
이번 주는 3일만 지나면 주말이에요~~!
2026.05.06. 수요일
자연어 처리
- mecab 형태소 분석기를 이용한 토큰화
- 형태소 빈도수 분석 실습
- 임베딩(Embeddnig)
구조화된 바이브 코딩을 이용한 은행 정기예금 가입 예측 데이터 분석 및 예측 코드 생성 및 검증 / 보고서 생성 지시서 작성 / 경영진 보고용 전략 보고서 작성 (PPT 초안까지 작성 및 slack DM으로 제출)
[ 한글 텍스트: 형태소 단위 토큰화 ]
- mecab 형태소 분석기를 이용한 형태소 단위 토큰화
# mecab 형태소 분석기 설치 -> 터미널 사용(선택적)
!pip install python-mecab-ko# mecab 형태소 분석기 사용법
## 필요한 함수 임포트
from mecab import MeCab
## 형태소 분석 모델 생성
mc = MeCab()
## 기능 구현(1) -> 형태소 분석 -> 결과물: [형태소1, 형태소2, ...]
morphs_mecab = mc.morphs(sentence=text_ko)
print(f'한글 텍스트 데이터를 mecab 형태소 분석기로 형태소 분석을 한 결과: \n{morphs_mecab}')
print('-'*80)
## 기능 구현(2) -> 형태소 분석 + 품사 태깅 -> 결과물: [(형태소1, 품사1), (형태소2, 품사2)]
pos_mecab = mc.pos(sentence=text_ko)
print(f'한글 텍스트 데이터를 품사와 함께 형태소 분석한 결과: \n{pos_mecab}')
print('-'*80)
## 기능 구현(3) -> 형태소 분석 + 명사 추출 -> 결과물: [명사1, 명사2, ...]
nouns_mecab = mc.nouns(sentence=text_ko)
print(f'한글 텍스트 데이터로부터 명사만 추출한 결과: \n{nouns_mecab}')
- 형태소 빈도수 분석 및 시각화
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')# 대한민국 헌법 텍스트 데이터 불러오기
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/constitution.txt'
## 파이썬으로 텍스트 파일을 읽어오기
with open(file=file_path, mode='r') as f:
text = f.read()
## 결과 확인
print(f'대한민국 헌법 전문: \n{text}')
print('-'*80)
