⃣ GenHlth ≤ 2.5
→ 건강 좋음
3️⃣ Age ≤ 28.5
→ 젊음
4️⃣ BMI ≤ 28.5
→ 정상 체중
⇨ 당뇨 가능성 낮음 (0)
2026.04.21. 화요일
머신러닝
- 기본 개념 복습
- Decision Tree 분류 모델 실습 - 당뇨병 여부 분류
- Decision Tree 분류 모델의 주요 매개변수 정리
- 모델 평가 방법의 개선
- GridSerchCV를 이용한 모델 성능 최적화
- 평가 방법 개선과 GridSerchCV를 이용한 Decision Tree 분류 모델 실습
온라인 쇼핑객 구매 의도 데이터 탐색 및 EDA (내용 생략)
-- 평가용 데이터를 이용한 예측
pred_test = dt.predict(X_test)
print(f'평가용 데이터에 대한 예측의 결과: \n{pred_test}')
print('-'*80)
print(f'평가용 데이터의 정답: \n{y_test}')
# 보충: 학습용 데이터에 대한 예측
pred_train = dt.predict(X_train)
print(f'학습용 데이터에 대한 예측의 결과: \n{pred_train}')
-- 모델 평가
# 필요한 함수 임포트
from sklearn.metrics import accuracy_score
# 평가용 데이터에 대한 성능 평가
accuracy = accuracy_score(y_test, pred_test)
# 학습용 데이터에 대한 성능 평가
accuracy_train = accuracy_score(y_train, pred_train)
# 결과 확인
print(f'평가용 데이터에 대한 성능: {accuracy}')
print('-'*80)
print(f'학습용 데이터에 대한 성능: {accuracy_train}')
[ GridSearchCV를 이용한 모델 최적화 ]
- best 모델 생성
# 필요한 함수 임포트
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 최적화 할 기본 모델
dt = DecisionTreeClassifier(random_state=0)
# 최적화 할 매개 변수와 탐색 조건 설정
params = {'max_depth':[3,4,5,6,7,8,9,10]}
# GridSearhCV 함수 호출, 탐색 모델 생성
grid_dt = GridSearchCV(
estimator=dt,
param_grid=params,
cv=10,
scoring='accuracy'
)
# 학습 및 검증: 학습 및 검증의 결과 -> 탐색 모델 내부에 저장
grid_dt.fit(X_train, y_train)
# 최적의 성능일때의 파라미터 확인
print(grid_dt.best_params_)
# 최적의 성능일때의 정확도 확인
print(grid_dt.best_score_)
# best 모델 추출(학습이 완료된 상태)
best_dt = grid_dt.best_estimator_
print(best_dt)
- best 모델의 의사 결정 트리 구조 시각화
# 필요한 함수 임폴트
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 이미지의 크기 재설정
plt.figure(figsize=(20,10))
# plot_tree() 함수 호출
plot_tree(
decision_tree=best_dt,
max_depth=3,
feature_names=X_train.columns,
filled=True
)
plt.show()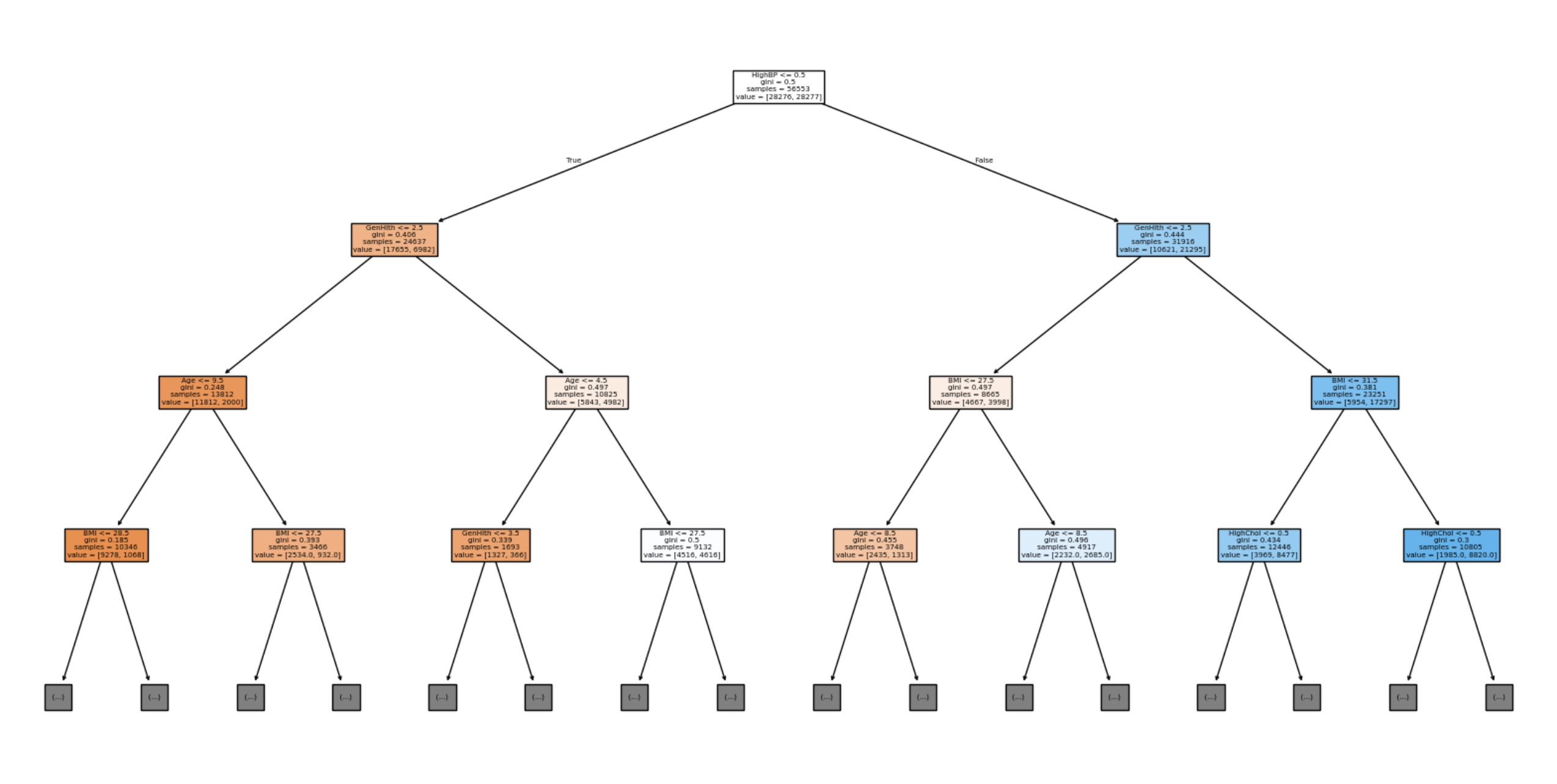
