시작하기 앞서 Colab을 너무 많이 사용해서 업그레이드 시켜줬다.
알아보니 런타임 종료시 업그레이드를 해야 다시 사용할 수 있지만,
계정을 여러개 돌려서 사용하면 된다.
1. 데이터 불러오기
# 내장된 데이터셋을 이 함수에서 로드할 수 있습니다
from tensorflow.keras.datasets import mnist
# MNIST 학습 및 테스트 데이터셋을 로드합니다
(x_train, y_train), (x_test, y_test) = mnist.load_data()
-
TensorFlow의 Keras 모듈에서 MNIST 데이터셋을 가져오기 위해 mnist를 임포트
-
MNIST 데이터셋을 로드하여 학습 데이터
(x_train, y_train)와 테스트 데이터(x_test, y_test)로 분리
: 학습 이미지 데이터 (28x28 픽셀 크기의 흑백 이미지가 60,000개)
y_train: 학습 이미지에 대한 레이블 (0부터 9까지의 숫자, 각 이미지가 어떤 숫자인지 나타냄)
x_test: 테스트 이미지 데이터 (28x28 픽셀 크기의 흑백 이미지가 10,000개)
y_test: 테스트 이미지에 대한 레이블
# GPU를 사용하고 있는지 확인합니다
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())현재 사용 가능한 로컬 장치 목록을 출력
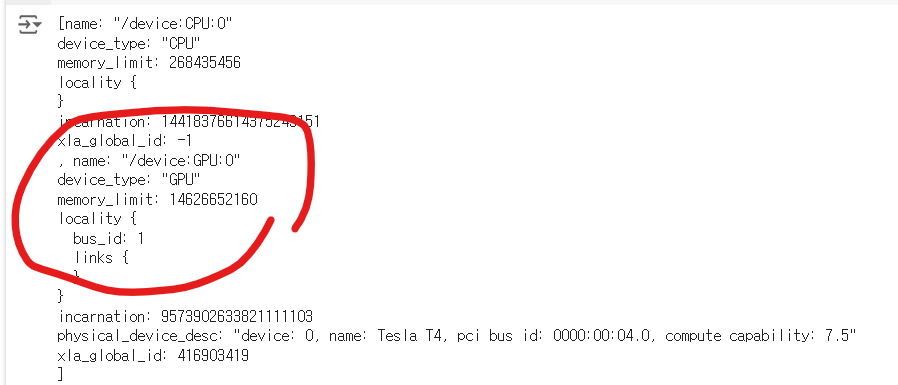
실행했을때, GPU가 저런식으로 구성돼있어야함
아니면 CPU로 동작하고 있는거니 변경
2. 데이터 세트 검사
말그대로 데이터 세트 검사로
PyTorch에서 데이터 검사를 했을때
Trainset 60000개 testset 100000개
(10000,28,28)
(60000,28,28)형태로 떳던것을 기억이난다.
# 학습 데이터(x_train)의 초기 형태 또는 차원을 출력합니다
print("Initial shape or dimensions of x_train", str(x_train.shape))
# 데이터 샘플의 개수를 출력합니다
print("Number of samples in our training data: " + str(len(x_train)))
print("Number of labels in our training data: " + str(len(y_train)))
print("Number of samples in our test data: " + str(len(x_test)))
print("Number of labels in our test data: " + str(len(y_test)))
# 학습 및 테스트 데이터의 이미지 차원과 레이블 개수를 출력합니다
print("\n")
print("Dimensions of x_train:" + str(x_train[0].shape))
print("Labels in x_train:" + str(y_train.shape))
print("\n")
print("Dimensions of x_test:" + str(x_test[0].shape))
print("Labels in y_test:" + str(y_test.shape))
익숙한 맛의 숫자들

3. 이미지 데이터 세트 시각화
숫자를 출력해서 보자는 뜻
무작위 숫자 6개를 가져온다. x_train에서
x_train은 학습이미지 데이터이므로 숫자를 보여줄것
# OpenCV와 NumPy를 임포트합니다
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 이미지를 화면에 표시하는 함수 정의
def imshow(title, image = None, size = 6):
if image.any(): # 이미지가 존재하는 경우
w, h = image.shape[0], image.shape[1] # 이미지의 높이와 너비를 가져옴
aspect_ratio = w/h # 가로세로 비율 계산
plt.figure(figsize=(size * aspect_ratio, size)) # 이미지 비율에 맞게 그림 크기 설정
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # 이미지를 BGR에서 RGB로 변환하여 표시
plt.title(title) # 제목 설정
plt.show() # 이미지 출력
else:
print("Image not found") # 이미지가 없는 경우 메시지 출력
# OpenCV를 사용하여 데이터셋에서 무작위로 선택한 6개의 이미지를 표시
for i in range(0, 6):
random_num = np.random.randint(0, len(x_train)) # 데이터셋에서 무작위 인덱스 선택
img = x_train[random_num] # 무작위로 선택한 인덱스의 이미지 가져오기
imshow("Sample", img, size = 2) # 이미지를 화면에 표시