print(f'대한민국 헌법 텍스트의 글자 수: {len(text)}')
# collections 패키지 -> Counter 함수 사용법
## 필요한 함수 임포트
from collections import Counter
## 데이터 생성
sample = ["hi", "hey", "hi", "hi", "hello", "hey"]
## Counter 함수 호출, 함수 실행
counts = Counter(sample)
## 결과 확인
print(f'단어별 빈도수: \n{counts}')
print('-'*80)
print(f'단어별 빈도수 측정의 결과 값의 자료형: {type(counts)}')
-- mecab 형태소 분석기를 이용한 빈도수 분석
# 형태소 분석 + 명사 추출
## 필요한 함수 임포트
from mecab import MeCab
## 형태소 분석 모델 생성
mc = MeCab()
## nouns() 함수 -> 형태소 분석 + 명사 추출
nouns = mc.nouns(text)
print(f'mecab 형태소 분석기를 이용하여 명사를 추출한 결과: \n{nouns}')
print('-'*80)
print(f'추출된 명사의 개수: {len(nouns)}')
print('-'*80)
## 길이가 1보다 큰 명사만 추출(목적: 불용어 제거)
nouns_mecab = []
for noun in nouns:
if len(noun)>1:
nouns_mecab.append(noun)
## 결과 확인
print(f'mecab 형태소 분석기를 이용하여 길이가 1보다 큰 명사만 추출한 결과: \n{nouns_mecab}')
print('-'*80)
print(f'길이가 1보다 큰 명사의 개수: {len(nouns_mecab)}개')
# 길이가 1보다 큰 명사의 빈도수 분석
## Counter() 함수 호출
counts_mecab = Counter(nouns_mecab)
## 결과 확인
print(f'mecab 형태소 분석기를 이용해서 추출한 길이가 1보다 큰 명사의 빈도수: \n{counts_mecab}')
print('-'*80)
print(f'길이가 1보다 큰 명사의 종류: {len(counts_mecab)}개')
-- wordcloud를 이용한 빈도수 시각화
# 필요한 함수 임포트
from wordcloud import WordCloud
# colab 환경 --> 한글 폰트(나눔체) 설치
!apt-get update -qq
!apt-get install fonts-nanum* -qq# WordCloud 함수 호출, 시각화 모델 생성