- 평가용 데이터를 이용한 예측
pred_test = best_dt.predict(X_test)
print(pred_test)
- best 모델 평가
# 필요한 함수 임포트
from sklearn.metrics import accuracy_score
# 평가용 데이터에 대한 성능 평가
accuracy = accuracy_score(y_test, pred_test)
# 결과 확인
print(f'평가용 데이터에 대한 정확: {accuracy}')
2026.04.22. 수요일

머신러닝
- AutoML: AutoGluon을 이용한 당뇨병 여부 분류 실습
- 앙상블(Ensemble) 소개
- 특성 중요도(Feature Importance)
- 분류 평가 지표
- 고객 이탈 예측
- 지도 학습을 이용한 회귀
온라인 쇼핑객 구매 의도 데이터 퍼널 분석 (내용 생략)
[ AutoGluon을 이용한 당뇨병 예측 ]
# colab: 무료 gpu 설정
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 설치
!pip install autogluon- 데이터 불러오기
# 필요한 라이브러리 임포트
import pandas as pd
# DataFrame 생성
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/diabetes_binary_5050split_health_indicators_BRFSS2015.csv'
## pd.read_csv() 함수 호출
df = pd.read_csv(file_path)
## 결과 확인
display(df)
- 학습용과 평가용 데이터 생성
# 필요한 함수 임포트
from sklearn.model_selection import train_test_split
# 80: 20의 비율로 분할
## train_test_split() 함수 호출
train_df, test_df = train_test_split(df,
test_size=0.2,
random_state=0,
stratify=df['Diabetes_binary'])
## 결과 확인(1): 학습용 데이터의 인덱스
info_index = train_df.index
print(info_index)
print('-'*80)
## 결과 확인(2): 학습용 데이터의 정답별 빈도수
print(train_df['Diabetes_binary'].value_counts())
- 모델 생성
# 필요한 함수 임포트
from autogluon.tabular import TabularPredictor
# TabularPredictor 함수 호출, 모델 생성
predictor = TabularPredictor(
label='Diabetes_binary',
problem_type='binary',
eval_metric='accuracy',
path='/content/drive/MyDrive/KDT/autogluon_model'
)label
→ 맞춰야 할 정답 컬럼
problem_type
→ binary = 이진 분류
eval_metric
→ accuracy 기준으로 성능 평가
path
→ 모델 저장 위치
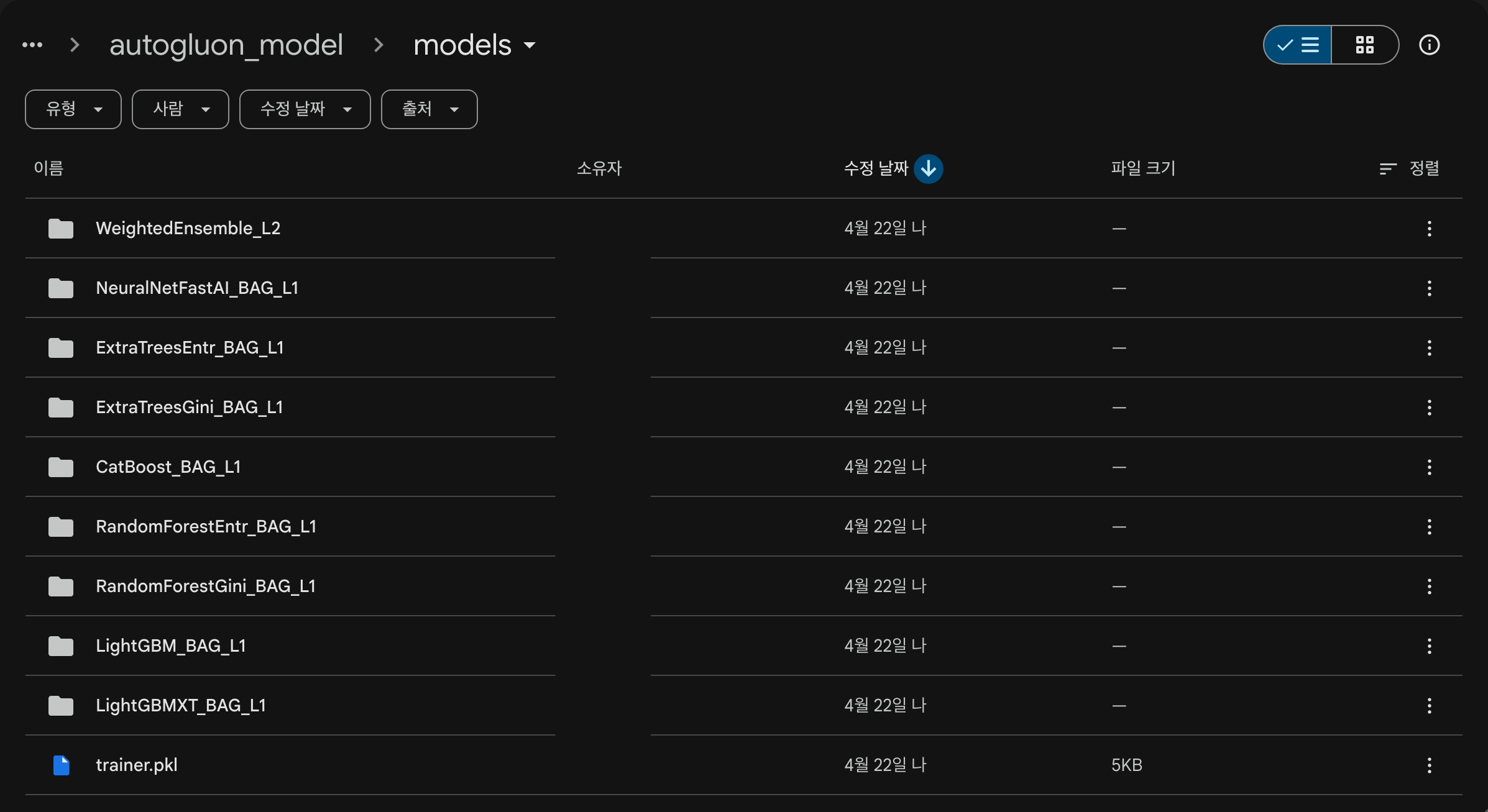
지정한 path 경로에 AutoGluon이 학습한 개별 모델들과 앙상블 모델이 모두 저장되며, 이후 재사용이 가능함
그리고 구글 코랩의 T4 GPU를 이용해 약 10분간 학습한 결과를 저장해두면, 시간 초과 등으로 다시 학습해야 하는 상황을 방지할 수 있음
