
2026.05.11. 월요일
자연어 처리
- 임베딩: 밀집 표현
- 사전 학습과 추론
- HuggingFace 라이브러리 pipeline() 함수
- SentenceTransformer 모델
월마트 매출 데이터 분석 및 예측
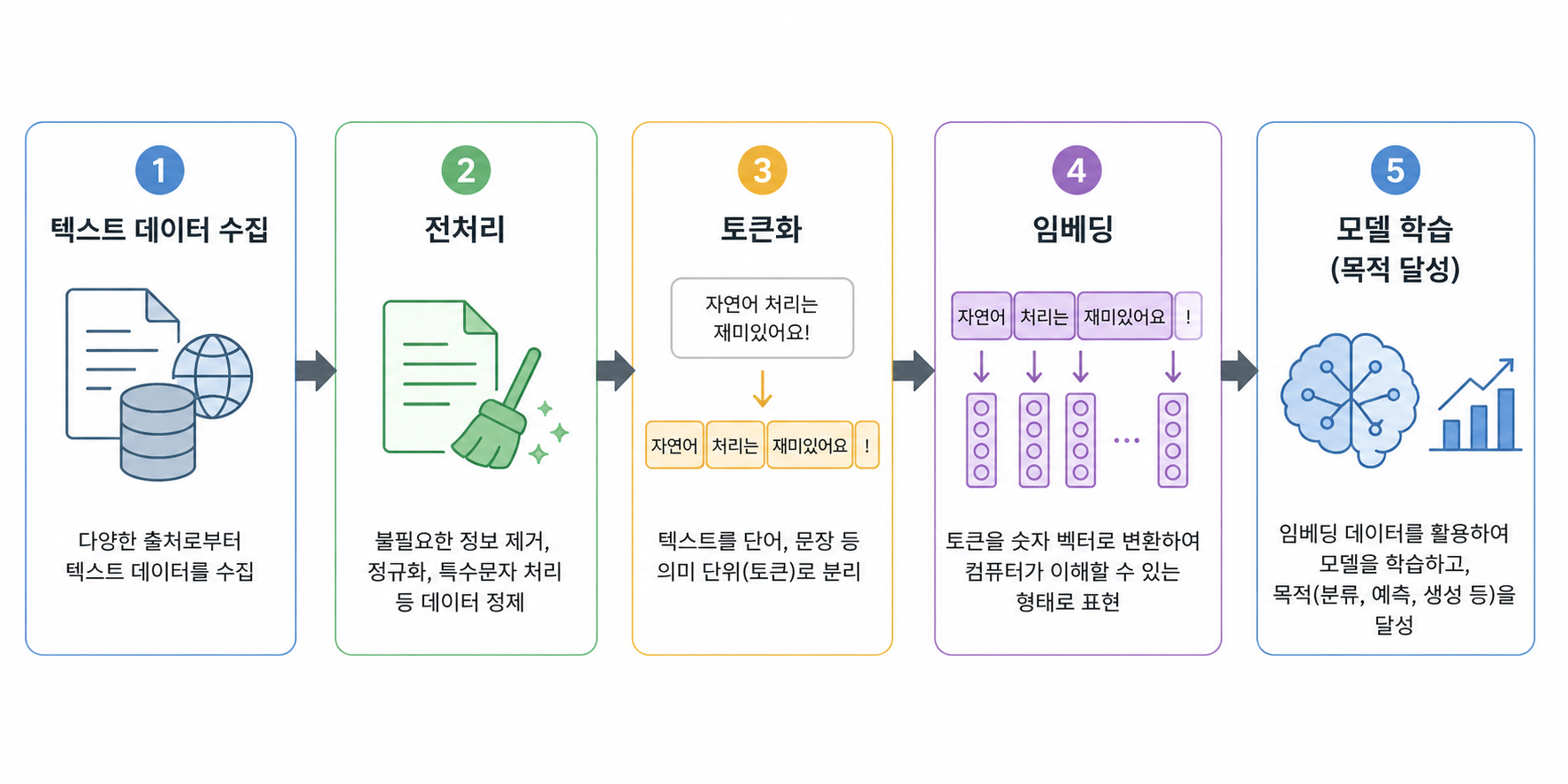
④ 임베딩
- 밀집 표현
데이터를 적은 차원의 숫자 벡터로 압축해서 의미를 담는 표현 방식
ex.
"사과" → [0.12, -0.44, 0.91, ...]
"바나나" → [0.10, -0.40, 0.88, ...]
특징
대부분의 값이 0이 아님 → “밀집(Dense)” 표현이라고 부름
의미가 비슷한 데이터끼리는 벡터도 비슷해짐 → "고양이"와 "강아지" 벡터가 가까움
차원이 비교적 작음 → 단어 하나를 수백 개 숫자로 표현 가능
- 사전 학습과 추론
사전 학습
많은 시간과 자원을 사용하여 방대한 양의 학습 데이터를 이용하여 모델의 파라미터(가중치)를 처음부터 학습시키는 과정
추론
사전 학습된 모델에 새로운 입력 데이터를 넣어 예측값을 계산해내는 과정
HuggingFace 라이브러리
- HuggingFace 라이브러리 pipeline() 함수
transformers 라이브러리의 가장 기본적인 함수
사전 학습된 모델을 연결하여 추론 작업을 관리하게 할 수 있도록 지원
- SentenceTransformer 모델
문장이나 단락을 의미를 가진 벡터(임베딩) 로 변환해주는 라이브러리/모델 모음
문장 의미 비교, 유사도 계산, 검색, 추천, 클러스터링에 매우 강함
[ pipeline 함수: 텍스트 감성 분석 ]
# hugginface 라이브러리 설치: colab 설치 완료
# 필요한 함수 임포트
from transformers import pipeline
# pipeline 함수 호출, 기본 모델 적용, all-in-model(토큰화 -> 임베딩 -> 분류) 생성
classifier = pipeline(task='text-classification')# text data 생성
text = ['The restaurant is awesome', 'The restaurant is awful']
# 감성 분석 실행
result = classifier(text)
print(f'감성 분석의 결과: \n{result}')
# 영어로된 경제 기사의 감성 분석 모델 사용
## 경제 기사로 학습된 all-in-model 모델 생성
model_name='ProsusAI/finbert'
classifier = pipeline(task='text-classification', model=model_name)
## text 생성
text=['Stocks rallied and the British pound gained.']
## 감성 분석 실행
result = classifier(text)
print(f'finbert 모델로 감성 분석을 한 결과: \n{result}')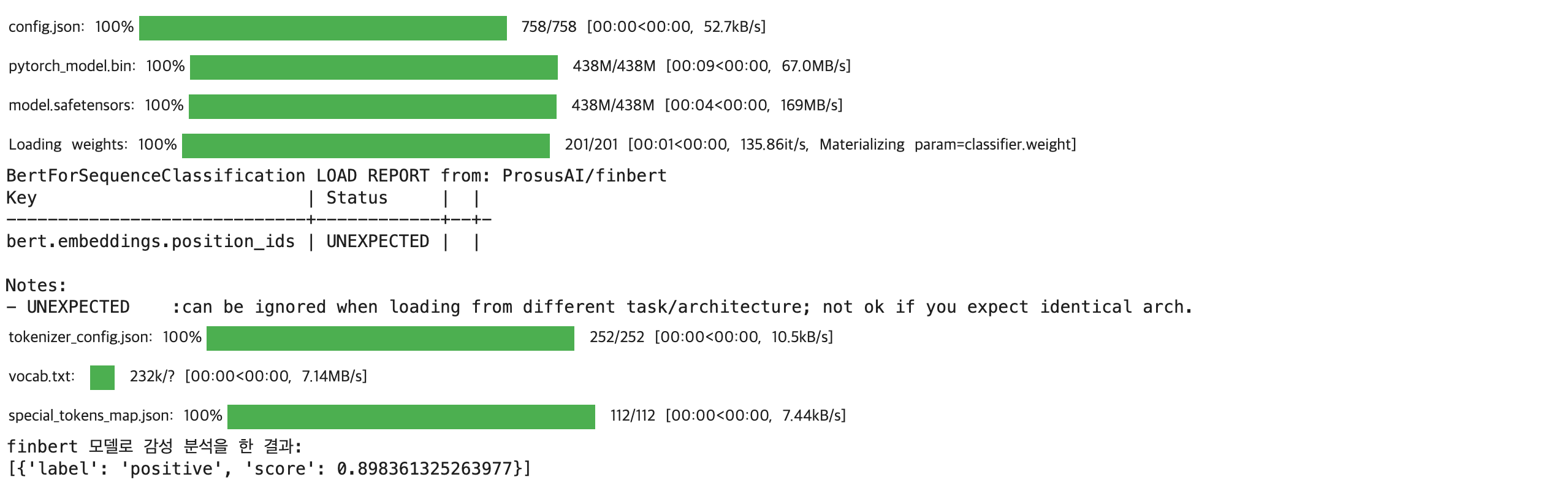
# 한글로 된 경제 기사의 감성 분석
## all-in-one 모델 생성
model_name='snunlp/KR-FinBert-SC'
## text 생성
text = "쇼핑몰 '알렛츠'도 갑자기 영업종료…'제2의 티메프 사태 우려'"
## 감성 분석 실행
result = classifier(text)
print(f'한글로 된 경제 기사에 대한 감성 분석 결과: {result}')
# 영화 리뷰 감성 분석
## all-in-one model 생성
model_name='doya/klue-sentiment-nsmc'
classifier = pipeline(task='text-classification', model=model_name)
## text 생성
text=['음악이 주가 된, 최고의 음악영화', '절대 봐서는 안 될 영화.. 재미도 없고 기분만 잡치고.. 한 세트장에서 다 해먹네']
## 감성 분석 실행
result = classifier(text)
print(result)
print('-'*80)
## 결과값 출력
print(f"첫 번째 영화 리뷰 감성 분석 결과: {result[0]['label']}")
print('-'*80)
print(f"두 번째 영화 리뷰 감성 분석 결과: {result[1]['label']}")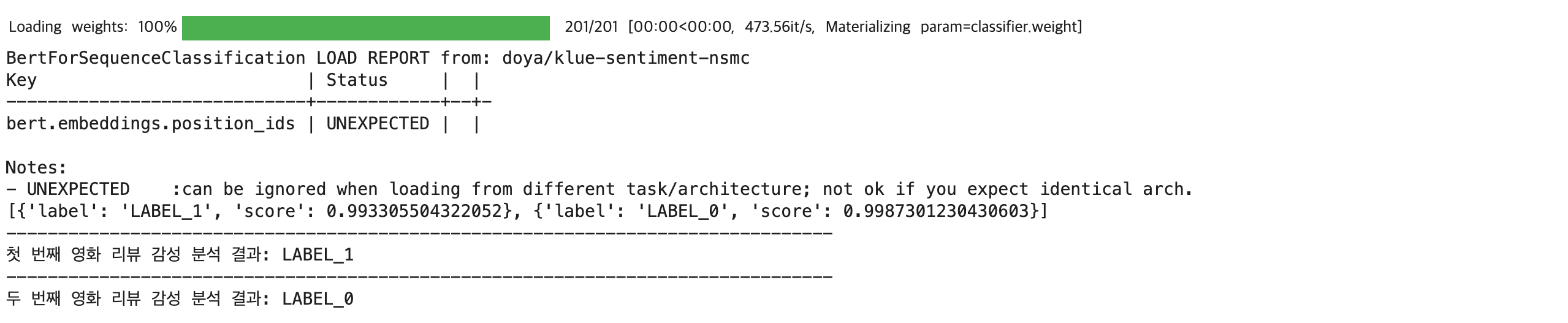
# 다수의 고객 리뷰 데이터 감성 분석
## all-in-one model 생성
model_name='doya/klue-sentiment-nsmc'
classifier = pipeline(task='text-classification', model=model_name)
## 가상의 고객 리뷰 데이터
customer_reviews = [
"배송이 생각보다 훨씬 빨랐고 포장도 꼼꼼해서 아주 만족스럽습니다!",
"기능은 다양해서 좋은데, 인터페이스가 너무 복잡해서 쓰기 어렵네요. 비추합니다.",
"가격 대비 성능은 나쁘지 않은데, 배터리가 너무 빨리 닳는 게 단점이에요.",
"이 가격에 이런 품질이라니... 친구들에게도 추천해주고 싶을 정도입니다.",
"상담원이 불친절해서 다시는 이용하고 싶지 않아요. 최악입니다."