wc = WordCloud(
font_path='/usr/share/fonts/truetype/nanum/NanumBarunGothic-YetHangul.ttf',
width=1000,
height=500,
max_words=50,
background_color='white',
max_font_size=200
)# mecab 형태소 분석기로 분석한 결과에 따른 시각화
## 이미지 생성
wc.generate_from_frequencies(counts_mecab)
## 이미지 저장
# file_path="/content/drive/MyDrive/KDT/헌법_mecab.png"
# file_path="/content/drive/MyDrive/KDT/헌법_mecab1.png"
file_path="/content/drive/MyDrive/KDT/헌법_mecab2.png"
wc.to_file(file_path)
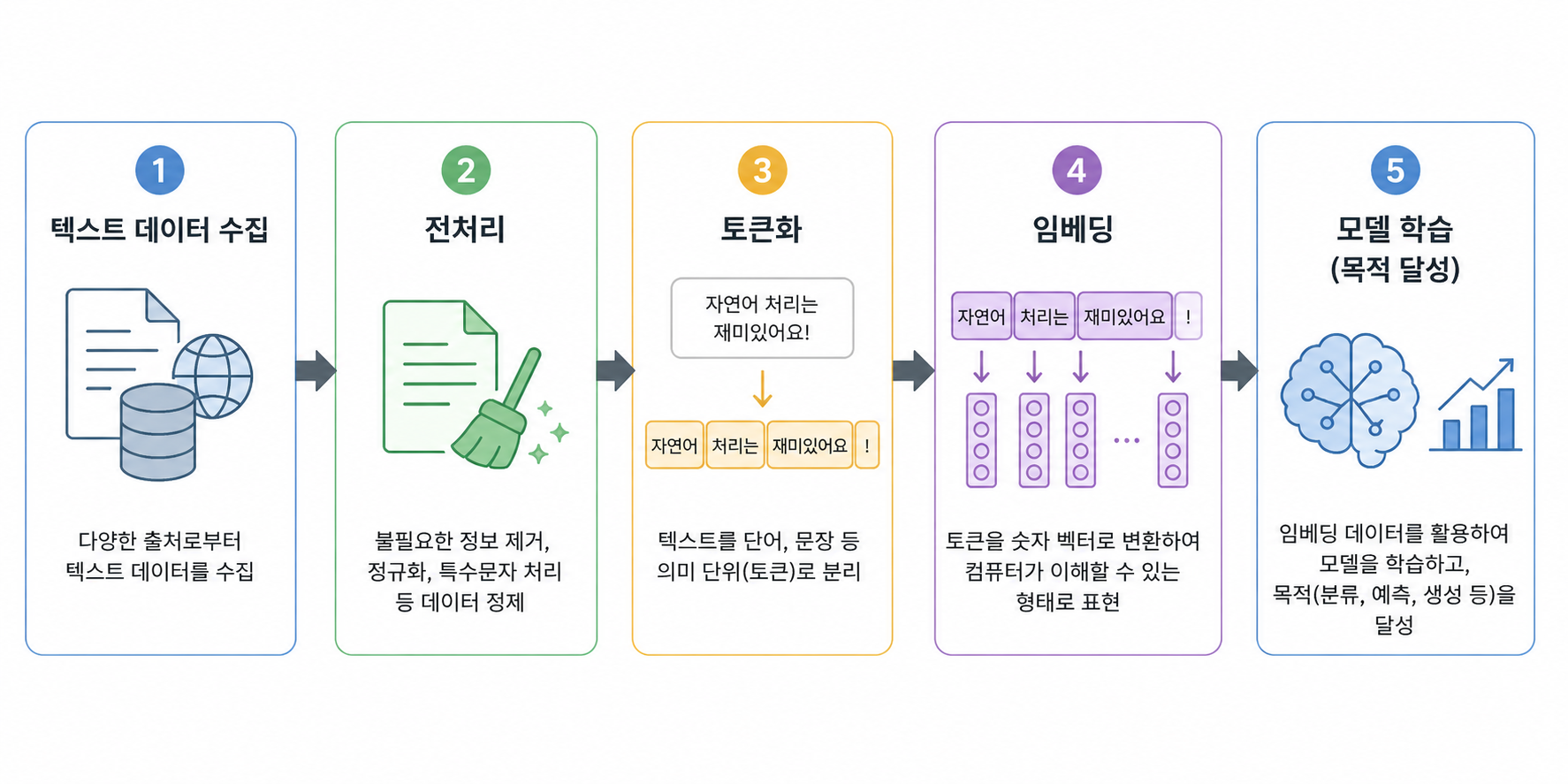
④ 임베딩
텍스트를 숫자 벡터 형태로 변환
단어 간 의미 관계를 반영하여 표현
표현의 방식: 희소 표현, 밀집 표현
- 희소 표현
전체 단어 집합 중 일부만 값이 있고 대부분이 0으로 채워지는 방식
차원은 크지만 실제 정보는 드문드문 존재함
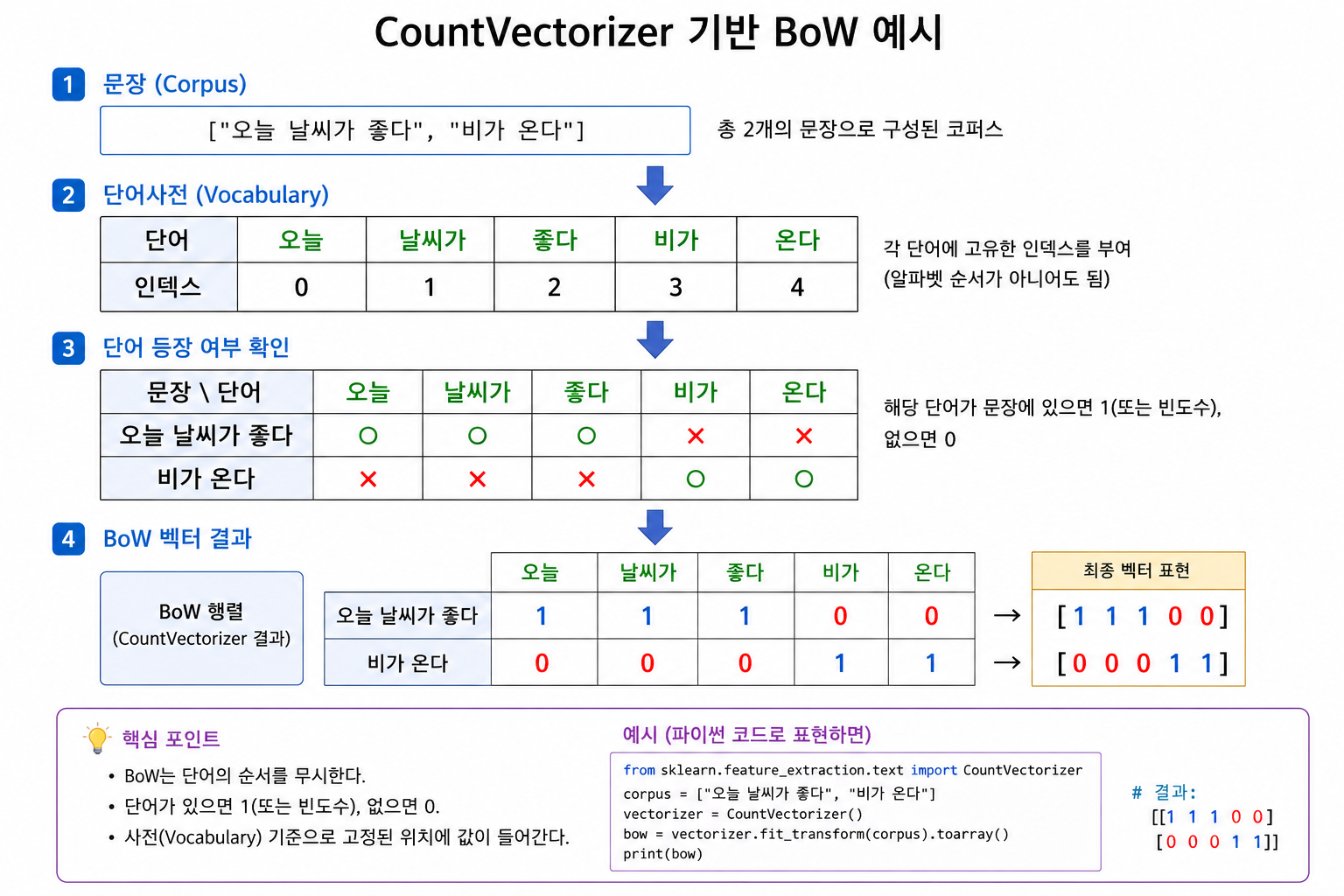
BoW(Bag of Words)
→ 단어 순서는 무시하고 등장 빈도만으로 벡터 생성함
모델: CountVectorizer 활용함
→ 각 단어 출현 횟수 기반으로 희소 행렬 형태 벡터로 변환함
[ 임베딩: BoW ]
# 필요한 함수 임포트
from sklearn.feature_extraction.text import CountVectorizer
# 임베딩 모델 생성
ko_cv = CountVectorizer()
en_cv = CountVectorizer()2026.05.07. 목요일
자연어 처리
- CountVectorizer 함수를 이용한 BoW 구현
- 코사인 유사도(Cosine Similarity)
- CountVectorizer와 코사인 유사도를 이용한 텍스트 유사도 측정
구조화된 바이브 코딩을 이용한 온라인 쇼핑객의 구매 의도 분석 및 예측 코드 생성 및 검증 / 보고서 생성 지시서 작성 / 경영진 보고용 전략 보고서 작성 (PPT 초안까지 작성 및 slack DM으로 제출)
텍스트 유사도(Text Similarity)
두 텍스트가 얼마나 비슷한 의미나 형태를 가지는지 수치로 표현하는 것
ex.
