
2026.04.27. 월요일
머신러닝
- 비지도학습
은행 정기예금 가입 예측 및 완료 및 풀이
[ 군집화 ]
비슷한 데이터끼리 자동으로 묶는 것
정답(label)이 없음 → 사람이 미리 답을 안 알려줌
데이터 자체의 패턴을 보고 그룹을 만듦
군집화 기준: 군집 내 분산 ↓ + 군집 간 분산 ↑
- 분류 vs 군집화
| 분류(Classification) | 군집화(Clustering) | |
|---|---|---|
| 정답(label) | 있음 | 없음 |
| 학습 방식 | 지도 학습 | 비지도 학습 |
| 목표 | 정해진 카테고리 예측 | 숨겨진 구조 발견 |
- 군집화 알고리즘 종류
① K-means
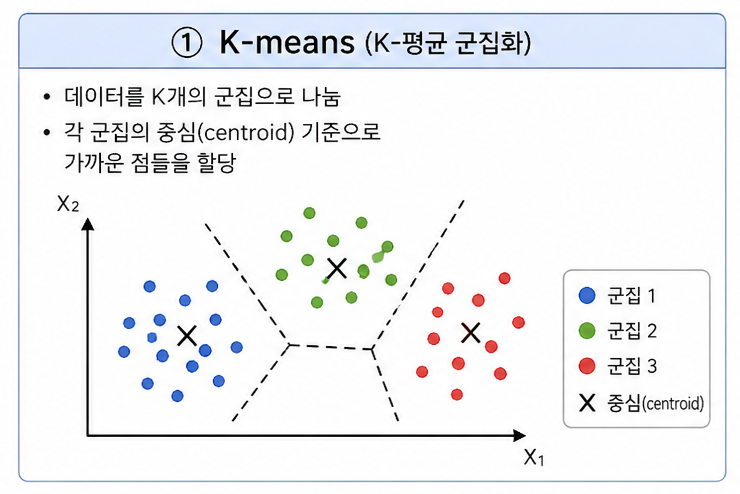
→ 거리 기반 군집화 (Centroid-based)
- 중심점(centroid)과의 거리를 기준으로 군집 형성
- 군집 내 분산 최소화가 목표
- 빠르고 간단하지만 K를 미리 정해야 함
- 이상치(outlier)에 민감
② 계층적 군집 (Hierarchical Clustering)
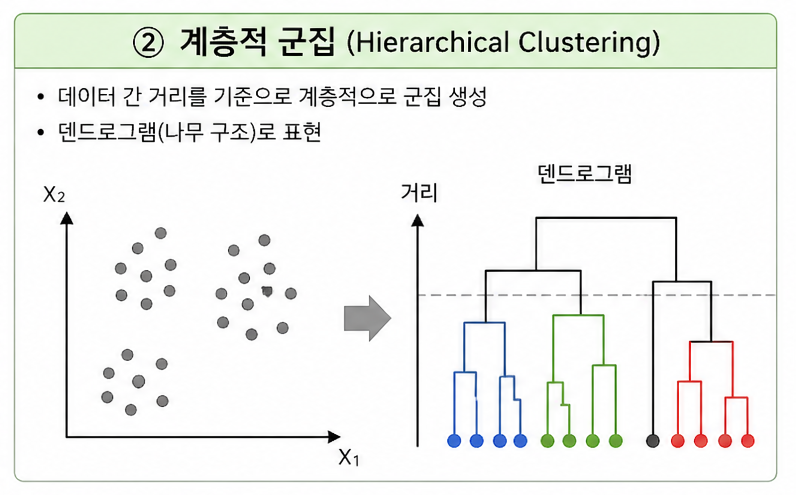
→ 계층 기반 군집화 (Tree-based)
- 데이터 간 거리를 이용해 단계적으로 군집 생성
- 덴드로그램으로 군집 구조를 시각화 가능
- K를 미리 정하지 않아도 됨
- 계산량이 커서 데이터가 많으면 느림
③ DBSCAN
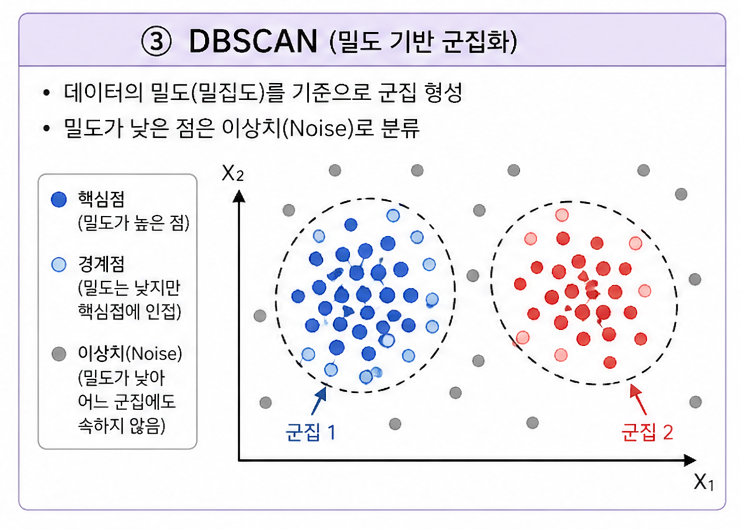
→ 밀도 기반 군집화 (Density-based)
- 밀도가 높은 영역을 하나의 군집으로 정의
- 이상치를 자동으로 noise로 분리
- 군집 개수를 미리 정할 필요 없음
- 밀도가 일정하지 않으면 성능 저하