]
## 감성 분석 수행
for review in customer_reviews:
# 개별 리뷰에 대한 감성 분석 실행
preds = classifier(review)
# 라벨을 읽기 편하게 변환 (LABEL_1: 긍정, LABEL_0: 부정)
if preds[0].get('label') == 'LABEL_1':
label = "긍정(Positive)"
else:
label = "부정(Negative)"
print(f"리뷰: {review}")
print(f"결과: {label}")
print("-" * 50)
[ SentenceTransformer를 이용한 문장 유사도 측정 ]
# 필요한 라이브러리 설치 -> colab 설치 완료
# 필요한 함수 임포트
from sentence_transformers import SentenceTransformer- 영어 문장 유사도 측정
# 유사도 측정을 할 텍스트 데이터 생성
en_sentences = ["What should I do to be a great scientist?",
"How can I be a good scientist?"]
# 사전 학습된 SentenceTransformer 영어 모델 생성
model_name='sentence-transformers/all-MiniLM-L12-v2'
model_eng = SentenceTransformer(model_name_or_path=model_name)# 문장 임베딩 행렬 생성
en_embeddings = model_eng.encode(en_sentences)
# 결과 확인
print(f'영어 텍스트의 임베딩 행렬의 모양: {en_embeddings.shape}')
# 코사인 유사도 측정
'''
## 입력 데이터: 임베딩 행렬(embeddings)
## model.similarity(embeddings, embeddings)
'''
en_sim = model_eng.similarity(en_embeddings, en_embeddings)
print(f'영어 문장 간의 코사인 유사도: \n{en_sim}')
2026.05.12. 화요일
자연어 처리
- SentenceTransformer 모델과 코사인 유사도를 이용한 텍스트 유사도 실습
- SentenceTransformer 모델과 코사인 유사도를 이용한 영화 추천 서비스 구현
- SentenceTransformer 모델과 코사인 유사도를 이용한 챗봇 구현 실습
월마트 매출 데이터를 이용한 구조화된 바이브 코딩 실습 -> slack DM으로 결과물 제출
[ SentenceTransformer를 이용한 문장 유사도 측정 ]
- 한글 문장 유사도 측정
# 유사도 측정을 할 텍스트 데이터 생성
## 매우 유사한 두 문장
ko_sentences1 = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?",
"무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]
## 서로 무관한 두 문장
ko_sentences2 = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?",
"오늘도 날씨가 매우 덥고 소나기가 내리는 등 동남아 날씨같아요."]
# 사전 학습된 다국어 SentenceTransformer 모델 생성
model_name='paraphrase-multilingual-MiniLM-L12-v2'
model_multi = SentenceTransformer(model_name)# 문장 임베딩 행렬 생성
## 매우 유사한 두 문장에 대한 임베딩 행렬 생성
ko_embeddings1 = model_multi.encode(ko_sentences1)
## 서로 무관한 두 문장에 대한 임베딩 행렬 생성
ko_embeddings2 = model_multi.encode(ko_sentences2)
## 결과 확인
print(f'매우 유사한 두 문장에 대한 임베딩 행렬의 모양: {ko_embeddings1.shape}')
print('-'*80)
print(f'서로 무관한 두 문장에 대한 임베딩 행렬의 모양: {ko_embeddings2.shape}')
# 코사인 유사도 측정
## 매우 유사한 두 문장간의 코사인 유사도
sim1 = model_multi.similarity(ko_embeddings1, ko_embeddings1)
print(f'매우 유사한 두 문장간의 코사인 유사도: \n{sim1}')
print('-'*80)
## 서로 무관한 두 문장간의 코사인 유사도
sim2 = model_multi.similarity(ko_embeddings2, ko_embeddings2)
print(f'서로 무관한 두 문장간의 코사인 유사도: \n{sim2}')
# 한국어로 사전 학습된 SentenceTransformer 모델 생성
model_name='ddobokki/klue-roberta-base-nli-sts'
model_kor=SentenceTransformer(model_name)# 문장 임베딩 행렬 생성
## 매우 유사한 두 문장에 대한 임베딩 행렬 생성
ko_embeddings1 = model_kor.encode(ko_sentences1)
## 서로 무관한 두 문장에 대한 임베딩 행렬 생성
ko_embeddings2 = model_kor.encode(ko_sentences2)
## 결과 확인
print(f'매우 유사한 두 문자에 대한 임베딩 행렬의 모양: {ko_embeddings1.shape}')
print('-'*80)
print(f'서로 무관한 두 문장에 대한 임베딩 행렬의 모양: {ko_embeddings2.shape}')
# 코사인 유사도 측정
## 매우 유사한 두 문장 간의 코사인 유사도
sim1 = model_kor.similarity(ko_embeddings1, ko_embeddings1)
print(f'매우 유사한 두 문장 간의 코사인 유사도: \n{sim1}')
print('-'*80)
## 서로 무관한 두 문장 간의 코사인 유사도
sim2 = model_kor.similarity(ko_embeddings2, ko_embeddings2)
print(f'서로 무관한 두 문장 간의 코사인 유사도: \n{sim2}')
- 영어 / 한글 문장 유사도 측정
# 유사도 측정을 위한 텍스트 데이터 생성
sentences = ['What should I do to be a great scientist?',
'훌륭한 과학자가 되려면 어떻게 해야 할까요?']
# 사전 학습된 다국어 SentenceTransformer 모델 생성
model_name='paraphrase-multilingual-MiniLM-L12-v2'
model_multi = SentenceTransformer(model_name)# 문장 임베딩 행렬 생성
embeddings = model_multi.encode(sentences)
print(f'임베딩 행렬의 모양: {embeddings.shape}')
# 코사인 유사도 측정
sim = model_multi.similarity(embeddings, embeddings)
print(f'영어와 한글 텍스트에 대한 코사인 유사도: \n{sim}')
[ SentenceTransformer 모델과 코사인 유사도를 이용한 영화 추천 서비스 구현 ]