문장1: “오늘 날씨가 정말 좋다”
문장2: “오늘은 날씨가 매우 좋네”
→ 사용하는 단어와 의미가 비슷하므로 유사도 높음
유사도 측정 기준
① 단어 기반 유사도
공통으로 등장하는 단어 수 비교
대표 예시: 자카드 유사도, BoW 기반 비교, TF-IDF 등
② 벡터 거리 기반 유사도
문장을 벡터로 변환 후 거리/각도 계산
대표 예시: 코사인 유사도, 유클리드 거리, 맨해튼 거리 등
③ 의미 기반 유사도
단어 뜻과 문맥까지 고려
대표 예시: Word2Vec, BERT 임베딩, Sentence Transformer 등
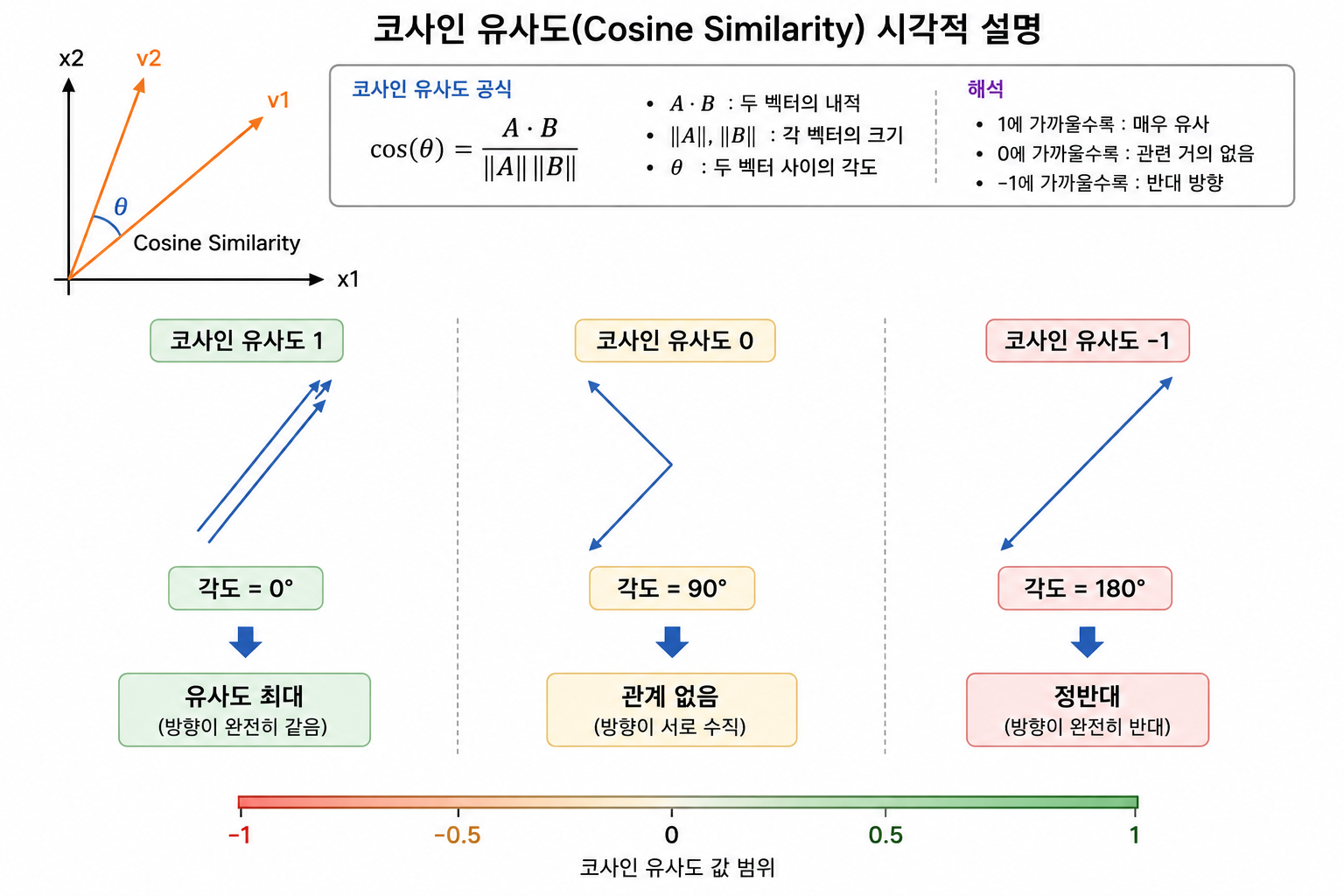
- 코사인 유사도(Cosine Similarity)
두 벡터 사이의 “각도”를 기준으로 얼마나 유사한지 측정하는 방법
벡터의 크기보다 방향이 얼마나 비슷한지를 확인함
[ 임베딩: BoW ]
# 필요한 함수 임포트
from sklearn.feature_extraction.text import CountVectorizer
# 임베딩 모델 생성
ko_cv = CountVectorizer()
en_cv = CountVectorizer()- 한글 텍스트 데이터에 대한 임베딩
# 한글 텍스트 데이터 생성 및 단어 사전 생성
## 한글 텍스트 데이터(말뭉치) 생성
ko_text = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부해아지']
## fit() 함수 호출 -> 토큰화(어절 단위) -> 토큰별 단어 사전 생성
ko_cv.fit(ko_text)
## 생성된 단어 사전 확인
ko_vocab = ko_cv.vocabulary_
sorted_ko_vocab = dict(sorted(ko_vocab.items(), key=lambda item: item[1]))
print(f'생성된 단어 사전: \n{sorted_ko_vocab}')
# 한글 text 임베딩
## 임베딩 할 text 생성
ko_sentences1 = ['나는 배가 고프다']
ko_sentences2 = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부해아지']
## transform().toarray() 함수 호출
ko_embedding1 = ko_cv.transform(['나는 배가 고프다']).toarray()
ko_embedding2 = ko_cv.transform(ko_sentences2).toarray()
## 결과 확인
print(f'첫 번째 한글 텍스트에 대한 임베딩의 결과: \n{ko_embedding1}')
print('-'*80)
print(f'두 번째 한글 텍스트에 대한 임베딩의 결과: \n{ko_embedding2}')
- 영어 텍스트 데이터에 대한 임베딩
# 영어 텍스트 데이터 생성 및 단어 사전 생성
## 영어 텍스트 데이터(말뭉치) 생성
en_text = ['You already know what The Present is',
'You already know where to find it',
'And you already know how it can make you happy and successful',
'You knew it best when you were younger',
'You have simply forgotten']