④ GMM (Gaussian Mixture Model)
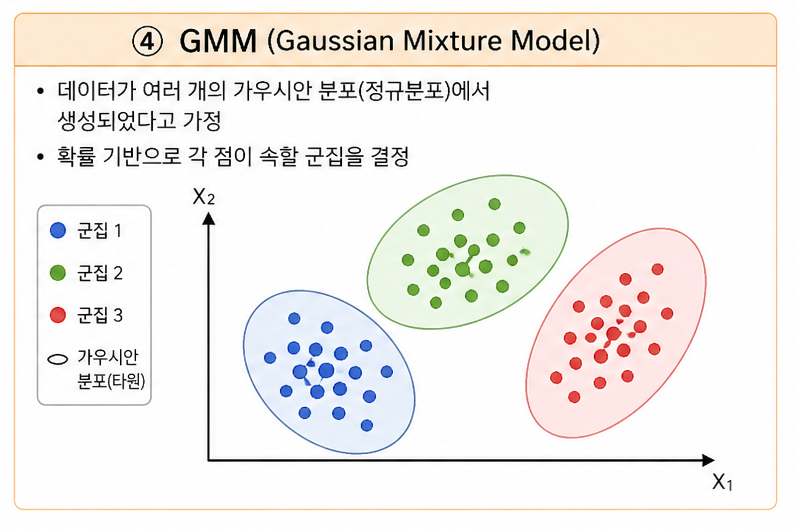
→ 확률 기반 군집화 (Probabilistic)
- 데이터가 여러 개의 정규분포에서 생성되었다고 가정
- 각 데이터가 군집에 속할 확률로 판단
- 타원형(elliptical) 군집 표현 가능
- 계산이 복잡하고 초기값에 영향 받음
- K-means 자세하게
데이터를 K개의 그룹으로 나누는 알고리즘
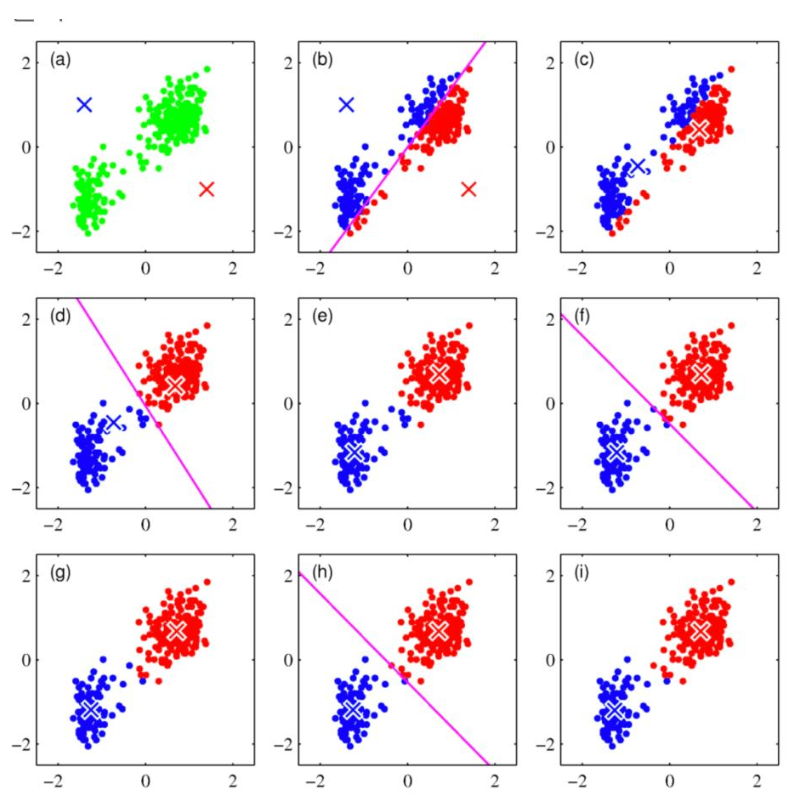
- 중심점(K개) 랜덤 선택
- 각 데이터 → 가장 가까운 중심점에 할당
- 중심점 재계산 (평균값)
- 반복 (수렴할 때까지)
목적 함수: 각 점과 중심 사이 거리 최소화
특징
구, 원 형태의 분포가 아니라면 적절하지 않음 → 전처리(표준화) 필요성
K의 개수에 따라 클러스터 성능이 많이 변함
최적의 클러스터 개수 설정: 엘보우 메소드 (Elbow Method), 실루엣 분석 (Silhouette Analysis)
엘보우 메소드 (Elbow Method)
군집 내 응집도의 효용성 측정
아이디어
K를 늘리면 당연히 군집이 더 잘 맞춰짐 → 오차 감소
근데 어느 순간부터 개선이 확 줄어드는 지점이 생김
그 지점을 선택
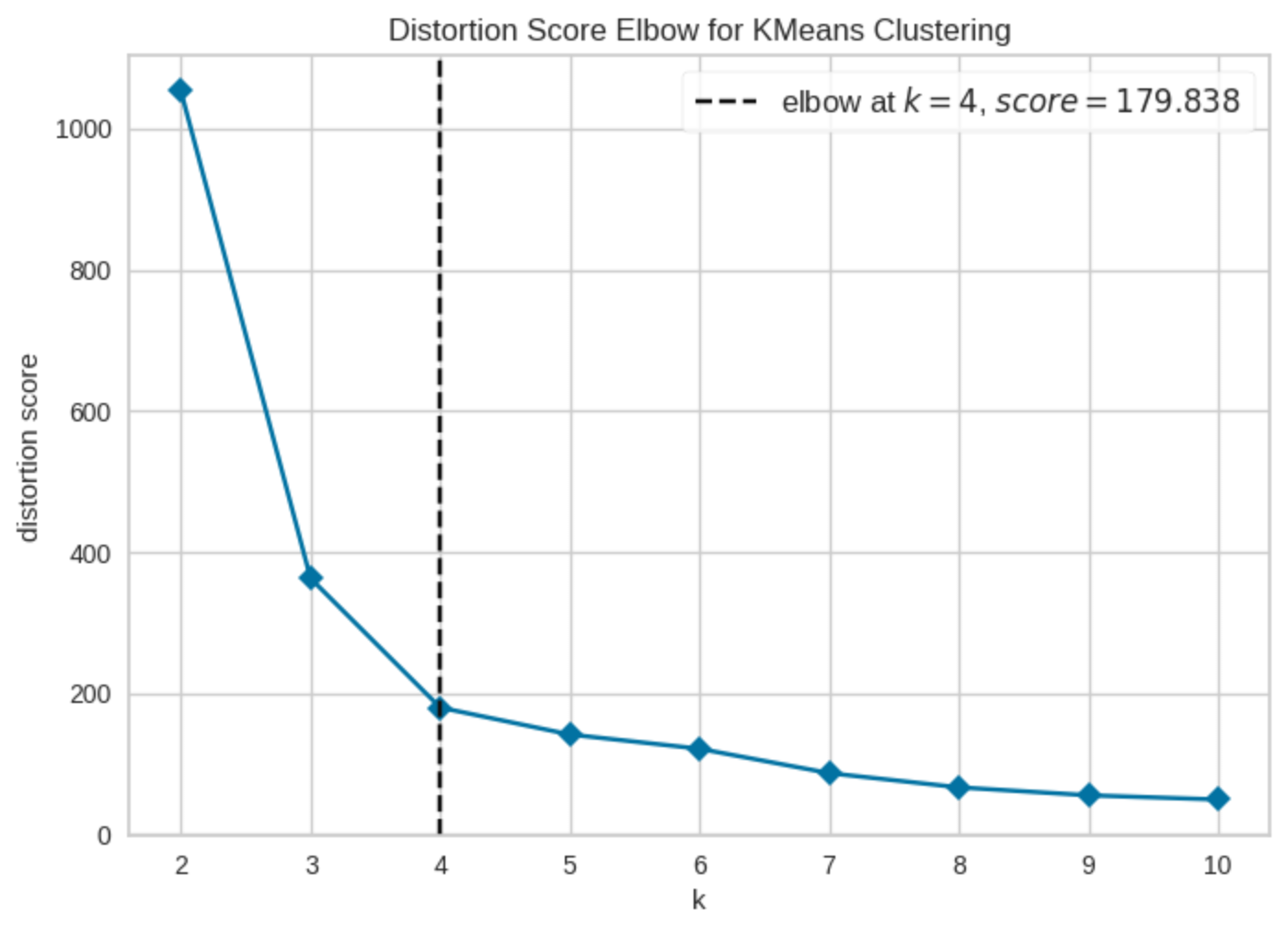
x축: K (클러스터 개수)
y축: SSE (오차)
군집 내 분산 (Inertia, SSE):
그래프가 급격히 떨어지다가 → 꺾이는 지점 (팔꿈치) → 그 K가 적절
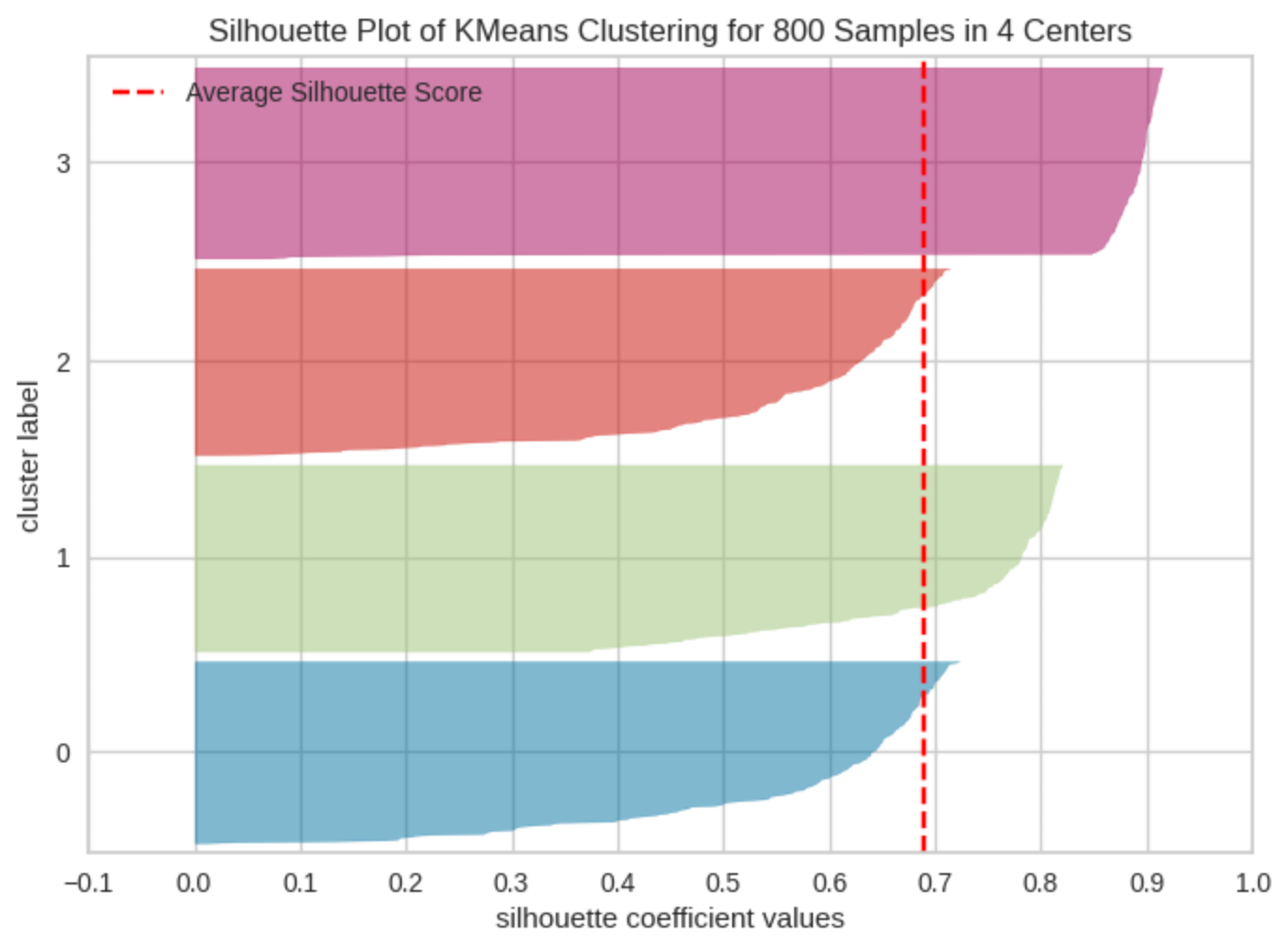
실루엣 분석 (Silhouette Analysis)
군집의 품질 평가
아이디어: 이 데이터가 자기 군집에 잘 속해 있는가?