[모델이름]_[학습방식]_[레벨]
모델 이름
ex. LightGBM, RandomForest, CatBoost, NeuralNetFastAI
→ 어떤 알고리즘인지 표시
BAG = Bagging (배깅)
데이터를 여러 번 나눠서, 같은 모델을 여러 개 학습시키는 방식
→ 과적합 줄임, 안정성 ↑
L1, L2 (L = Layer (단계))
L1 (Level 1)
→ 기본 모델들
ex. LightGBM_BAG_L1, RandomForest_BAG_L1
→ 데이터로 바로 학습한 모델들
L2 (Level 2)
→ 상위 모델 (앙상블)
ex. WeightedEnsemble_L2
→ L1 모델들의 결과를 입력으로 사용
- 모델 학습, 최적화, best 모델 생성(검증 포함)
predictor.fit(
# 학습용 데이터 입력
train_data=train_df,
# 학습 전략 설정
presets='best_quality',
# GPU 사용 설정
ag_args_fit={'num_gpus':1},
# 학습 시간
time_limit=600
)(출력 생략)
train_data
→ 모델 학습에 사용되는 데이터 (입력 변수와 정답 포함)
presets=‘best_quality’
→ 최대 성능 목표, 여러 모델 다 돌림, 시간 오래 걸림
num_gpus=1
→ GPU 사용
time_limit=600
→ 600초 (10분) 동안 학습
# 학습에 사용된 모델 모델 성능 비교
leaderboard = predictor.leaderboard()
display(leaderboard)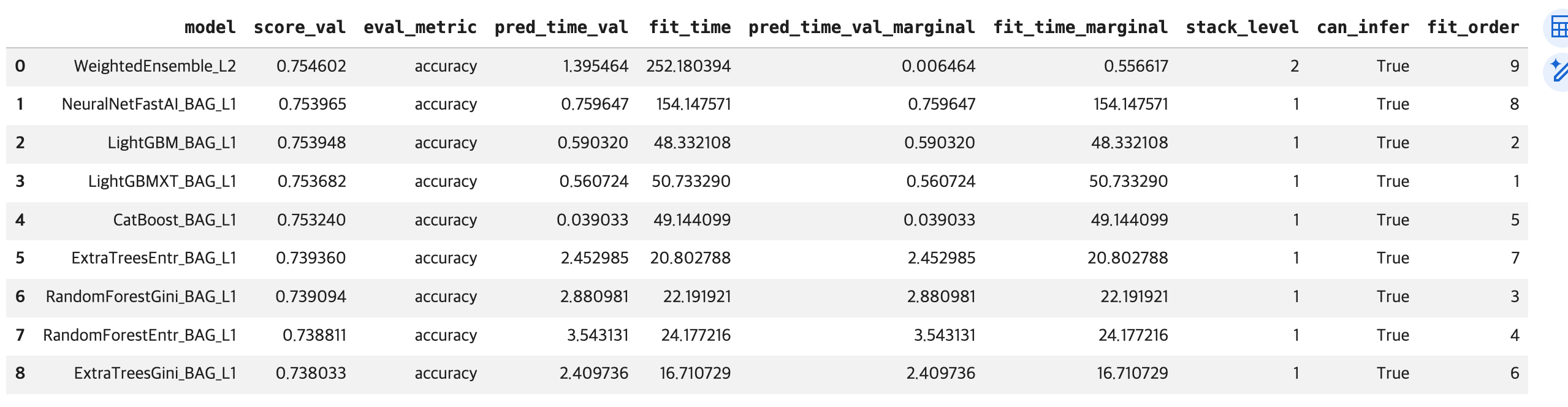
# best 모델: 모델들을 블렌딩(혼합 비율-> 가중치)
best_model = predictor.model_best
print(f'best 모델: {best_model}')- 평가용 데이터를 이용한 성능 평가
# evaluate() 함수 호출: 정답이 포함된 평가용 데이터 입력, 예측과 평가를 한 번에 수행
performance = predictor.evaluate(data=test_df)
# print(f'best 모델의 성능 평가: {performance}')
print(f'best 모델의 성능 평가: {performance["accuracy"]}')
- 저장된 모델 불러오기
# 필요한 함수 임포트
from autogluon.tabular import TabularPredictor
# load() 함수 호출, 저장된 폴더 경로 입력
path='/content/drive/MyDrive/KDT/autogluon_model'
loaded_predictor = TabularPredictor.load(path)
# 저장된 모델의 성능 확인
performance = loaded_predictor.evaluate(data=test_df)
print(f'저장된 모델의 성능 평가: {performance["accuracy"]}')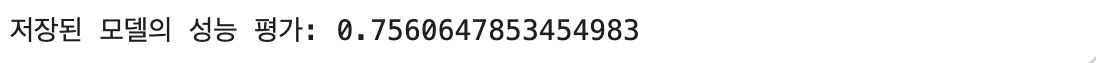
# 평가용 데이터에 대한 예측
print(loaded_predictor.predict(data=test_df))
- best 모델의 구성 확인
# best 모델 이름 가져오기
best_model_name = loaded_predictor.model_best
print(best_model_name)
print('-'*80)
# 모델 정보(info)를 통해 가중치 확인
info = loaded_predictor.info()