## fit() 함수 -> 토큰화(띄어쓰기 기준: 단어) + 단어 사전 생성
en_cv.fit(en_text)
## 생성된 단어 사전 확인
en_vocab = en_cv.vocabulary_
sorted_en_vocab = dict(sorted(en_vocab.items(), key=lambda item: item[1]))
print(f'생성된 단어 사전: \n{sorted_en_vocab}')
# 영어 문장 임베딩
## 임베딩 할 텍스트 데이터 생성
en_sentences1 = ['You already know what The Present is']
en_sentences2 = ['You already know what The Present is',
'You already know where to find it',
'And you already know how it can make you happy and successful',
'You knew it best when you were younger',
'You have simply forgotten']
## transform().toarray() 함수 호출
en_embedding1 = en_cv.transform(en_sentences1).toarray()
en_embedding2 = en_cv.transform(en_sentences2).toarray()
## 결과 확인
print(f'첫 번째 영어 텍스트에 대한 임베딩의 결과: \n{en_embedding1}')
print('-'*80)
print(f'두 번째 영어 텍스트에 대한 임베딩의 결과: \n{en_embedding2}')
- 코사인 유사도를 이용한 텍스트 유사도 측정
# 필요한 함수 임포트
from sklearn.metrics.pairwise import cosine_similarity
# 유사도 측정을 할 텍스트 데이터 생성
en_sentences = ["What should I do to be a great scientist?",
"How can I be a good scientist?"]
ko_sentences = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?",
"무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]# 영어 텍스트 데이터에 대한 단어 사전 생성
## fit() 함수 호출
en_cv.fit(en_sentences)
## 단어 사전 확인
en_vocab = en_cv.vocabulary_
sorted_en_vocab = dict(sorted(en_vocab.items(), key=lambda item: item[1]))
print(f'영어 텍스트로부터 생성된 단어 사전: \n{sorted_en_vocab}')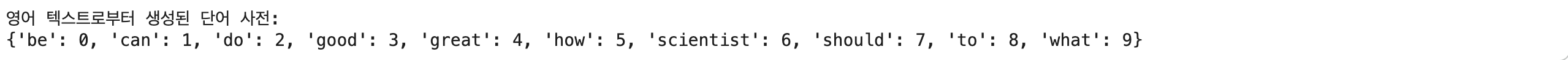
# 임베딩용 영어 문장 생성
# en_text1 = ["What should I do to be a great scientist?"]
# en_text2 = ["How can I be a good scientist?"]
en_text = ["What should I do to be a great scientist?",
"How can I be a good scientist?"]