실루엣 점수
각 데이터에 대해:
a = 같은 군집과의 평균 거리
b = 가장 가까운 다른 군집과의 거리
해석
값 범위: -1 ~ 1
| 값 | 의미 |
|---|---|
| 1에 가까움 | 군집 잘됨 |
| 0 근처 | 애매 |
| 음수 | 잘못 분류됨 |
→ 전체 평균 실루엣 점수가 가장 큰 K 선택
특징
군집 품질까지 같이 평가 가능
엘보우보다 더 신뢰도 높음
계산량은 조금 더 큼
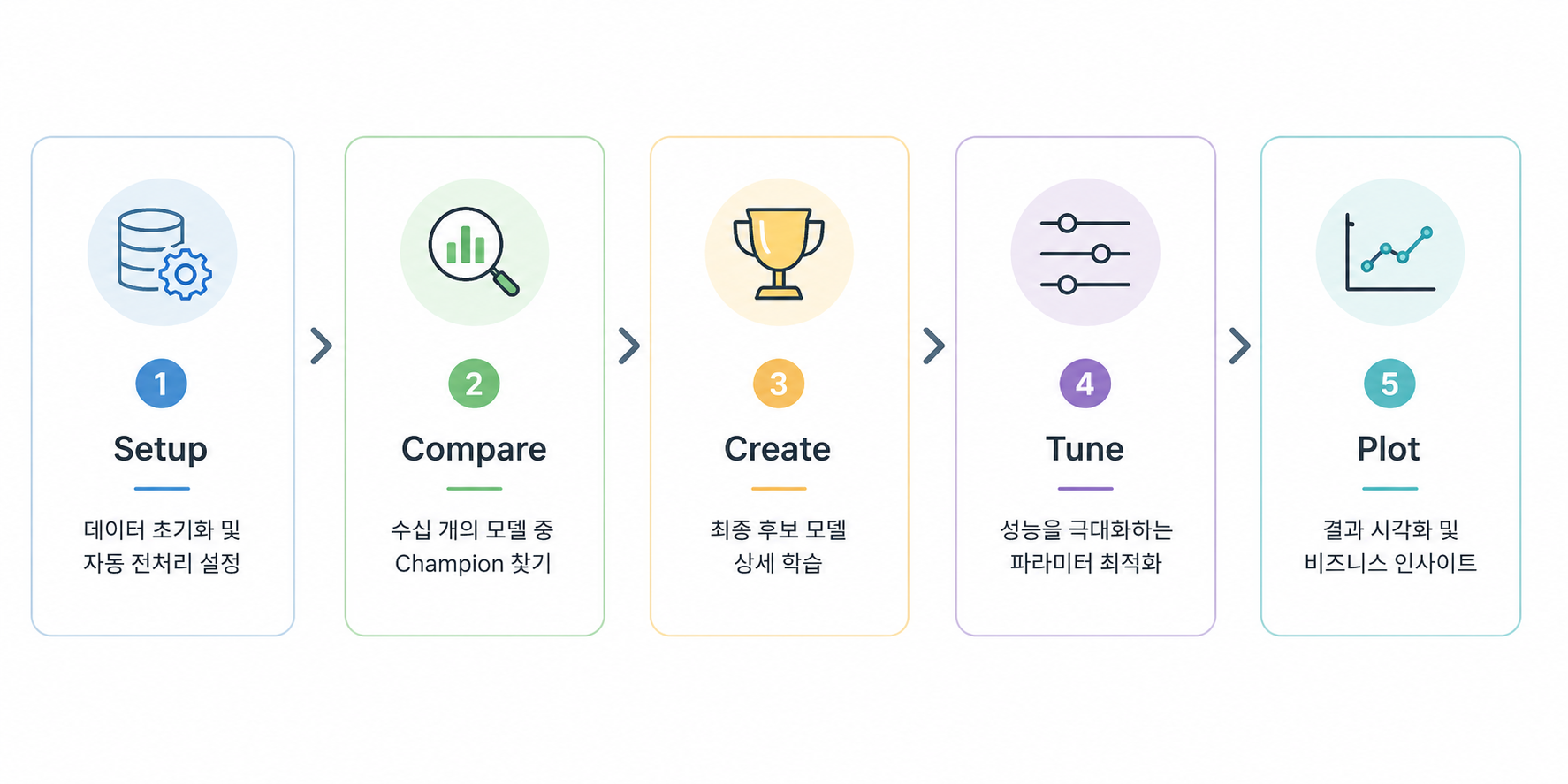
[ PyCaret ]
- PyCaret 5-Step 워크플로우
[ PyCaret을 이용한 군집화 ]
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# pycaret 설치
!pip install git+https://github.com/pycaret/pycaret.git@master --upgrade- 데이터 불러오기
# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/rfm_data.csv'
# pd.read_csv() 함수 호출, DataFrame 생성
df = pd.read_csv(file_path)
# 결과 확인
display(df)
RFM: 고객을 3가지 기준으로 나누는 방법(좋은 고객을 찾기 위한 기준 3개)
R (Recency): 얼마나 최근에 구매했는가
마지막 구매가 얼마나 최근인가
값이 작을수록 좋음
단위: 일반적으로 “일”
F (Frequency): 얼마나 자주 구매했는가
얼마나 자주 구매했는가
값이 클수록 좋음
M (Monetary): 얼마나 많이 돈을 썼는가
총 얼마를 썼는가
값이 클수록 좋음
- 환경 설정
# 필요한 함수 임포트
from pycaret.clustering import *
# setup() 함수 호출, 환경 설정
s = setup(
# 데이터 입력
data=df,
# 데이터: 표준화 적용(평균=0, 표준편차=1)
normalize=True,
# 재현성 구현(random_state 역할)
session_id=42
)
# 환경 설정에 대한 확인
print(s)⭐ normalize=True: 데이터 표준화
평균 = 0 / 표준편차 = 1
RFM은 스케일 차이 큼
Recency (수십~수백)
Monetary (수천~수십만)
안 하면? → 특정 컬럼이 군집을 지배함
⇨ 그래서 반드시 필요

- K-Means 모델 생성
# create_model() 함수 호출
model = create_model(model='kmeans')
print(model)
n_clusters 는 PyCaret 내부에서 K-means 기본 설정이 K=4로 잡혀 있음
# 최적의 군집 수 분석(1) - Elbow method 실행
## 필요한 모듈 임포트
import matplotlib.pyplot as plt
## plot_model 함수: 머신러닝 모델의 성능과 특성을 시가적으로 분석
plot_model(model=model, plot='elbow')
plt.show()
# 최적의 군집 수 분석(2) - 실루엣 분석 실행
## plot_model: 군집의 개수=4 -> 실루엣 분석 실행
plot_model(model=model, plot='silhouette')
plt.show()
# best 모델 -> 기본 값(군집의 개수=4)으로 생성된 모델
print(model)
- best 모델을 실제 데이터에 적용
# assign_model 함수 기능
"""
# best 모델을 사용하여 실제 데이터에 적용
# 군집화 결과를 데이터에 추가
# 'Cluster'라는 새로운 컬럼이 추가된 데이터프레임을 생성
"""