best_model_info = info['model_info'][best_model_name]
print(best_model_info)
⇨ 어제까지 Decision Tree를 직접 설정하던 과정을, AutoGluon이 모델 선택, 학습, 하이퍼파라미터 튜닝 등을 포함해 자동으로 수행함
[ 앙상블 (Ensemble) ]
여러 개의 모델을 결합하여 단일 모델보다 더 높은 성능을 내는 기법
- Bagging
하나의 모델(주로 Decision Tree)을 여러 개 생성한 뒤, 서로 다른 데이터 샘플로 독립적으로 학습하고, 각 모델의 예측 결과를 결합하여 최종 결과를 도출하는 방식
→ 데이터의 일부를 여러 번 샘플링하여 모델을 학습시키므로 과적합을 줄이고 안정적인 성능을 얻을 수 있음
→ 결과 결합 방식: 분류는 다수결, 회귀는 평균값 사용
대표 모델: Random Forest
- Boosting
여러 개의 모델을 순차적으로 학습하며, 이전 모델이 틀린 데이터를 다음 모델이 보완하는 방식
→ 오차를 점진적으로 줄여가며 학습하기 때문에 일반적으로 Bagging보다 높은 성능을 보임
대표 알고리즘: XGBoost, LightGBM, CatBoost
- 특성 중요도
모델이 예측을 수행할 때, 각 특성(feature)이 결과에 얼마나 영향을 미쳤는지를 나타내는 지표
→ 모델의 의사결정 과정을 해석할 수 있는 중요한 단서가 됨
예를 들어, 마케팅 성과를 예측하는 모델에서는 어떤 고객 특성이 성과에 큰 영향을 미치는지 파악할 수 있음
2026.04.23. 목요일
머신러닝
- 특성 중요도 분석 및 시각화
- 분류 평가 지표 정리
- 고객 이탈 예측
- 지도 학습을 이용한 회귀
이커머스 고객 월 예상 구매액 예측 데이터 분석
- 특성 중요도 분석 및 시각화
# 특성 중요도: 어떤 컬럼이 당뇨병 예측(정상과 환자로 분류)에 가장 큰 기여를 했는지 수치적으로 계산
importance = loaded_predictor.feature_importance(test_df)
display(df_importance)
print('-'*80)
# reset_index() 함수 적용 -> 행 인덱스 -> 컬럼으로 변환
df_importance = importance.reset_index()
display(df_importance)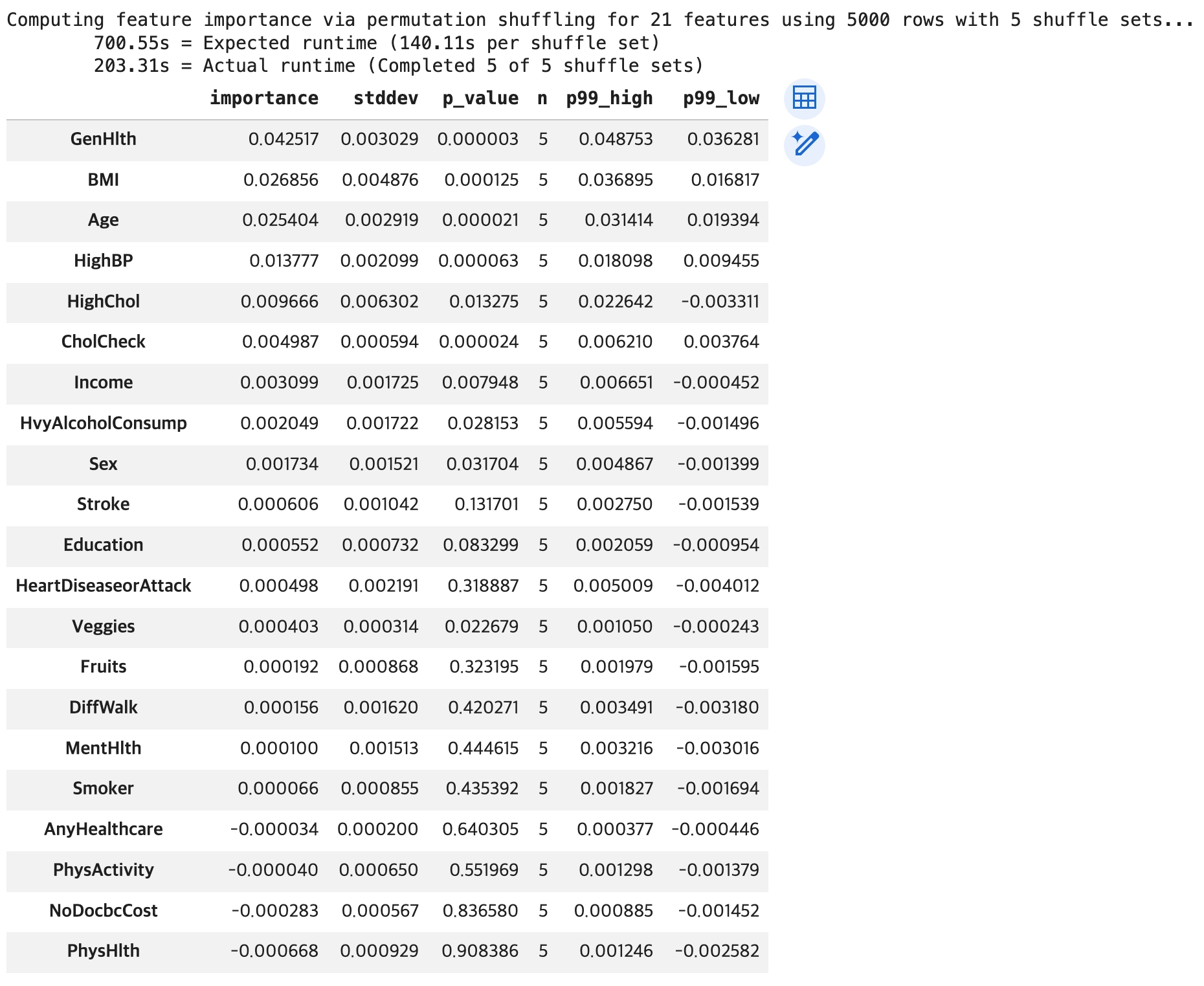
# reset_index() 함수 적용 -> 행 인덱스 -> 컬럼으로 변환
df_importance1 = df_importance.reset_index()
display(df_importance1)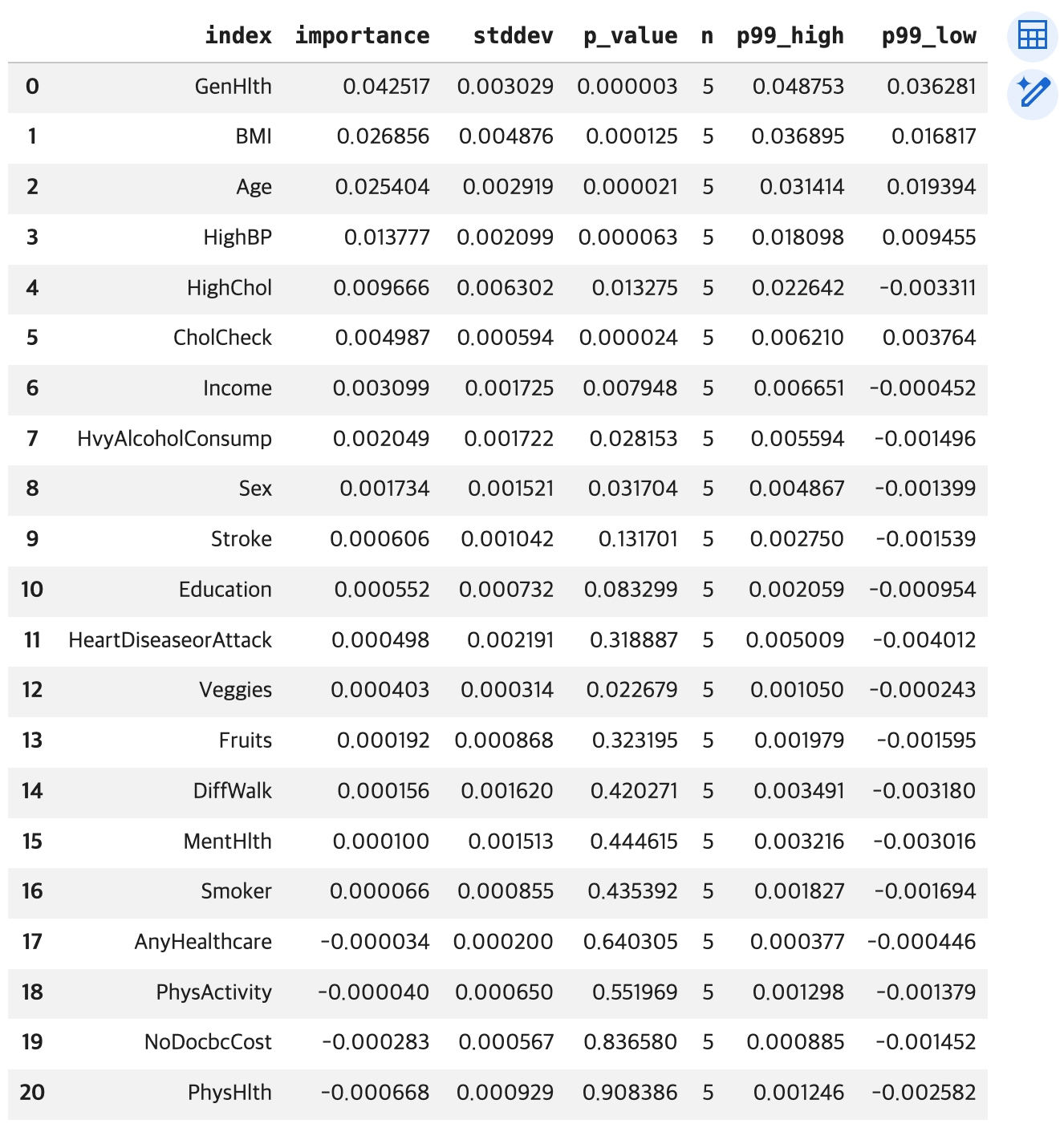
# importance 컬럼의 값 -> 오름차순 정렬 변경
df_importance2 = df_importance1.sort_values(by='importance')
display(df_importance2)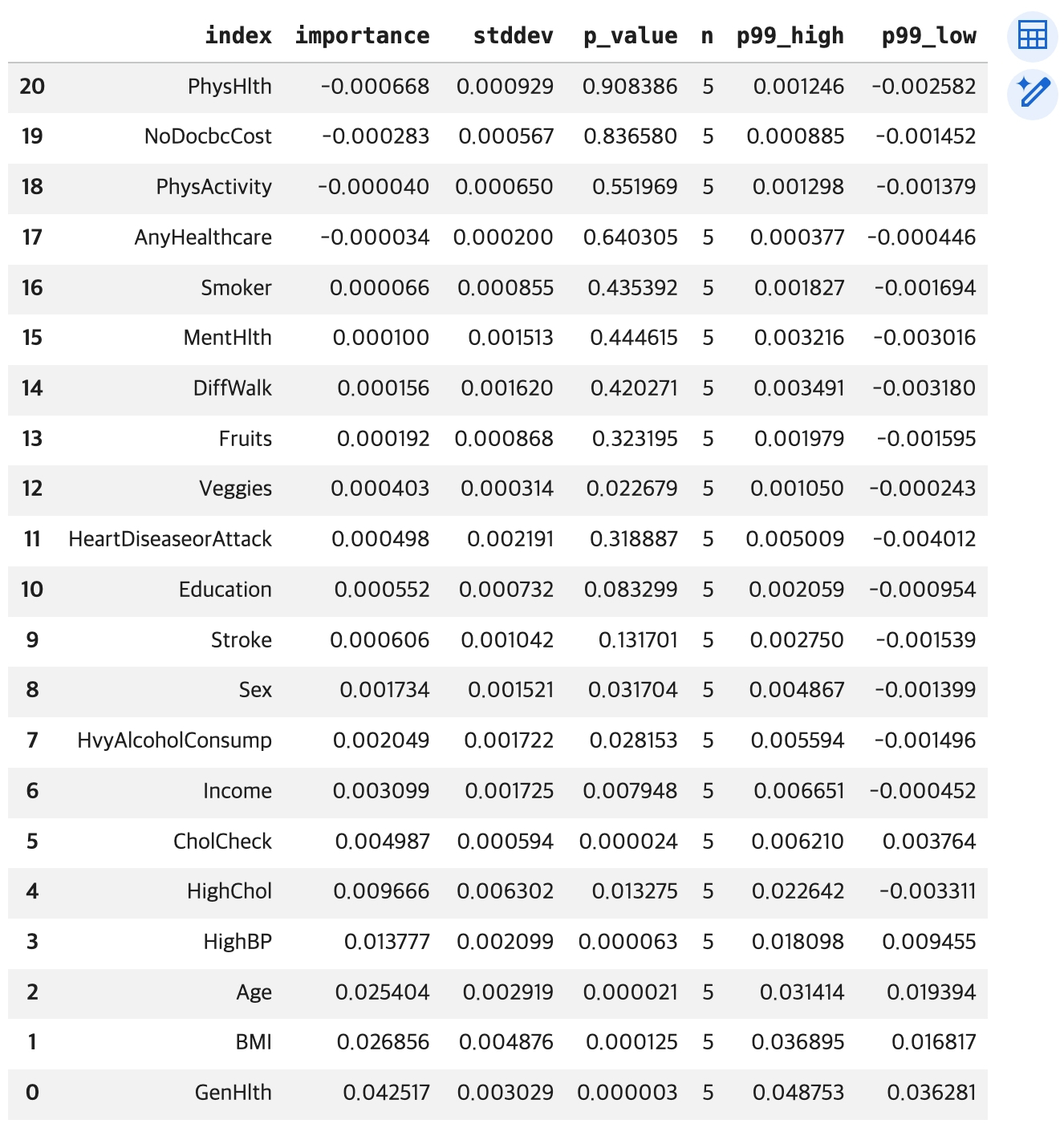
# 특성 중요도
## 필요한 모듈 임포트
import plotly.express as px
## 수평 막대그래프 생성 및 출력
fig = px.bar(
data_frame=df_importance2,
x='importance',
y='index',
orientation='h',
)
fig.show()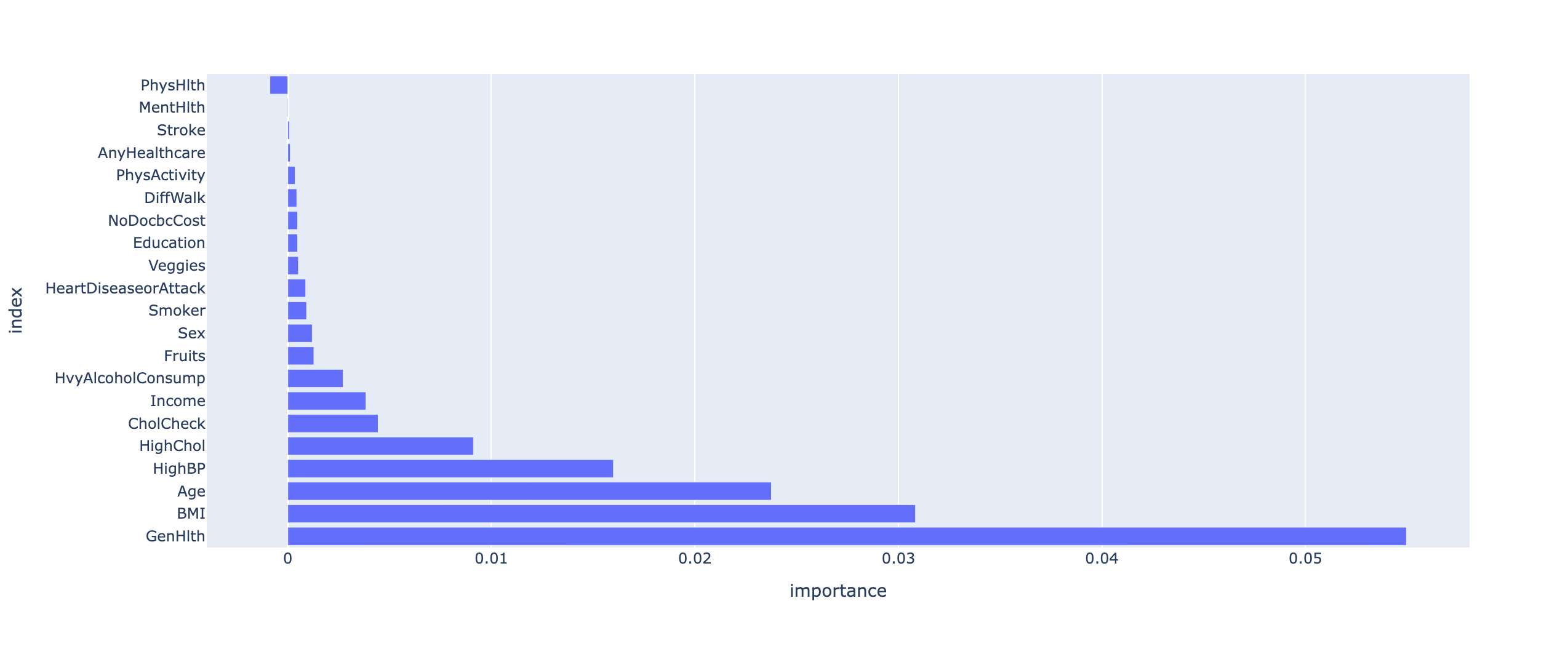
[ Confusion Matrix (혼동 행렬) ]