# 영어 문장 임베딩
# X1 = en_cv.transform(en_text1).toarray()
# Y1 = en_cv.transform(en_text2).toarray()
X1 = en_cv.transform(en_text).toarray()
# 임베딩의 결과 확인
# print(f'첫 번째 영어 문장에 대한 임베딩의 결과: \n{X1}')
# print('-'*80)
# print(f'두 번째 영어 문장에 대한 임베딩의 결과: \n{Y1}')
print(f'전체 영어 문장에 대한 임베딩의 결과: \n{X1}')
# 영어 문장에 대한 코사인 유사도 측정
# en_sim = cosine_similarity(X1, Y1)
en_sim = cosine_similarity(X1)
print(f'영어 문장 간의 코사인 유사도: \n{en_sim}')
# 한글 텍스트에 대한 단어 사전 생성
## fit() 함수 호출
ko_cv.fit(ko_sentences)
## 단어 사전 확인
ko_vocab = ko_cv.vocabulary_
sorted_ko_vocab = dict(sorted(ko_vocab.items(), key=lambda item: item[1]))
print(f'생성된 단어 사전: \n{sorted_ko_vocab}')
# 임베딩용 한글 문장 생성
# ko_text1 = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?"]
# ko_text2 = ["무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]
ko_text = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?",
"무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]
# 한글 문장에 대한 임베딩
# X2 = ko_cv.transform(ko_text1).toarray()
# Y2 = ko_cv.transform(ko_text2).toarray()
X2 = ko_cv.transform(ko_text).toarray()
# 임베딩의 결과 확인
# print(f'첫 번째 한글 문장에 대한 임베딩의 결과: \n{X2}')
# print('-'*80)
# print(f'두 번째 한글 문장에 대한 임베딩의 결과: \n{Y2}')
print(f'전체 한글 문장에 대한 임베딩의 결과: \n{X2}')
# 한글 문장에 대한 코사인 유사도 측정
# ko_sim = cosine_similarity(X2, Y2)
ko_sim = cosine_similarity(X2)
print(f'한글 문장에 대한 코사인 유사도: \n{ko_sim}')
2026.05.08. 금요일
자연어 처리
- CountVectorizer 와 코사인 유사도를 이용한 추천 시스템 구현 실습