kmeans_results = assign_model(model=model)
display(kmeans_results)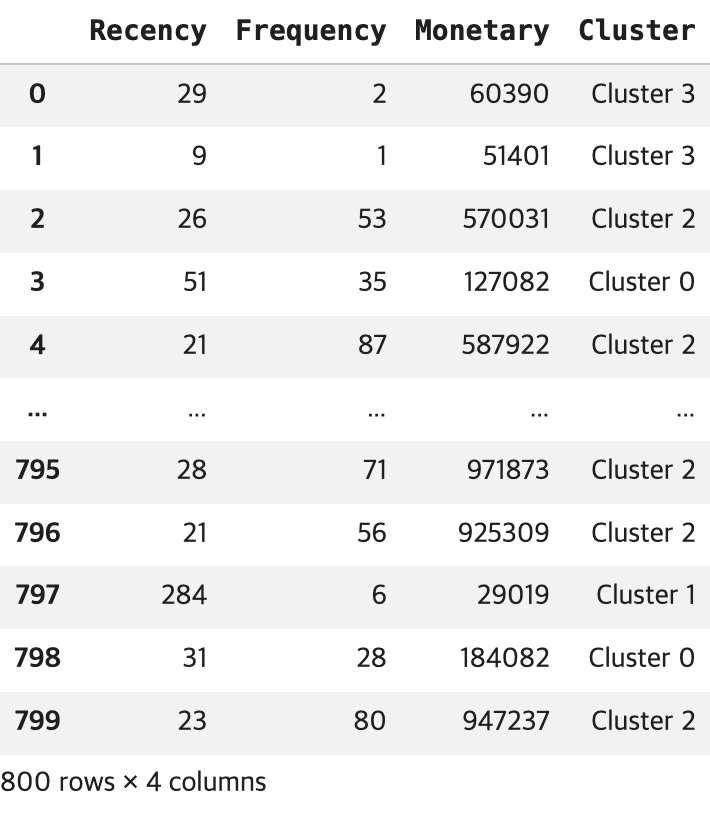
- 군집별 특성 분석
"""
# assign_model로 생성된 Cluster 컬럼을 기준으로 그룹 연산을 수행
# [VIP 고객]: Recency(최근) 낮고, Frequency/Monetary(빈도/금액) 높음
# [이탈 위험 고객]: Recency(최근) 높고, Frequency/Monetary(빈도/금액) 낮음
# [충성 고객]: RFM이 모두 준수한 중간 그룹
# [신규 고객]: Recency(최근) 낮지만, Frequency/Monetary(빈도/금액)도 낮음
"""
cluster_analysis = kmeans_results.groupby(by='Cluster').mean()
display(cluster_analysis)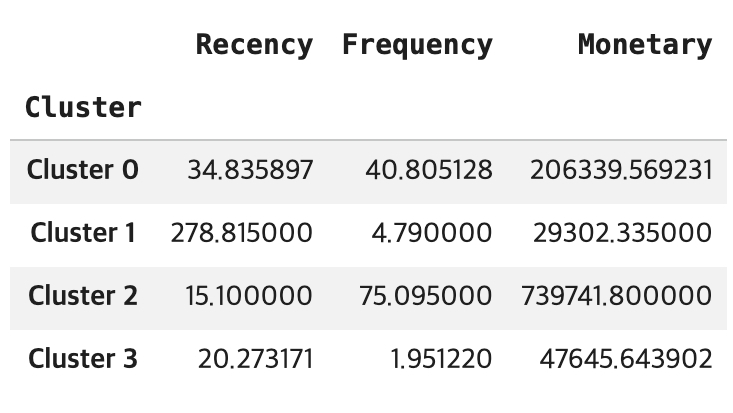
print(kmeans_results['Cluster'].value_counts())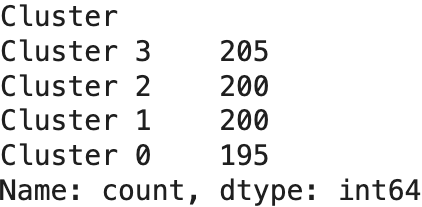
2026.04.28. 화요일
딥러닝
- 딥러닝과 머신러닝 차이점
- 인공 뉴런
- 동영상 시청
- 딥러닝의 응용 분야
- 컴퓨터 비전
온라인 쇼핑객 구매 의도 데이터 예측
머신러닝 종합문제
[ 머신러닝 vs 딥러닝 ]
- 머신러닝
데이터에서 규칙을 학습해서 예측하는 방법 / 정형 데이터에 강함
이유: 사람이 특징을 직접 만들어주기 쉬움 (예: “나이 + 소득 → 구매 가능성”)
- 딥러닝
머신러닝의 한 종류지만, 인공신경망을 이용해서 스스로 특징을 학습하는 방식 / 비정형 데이터에 강함
이유: 사람이 특징을 만들 필요가 없음, 모델이 스스로 중요한 패턴을 찾음
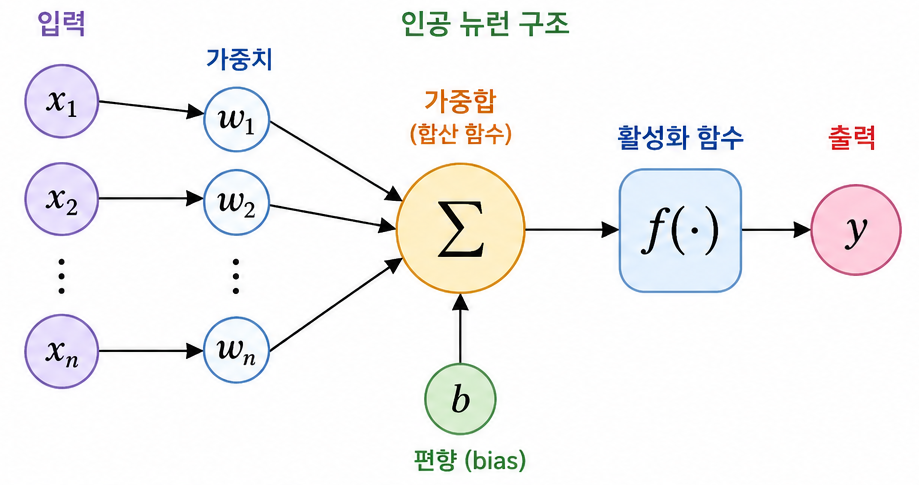
[ 인공 뉴런 (Perceptron) ]
사람의 뇌에 있는 생물학적 뉴런을 단순화해서 만든 계산 모델
즉, 여러 입력값을 받아서 계산한 뒤 하나의 출력값을 내는 가장 기본적인 인공지능 계산 단위
[ 동영상 시청 ]
[ 딥러닝의 응용 분야 ]
① 컴퓨터 비전(Computer Vision): 컴퓨터가 이미지와 영상 데이터를 분석하여 사물을 식별하는 기술 (ex. 로봇, 자율주행, 의료 진단)
② 자연어처리(Natural Language Processing): 컴퓨터가 인간의 언어를 이해하고 생성하도록 하는 기술 (ex. 감성 분석)
[ 컴퓨터 비전 ]
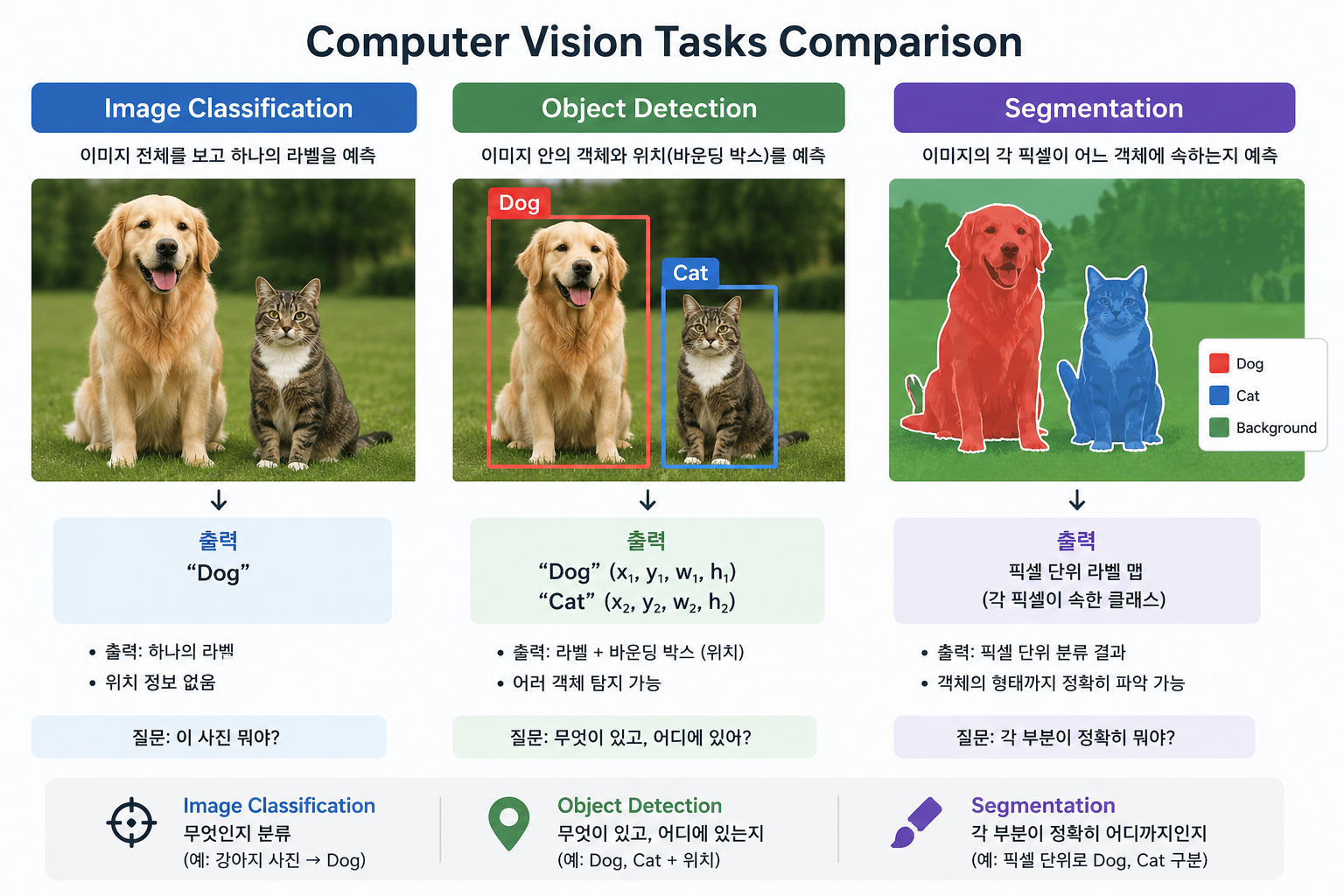
이미지나 영상 데이터를 입력으로 받아서 의미 있는 정보를 추출하고 해석하는 인공지능 분야
- Image Classification (이미지 분류)
이미지 전체를 보고 “이 이미지가 무엇인지 하나의 라벨로 분류”하는 작업
특징
출력: 하나의 클래스 (label 1개)
위치 정보 없음
“전체 이미지 기준 판단”
- Object Detection (객체 탐지)
이미지 안에 있는 여러 객체를 찾고, 각각의 위치까지 표시하는 작업
특징
출력: 클래스 + 위치 (bounding box)
여러 객체 동시에 탐지 가능
- Segmentation (세그멘테이션)
이미지를 픽셀 단위로 나눠서 각 픽셀이 어떤 객체에 속하는지 분류하는 작업
종류
Semantic Segmentation: 같은 클래스는 모두 같은 색으로 처리
Instance Segmentation: 같은 클래스라도 개별 객체 구분
특징
가장 정밀한 수준 (pixel-level)
객체의 “형태”까지 정확하게 파악
[ 이미지 ]
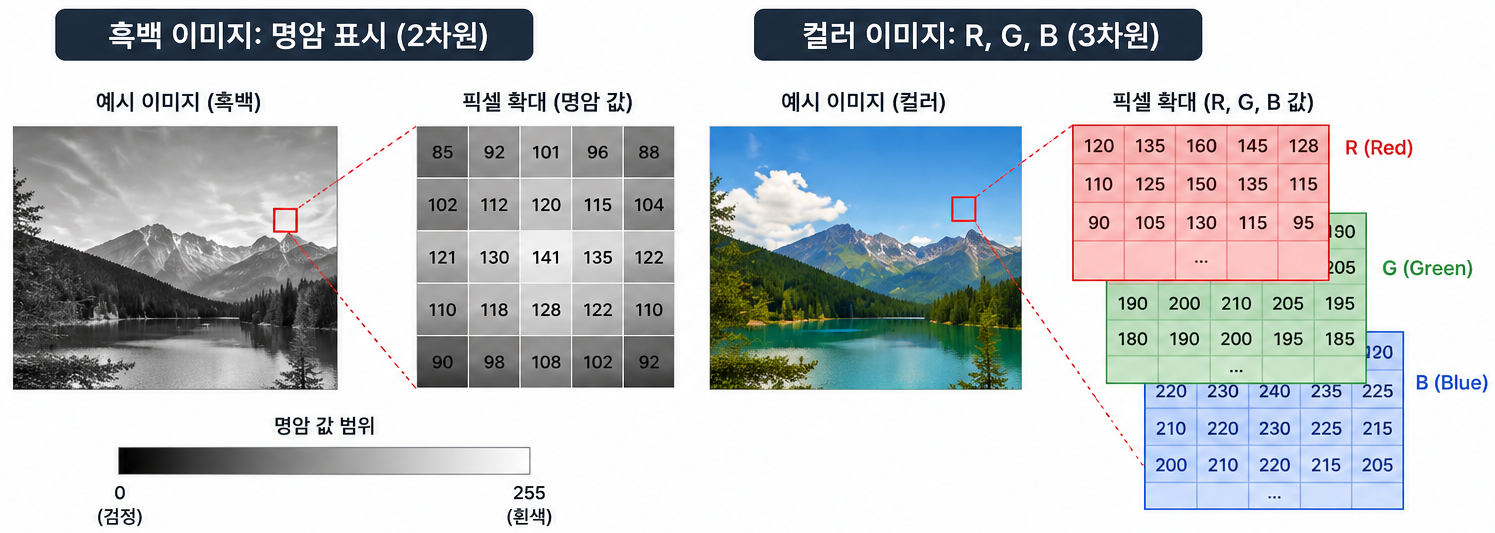