모델의 예측 결과와 실제 값을 비교하여, 분류 성능을 한눈에 보여주는 표
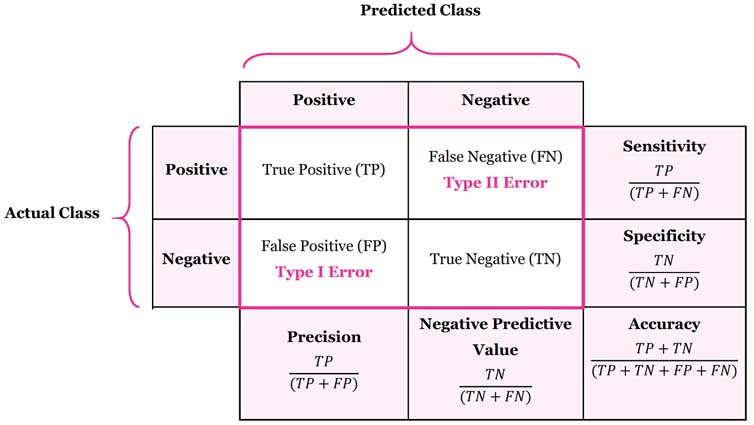
암기법
앞 = 맞/틀
뒤 = 예측 결과
[ 분류 평가 지표 ]
- 정확도 (Accuracy)
전체 데이터 중에서 올바르게 예측한 비율
→ 직관적이지만, 데이터가 불균형할 경우 한계가 있음
- 재현율 (Recall)
실제 Positive 중에서 모델이 맞게 예측한 비율
→ 놓치지 않고 찾아내는 능력
- 정밀도 (Precision)
모델이 Positive라고 예측한 것 중에서 실제로 Positive인 비율
→ 틀리게 Positive라고 예측하지 않는 능력
- F1 Score
정밀도와 재현율의 조화 평균
→ 두 지표를 균형 있게 평가할 때 사용
[ AI가 하는 스무고개, "우리 고객 중 누가 떠날까? 분석 및 예측 ]
(생략)
- 학습용과 평가용 데이터 생성
# 필요한 함수 임포트
from sklearn.model_selection import train_test_split
# 80:20으로 분할
train_df, test_df = train_test_split(df1, test_size=0.2, random_state=0, stratify=df1['Churn'])
# 결과 확인(1): 학습용 데이터의 인덱스
info_index = train_df.index
print(f'학습용 데이터의 행 인덱스: \n{info_index}')
print('-'*80)
# 결과 확인(2): 학습용 데이터의 정답 비율
train_df_ratio = train_df['Churn'].value_counts(normalize=True)
print(f'학습용 데이터의 정답 비율: \n{train_df_ratio}')(결과 생략)
- 모델 생성
# 필요한 함수 임포트
from autogluon.tabular import TabularPredictor
# TabularPredictor 함수 호출, 모델 생성
predictor = TabularPredictor(
label='Churn',
problem_type='binary',
eval_metric='f1',
path='/content/drive/MyDrive/KDT/autogluon_churn_model'
)- 모델 학습, 최적화, best 모델 생성(검증 포함)
predictor.fit(
# 학습용 데이터 입력
train_data=train_df,
# 학습 전략 설정
presets='best_quality',
# GPU 사용 설정
ag_args_fit={'num_gpus':1},
# 학습 시간
time_limit=600
)(결과 생략)
# 학습에 사용된 모델 성능 비교
leaderboard = predictor.leaderboard()
display(leaderboard)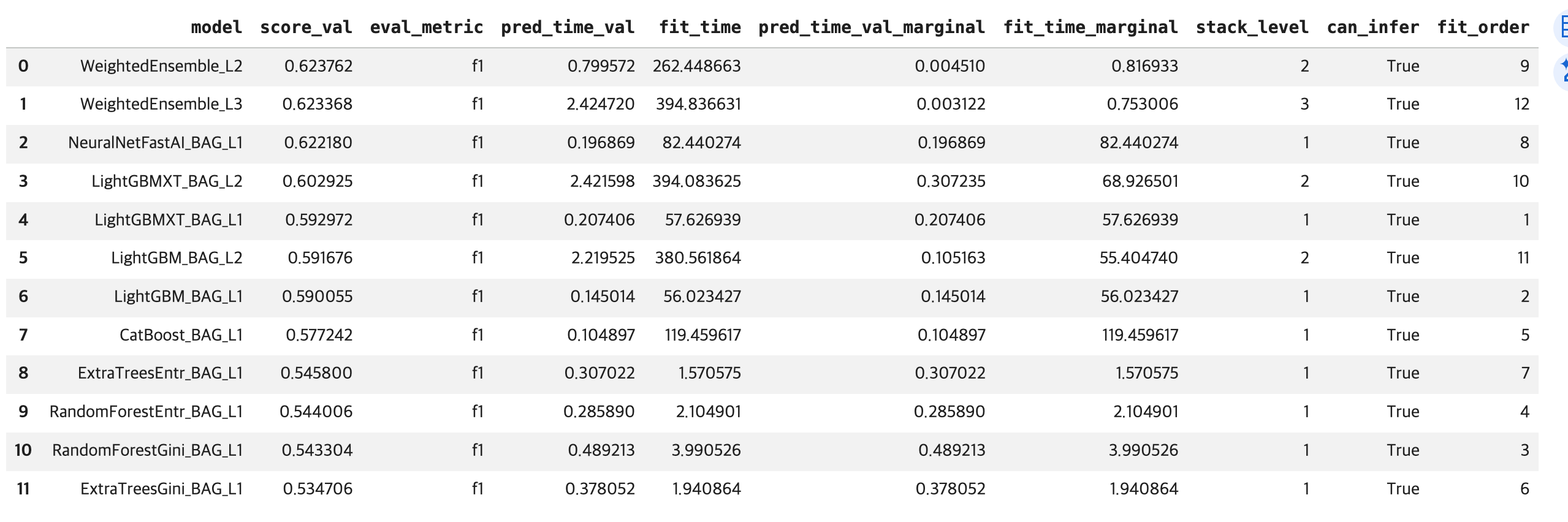
NeuralNetFastAI: AutoGluon이 딥러닝 모델까지 자동으로 활용할 수 있게 해주는 핵심 구성 요소
# best 모델: 모델들을 블렌딩(혼합 비율-> 가중치)
best_model = predictor.model_best
print(f'best 모델: {best_model}')
- best 모델의 구성 확인
# 모델 정보(info)를 통해 가중치 확인
info = predictor.info()
best_model_info = info['model_info'][best_model]
print(best_model_info)

2026.04.24. 금요일