# colab: gpu 설정- 데이터 불러오기
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 파이썬 경고 무시 설정
import warnings
warnings.filterwarnings('ignore')# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/movies_metadata.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
# 결과 확인
display(df)
- 전처리
# overview, tilte 컬럼 -> 팬시 인덱싱
df1 = df[['overview','title']]
display(df1)
# 누락 데이터 확인 및 처리(제거)
## 각 컬럼별 누락 데이터의 수 확인
num_nulls = df1.isnull().sum()
print(f'각 컬럼별 누락 데이터의 수: \n{num_nulls}')
print('-'*80)
## 누락 데이터가 존재하는 행 제거
df2 = df1.dropna(ignore_index=True)
display(df2)
- 텍스트 임베딩
# 필요한 함수 임포트
from sentence_transformers import SentenceTransformer
# 사전 학습된 SentenceTransformer 모델 생성
model_name='all-MiniLM-L12-v2'
model=SentenceTransformer(model_name)# data의 수 -> 10000개로 축소(행 인덱스: 0~9999) -> 슬라이싱
df3 = df2[0:10000]
display(df3)
# 문장 임베딩 행렬 생성
## overview 컬럼 -> 리스트로 변환
text_list = df3['overview'].to_list()
print(text_list)
print('-'*80)
## encode() 함수 호출
embeddings = model.encode(text_list)
## 결과 확인
print(f'생성된 임베딩 행렬의 모양: {embeddings.shape}')
- 영화 추천 서비스 구현
# 10000개 영화 줄거리 -> 코사인 유사도 측정
## similarity() 함수 호출
similarity = model.similarity(embeddings, embeddings)
## 결과 확인
print(f'유사도 측정의 결과: \n{similarity}')
print('-'*0)
print(f'유사도 측정의 결과 값의 모양: {similarity.shape}')
# 코사인 유사도 결과 값 -> DataFrame 생성
## 컬럼과 행 인덱스 설정
index = df3['title'].to_list()
columns = df3['title'].to_list()
## DataFrame 생성
df_sim = pd.DataFrame(data=similarity, index=index, columns=columns)
## 결과 확인
display(df_sim)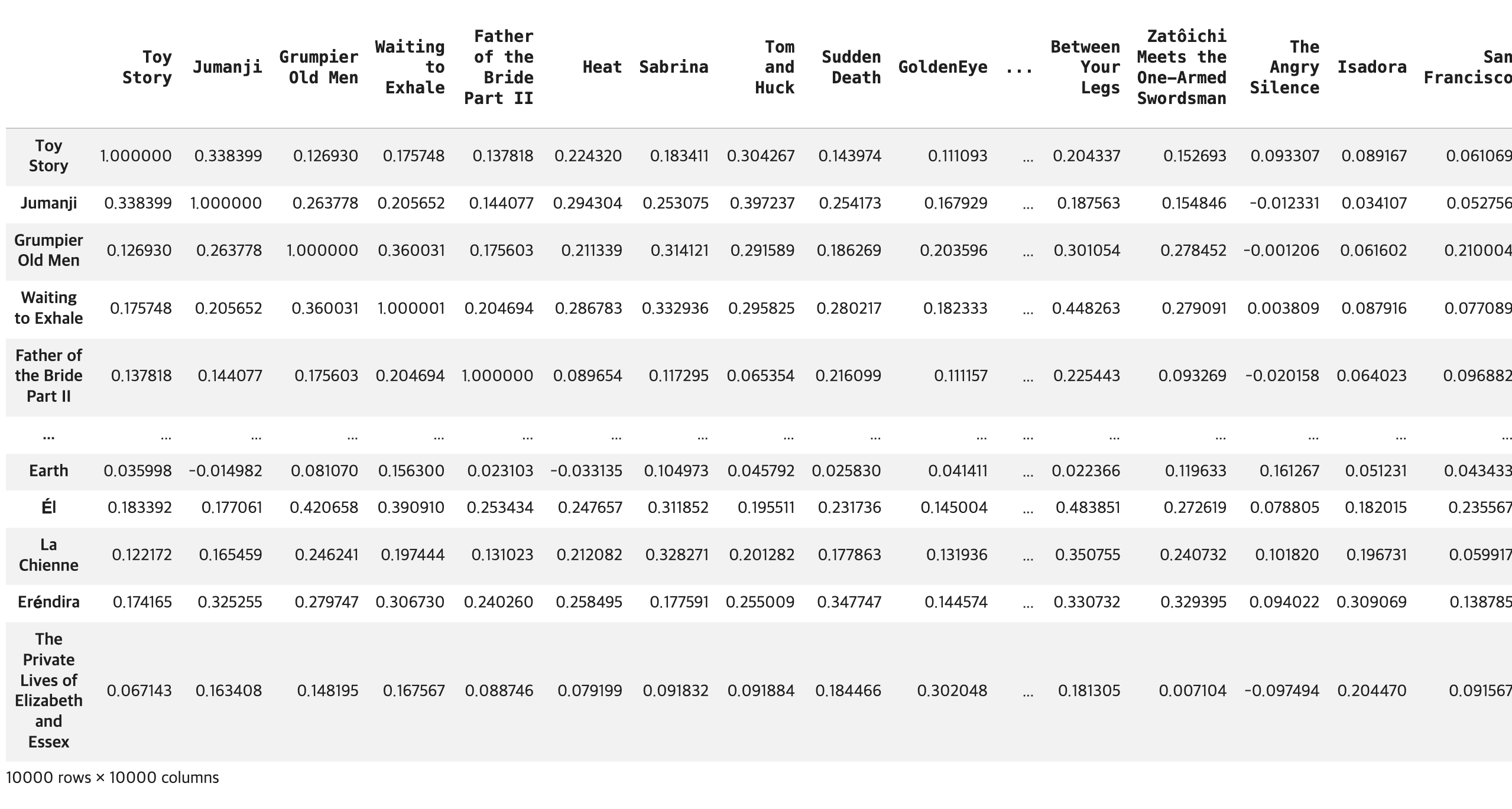
# 특정 영화 지정 -> 특정 컬럼 지정
'''
1. 컬럼의 값 -> 인덱스 순서(현재) -> 크기 순으로 정렬(내림 차순 정렬)
2. 해당 영화를 제외, 나머저에서 top_n 추출 -> 슬라이싱
'''
## 추출할 영화의 개수 설정
n=10
## 컬럼의 값 -> 크기 순으로 정렬(내림 차순) -> 슬라이싱: 해당 영화를 제외(0번행 삭제), 나머지 top_n 추출
top_10 = df_sim['Toy Story'].sort_values(ascending=False)[1:n+1]
## 결과 확인
print(f'Toy Story와 줄거리가 가장 유사한 영화 top 10: \n{top_10}')
print(df_sim.columns)
# 특정 영화 기준 -> 줄거리가 유사한 영화 추천 함수 생성
def top_n_recommend(k, title):
## 사용자의 입력이 10000개의 영화 제목에 있는 경우에만 실행
if title in df_sim.columns:
top_n = df_sim[title].sort_values(ascending=False)[1:k+1]
return top_n
else:
print("존재하지 않는 영화 제목이오니, 확인 후 다시 입력을 해주세요")# 영화 추천 함수 실행
## 매개 변수 값 설정
num = 10
name = "GoldenEye"
## 함수 호출
top_10 = top_n_recommend(k=num, title=name)
## 결과 확인
print(top_10)
[ 문장 유사도를 이용한 chatbot 개발 ]
# colab: gpu 설정- 데이터 불러오기
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 임포트
import pandas as pd
# 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/ChatBotData.csv'
# DataFrame 생성
df = pd.read_csv(file_path)
display(df)
- 전처리
# 불필요한 컬럼 삭제
df1 = df.drop(columns=['label'])
display(df1)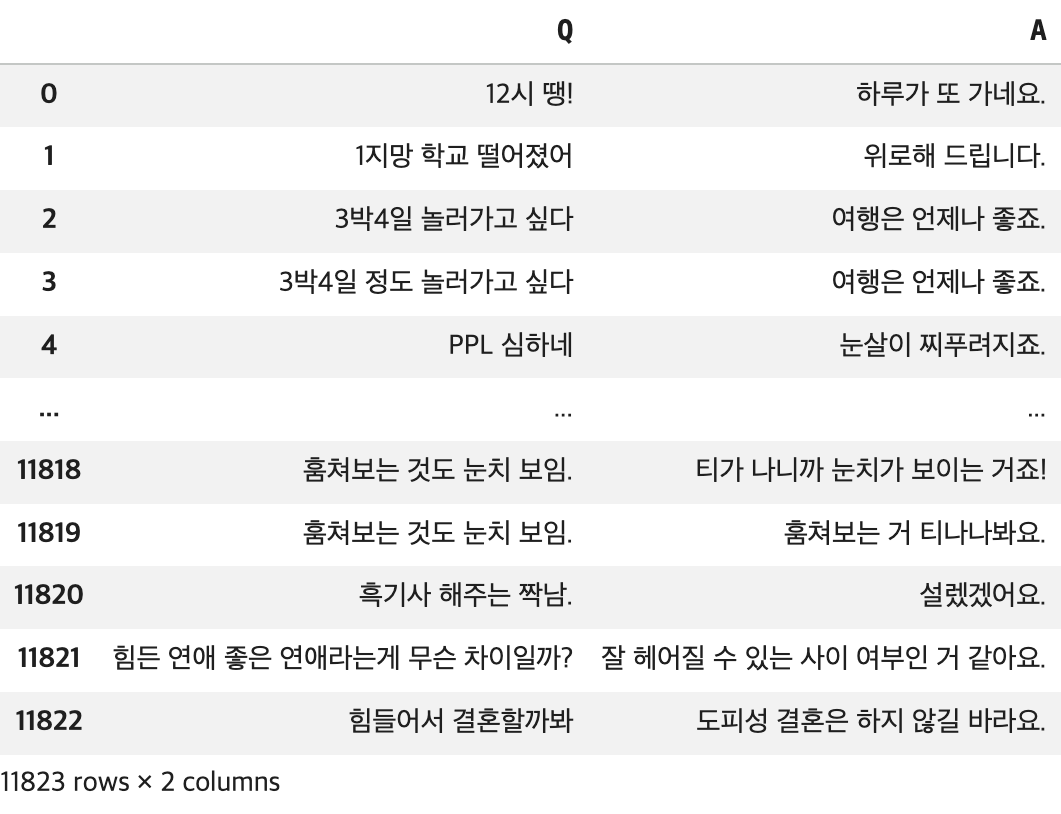
- 문장 임베딩 벡터 생성
from sentence_transformers import SentenceTransformer
# 사전 학습된 한국어 모델 생성
model_name='jhgan/ko-sroberta-multitask'
model=SentenceTransformer(model_name)# 예상 질문(Q)에 대한 임베딩 벡터 생성
## 필요한 함수 임포트
from tqdm import tqdm
## Q 컬럼 인덱싱 -> 리스트로 변환
sentences = df1['Q'].to_list()
print(sentences)
## 생성된 임베딩 벡터 저장 -> 빈 리스트 생성
embedding_list = []
## for문 + append(embedding) 사용
for sent in tqdm(sentences):
# 예상 질문 문장 1개에 대한 임베딩 벡터 생성
embedding = model.encode(sent)
# 임베딩 결과 저장
embedding_list.append(embedding)
## 결과 확인
print(f'임베딩 벡터의 개수: {len(embedding_list)}개')
print('-'*80)
print(f'첫 번째 예상 질문에 대한 임베딩 벡터: \n{embedding_list[0]}')
2026.05.13. 수요일
자연어 처리
- SentenceTransformer 모델과 코사인 유사도를 이용한 챗봇 구현 실습
- 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 실습 (1)
- 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 실습 (2)
이커머스 고객 행동 분석 데이터 분석 및 예측 -> Slack DM으로 결과물 제출
[ 문장 유사도를 이용한 chatbot 개발 ]
- 새로운 컬럼 생성
# 생성된 임베딩의 리스트 -> Pandas Series 자료형 생성
## 필요한 라이브러리 임포트
import pandas as pd