기본 단위: 픽셀, 0~255사이 숫자로 존재
흑백: 명암 표시 (2차원)
컬러: R, G, B (3차원)
[ PIL 라이브러리 ]
# 필요한 모듈 임포트
import matplotlib.pyplot as plt
from PIL import Image- 이미지 읽기 및 출력
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 이미지 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/Lenna.png'
# 이미지 읽기
img = Image.open(file_path)
print(f'Image.open 함수를 사용한 결과: \n{img}')
print('-'*80)
# 모니터에 이미지 출력(쓰기)
plt.imshow(img)
plt.show()
print('-'*80)
plt.imshow(img)
plt.show()
2026.04.29. 수요일
딥러닝: 컴퓨터 비전
- 이미지 크기 조절
- 사전 학습과 추론
- HuggingFace Pipeline 함수를 이용한 이미지 분류 실습
고객 페르소나 분석 데이터 전처리 ~ 총 지출액 예측
[ PIL 라이브러리 ]
- 이미지 크기 조절
# 원본 이미지의 크기 확인
print(f'원본 이미지의 크기: {img.size}')
plt.imshow(img)
plt.show()
print('\n')
# 이미지의 크기 확대
scale_up = img.resize(size=(1024, 1024))
scale_up.save("/content/drive/MyDrive/KDT/scale_up.png")
print("확대된 이미지 저장 완료")
plt.imshow(scale_up)
plt.show()
print('\n')
# 이미지의 크기 축소
scale_down = img.resize(size=(256, 256))
scale_down.save("/content/drive/MyDrive/KDT/scale_down.png")
print("축소된 이미지 저장 완료")
plt.imshow(scale_down)
plt.show()
[ 사전 학습과 추론 ]
- 사전 학습
모델이 대량의 데이터를 이용해서 기본적인 패턴과 지식을 배우는 단계
ex. 문장 구조, 단어 의미, 이미지 특징 등
이 과정에서 모델은 “세상을 이해하는 기본 능력”을 갖게 됨
→ 쉽게 말하면: 공부하는 단계
- 추론
이미 학습된 모델을 이용해서 새로운 입력에 대해 결과를 내는 단계
ex. 질문에 답하기, 이미지 분류하기 등
→ 쉽게 말하면: 배운 걸 써먹는 단계
[ pipeline 함수를 이용한 이미지 분류 ]
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 모듈 / 함수 임포트
from transformers import pipeline
from PIL import Image
import matplotlib.pyplot as plt
# 실습용 이미지 확인
## 파일 경로 설정
file_path1='/content/drive/MyDrive/KDT/img1.png'
file_path2='/content/drive/MyDrive/KDT/img2.png'
## 이미지 읽기
img1 = Image.open(file_path1)
img2 = Image.open(file_path2)
## 이미지 출력
plt.imshow(img1)
plt.show()
print('-'*80)
plt.imshow(img2)
plt.show()
# pipeline 함수와 사전 학습된 모델을 이용한 이미지 분류(추론: inference)
## 이미지 분류 all-in-one 모델 생성
model_name='google/vit-base-patch16-224'