3개 생략
랜덤으로 가져온것으로 규칙성은 없다.
이미지 50개 출력
# MNIST 학습 데이터셋의 처음 50개 이미지를 시각화합니다
import matplotlib.pyplot as plt
# 그림을 생성하고 크기를 변경합니다
figure = plt.figure()
plt.figure(figsize=(16, 10)) # 그림 크기를 가로 16인치, 세로 10인치로 설정
# 표시할 이미지의 개수를 설정합니다
num_of_images = 50
# 1부터 50까지 인덱스를 반복합니다
for index in range(1, num_of_images + 1):
plt.subplot(5, 10, index).set_title(f'{y_train[index]}') # 5행 10열의 서브플롯에 각 이미지의 레이블을 제목으로 설정
plt.axis('off') # 축을 끕니다
plt.imshow(x_train[index], cmap='gray_r') # 이미지를 'gray_r' 컬러맵을 사용하여 흑백으로 표시

전과 다르게 숫자위에 제목이 붙었다.
코드를 확인하니 y_train 값인데
이건 labels값이라 똑같을 것이다.
4. 데이터 세트 전처리
훈련을 위해 CNN에 데이터를 전달하기 전에 먼저 데이터를 준비해야한다.
- 4차원을 추가하여 데이터 재구성
(60000, 28, 28)을 (60000, 28, 28, 1)로 바꾼다는건데,
Keras에서 필요한 '형태'로 데이터를 변경해 줘야한다.
- uint8에서 float32로 데이터 유형 변경
정규화 할때, 픽셀 값을 0에서 255 사이의 정수에서 0에서 1 사이의 실수로 변환하는데,
이 과정에서 float32 타입이 필요하다.
- 데이터를 0에서 1 사이의 값으로 정규화
데이터는 신경망 학습의 안정성을 높이고 학습 속도를 빠르게 할 수 있다
- One hot encoding
?
# 이미지의 행과 열 수를 저장합니다
img_rows = x_train[0].shape[0]
img_cols = x_train[0].shape[1]
# Keras에서 필요한 '형태'로 데이터를 맞춥니다
# 데이터에 4번째 차원을 추가하여 (60000, 28, 28) 형태의 원래 이미지 모양을 (60000, 28, 28, 1)로 변경합니다
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
# 단일 이미지의 형태를 저장합니다
input_shape = (img_rows, img_cols, 1)
# 이미지 데이터를 float32 데이터 타입으로 변경합니다 (원래는 uint8)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 데이터를 정규화하여 범위를 (0에서 255)에서 (0에서 1)로 변경합니다
x_train /= 255.0
x_test /= 255.0
# 전처리된 데이터의 형태를 출력합니다
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')


이미지 행과 열 제대로 저장했는지 출력 테스트
아까 One Hot Encoding이 있었는데 뭔말인지 몰라서 예제를 돌렸다.
One Hot Encode Our Labels
from tensorflow.keras.utils import to_categorical
# 이제 출력값을 원-핫 인코딩합니다
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 원-핫 인코딩된 행렬의 열 수를 셉니다
print("Number of Classes: " + str(y_test.shape[1]))
# 클래스 수를 저장합니다
num_classes = y_test.shape[1]
# 이미지의 총 픽셀 수를 저장합니다
num_pixels = x_train.shape[1] * x_train.shape[2]
원 핫 인코딩의 예제라고 나와있는데,

4,5,2,6 이라는 라벨을 핫 인코딩 했을때,
0~9 숫자 중 1로 표시한다는 것 같다.
또 Number of Classes 가 10인걸 보아 0~9까지의 숫자를 클래스로 나타낸것 같고
실제로 열의 개수를 세는 코드가 있다.
# 원-핫 인코딩된 행렬의 열 수를 셉니다
print("Number of Classes: " + str(y_test.shape[1]))y_train[0] 은 학습 데이터셋 중의 첫번째 숫자의 이름이다

y_train과 y_test는 위에서 핫 인코딩을 했으므로
이제부터 값이 변경돼서 출력될것이다.
6번째가 1이니까 값은 5가 되겠다.
모델 빌드는 다음 글에서 진행~