## Series 자료형 생성
embedding_series = pd.Series(data=embedding_list)
print(embedding_series)
# 새로운 컬럼 -> 예상 질문(Q)에 대한 임베딩 벡터 저장
df1['embedding'] = embedding_series
display(df1)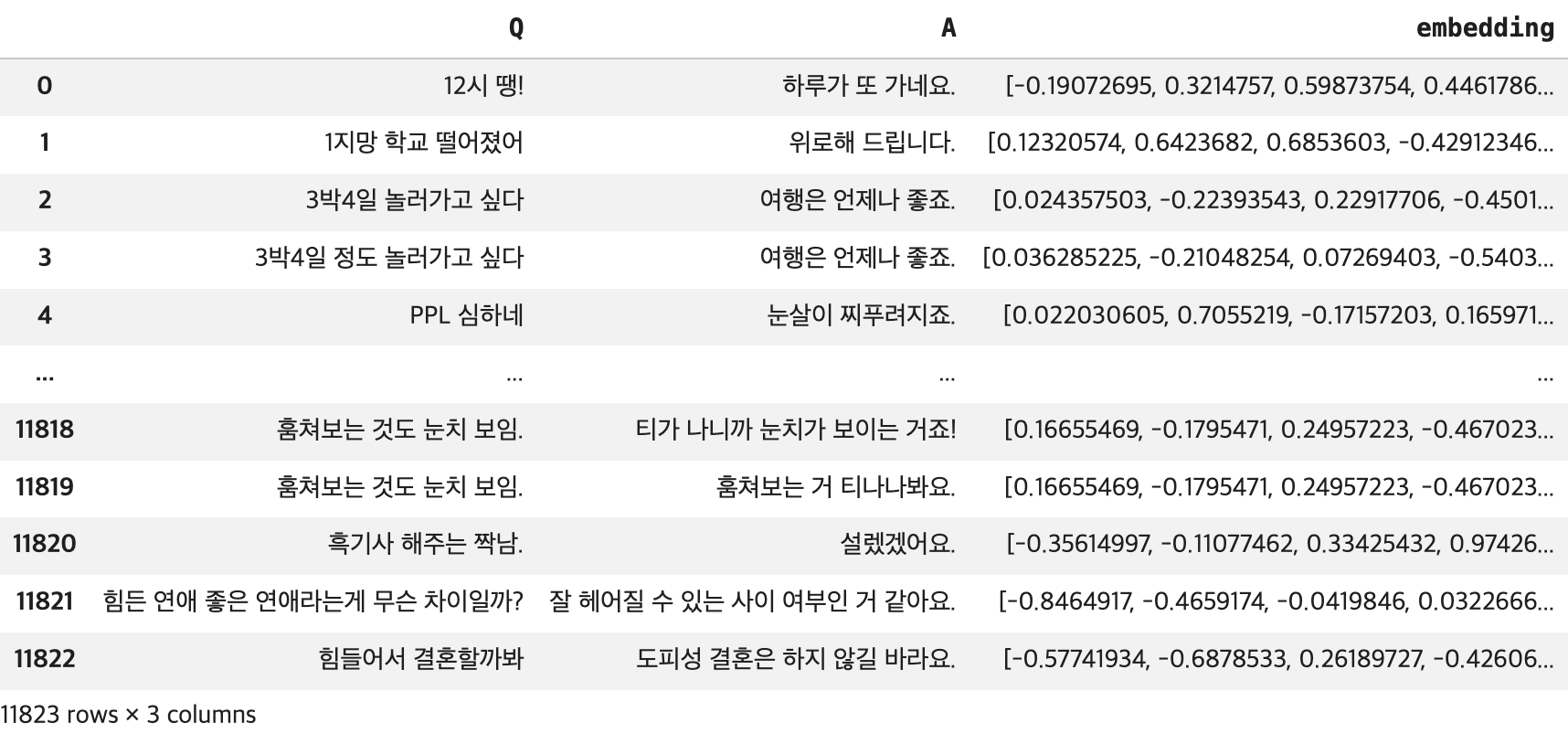
- 사용자 정의 함수 생성
# 1차원 배열 간의 코사인 유사도 측정 함수 정의
import numpy as np
def cosine_similarity(a, b):
# 내적(dot product) 계산
dot_product = np.dot(a, b)
# 벡터의 크기(norm) 계산
norm_a = np.linalg.norm(a)
norm_b = np.linalg.norm(b)
# 0으로 나누는 것 방지 (벡터의 크기가 0일 경우)
if norm_a == 0 or norm_b == 0:
return 0
return dot_product / (norm_a * norm_b)# 사용자 질문에 대한 응답 구현 함수 작동 테스트
## 사용자 질문(예시) 생성
question="배가 고파요"
## 사용자 질문 -> 임베딩 벡터 생성
user_embedding = model.encode(question)
# print(f'사용자 질문에 대한 임베딩의 결과: \n{user_embedding}')
## 사용자 질문과 예상 질문 간의 코사인 유사도 계산
score_list = []
for embedding in df1['embedding']:
sim = cosine_similarity(user_embedding, embedding)
# 결과를 score_list에 저장
score_list.append(sim)
print(f'사용자 질문과 챗봇 데이터의 예상 질문 간의 코사인 유사도: \n{score_list}')
print('-'*80)
## score 컬럼 생성
df1['score'] = pd.Series(data=score_list)
display(df1)
print('-'*80)
## score 컬럼 -> 값이 최대인 행 인덱스 추출 -> idxmax() 함수 사용
idx = df1['score'].idxmax()
print(f'사용자 질문과 가장 유사한 예상 질문의 인덱스: {idx}')
print('-'*80)
## 코사인 유사도 값이 가장 큰 예상 질문에 대한 답변 추출 -> 행:idx, 열:'A' -> 인덱싱
answer = df1.loc[idx, 'A']
print(f'챗봇의 답변: {answer}')
# 사용자 질문에 대한 응답 구현 함수 정의
def chatbot(question):
# 사용자 질문 -> 임베딩 벡터 생성
user_embedding = model.encode(question)
# 사용자 질문과 예상 질문('Q) 간의 코사인 유사도 계산
score_list=[]
for embedding in df1['embedding']:
sim = cosine_similarity(user_embedding, embedding)
score_list.append(sim)
# score 컬럼 생성 -> 코사인 유사도 값 저장
df1['score'] = pd.Series(data=score_list)
# score 컬럼 -> 값이 최대인 행 인덱스 추출
idx = df1['score'].idxmax()
# 답변 추출 -> 행: idx, 열: 'A' -> 인덱싱
answer = df1.loc[idx, 'A']
# 답변 반환
return answer- chatbot 함수 실행
# 사용자 질문 생성: 배가 고파용, 출근하기 싫어요, 여행가고 싶어요, 춥고 열이 나요
user_input = input("사용자 질문:")
# print(user_input)
# 챗봇의 답변 출력
answer = chatbot(question=user_input)
print(f'chatbot 답변: {answer}')

[ 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 ]
- 가상 데이터를 이용한 감성 분석 및 브랜드 평판 분석
# colab: gpu 연결
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 / 함수 임포트
import pandas as pd
from transformers import pipeline
import plotly.express as px# 데이터 불러오기
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/social_media_reviews.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)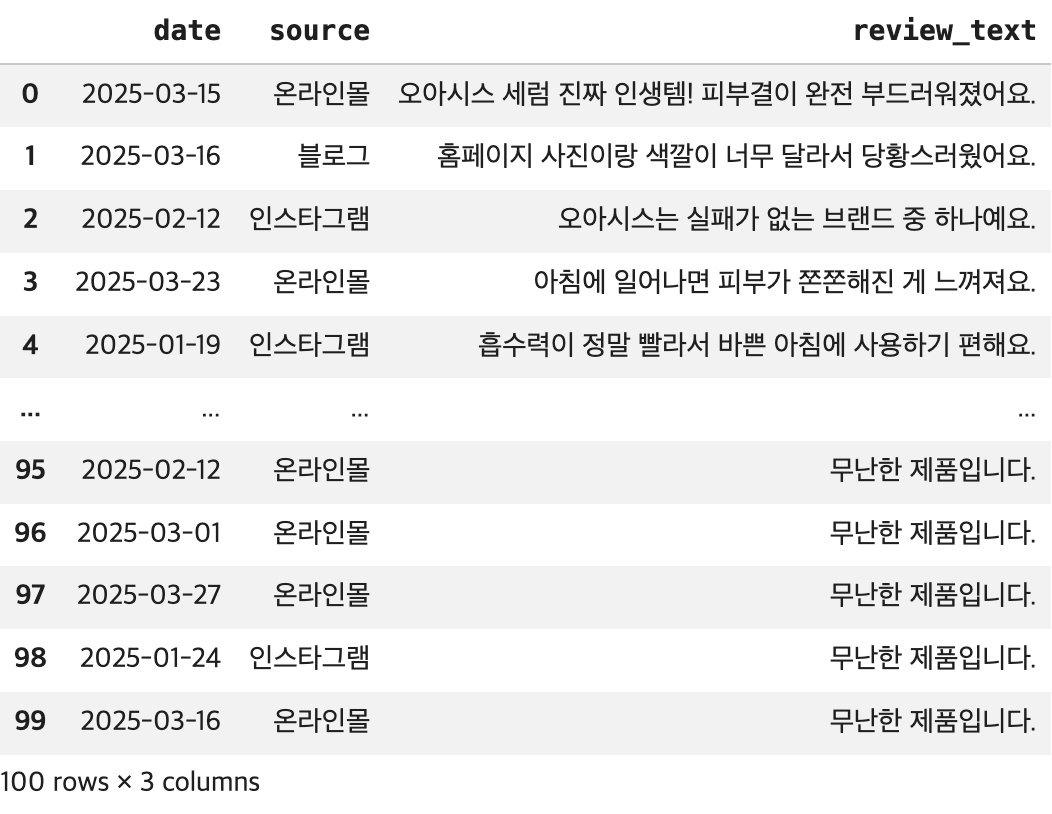
# HuggingFace pipeline 함수를 이용하여 감성 분석 all-in-one 모델 생성
sentiment_classifier = pipeline(
task='text-classification',
model='daekeun-ml/koelectra-small-v3-nsmc'
)# 샘플 리뷰 텍스트로 감성 분석 테스트
## 샘플 리뷰 텍스트 생성
sample_review = "배송도 빠르고 포장도 꼼꼼해서 좋았어요. 오아시스 최고!"
## 감성 분석 실행
result = sentiment_classifier(sample_review)
## 결과 확인
print(f'분석 결과: \n{result}')
# 전체 리뷰 데이터에 대한 감성 분석 적용 및 '레이블'만 추출
## review_text 컬럼의 텍스트 -> 리스트로 변환
all_reviews = df['review_text'].to_list()
print(all_reviews)
print('-'*80)
## 감성 분석 실행
sentiment_results = sentiment_classifier(all_reviews)
print(sentiment_results)
print('-'*80)
## 레이블 추출
label_list = []
for result in sentiment_results:
label = result.get('label')
if label == '1':
label = '긍정'
label_list.append(label)
else:
label = '부정'
label_list.append(label)
## 새로운 컬럼(sentiment) 추가
df['sentiment'] = pd.Series(label_list)
## 결과 확인
display(df)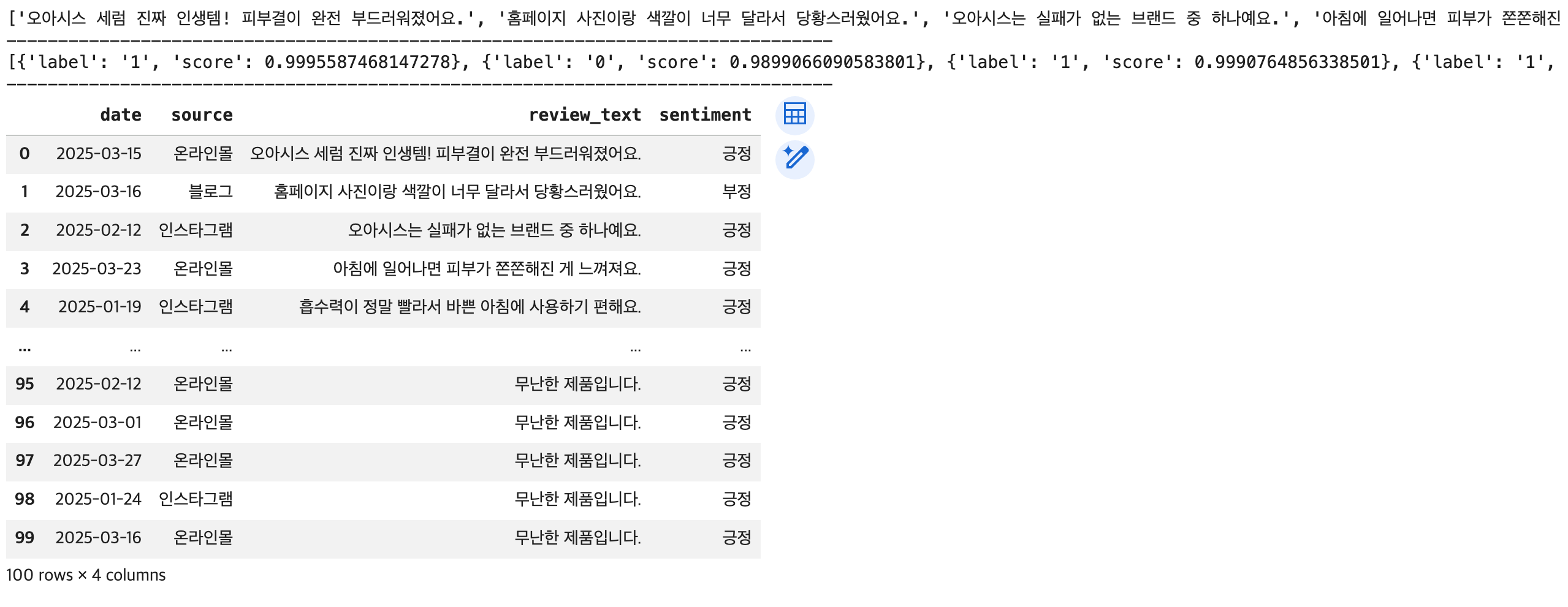
# 분석 목표: 전체 브랜드 평판 현황 (긍정 / 부정 비율)
## 긍정과 부정의 빈도수 측정 -> DataFrame으로 변환
df_sentiment_counts = df['sentiment'].value_counts().reset_index()
display(df_sentiment_counts)
print('-'*80)
## 시각화
fig1 = px.pie(data_frame=df_sentiment_counts,
names='sentiment',
values='count',
title='긍정과 부정의 비율',
hole=0.3)