model=pipeline(task='image-classification', model=model_name)
## 분류 실행 및 결과 확인
output1 = model(img1)
output2 = model(img2)
print(f'첫 번째 이미지 분류 실행의 결과: \n{output1}')
print('-'*80)
print(f'두 번째 이미지 분류 실행의 결과: \n{output2}')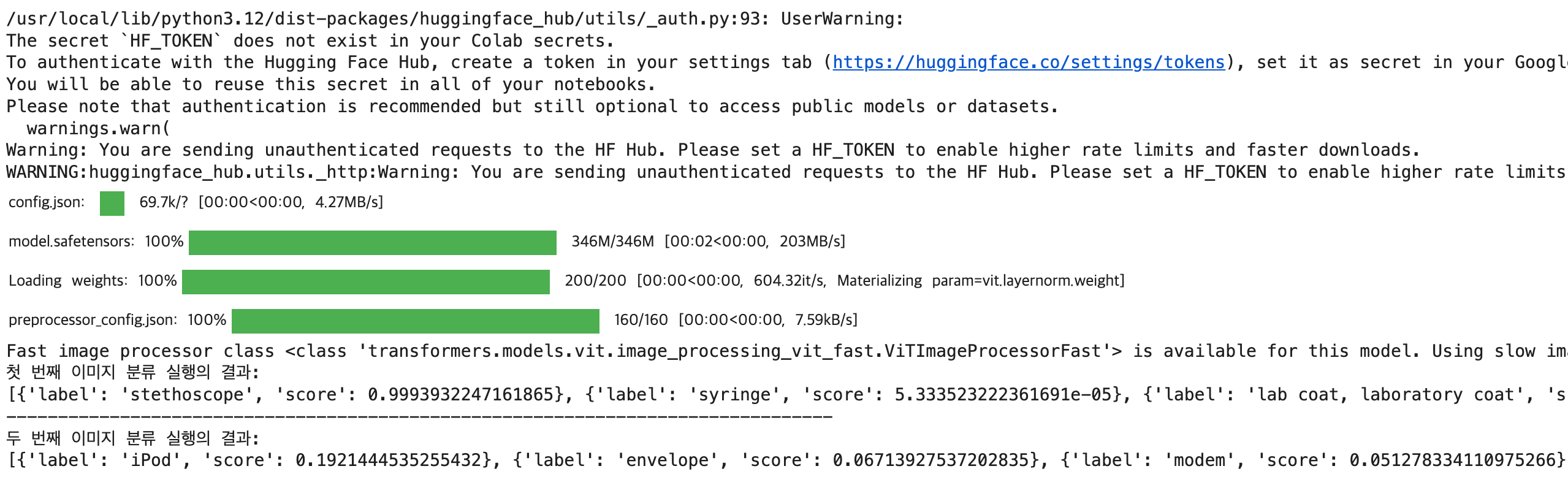
[ clip 모델: zero-shot image classification ]
# pipeline 함수를 이용, 사전 학습된 clip 모델 생성
## all-in-model 생성
model_name='openai/clip-vit-base-patch16'
model_clip=pipeline(task='zero-shot-image-classification', model=model_name)
## 이미지 파일 경로 설정
file_path1='/content/drive/MyDrive/KDT/rm.jpg'
file_path2='/content/drive/MyDrive/KDT/kimchi.jpg'
## 이미지 읽기 및 출력
img1 = Image.open(file_path1)
plt.imshow(img1)
plt.show()
print('-'*80)
img2 = Image.open(file_path2)
plt.imshow(img2)
plt.show()
# 이미지에 대한 설명글 작성 -> 사용자 작성
text1 = ["a photo of G-Dragon", "a photo of Jin", "a photo of Suga", "a photo of RM"]
text2 = ['a photo of kimchi', 'a photo of Zha Cai', 'a photo of seasoned cabbage']
# 모델의 예측 -> 어떤 설명글이 입력 이미지와 유사도가 높은지를 예측
output1 = model_clip(image=img1, candidate_labels=text1)
output2 = model_clip(image=img2, candidate_labels=text2)
# 결과 확인
print(f'첫 번째 이미지 분류 실행의 결과: \n{output1}')
print('-'*80)
print(f'두 번째 이미지 분류 실행의 결과: \n{output2}')
2026.04.30. 목요일
고객 페르소나 분석 데이터 정리
자연어 처리
- 개념
- 자연어 처리 과정
- 형태소 정리
- 영어와 한글의 불용어 차이
- 토큰화
구조화된 바이브 코딩을 이용한 고객 이탈 분석 및 예측 코드 생성 및 검증
고객 이탈 방어 전략 보고서 작성 (PPT 초안까지 작성 및 slack DM으로 제출)
[ 자연어 ]
일상 생활에서 사용하는 언어 (↔︎ 프로그래밍 언어)
ex. 한글, 영어
자연어 처리(Natural Language Processing, NLP): 인간이 일상적으로 사용하는 언어(자연어)를 컴퓨터가 이해하고, 해석하고, 생성할 수 있도록 만드는 기술 또는 학문 분야
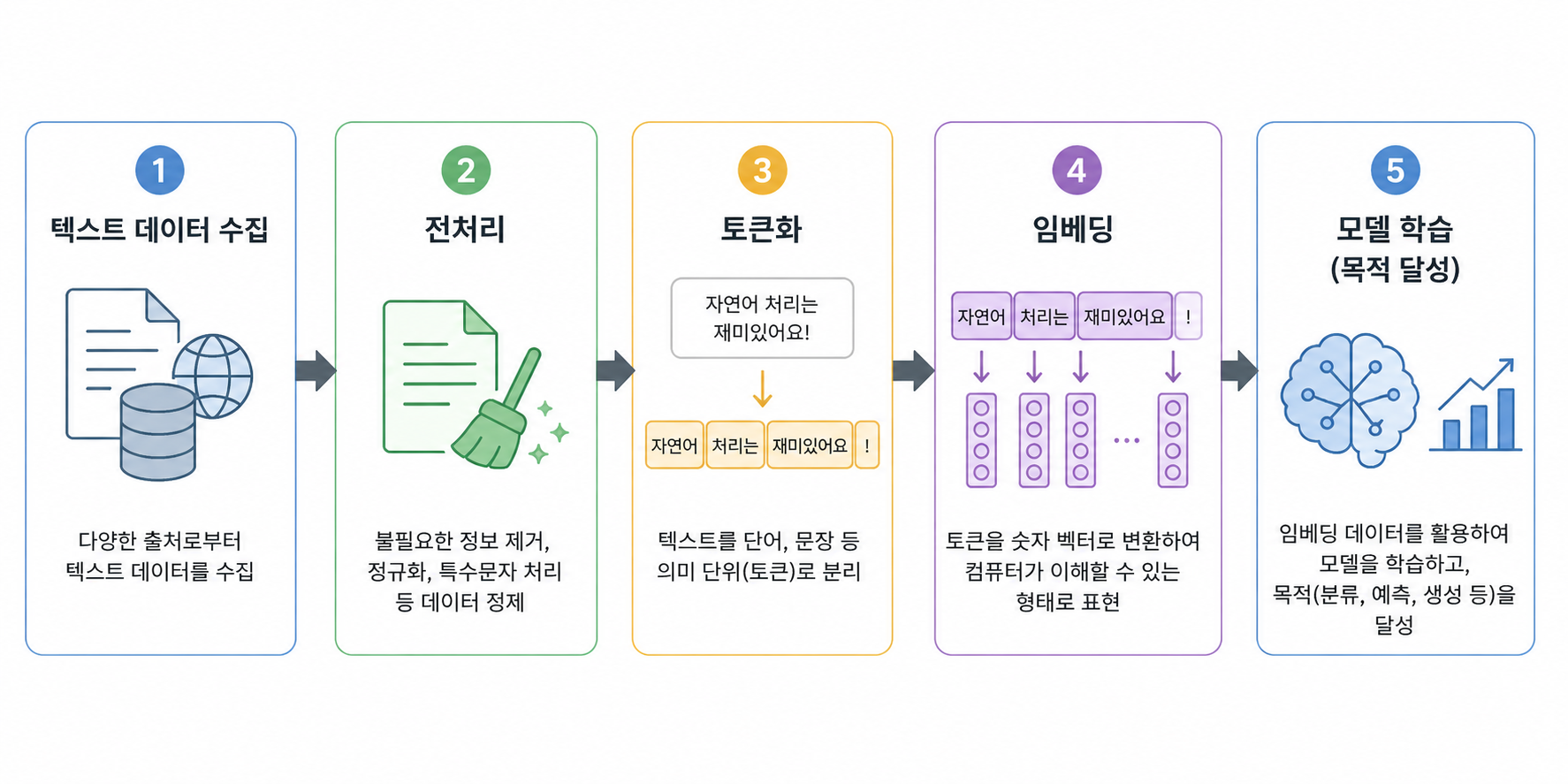
① 텍스트 데이터 수집
공공데이터, 오픈 API를 이용한 데이터 수집
크롤링을 이용한 Web 데이터 수집 (SNS/블로그, 카페 등)
② 전처리
문장부호, 특수문자 등 불필요한 요소 제거
불용어(stopwords) 제거 및 텍스트 정제
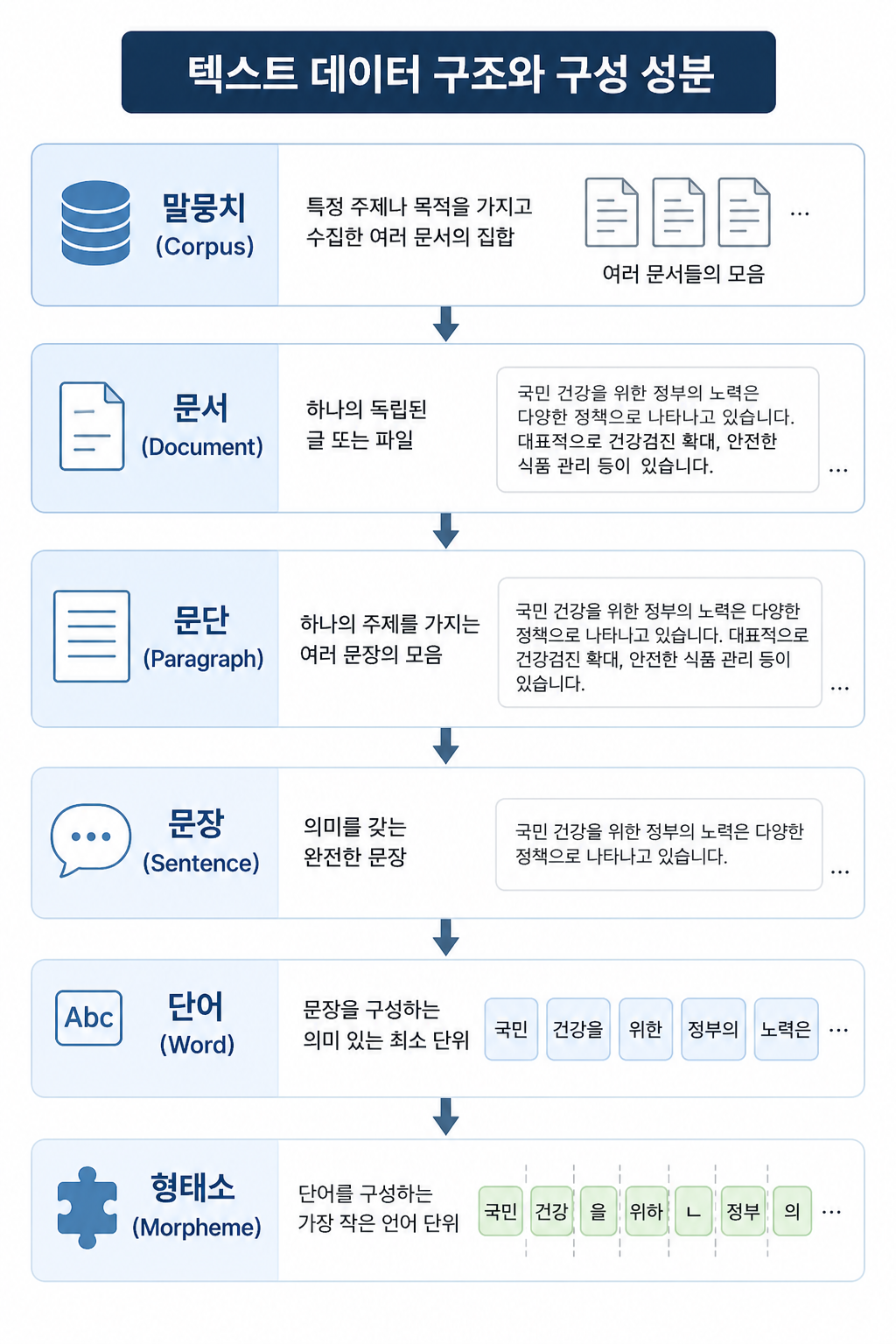
형태소
ex.