머신러닝
- 고객 이탈 예측 마무리
- 지도 학습을 이용한 회귀
기본 개념
성능 평가 방법
회귀 트리 모델
이커머스 고객 월 예상 구매액 예측 실습
은행 정기예금 가입 예측 완료
- 저장된 모델 불러오기
# 필요한 함수 임포트
from autogluon.tabular import TabularPredictor
# load() 함수 호출, 저장된 폴더 경로 입력
path='/content/drive/MyDrive/KDT/autogluon_churn_model'
loaded_predictor = TabularPredictor.load(path)
# 불러온 모델 검증: 모델 정보(info)를 통해 가중치 확인
info = loaded_predictor.info()
best_model = loaded_predictor.model_best
best_model_info = info['model_info'][best_model]
print(best_model_info)
- 평가용 데이터를 이용한 성능 평가
# evaluate() 함수 호출: 정답이 포함된 평가용 데이터 입력, 예측과 평가를 한 번에 수행
performance = loaded_predictor.evaluate(data=test_df)
print(f'best 모델의 성능 평가: {performance}')

# predict() 함수 호출: 평가용 데이터 행 별로 이탈 여부 예측
predictions = loaded_predictor.predict(data=test_df)
print(predictions)
- 특성 중요도 분석 및 시각화
# 특성 중요도: 어떤 컬럼이 당뇨병 예측에 가장 큰 기여를 했는지 수치적으로 계산
df_importance = loaded_predictor.feature_importance(data=test_df)
display(df_importance)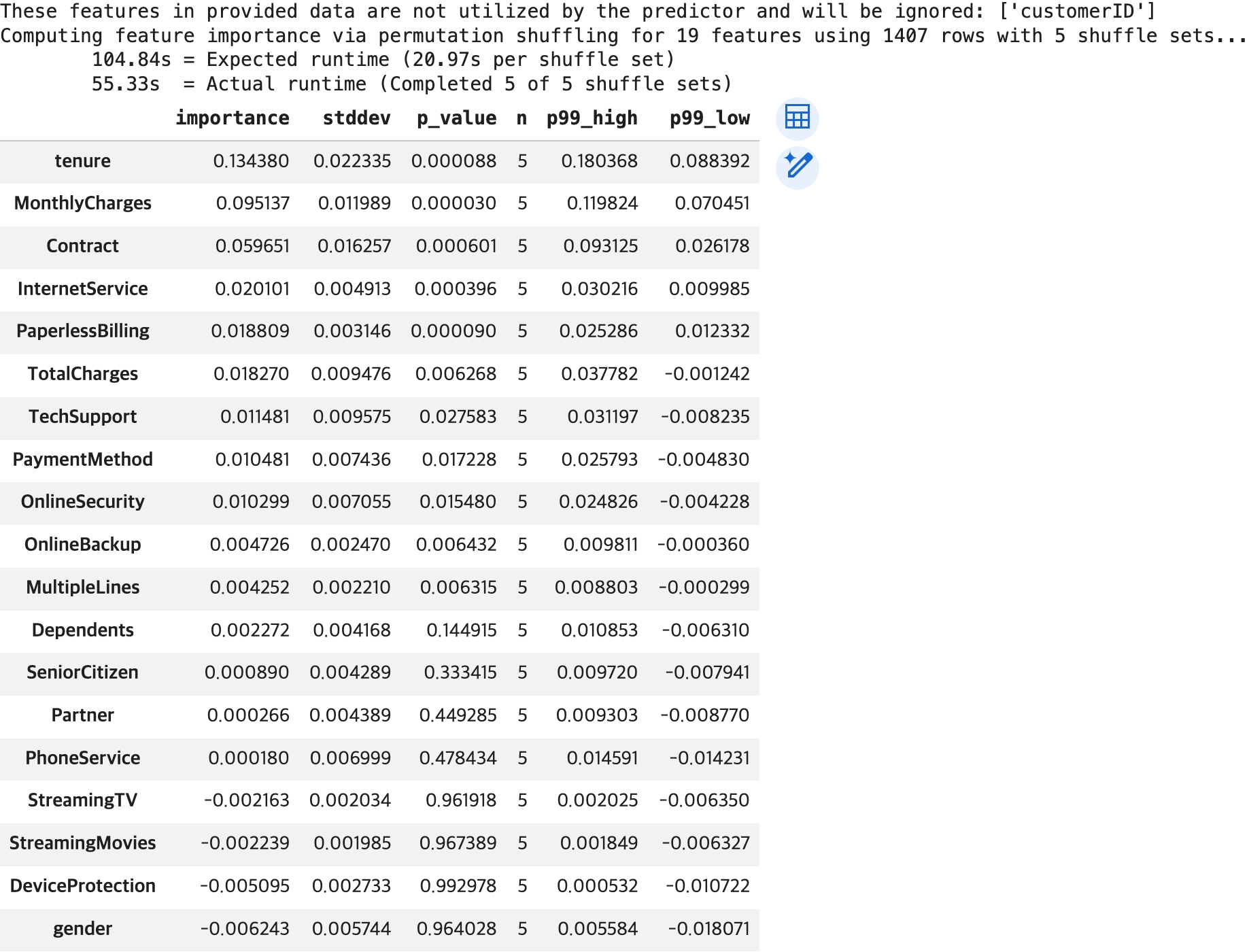
p-value: 이 feature가 실제로 중요하지 않다는 가정 하에,
현재와 같은 중요도(importance)가 우연히 관측될 확률
p-value가 작다: 우연일 가능성이 낮음 → 중요하다고 판단 가능
p-value가 크다: 우연일 가능성이 있음 → 신뢰하기 어려움
(일반적으로)
p-value < 0.05 → 유의미
p-value < 0.01 → 매우 유의미
p-value > 0.05 → 해석에 주의 필요
ex. gender: importance 음수 + p-value 큼
→ 성능에 부정적인 영향을 준 것처럼 보일 수 있으나 통계적으로 유의하지 않으므로 해당 결과는 신뢰하기 어려움
→ 따라서 중요하지 않은 feature로 해석하는 것이 적절
⇨ importance는 영향력의 크기, p-value는 그 결과의 신뢰도
# reset_index() 함수 적용 -> 행 인덱스 -> 컬럼으로 변환
df_importance1 = df_importance.reset_index()
display(df_importance1)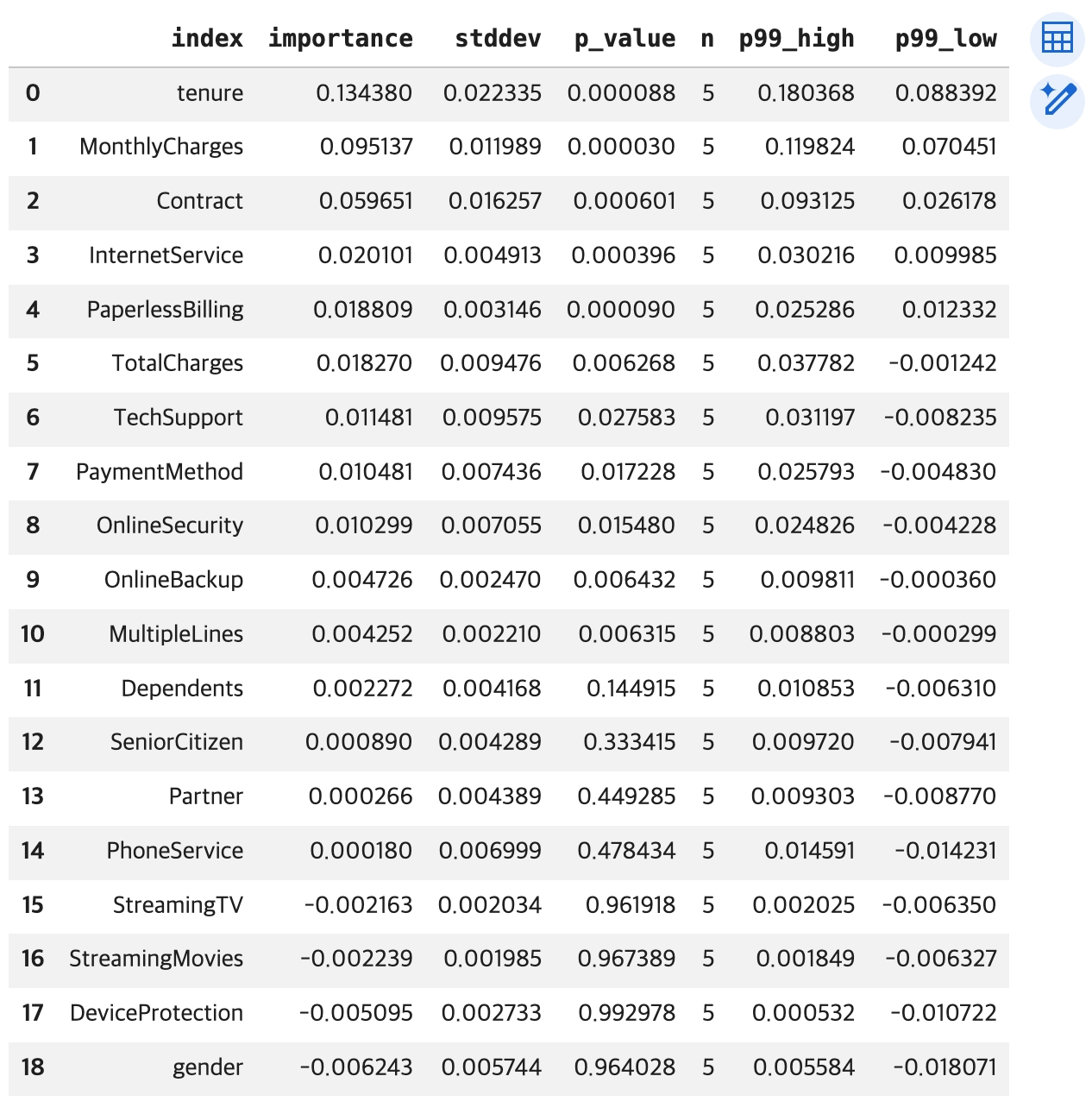
# importance 컬럼의 값 -> 오름차순 정렬 변경
df_importance2 = df_importance1.sort_values(by='importance')
display(df_importance2)(결과 생략)
# 특성 중요도
## 필요한 모듈 임포트
import plotly.express as px
## 수평 막대그래프 생성 및 출력
fig = px.bar(