- 임베딩: 밀집 표현
- 사전 학습과 추론
- HuggingFace 라이브러리 pipeline() 함수
구조화된 바이브 코딩을 이용한 고객 페르소나 분석 및 총 지출액 예측 코드 생성 및 검증 / 보고서 생성 지시서 작성 / 경영진 보고용 전략 보고서 작성 (PPT 초안까지 작성 및 slack DM으로 제출)
[ Countvectorizer 모델과 코사인 유사도를 이용한 영화 추천 서비스 구현 ]
- 데이터 불러오기
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 파이썬 경고 무시 설정
import warnings
warnings.filterwarnings('ignore')# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/movies_metadata.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
# 결과 확인
display(df)
- 전처리
# overview, title 컬럼 -> 팬시 인덱싱
df1 = df[['overview','title']]
display(df1)
# 누락 데이터 확인 및 처리(제거)
## 각 컬럼별 누락 데이터의 수 확인
num_nulls = df1.isnull().sum()
print(f'각 컬럼별 누락 데이터의 수: \n{num_nulls}')
print('-'*80)
## 누락 데이터가 존재하는 행 제거
df2 = df1.dropna(ignore_index=True)
display(df2)
- 텍스트 임베딩
# 필요한 함수 임포트
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer 함수 호출, 임베딩 모델 생성
cv = CountVectorizer(stop_words='english')# 영어 텍스트 데이터 생성 / 단어 사전 및 임베딩 행렬 생성
## data의 수 -> 10000개로 축소(행 인덱스: 0~9999) -> 슬라이싱
df3 = df2[0:10000]
display(df3)
print('-'*80)
## 단어 사전 생성에 사용할 텍스트 데이터 생성: 컬럼 -> 리스트
text_list = df3['overview'].to_list()
print(text_list)
print('-'*80)
## fit_transform([text]).toarray() -> 불용어 제거 + 단어 사전 생성 + 임베딩 행렬 생성
overview_matrix = cv.fit_transform(text_list).toarray()
## 생성된 단어 사전 추출
vocab = cv.vocabulary_
sorted_vocab = dict(sorted(vocab.items(), key=lambda item: item[1]))
## 결과 확인
print(f'생성된 영어 단어 사전: \n{sorted_vocab}')