영어: Kindness = Kind(형용사) + -ness(접사), Useful = use(동사) + -ful(접사)
한글: 책가방 = 책(명사) + 가방(명사), 풋사과 = 풋(접사)- + 사과(명사)
영어와 한글의 불용어 차이
영어: 불용어 → 단어(대명사, 관사, 접속사, 조동사)
한글: 불용어 → 조사, 어미 등 형태소
③ 토큰화
텍스트를 단어, 문장 등의 단위로 분리
의미를 갖는 최소 단위(토큰)로 나누는 과정
문장 토큰호하, 단어 토큰화, 형태소 토큰화
④ 임베딩
텍스트를 숫자 벡터 형태로 변환
단어 간 의미 관계를 반영하여 표현
표현의 방식: 희소 표현, 밀집 표현
⑤ 모델 학습 (목적 달성)
임베딩된 데이터를 활용해 모델 학습
분류, 예측, 생성 등 다양한 목적 수행
[ 텍스트 토큰화 ]
# 필요한 라이브러리 임포트
import nltk
# nltk -> 추가 설치 사항, 필요한 기능을 추가로 다운로드
## 문장을 구분하기 위한 문장 부호 다운로드
nltk.download('punkt_tab')
## 불용어 다운로드
nltk.download('stopwords')
# 영어 불용어 리스트 생성
## 불용어 생성 함수 호출
stopwords_list = nltk.corpus.stopwords.words('english')
print(f'영어 불용어 리스트 : \n{stopwords_list}')
print('\n')
## 불용어 리스트의 성분 원소의 개수 확인
print(len(stopwords_list))
- 문장 단위 토큰화
# 텍스트 데이터 생성
text_ko='''산업통상자원부는 지난 2개월간 공모절차를 진행한 결과, 시스템반도체 검증지원센터의 입지로 성남 판교가 최종 선정됐다고 9일 밝혔다.
시스템반도체 검증지원센터는 제2판교 테크노벨리에 위치한 성남 글로벌 융합센터 내에 조성될 계획이다.
올해부터 2028년까지 5년간 국비 150억원, 지방비 64억5000만원 등 총 214억5000만원의 예산을 투입해 한국팹리스산업협회, 한국반도체산업협회, 성남산업진흥원, 한국전자기술연구원 등이 함께 구축한다.
센터는 중소·중견기업이 확보하기 어려운 검증용 첨단장비를 구비하고, 전문 검증인력을 채용해 반도체 검증 환경을 구축할 예정이다.
또 검증 전문 인력 및 수요 측면 전문가들이 팹리스 기업에 설계의 취약점 분석하고, 해결방안을 제시해 ‘제품의 상용화’도 지원한다.
오는 8월까지 공간을 조성하고, 올해 하반기부터 기업들에게 검증지원 서비스를 제공할 예정이다.
산업부 관계자는 “설계 프로그램(EDA), 시제품 제작 등 반도체 설계를 중점 지원하는 ‘설계지원센터’와 검증·상용화를 지원하는 ‘검증지원센터’를 연계할 예정”이라며 “반도체 칩 설계-검증-상용화 전주기에 걸친 밀착 지원으로 팹리스들의 경쟁력을 높일 수 있을 것”이라고 기대했다.'''
text_en='''I am happy to join with you today in what will go down in history as the greatest demonstration for freedom in the history of our nation.
Five score years ago, a great American, in whose symbolic shadow we stand today, signed the Emancipation Proclamation.
This momentous decree came as a great beacon light of hope to millions of Negro slaves who had been seared in the flames of withering injustice.
It came as a joyous daybreak to end the long night of their captivity.But one hundred years later, the Negro still is not free. One hundred years later, the life of the Negro is still sadly crippled by the manacles of segregation and the chains of discrimination. One hundred years later, the Negro lives on a lonely island of poverty in the midst of a vast ocean of material prosperity. One hundred years later, the Negro is still languishing in the corners of American society and finds himself an exile in his own land. So we have come here today to dramatize a shameful condition.
In a sense we have come to our nation's capital to cash a check. When the architects of our republic wrote the magnificent words of the Constitution and the Declaration of Independence, they were signing a promissory note to which every American was to fall heir. This note was a promise that all men, -yes, black men as well as white men,- would be guaranteed the unalienable rights of life, liberty, and the pursuit of happiness. '''
# 문장 단위 토큰화
## 필요한 함수 임폴트
from nltk.tokenize import sent_tokenize
## 한글 텍스트 토큰화
result1 = sent_tokenize(text_ko)
## 영어 텍스트 토큰화
result2 = sent_tokenize(text_en)
## 결과 확인
print(f'한글 텍스트 데이터를 문장 단위로 토큰화 한 결과 : \n{result1}')
print('-'*80)
print(f'영어 텍스트 데이터를 문장 단위로 토큰화 한 결과 : \n{result2}')
# 문장 단위로 토큰화 한 결과 확인
## 한글 텍스트 데이터
for sentence in result1:
print(sentence)
print('-'*80)
print('\n')
## 영어 텍스트 데이터
for sentence in result2:
print(sentence)
print('-'*80)
- 띄우쓰기 기준 토큰화(어절 단위)
# 필요한 함수 임포트
from nltk.tokenize import word_tokenize
# 한글 텍스트 -> 결과물: [어절1, 어절2, ...]
output1 = word_tokenize(text=text_ko)
# 영어 텍스트 -> 결과물: [단어1, 단어2, ...]
output2 = word_tokenize(text=text_en)
# 결과 확인
print(f'한글 텍스트 데이터를 띄어쓰기 기준으로 토큰화를 한 결과: \n{output1}')
print('-'*80)
print(f'영어 텍스트 데이터를 띄어쓰기 기준으로 토큰화를 한 결과: \n{output2}')
# 영어 텍스트 -> 불용어 제거
## 결과를 저장할 빈 리스트 생성
cleaned_words = []
## for문 + if문 사용 -> 불용어 제거
for word in output2:
if word.lower() not in stopwords_list:
cleaned_words.append(word)
## 결과 확인
print(f'불용어 제거 전 토큰화의 결과: \n{output2}')
print('-'*80)
print(f'불용어 제거 전 토큰의 수: {len(output2)}개')
print('-'*80)
print(f'불용어 제거 후 토큰화의 결과: \n{cleaned_words}')
print('-'*80)
print(f'불용어 제거 후 토큰의 수: {len(cleaned_words)}개')
[ 한글 텍스트: 형태소 단위 토큰화 ]
- mecab 형태소 분석기를 이용한 형태소 단위 토큰화
# mecab 형태소 분석기 설치 -> 터미널 사용(선택적)
# !pip install python-mecab-ko
# mecab 형태소 분석기 사용법
## 필요한 함수 임포트
from mecab import MeCab
## 형태소 분석 모델 생성
mc = MeCab()
## 기능 구현(1) -> 형태소 분석 -> 결과물: [형태소1, 형태소2, ...]
morphs_mecab = mc.morphs(sentence=text_ko)
print(f'한글 텍스트 데이터를 mecab 형태소 분석기로 형태소 분석을 한 결과: \n{morphs_mecab}')
[ 고객이탈 분석_0430_MyVer ]
AI에게 코드 작성 요청과 보고서 작성 요청을 위해 만든 가이드라인 (프롬프트에 사용)
1. 분석 배경
(1) 목적: 고객 이탈(Churn) 데이터를 기반으로 이탈률의 전반적인 수준을 파악하고, 결제 방식(Payment Method) 및 고객 연령대(Senior 여부)에 따른 이탈 패턴을 분석한다.
특히 단일 변수 분석을 넘어, 결제 방식과 연령대의 교차 분석을 통해 고위험 고객 세그먼트를 도출하고, 이를 바탕으로 데이터 기반 리텐션(고객 유지) 캠페인 전략 수립의 근거를 마련하는 것을 목적으로 한다.
(2) 도구: Google Colab, Python (pandas, plotly).
2. 데이터 처리 요구사항
(1) 데이터 정제:
TotalCharges 컬럼의 공백(문자열) 값을 결측치로 변환 후 제거 또는 적절히 처리
TotalCharges 컬럼을 숫자형(float)으로 변환
Churn 컬럼을 Yes/No → 1/0 형태로 변환하여 분석에 활용
범주형 변수(PaymentMethod, SeniorCitizen)의 값을 분석에 용이하도록 정리 (SeniorCitizen: 0 → 일반 고객, 1 → 시니어 고객)
분석에 불필요한 컬럼(customerID)은 제거
(2) 지표 계산:
전체 고객 대비 이탈률(Churn Rate) 계산
결제 방식(Payment Method)별 이탈률 계산
시니어 여부(SeniorCitizen)별 이탈률 계산
결제 방식 × 시니어 여부 교차 그룹별 이탈률 계산 (예: 시니어 + Electronic check, 일반 + 자동이체 등)
각 그룹별 고객 수 대비 이탈 고객 비율을 기준으로 비교 분석 수행
3. 시각화 요구사항 (Plotly 활용)
전체 이탈률을 직관적으로 보여주는 Bar Chart 또는 Indicator Chart 구성
결제 방식별 이탈률 비교를 위한 Bar Chart 시각화
시니어 여부에 따른 이탈률 비교 Bar Chart 시각화
결제 방식 × 시니어 여부 교차 분석 결과를 Grouped Bar Chart 또는 Heatmap 형태로 시각화
Plotly의 hover 기능을 활용하여 고객 수, 이탈률 등의 세부 수치를 인터랙티브하게 확인 가능하도록 구성
색상 대비를 통해 이탈률이 높은 그룹이 직관적으로 드러나도록 설계
4. 코드 작성 원칙
(1) Plotly의 인터랙티브 기능을 적극 활용하여 세부 수치를 확인할 수 있게 할 것.
(2) 분석 결과 테이블(이탈률 등)을 Markdown 형태로 출력하여 보고서에 인용하기 쉽게 할 것.
(3) 친절하고 자세한 주석을 포함할 것.
- 각 코드 블록마다 수행 목적을 설명
- 데이터 처리 및 지표 계산 과정에 대한 단계별 주석 작성
- 시각화 코드에서는 그래프의 의미와 해석 방법까지 주석으로 명시
(4) 평균의 함정이 없도록 할 것.