fig1.show()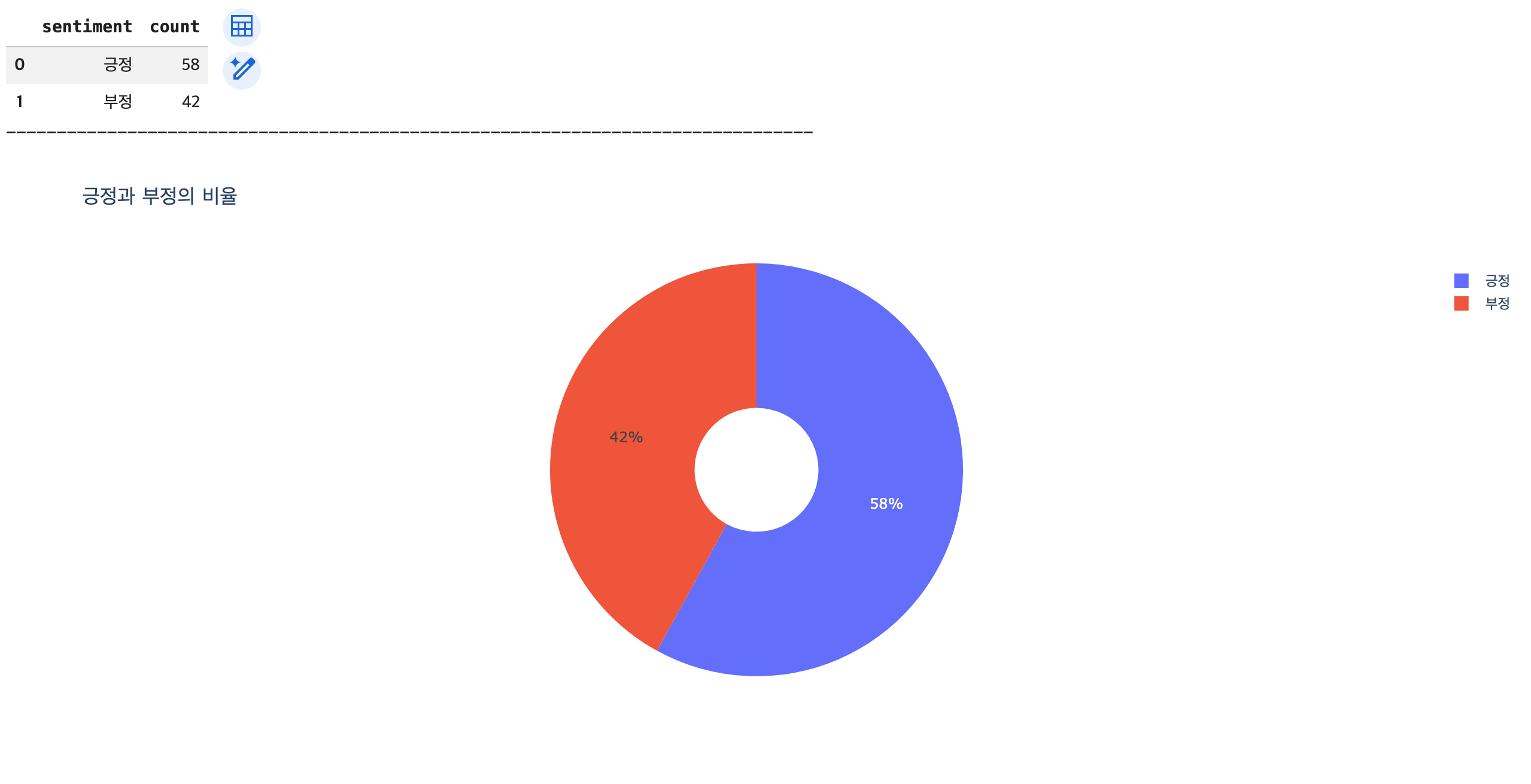
# 분석 목표: 채널별 평판 분석
## 마케팅 질문: "어떤 채널에서 부정적인 여론이 가장 많이 발생하고 있는가?"
## 채널별로 감성 분석의 결과 추출 -> DataFrame으로 변환
df_channel_sentiment = df.groupby(by='source')['sentiment'].value_counts(normalize=True).reset_index()
display(df_channel_sentiment)
print('-'*80)
## 시각화(수평 막대그래프)
fig2 = px.bar(data_frame=df_channel_sentiment,
x='proportion',
y='source',
color='sentiment',
barmode='group',
text_auto='.2f',
orientation='h',
title='채널별 감성 분포')
fig2.show()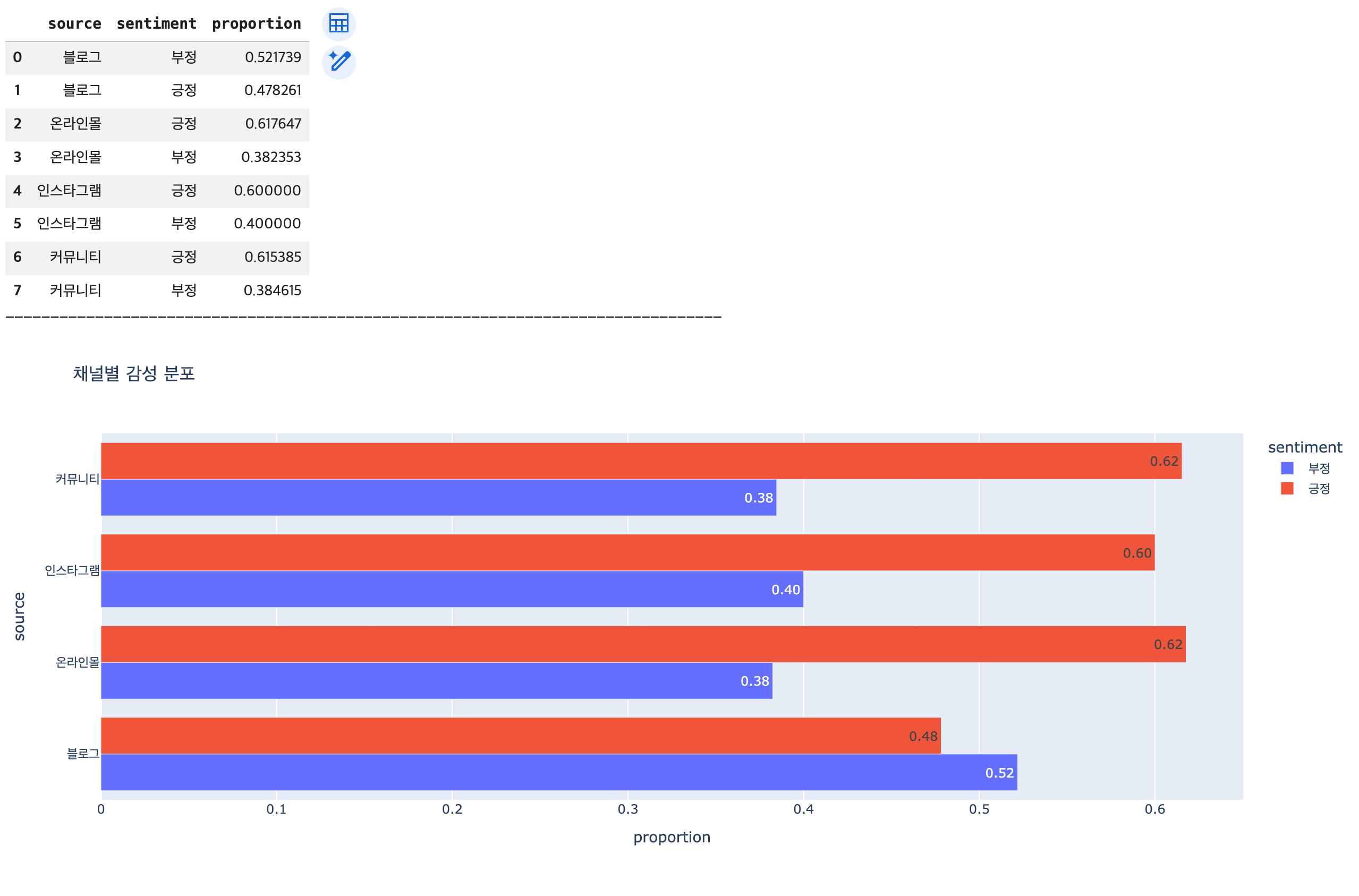
# 분석 목표: 월별 부정 리뷰 트렌드 분석
## 마케팅 질문: "최근 들어 부정적인 여론이 증가하고 있지는 않은가?"
## date 컬럼 -> datetime 자료형으로 변환
df['date'] = pd.to_datetime(df['date'])
display(df)
print('-'*80)
## data 컬럼 -> '월' 데이터 생성 및 새로운 컬럼 추가
df['month'] = df['date'].dt.month
display(df)
print('-'*80)
## 부정 데이터 추출
negative_reviews = df.query("sentiment == '부정'")
display(negative_reviews)
print('-'*80)
## 월별 부정 데이터의 수 추출 -> DataFrame으로 변환
monthly_negative_counts = negative_reviews.groupby(by='month').size().reset_index()
monthly_negative_counts.columns = ['month', 'count']
display(monthly_negative_counts)
print('-'*80)
## 시각화
"""
# 특정 월에 부정 리뷰가 급증했다면, 해당 시점의 제품/서비스 변경, 이벤트, 사회적 이슈 등을 교차 분석하여 원인을 파악해야 합니다.
"""
fig3 = px.line(data_frame=monthly_negative_counts,
x='month',
y='count')
fig3.show()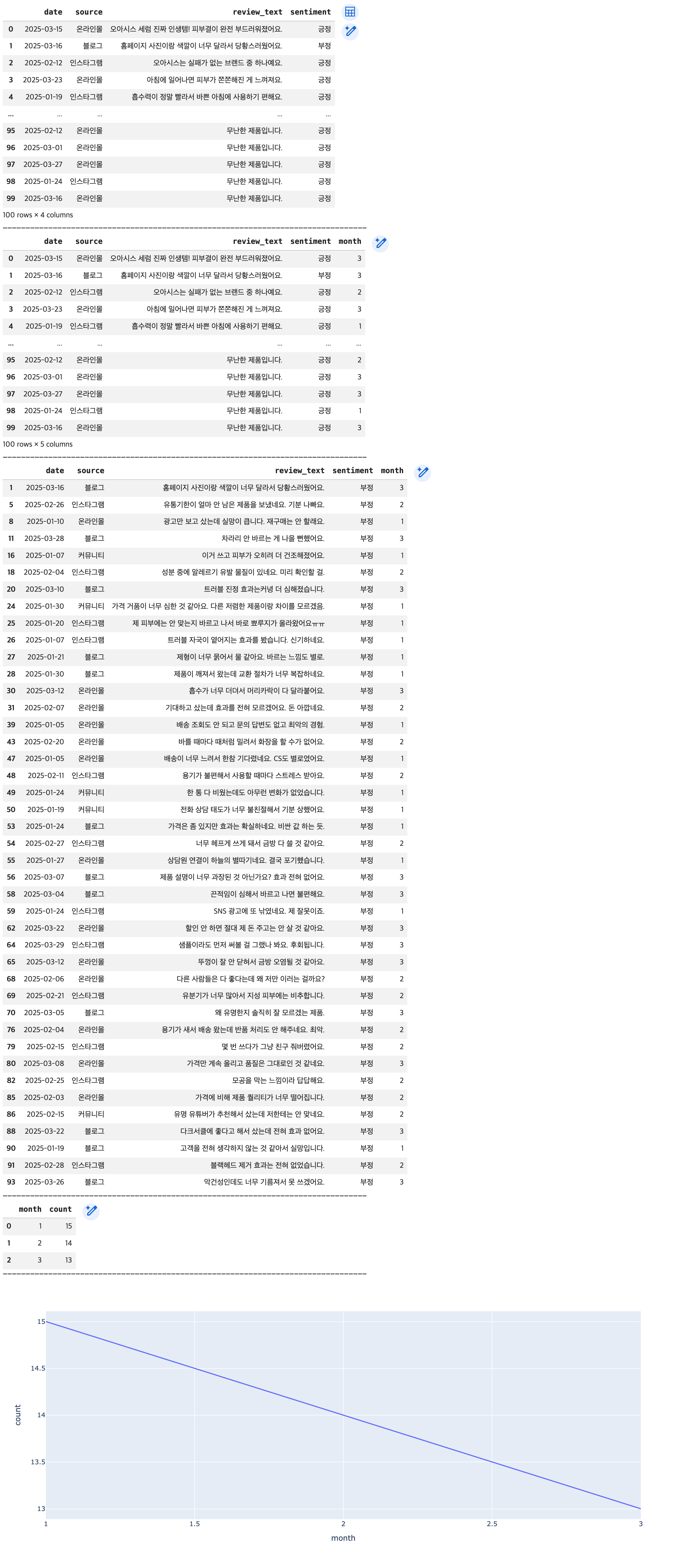
monthly_negative_counts = negative_reviews.groupby(by='month').size().reset_index()
display(monthly_negative_counts)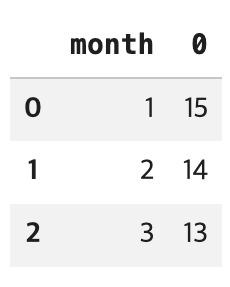
2026.05.14. 목요일
자연어 처리: 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 실습(2)
- 마켓컬리 특정 상품 정보 크롤링