data_frame=df_importance2,
x='importance',
y='index',
orientation='h',
)
fig.show()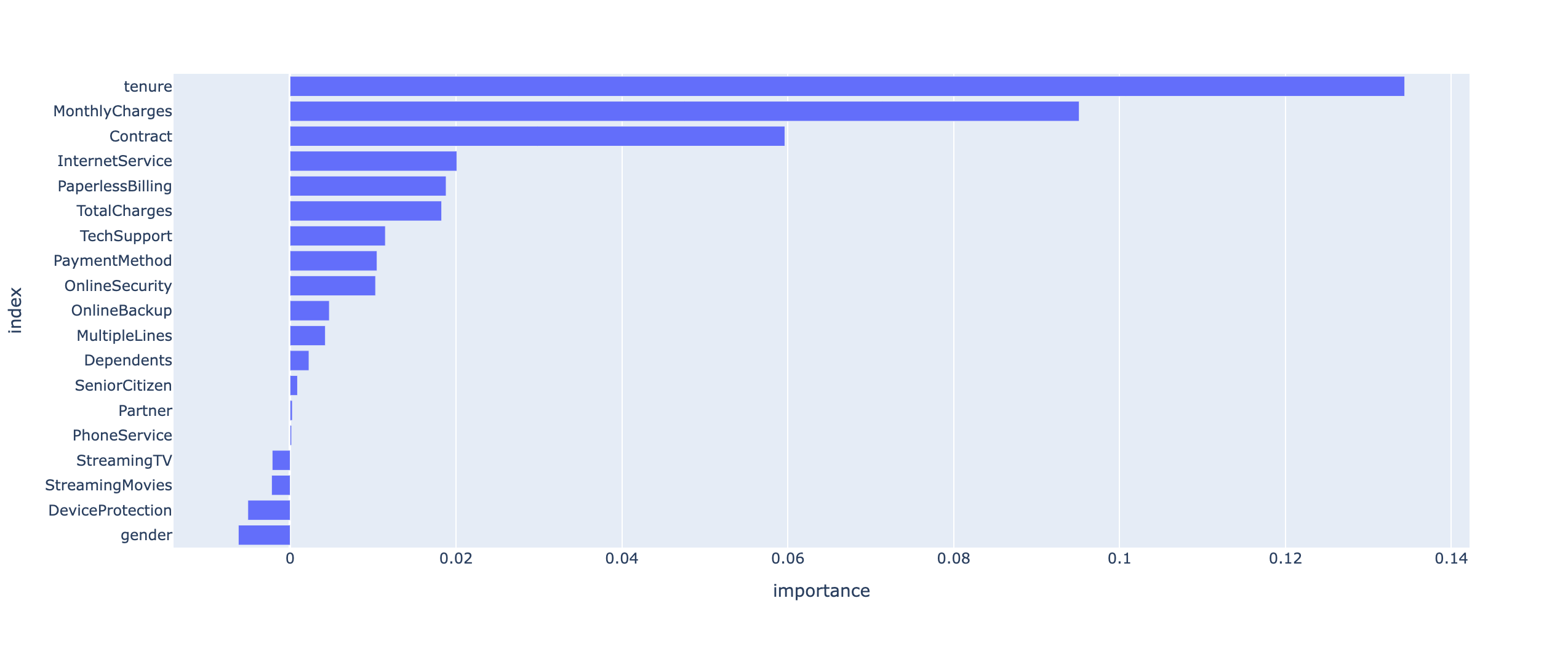
[ 선형 회귀 ]
입력 변수와 출력 사이의 관계를 직선(선형)으로 가정하는 모델
성능 평가 방법
대표적으로 오차 기반 지표 사용
① MSE (Mean Squared Error): 실제값과 예측값 차이를 제곱해서 평균
값이 작을수록 좋음
큰 오차에 더 민감
② RMSE (Root Mean Squared Error): MSE에 루트 씌운 것
단위가 원래 데이터와 같아서 해석 쉬움
값이 작을수록 좋은 모델
[ 비선형 회귀 ]
데이터 관계가 직선이 아닌 곡선 또는 복잡한 형태일 때 사용
선형 모델로 표현하기 어려운 패턴을 학습
회귀 트리 (Regression Tree)
데이터를 여러 기준으로 나눠서 구간별로 다른 값을 예측하는 모델
나이 < 30 → 평균값 A
나이 ≥ 30 → 소득 기준으로 다시 분기
→ 각 구간(리프 노드)마다 평균값을 예측값으로 사용
⇨ 비선형 회귀 특징
비선형 관계 잘 표현
해석이 직관적 (조건문 형태)
데이터 분할을 반복하면서 복잡한 패턴 학습
[ 이커머스 고객 월 예상 구매액 데이터 분석 및 예측 / AutoGluon을 이용한 월 예상 구매액 예측 및 구매 기여 핵심 요인 분석 ]
- 학습용과 평가용 데이터 생성
# 필요한 함수 임포트
from sklearn.model_selection import train_test_split
# 80:20의 비율로 분할
train_df, test_df = train_test_split(df, test_size=0.2, random_state=0)
# 결과 확인: 학습용 데이터(train_df)의 인덱스
info_index = train_df.index
print(f"학습용 데이터 인덱스: \n{info_index}")(결과 생략)
- 모델 생성
# 필요한 함수 임포트
from autogluon.tabular import TabularPredictor
# TabularPredictor 함수 호출, 모델 생성
predictor = TabularPredictor(
label='월예상구매액',
# 회귀 문제 명시
problem_type='regression',
# 평가 기준 설정
eval_metric='root_mean_squared_error',
# 학습된 모델 저장 경로 설정
path='/content/drive/MyDrive/KDT/AutoGluon_Regression'
)- 모델 학습, 최적화, best 모델 생성(검증 포함)
predictor.fit(
# 학습용 데이터 입력
train_data=train_df,
# 학습 전략 설정
presets='best_quality',
# GPU 사용 설정
ag_args_fit={'num_gpus':1},
# 학습 시간
time_limit=600
)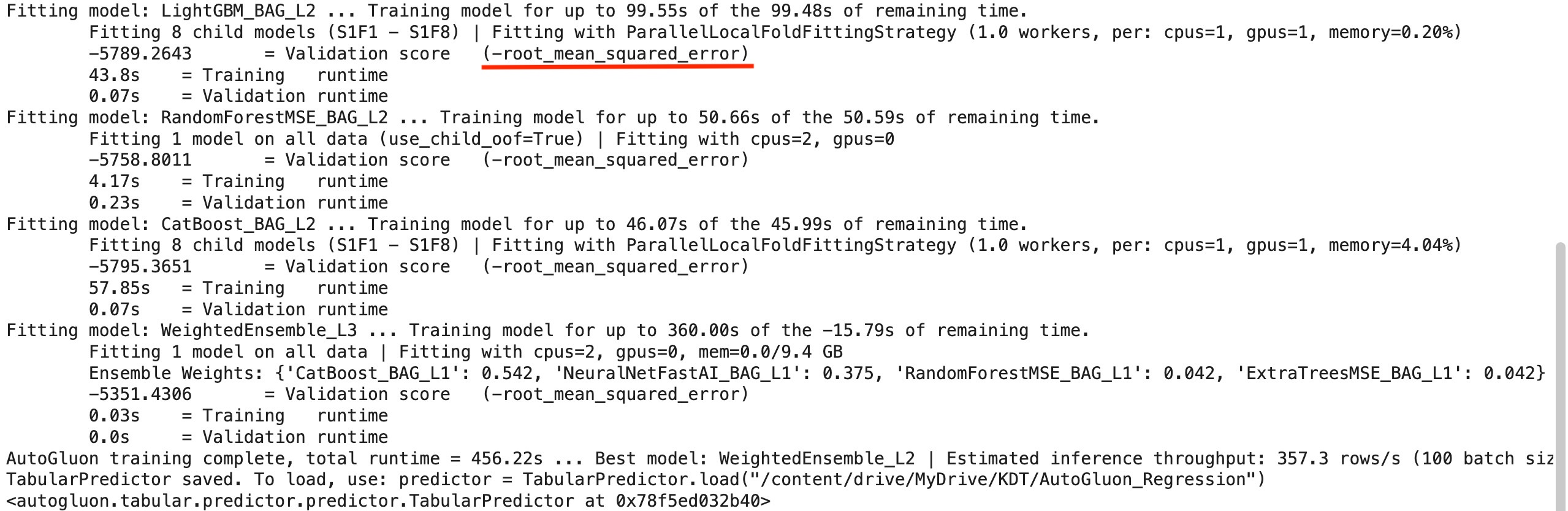
root_mean_squared_error 앞에 -가 있는 이유
AutoGluon은 모델 성능을 비교하고 최적 모델을 선택할 때 모든 평가 지표를 “값이 클수록 좋은 방향”으로 통일함
하지만 RMSE는 값이 작을수록 좋은 지표이기 때문에, 내부적으로 score = -RMSE 형태로 변환하여 최대화(maximization) 문제로 바꿈