본 분석은 단일 변수 비교를 넘어, 결제 방식과 고객 특성의 조합을 기반으로
이탈 위험이 높은 고객군을 식별하고, 이에 따른 맞춤형 리텐션 전략 수립 가능성을 제시한다.1. 보고서 구조
1) 섹션 1: 현황 분석: 전체 이탈률 및 주요 이탈 세그먼트 수치 요약.
2) 섹션 2: 가설 검증: “이탈은 결제 방식 자체의 영향인가, 아니면 시니어 여부와 결합된 특정 고객군에서 집중적으로 발생하는가?”
3) 섹션 3: 리텐션 전략: 이탈 위험이 가장 큰 사용자들을 위한 구체적인 맞춤형 오퍼 제안.
2. 인사이트 도출 원칙
1) 증거 우선: 분석 코드에서 나온 이탈률(%) 및 가입 기간별 수치를 문장에 직접 인용할 것.
2) 비즈니스 액션 연결: 단순 수치 나열이 아니라, '어떤 시점에 어떤 혜택을 주어야 하는지' 마케팅 액션 아이템을 도출할 것.
3. 톤앤매너
경영진을 설득할 수 있는 신뢰감 있고 간결한 비즈니스 문체.- 코드
# =========================================
# 0. 라이브러리 불러오기
# =========================================
# 데이터 처리: pandas
# 시각화: plotly (인터랙티브 그래프)
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
# =========================================
# 1. 데이터 불러오기
# =========================================
# CSV 파일 경로 (Colab 업로드 기준)
df = pd.read_csv('/content/drive/MyDrive/KDT/Telco-Customer-Churn.csv')
# 데이터 기본 확인
print("데이터 크기:", df.shape)
display(df.head())
# =========================================
# 2. 데이터 정제 (지시서 요구사항 반영)
# =========================================
# -------------------------------
# (1) TotalCharges 처리
# -------------------------------
# 공백을 NaN으로 변환
df['TotalCharges'] = df['TotalCharges'].replace(' ', pd.NA)
# 숫자형으로 변환 (문제 발생 시 NaN 처리)
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce')
# 결측치 제거
df = df.dropna(subset=['TotalCharges'])
# -------------------------------
# (2) Churn 컬럼 변환 (Yes/No → 1/0)
# -------------------------------
df['Churn'] = df['Churn'].map({'Yes': 1, 'No': 0})
# -------------------------------
# (3) SeniorCitizen 라벨링
# -------------------------------
df['SeniorGroup'] = df['SeniorCitizen'].map({
0: '일반 고객',
1: '시니어 고객'
})
# -------------------------------
# (4) 불필요 컬럼 제거
# -------------------------------
df = df.drop(columns=['customerID'])
# 데이터 정제 후 확인
print("정제 후 데이터 크기:", df.shape)
# =========================================
# 3. 핵심 지표 계산
# =========================================
# -------------------------------
# (1) 전체 이탈률
# -------------------------------
overall_churn_rate = df['Churn'].mean()
# -------------------------------
# (2) 결제 방식별 이탈률
# -------------------------------
payment_churn = df.groupby('PaymentMethod').agg(
고객수=('Churn', 'count'),
이탈률=('Churn', 'mean')
).reset_index()
# -------------------------------
# (3) 시니어 여부별 이탈률
# -------------------------------
senior_churn = df.groupby('SeniorGroup').agg(
고객수=('Churn', 'count'),
이탈률=('Churn', 'mean')
).reset_index()
# -------------------------------
# (4) 교차 분석 (Payment × Senior)
# -------------------------------
cross_churn = df.groupby(['PaymentMethod', 'SeniorGroup']).agg(
고객수=('Churn', 'count'),
이탈률=('Churn', 'mean')
).reset_index()
# =========================================
# 4. 분석 결과 테이블 (Markdown 출력)
# =========================================
print("\n## 📊 전체 이탈률")
print(f"- 전체 이탈률: {overall_churn_rate:.2%}")
print("\n## 📊 결제 방식별 이탈률")
display(payment_churn)
print("\n## 📊 시니어 여부별 이탈률")
display(senior_churn)
print("\n## 📊 결제 방식 × 시니어 교차 분석")
display(cross_churn)
# =========================================
# 5. 시각화 (Plotly)
# =========================================
# -------------------------------
# (1) 전체 이탈률 Indicator
# -------------------------------
fig1 = go.Figure(go.Indicator(
mode="number+gauge",
value=overall_churn_rate * 100,
title={'text': "전체 이탈률 (%)"},
gauge={'axis': {'range': [0, 100]}}
))
fig1.show()
# -------------------------------
# (2) 결제 방식별 이탈률
# -------------------------------
fig2 = px.bar(
payment_churn,
x='PaymentMethod',
y='이탈률',
text=payment_churn['이탈률'].apply(lambda x: f"{x:.1%}"),
hover_data=['고객수'],
color='이탈률',
title='결제 방식별 이탈률'
)
fig2.update_layout(
yaxis_tickformat='.0%',
xaxis_title='결제 방식',
yaxis_title='이탈률'
)
fig2.show()
# -------------------------------
# (3) 시니어 여부별 이탈률
# -------------------------------
fig3 = px.bar(
senior_churn,
x='SeniorGroup',
y='이탈률',
text=senior_churn['이탈률'].apply(lambda x: f"{x:.1%}"),
hover_data=['고객수'],
color='이탈률',
title='시니어 여부별 이탈률'
)
fig3.update_layout(
yaxis_tickformat='.0%',
xaxis_title='고객 그룹',
yaxis_title='이탈률'
)
fig3.show()
# -------------------------------
# (4) 교차 분석 (Grouped Bar Chart)
# -------------------------------
fig4 = px.bar(
cross_churn,
x='PaymentMethod',
y='이탈률',
color='SeniorGroup',
barmode='group',
text=cross_churn['이탈률'].apply(lambda x: f"{x:.1%}"),
hover_data=['고객수'],
title='결제 방식 × 시니어 여부 이탈률'
)
fig4.update_layout(
yaxis_tickformat='.0%',
xaxis_title='결제 방식',
yaxis_title='이탈률'
)
fig4.show()
# -------------------------------
# (5) Heatmap (고위험군 식별용)
# -------------------------------
heatmap_data = cross_churn.pivot(
index='SeniorGroup',
columns='PaymentMethod',
values='이탈률'
)
fig5 = px.imshow(
heatmap_data,
text_auto='.1%',
aspect='auto',
title='이탈률 Heatmap (고위험 고객군 식별)'
)
fig5.show()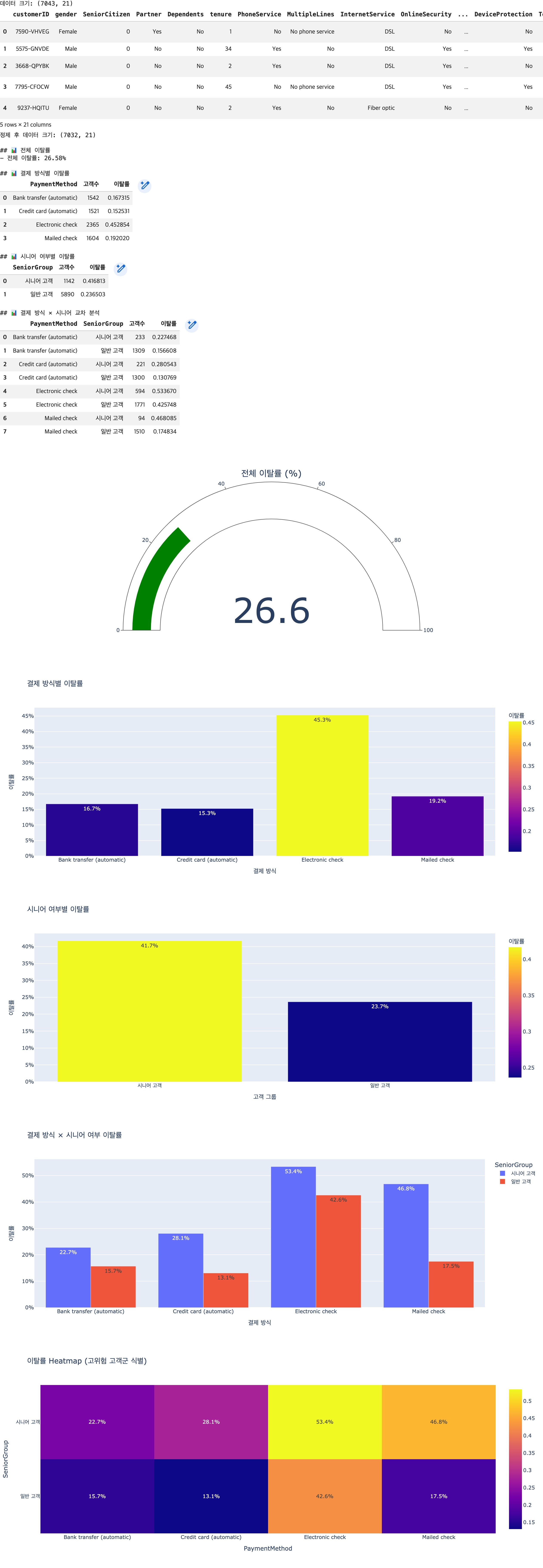
시간이 없는 관계로.. ppt는 초안만 만들었어요..

간단하게.. 흰 배경에 검은 글씨.. 이미지 없음.. 😅😅
다음엔 미리캔버스 한 번 써봐야겠어요! 대AI시대에 ppt는 항상 파워포인트나 피그마로 하나하나 만들기만 해서야.. 😳