- 분석
생성형 Al
- 무료 colab을 이용한 qwen3 사용법
- JSON 문자열
- qwen3를 사용한 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 실습
구조화된 바이브 코딩을 이용한 이커머스 고객 행동 분석 데이터 분석, 예측 및 보고서 작성 -> Slack DM으로 결과물 제출
[ 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 ]
- 마켓컬리 크롤링 데이터를 이용한 감성 분석 및 브랜드 평판 분석
# colab: 무료 gpu 사용 설정
# 필요한 라이브러리 / 함수 임포트
import pandas as pd
from transformers import pipeline
import plotly.express as px# 데이터 불러오기
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/kurly_reviews.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)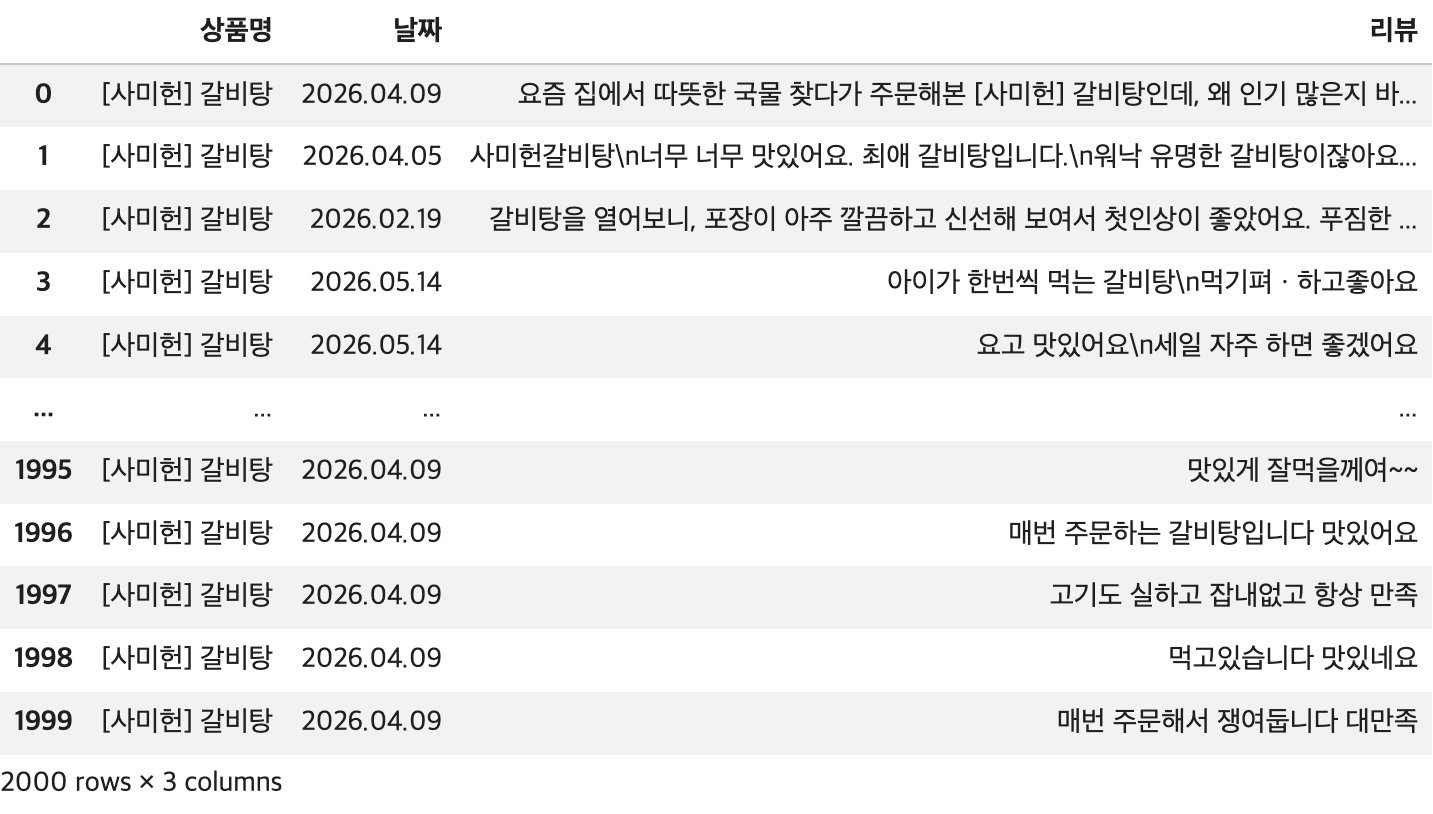
# 누락 데이터 확인
num_nulls = df.isnull().sum()
print(num_nulls)
# HuggingFace pipeline 함수를 이용하여 감성분석 all-in-one 모델 생성
sentiment_classifier = pipeline(
task='text-classification',
model='daekeun-ml/koelectra-small-v3-nsmc'
)# 전체 리뷰 데이터에 대한 감성 분석 적용 및 '레이블' 추출, 새로운 컬럼 추가
## '리뷰' 컬럼의 텍스트 -> 리스트로 변환
all_reviews = df['리뷰'].to_list()
print(all_reviews)
print('-'*80)
## 감성 분석 실행
sentiment_results = sentiment_classifier(all_reviews, truncation=True)
## 레이블 추출
label_list = []
for result in sentiment_results:
label = result.get('label')
if label == '1':
label = '긍정'
label_list.append(label)
else:
label = '부정'
label_list.append(label)
## 새로운 컬럼(sentiment) 추가
df['sentiment'] = pd.Series(label_list)
## 결과 확인
display(df)
# 분석 목표: 브랜드 평판 현황 (긍정 / 부정 비율)
## 긍정과 부정의 빈도수 측정 -> DataFrame 변환
df_sentiment_counts = df['sentiment'].value_counts().reset_index()
display(df_sentiment_counts)
print('-'*80)
## 시각화
fig1 = px.pie(data_frame=df_sentiment_counts,
names='sentiment',
values='count',
title='긍정과 부정의 비율')