print('-'*80)
print(f'생성된 영어 단어의 수: {len(sorted_vocab)}개')
print('-'*80)
print(f'overview 컬럼에 대한 임베딩의 결과(모양): {overview_matrix.shape}')
- 영화 추천 서비스 구현
# 10000개 영화 줄거리 -> 코사인 유사도 측정
## 필요한 함수 임포트
from sklearn.metrics.pairwise import cosine_similarity
## cosine_similarity() 함수 실행
sim = cosine_similarity(overview_matrix)
## 결과 확인
print(sim)
# 코사인 유사도 결과 값 -> DataFrame 생성
## 컬럼과 행 인덱스 설정
index = df3['title'].to_list()
columns = df3['title'].to_list()
## DataFrame 생성
df_sim = pd.DataFrame(data=sim, index=index, columns=columns)
## 결과 확인
display(df_sim)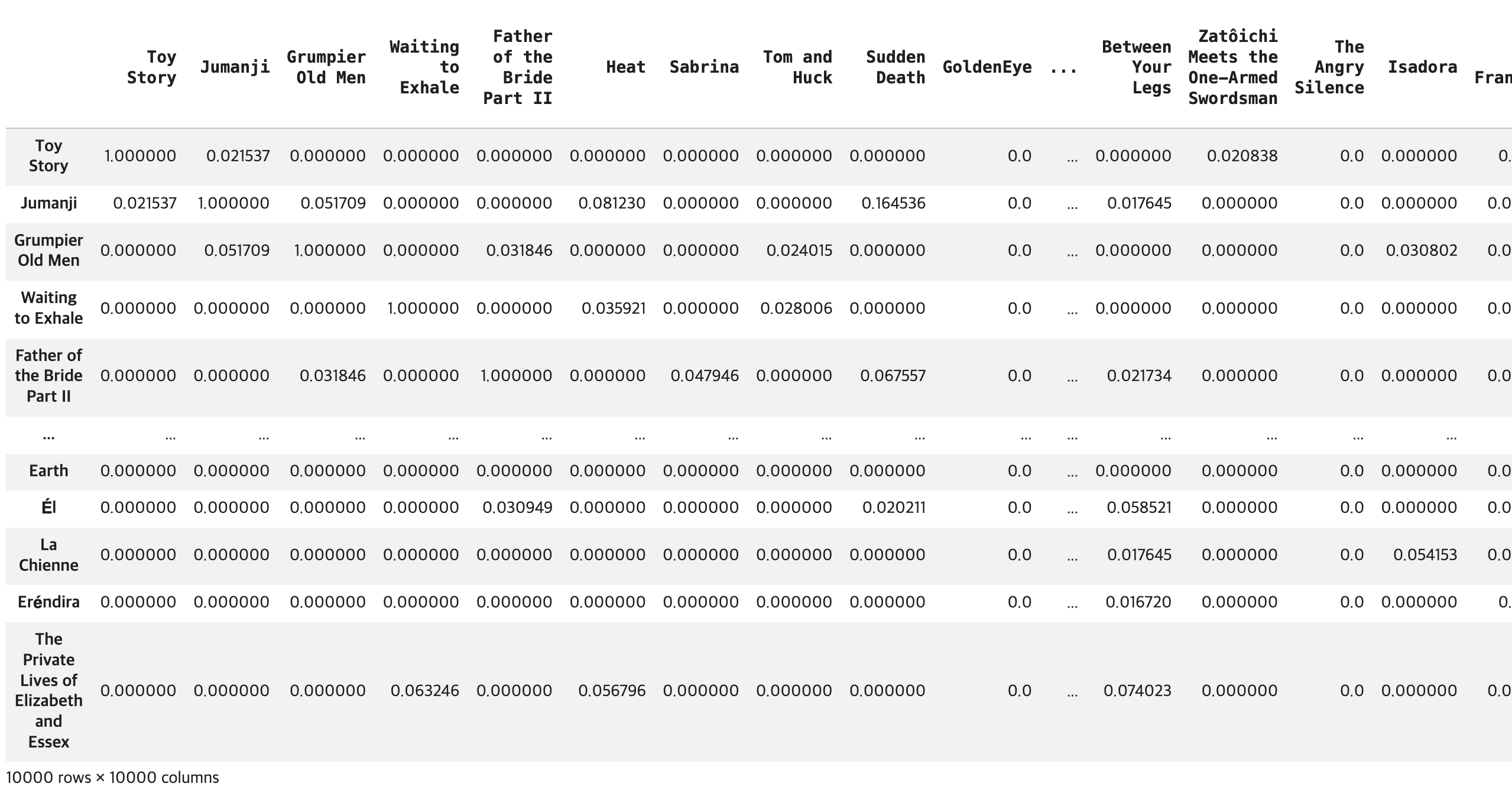
# 특정 영화 지정 -> 특정 컬럼 지정
'''
1. 컬럼의 값 -> 인덱스 순서(현재) -> 크기 순으로 정렬(내림 차순 정렬)
2. 해당 영화를 제외, 나머저에서 top_n 추출 -> 슬라이싱
'''
## 추출할 영화의 개수 설정
n = 10
## 컬럼의 값 -> 크기 순으로 정렬 -> 슬라이싱: 해당 영화를 제외, 나머저에서 top_n 추출
top_10 = df_sim['Toy Story'].sort_values(ascending=False)[1:n+1]
## 결과 확인
print(f'Toy Story와 줄거리가 가장 유사한 영화 top 10: \n{top_10}')
print(df_sim.columns)
# 특정 영화 기준 --> 줄거리가 유사한 영화 추천 함수 생성
def top_n_recommend(k, title):
## 사용자의 입력이 10000개의 영화 제목에 있는 경우에만 실행
if title in df_sim.columns:
top_n = df_sim[title].sort_values(ascending=False)[1:k+1]
return top_n
else:
print("존재하지 않는 영화 제목이오니, 확인 후 다시 입력을 해주세요")
# 영화 추천 함수 실행
## 매개 변수 값 설정
num = 10
name = "GoldenEye"
## 함수 호출
top_10 = top_n_recommend(k=num, title=name)
## 결과 확인
print(top_10)
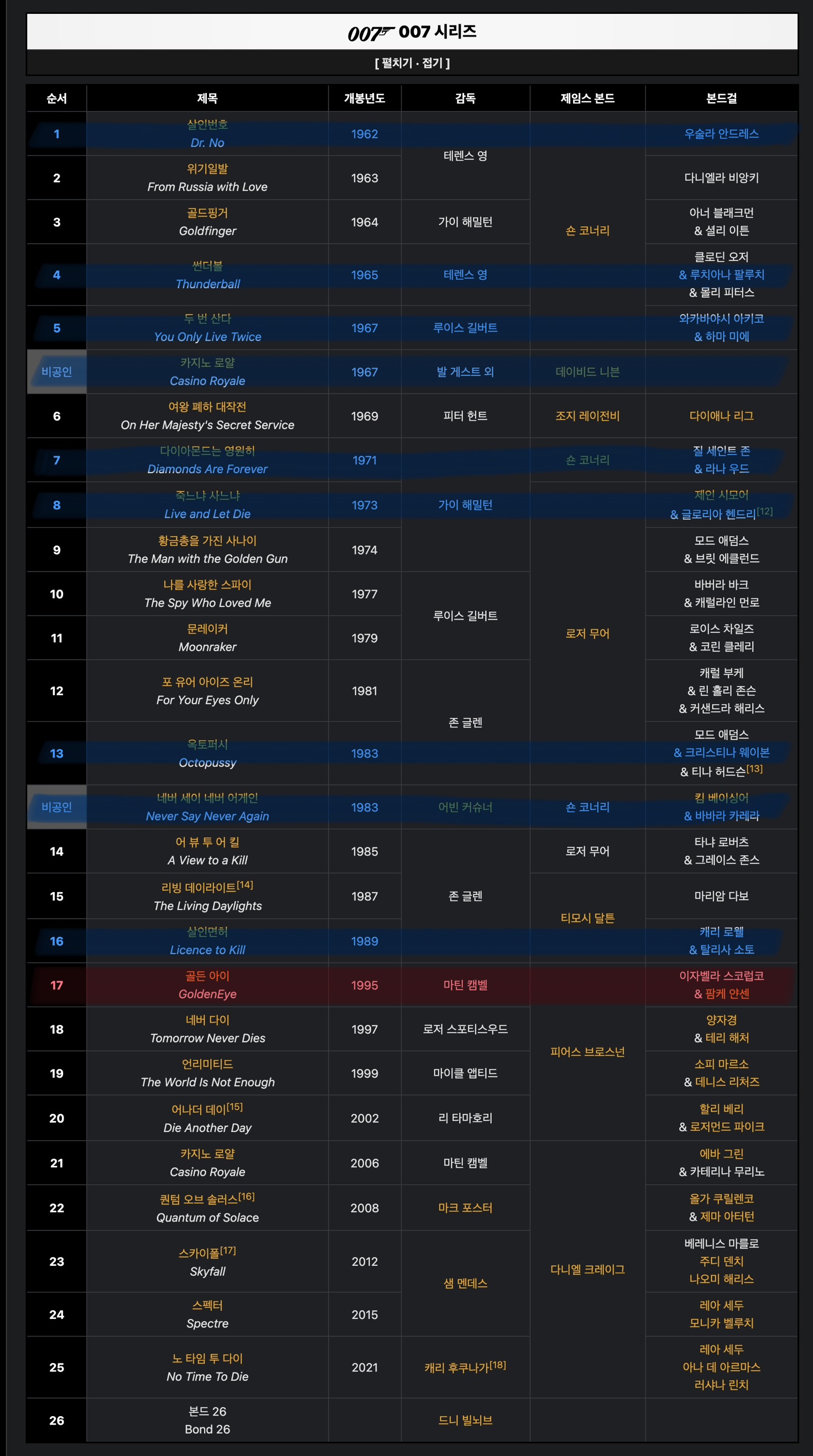
Phantasm 제외 나머지 9개는 모두 007 시리즈 작품인 걸 확인 가능