이를 통해 서로 다른 모델 간 성능 비교, bagging 및 cross-validation 결과 집계, 그리고 weighted ensemble 최적화 과정에서 일관된 기준으로 모델을 평가할 수 있음
# 학습에 사용된 모델 성능 비교
leaderboard = predictor.leaderboard()
display(leaderboard)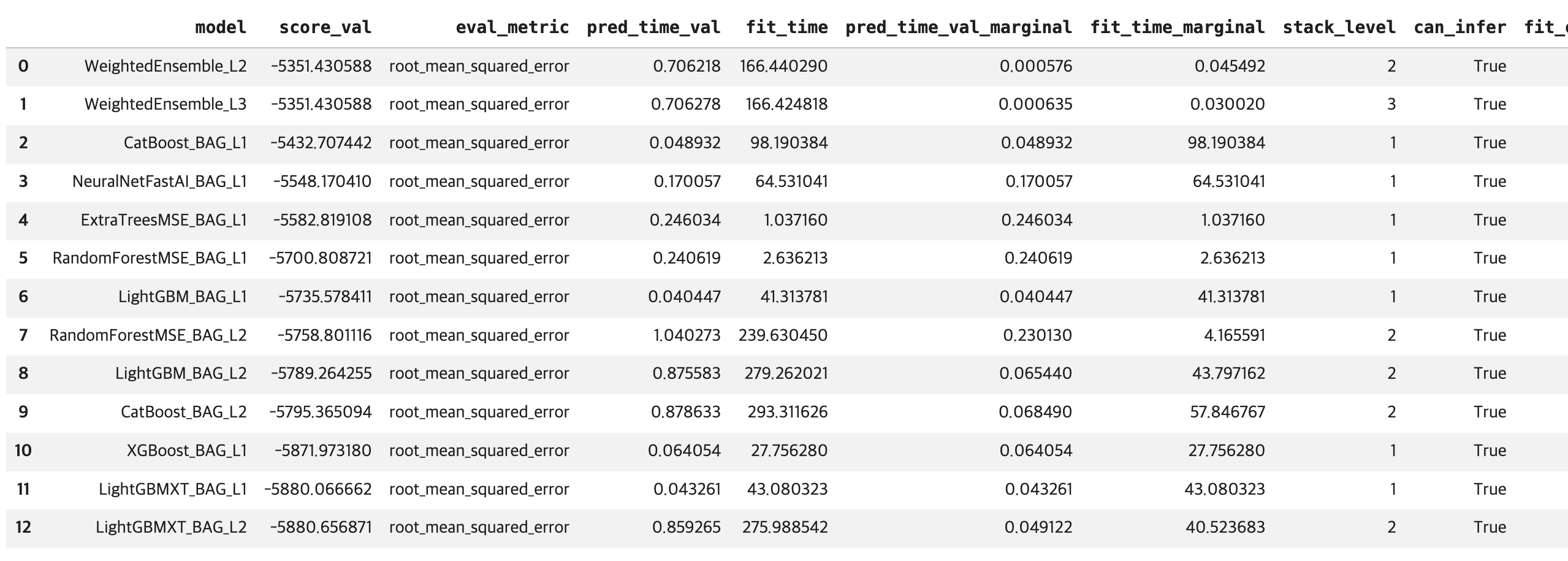
# best 모델: 모델들을 블렌딩(혼합 비율-> 가중치)
best_model = predictor.model_best
print(f'best 모델: {best_model}')
- best 모델의 구성 확인
# 모델 정보(info)를 통해 가중치 확인
info = predictor.info()
best_model_info = info['model_info'][best_model]
print(best_model_info)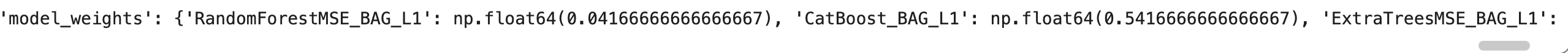

- 평가용 데이터를 이용한 성능 평가
# evaluate() 함수 호출: 정답이 포함된 평가용 데이터 입력, 예측과 평가를 한 번에 수행
performance = predictor.evaluate(data=test_df)
print(f'best 모델의 성능 평가: {performance}')
# predict() 함수 호출: 평가용 데이터 행 별로 예상 구매액 예측
predictions = predictor.predict(data=test_df)
print(predictions)

# predict() 함수 호출: 평가용 데이터 행 별로 예상 구매액 예측
predictions = predictor.predict(data=test_df)
print(predictions)(결과 생략)
- 특성 중요도 분석 및 시각화
# 특성 중요도 계산: 어떤 특성(컬럼)이 구매액 예측에 가장 큰 영향을 미쳤는지 확인
importance = predictor.feature_importance(test_df)
print('특성 중요도')
display(importance)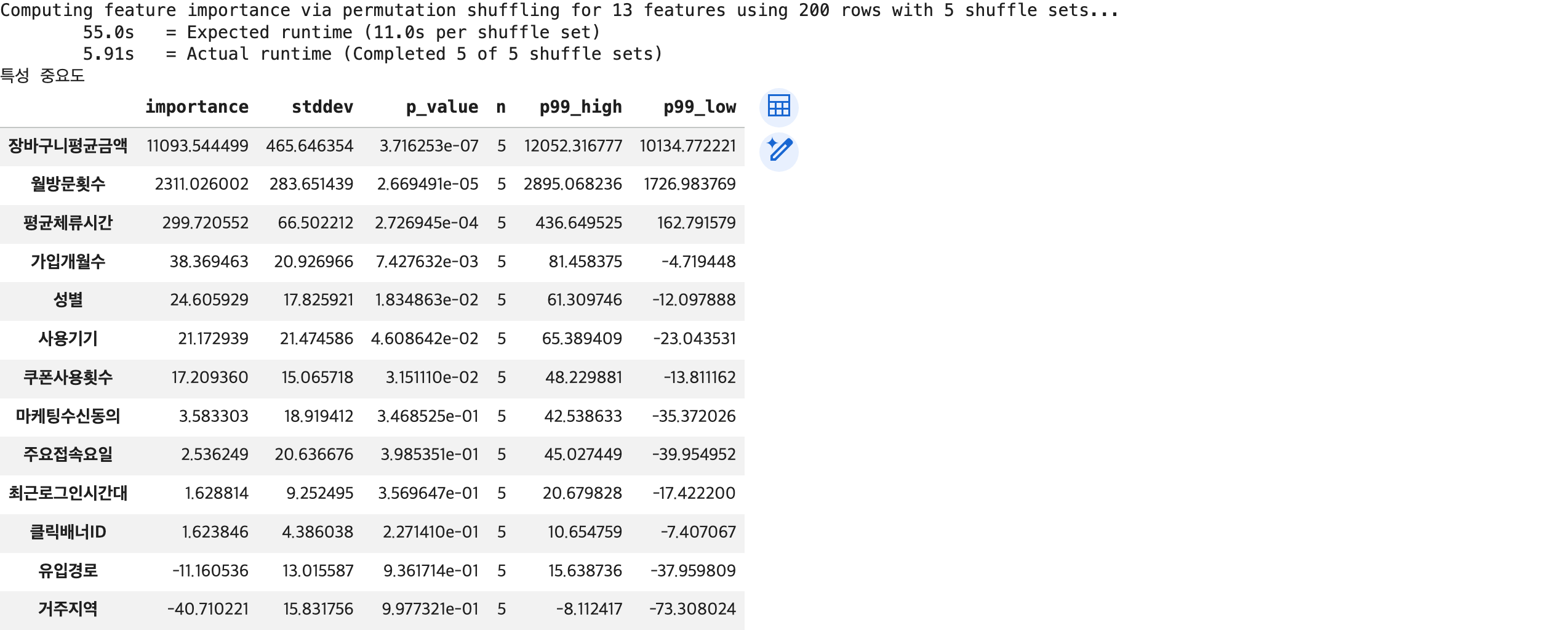
# reset_index() 함수 적용 -> 행 인덱스 -> 컬럼으로 변환
importance1 = importance.reset_index()
display(importance1)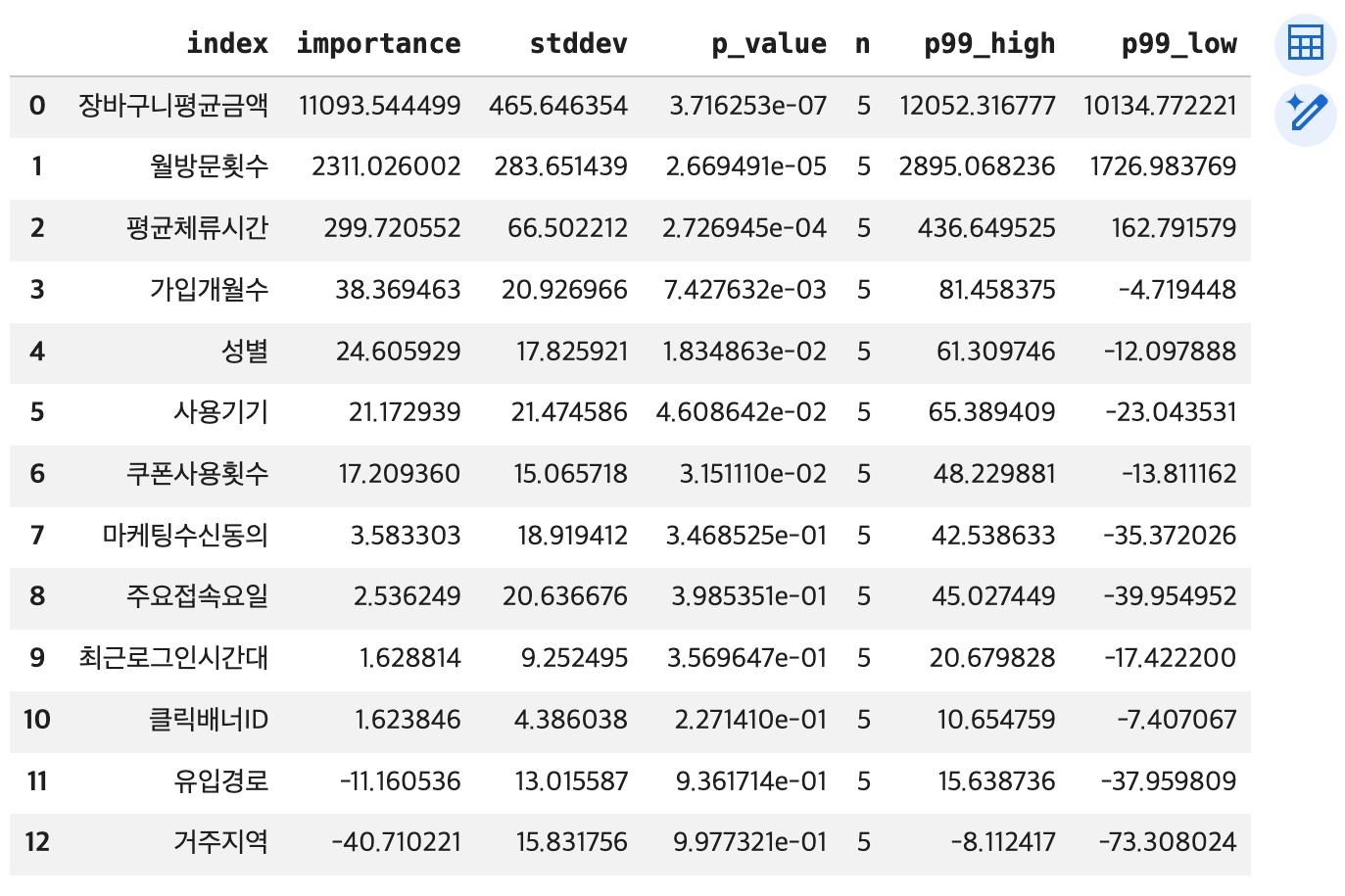
# importance 컬럼의 값 -> 오름차순 정렬 변경
importance2 = importance1.sort_values(by='importance')
display(importance2)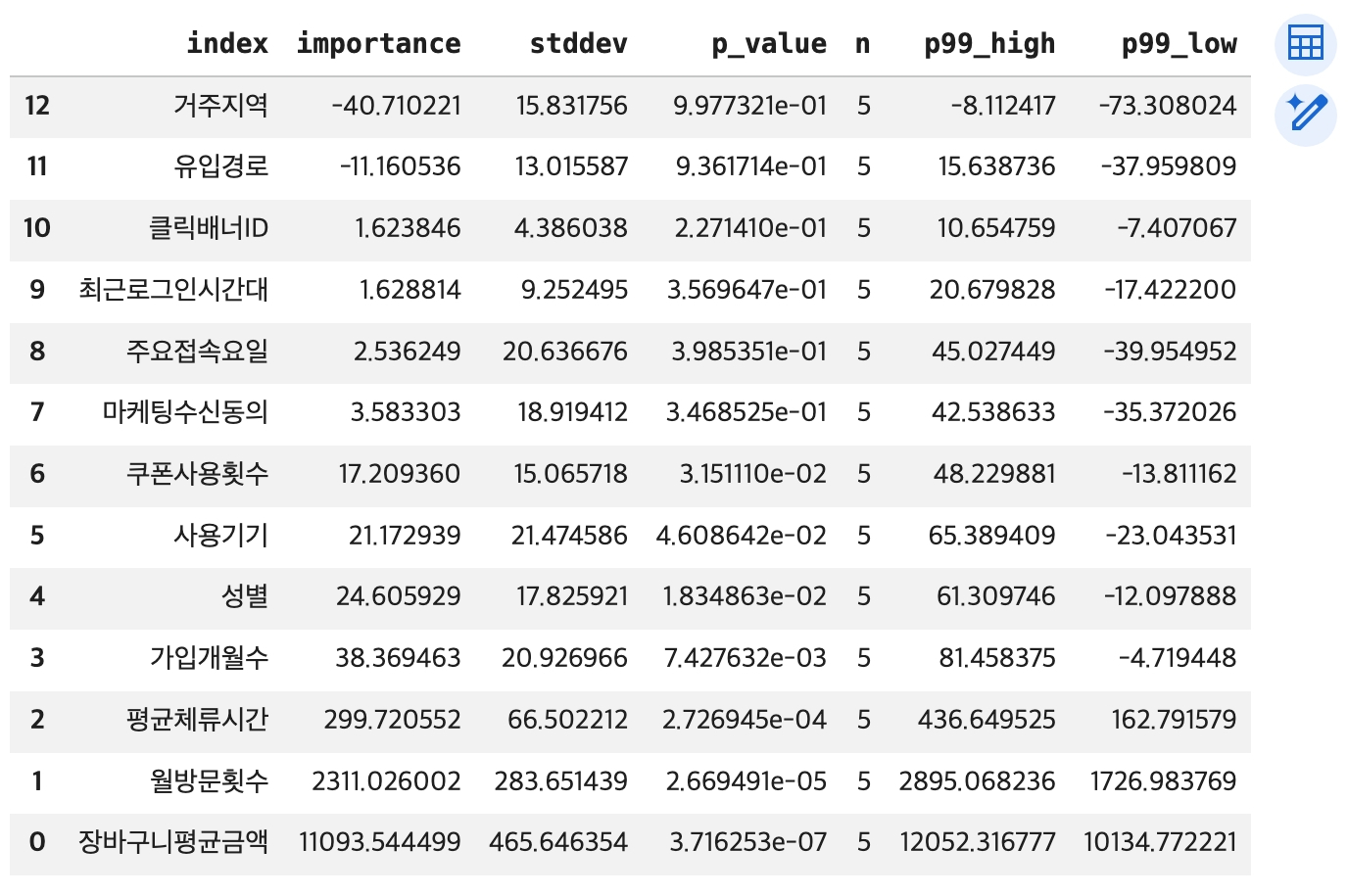
# 특성 중요도
## 필요한 모듈 임포트
import plotly.express as px
## 수평 막대그래프 생성 및 출력
fig = px.bar(
data_frame=importance2,
x='importance',
y='index',
orientation='h',
)
fig.show()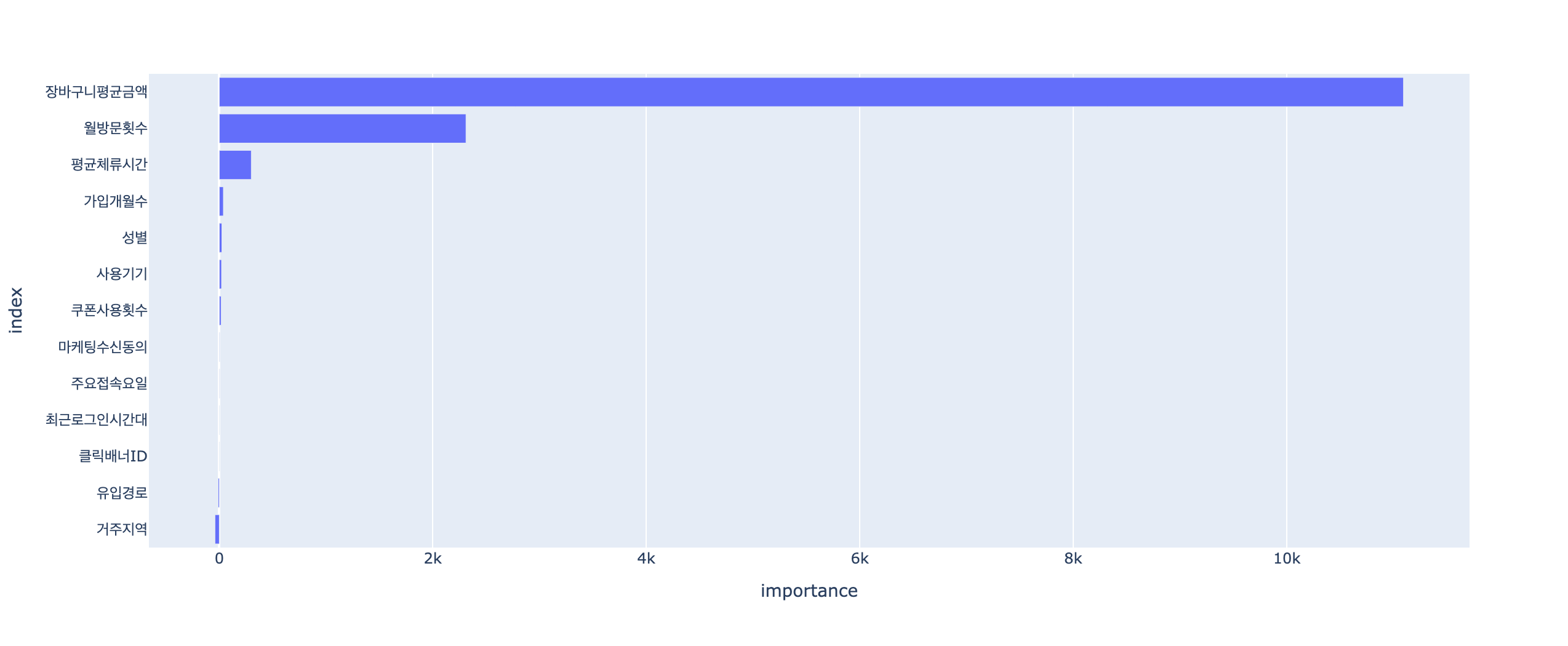
이번 주에 인공지능에 대한 이론 수업 들으니까 예전에 네이버 부스트코스에서 수업 들은 거 갑자기 생각나서.. 주말에 자료 다시 찾아봐야겠어요.. 예전에 이해 안 돼서 넘어갔는 부분 지금을 알 수도 있을 것 같아요~!!
이것도 찾아봐야 하고, 기타 줄도 교체해야 하고, 토요일에 친구들이랑 놀아야 하는데.. 이번 주 주말은 바쁘겠네요.. 😂😂