fig1.show()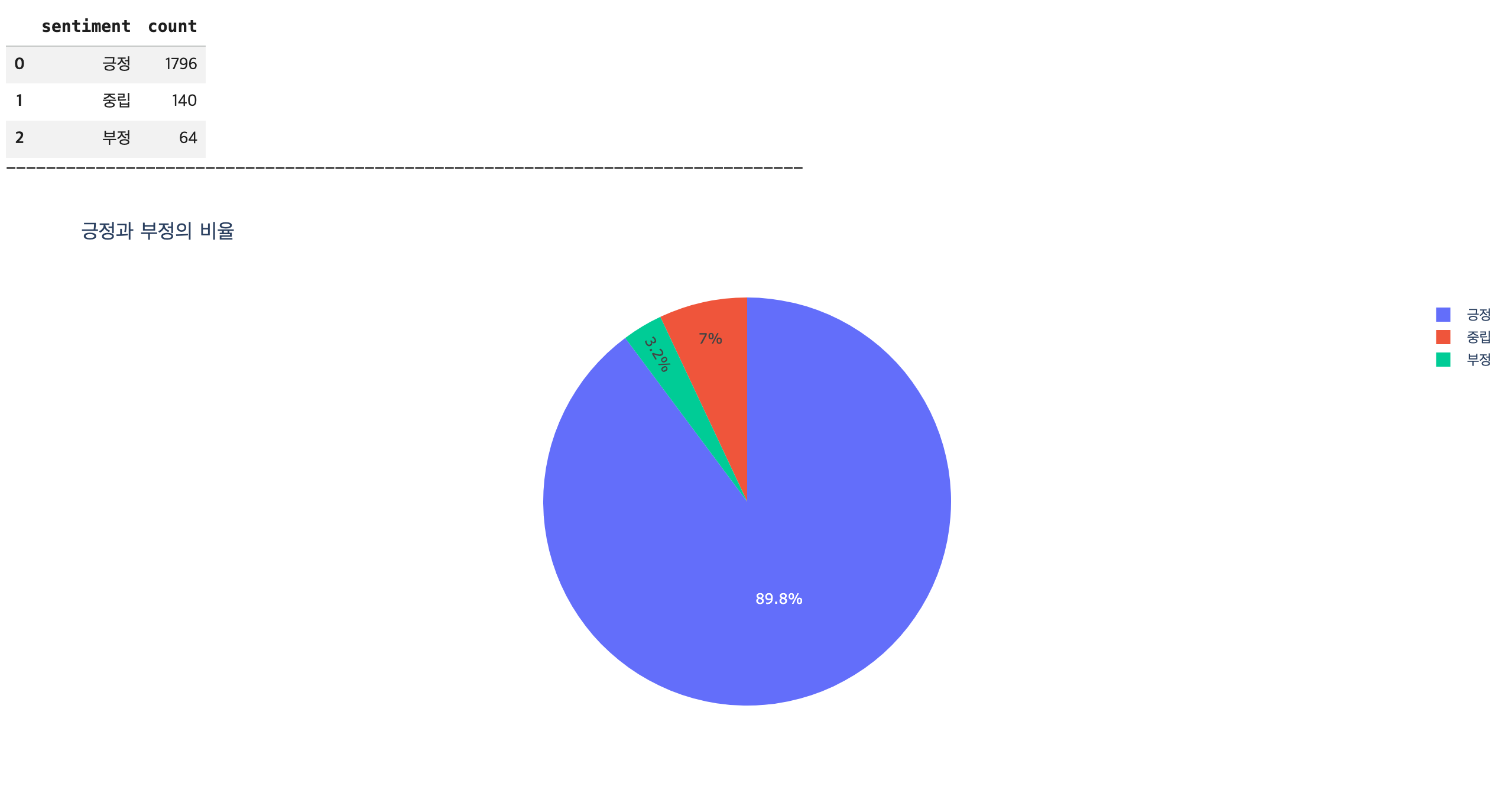
# 기본 정보 확인
df.info()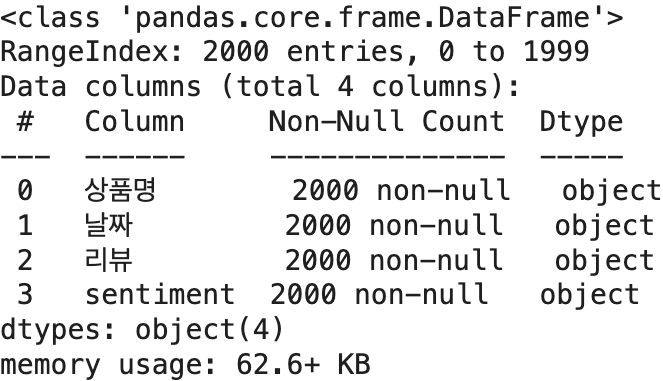
# 분석 목표: 월별 부정 리뷰 트렌드 분석
## 마케팅 질문: "최근 들어 부정적인 여론이 증가하고 있지는 않은가?"
## 날짜 컬럼 -> datetime 자료형으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
## date -> '월'데이터 생성 및 추가
df['month'] = df['날짜'].dt.month
## 월별 데이터의 수 추출
monthly_counts = df.groupby('month').size()
print(f'월별 데이터의 수: \n{monthly_counts}')
print('-'*80)
## 부정 데이터 추출
negative_reviews = df.query("sentiment == '부정'")
display(negative_reviews)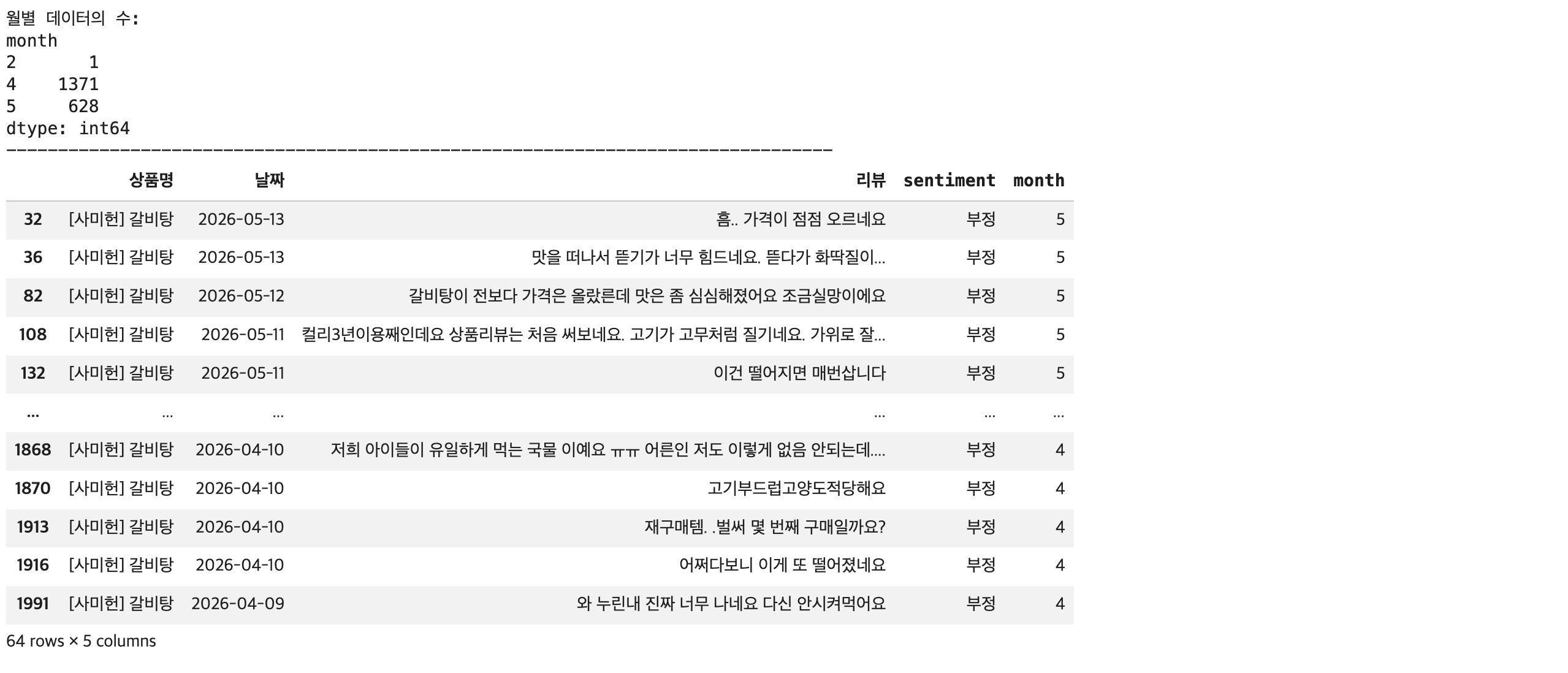
# 분석 목표: 월별 부정 리뷰 트렌드 분석
## 마케팅 질문: "최근 들어 부정적인 여론이 증가하고 있지는 않은가?"
## 날짜 컬럼 -> datetime 자료형으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
## date -> '월'데이터 생성 및 추가
df['month'] = df['날짜'].dt.month
## 월별 데이터의 수 추출
monthly_counts = df.groupby('month').size()
print(f'월별 데이터의 수: \n{monthly_counts}')
print('-'*80)
## 부정 데이터 추출
negative_reviews = df.query("sentiment == '부정'")
## 월별 부정 데이터의 수 추출 -> DataFrame으로 변환
monthly_negative_counts = negative_reviews.groupby('month').size().reset_index()
monthly_negative_counts.columns = ['month', 'count']
display(monthly_negative_counts)
print('-'*80)
## 시각화
"""
# 특정 월에 부정 리뷰가 급증했다면, 해당 시점의 제품/서비스 변경, 이벤트, 사회적 이슈 등을 교차 분석하여 원인을 파악해야 합니다.
"""
fig2 = px.line(data_frame=monthly_negative_counts,
x='month',
y='count')
fig2.show()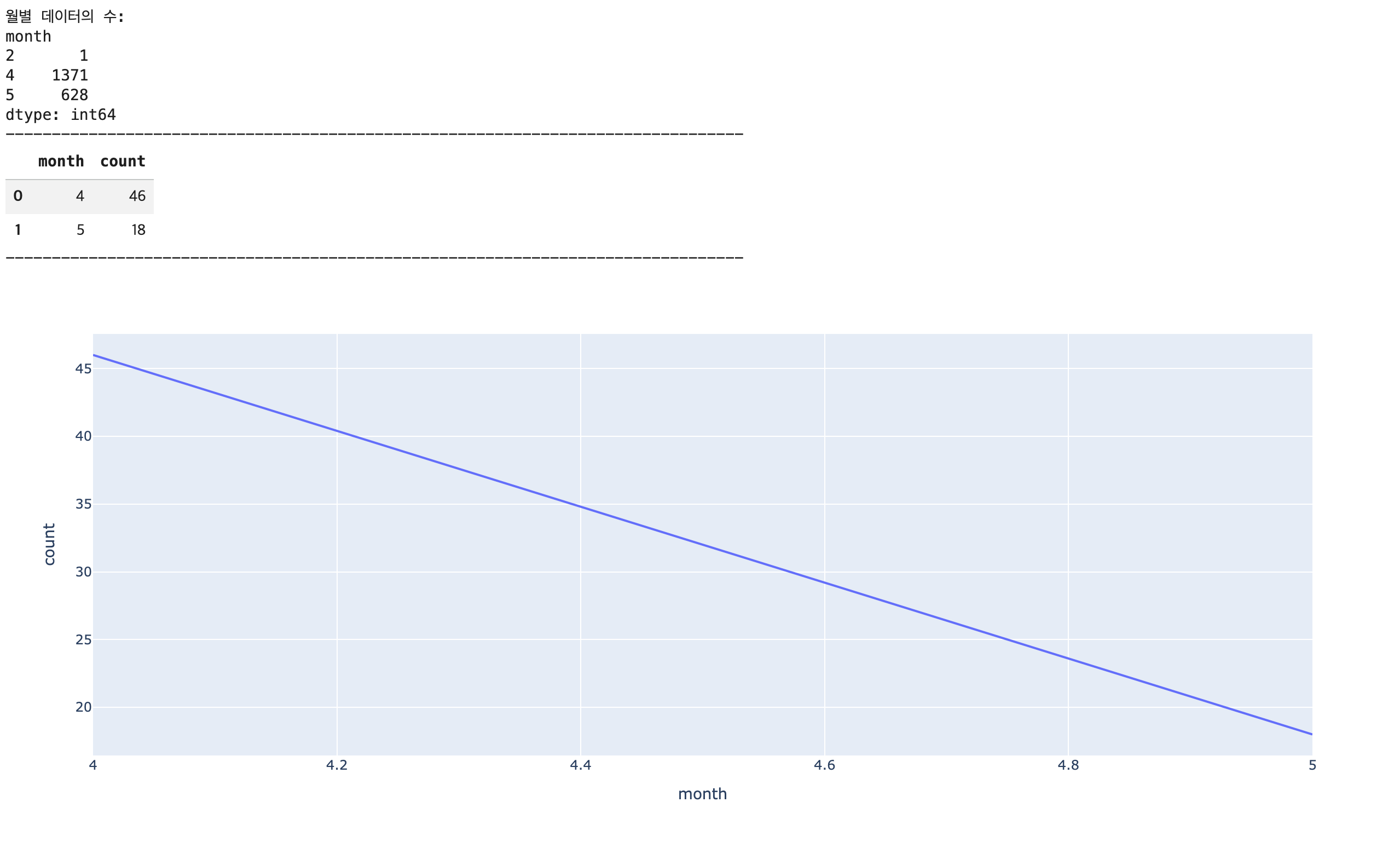
2026.05.15. 금요일
생성형 Al
- JSON 문자열 (교재 175 page)
- qwen3를 사용한 소셜 미디어 감성 분석을 통한 브랜드 평판 분석 실습
데이터분석심화_종합문제 정리
블랙 프라이데이 구매 예측 데이터 분석 및 구매액 예측
구조화된 바이브 코딩을 이용한 블랙 프라이데이 구매 예측 데이터 분석 및 보고서작성 -> Slack DM으로 결과물 제출
[ JSON 문자열을 python dict 자료형으로 변환하기 ]
# 필요한 모듈 임포트
import json
# JSON 문자열 생성
json_string = '{"name": "철수", "age": 25, "city": "Seoul"}'
print(json_string)
# json.loads() 호출, 딕셔너리로 변환
dict_data = json.loads(json_string)
print(f'자료형: {type(dict_data)}')
print('-'*80)
# name의 값 추출
value = dict_data['name']
print(f'name의 값: {value}')
[ qwen3를 이용한 감성 분석 ]
- 환경 설정
# colab: 무료 gpu 사용
# 필요한 라이브러리 설치
!pip install bitsandbytes# 필요한 라이브러리 / 함수 임폴트
import torch
from transformers import pipeline, BitsAndBytesConfig
# Qwen3 모델 -> pipeline 함수 적용
## 모델 이름 설정
model_name = "Qwen/Qwen3-4B-Instruct-2507"
## 4-bit 양자화를 위한 BitsAndBytesConfig 설정
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
## pipeline 함수 호출, 모델 생성 (4-bit 양자화로 Colab T4 GPU 최적화)
qwen3 = pipeline(
task="text-generation",
model=model_name,
device_map="auto",
model_kwargs={
"dtype": torch.bfloat16,
"quantization_config": quantization_config
}
)- qwen3 실행 함수 정의
# qwen3 실행 함수 정의
def get_completion(prompt):
messages = [
{"role": "system", "content": "당신은 한글로 된 고객 리뷰에 대한 경력 10년 이상의 우수한 감성 분석 전문가 입니다."},
{"role": "user", "content": prompt}
]
output = qwen3(messages, temperature=0.01, return_full_text=False)
return output[0]['generated_text']- 고객 리뷰 감성 분석
# 고객 리뷰 텍스트 및 prompt 생성
## 고객 리뷰 텍스트 생성
customer_review = """
바지 밑위가 길고 제 허벅지는 터져나가서 상의를 넣어 입고 가만있을 때 정면모습이 쪼금 애매한 주름이 지네요
그래도 착용감은 편안하고 밝은 바지인데도 부한 느낌도 없어서 마음에 들어요
크림진이 하나도 없어서 고민고민하다 구매했는데 이정도면 만족입니다
다만 허리에 있는 가죽패치가 검정이라 세탁시 이염될까봐 무서운거랑 바지밑단 주름이 좀 자글자글하게 지는 단점은 있어요!
"""
## 정답 예시 생성
example = "{'감성 분석 결과' : '긍정 또는 부정'}"
# user_prompt 생성
user_prompt = f"""한글로 작성된 고객 리뷰를 분석해서 정답 예시처럼 긍정인지 부정인지를 json 형식으로 제시해 주세요.
고객 리뷰:
{customer_review}
정답 예시:
{example}
"""
print(user_prompt)
# get_completion 함수 실행
response = get_completion(user_prompt)
print(response)
# qwen3의 답변 결과 분석 및 처리
## 필요한 모듈 임포트
import json
## 자료형 확인
print(f'qwen3 답변 자료형: {type(response)}')
print('-'*80)
## json 문자열 -> python dict 변환
dict_data = json.loads(response)
print(f'자료형: {type(dict_data)}')
print('-'*80)
## 감성 분석의 결과 추출
result = dict_data['감성 분석 결과']
print(result)
- 가상 데이터를 이용한 감성 분석
# colab과 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요한 라이브러리 임포트
import pandas as pd
# 데이터 불러오기
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/social_media_reviews.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)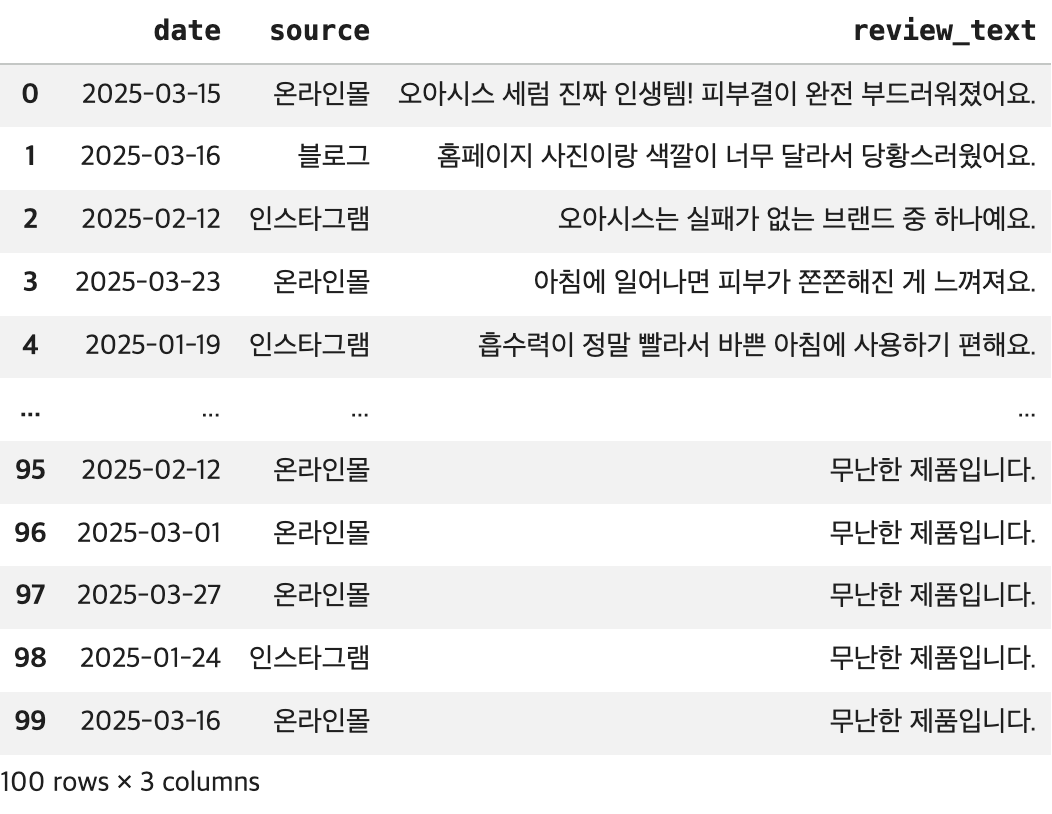
# 리뷰 데이터 추출
review_list = df['review_text'].to_list()
print(review_list)
print('-'*80)
# 상위 10개의 데이터 추출
reviews = review_list[0:10]
print(reviews)
# 상위 10개 리뷰 데이터에 대한 감성 분석 적용 및 '레이블' 추출
## 필요한 모듈 임포트
import json
## 감성 분석 결과 저장 리스트 생성
sentiment_results = []
## 감성 분석 실행: for문 + append()
for review in reviews:
### 프롬프트 작성
#### 정답 예시 생성
example = "{'감성 분석 결과' : '긍정 또는 부정'}"
#### user_prompt 생성
user_prompt = f"""한글로 작성된 고객 리뷰를 분석해서 정답 예시처럼 긍정인지 부정인지를 json 형식으로 제시해 주세요.
고객 리뷰:
{review}
정답 예시:
{example}
"""
output = get_completion(user_prompt)
### json 문자열을 파이썬 dict로 변환
dict_data = json.loads(output)
### 감성 분석 결과 추출
sentiment = dict_data['감성 분석 결과']
### 감성 분석 결과 저장
sentiment_results.append(sentiment)
## 분석 결과 확인
print(sentiment_results)
# 결과 확인
## 기존 DataFrame -> 상위 10개 슬라이싱
df1 = df[0:10]
display(df1)
print('-'*80)
## 새로운 컬럼(sentiment) 추가
df1['sentiment'] = pd.Series(sentiment_results)
display(df1)
- 마켓컬리 크롤링 데이터를 이용한 감성 분석
# 데이터 불러오기
## 파일 경로 설정
file_path='/content/drive/MyDrive/KDT/kurly_reviews.csv'
## DataFrame 생성
df = pd.read_csv(file_path)
## 결과 확인
display(df)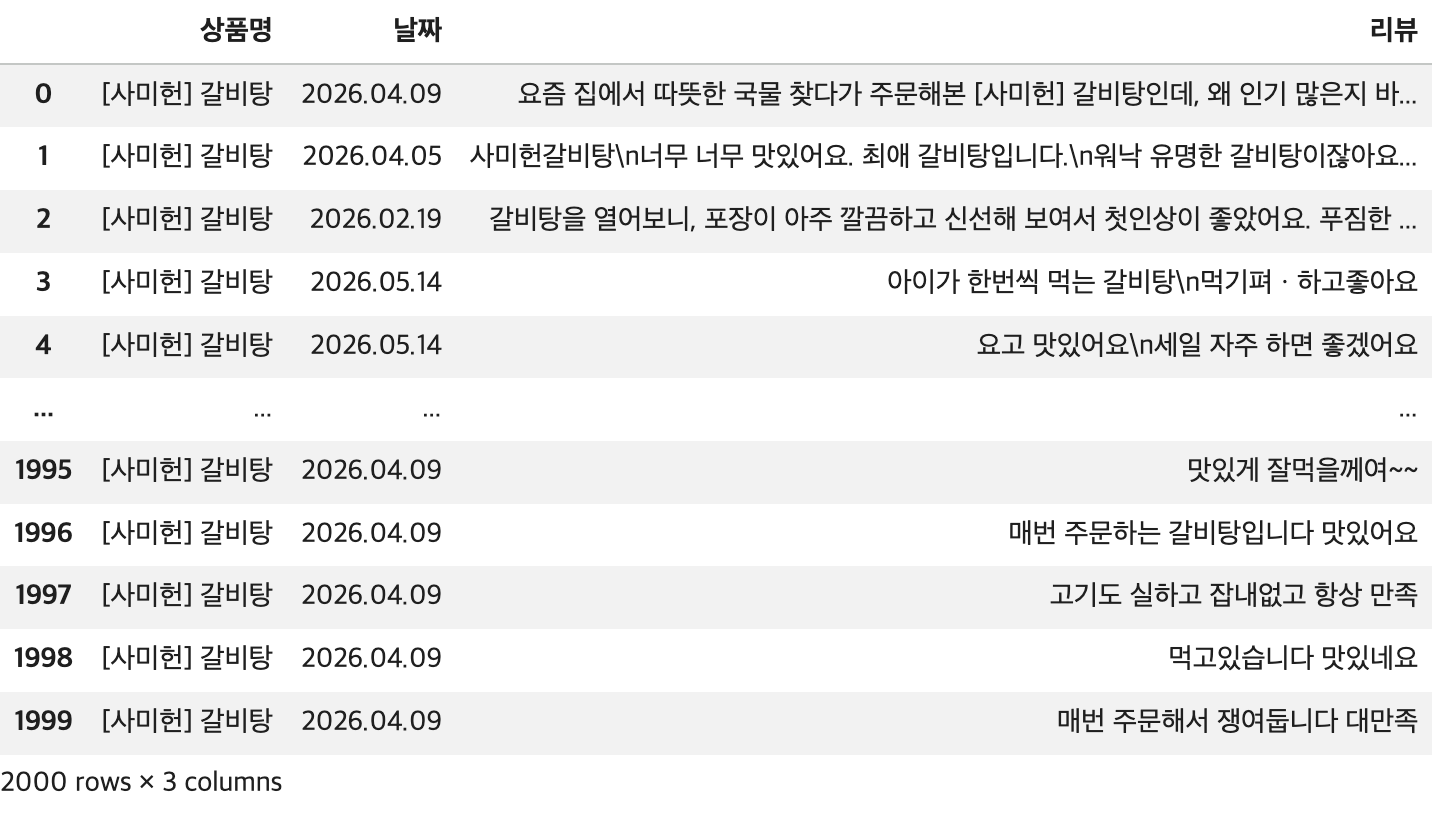
# 리뷰 데이터 추출
review_list = df['리뷰'].to_list()
print(review_list)
print('-'*80)
# 상위 60개의 데이터 추출
reviews = review_list[0:60]
print(reviews)
# 상위 60개 리뷰 데이터에 대한 감성 분석 적용 및 '레이블' 추출
## 필요한 모듈 임포트
import json
## 감성 분석 결과 저장 리스트 생성
sentiment_results = []
## 감성 분석 실행: for문 + append()
for review in reviews:
### 프롬프트 작성
#### 정답 예시 생성
example = "{'감성 분석 결과' : '긍정 또는 부정'}"
#### user_prompt 생성
user_prompt = f"""한글로 작성된 고객 리뷰를 분석해서 정답 예시처럼 긍정인지 부정인지를 json 형식으로 제시해 주세요.
고객 리뷰:
{review}
정답 예시:
{example}
"""
output = get_completion(user_prompt)
### json 문자열을 파이썬 dict로 변환
dict_data = json.loads(output)
### 감성 분석 결과 추출
sentiment = dict_data['감성 분석 결과']
### 감성 분석 결과 저장
sentiment_results.append(sentiment)
## 분석 결과 확인
print(sentiment_results)
# 결과 확인
## 기존 DataFrame -> 상위 60개 슬라이싱
df1 = df[0:60]
display(df1)
print('-'*80)
## 새로운 컬럼(sentiment) 추가
df1['sentiment'] = pd.Series(sentiment_results)
display(df1)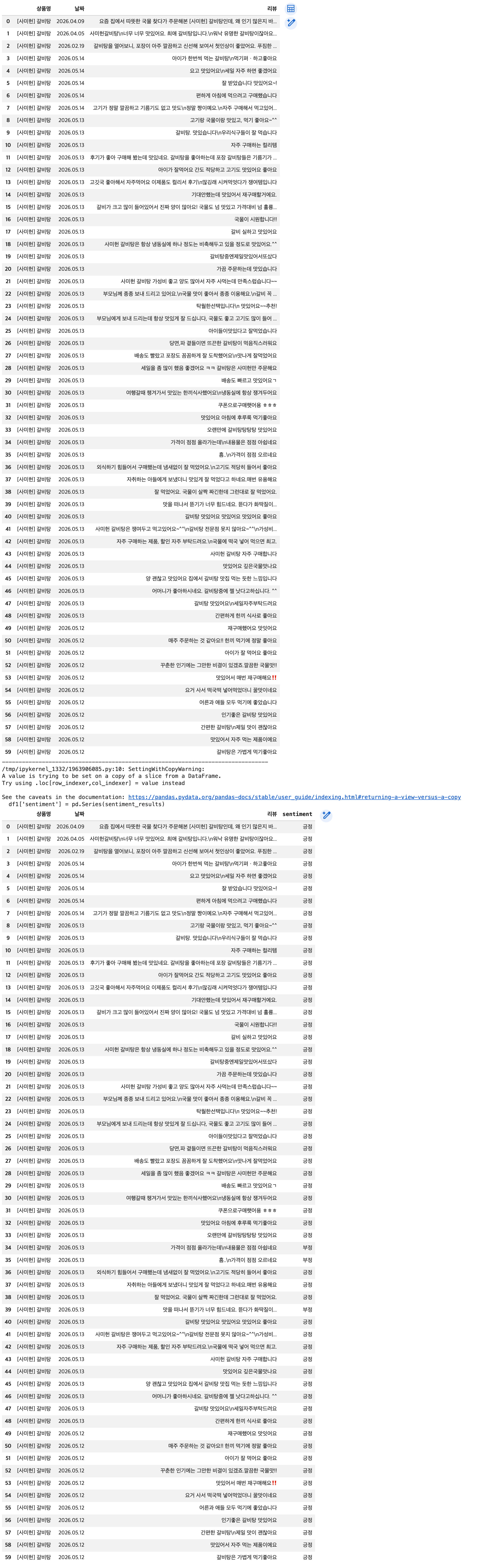
다음 주 수요일은 면접이고, 월요일엔 학교에 면접 컨설팅 받으러 갑니다..
거의 인생 첫 면접이라.. 너무 무서워요 😨😨

