5. 모델 빌드
또 이 CNN을 빌드를 할건데,
텐서플로우랑 케라스를 사용해서 빌드를 한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import SGD라이브러리는 요래 있다.
와중에 Dense가 뭔지 몰라 검색

Dense는 평탄화 다음 층인데
평탄화된 벡터를 입력으로 받아 분류 작업을 수행하고,
사용예시
Dense(128, activation='relu'): 중간에 있는 완전 연결 층.
Dense(10, activation='softmax'): 최종 출력 층, 각 클래스에 대한 확률을 출력
사용예시를 보니 FC1과 FC2를 포함한 것이 Dense 인것 같다.

지피티에게 물어보니까 중간(FC1)과 최종(FC2) 두개를 알려줬다.
모델 코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import SGD
# 모델 생성
model = Sequential()
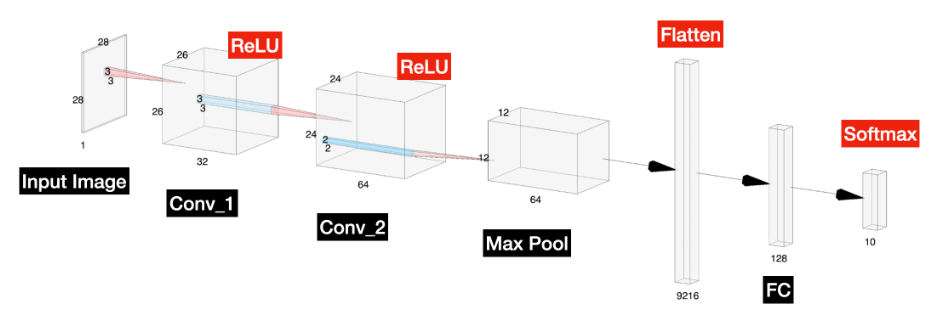
# 첫 번째 합성곱 층, 필터 크기는 32로 층 크기를 26 x 26 x 32로 줄입니다.
# ReLU 활성화 함수를 사용하고 입력 형태는 28 x 28 x 1로 지정합니다.
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
# 두 번째 합성곱 층, 필터 크기는 64로 층 크기를 24 x 24 x 64로 줄입니다.
model.add(Conv2D(64, (3, 3), activation='relu'))
# MaxPooling을 사용하여 커널 크기 2 x 2로 크기를 12 x 12 x 64로 줄입니다.
model.add(MaxPooling2D(pool_size=(2, 2)))
# Dense 층에 입력하기 전에 텐서 객체를 평탄화합니다.
# 텐서를 평탄화하면 텐서에 포함된 요소 수에 해당하는 형태로 텐서가 재구성됩니다.
# CNN에서는 12 * 12 * 64에서 9216 * 1로 변환됩니다.
model.add(Flatten())
# 이 층을 크기 1 * 128의 완전 연결(Dense) 층에 연결합니다.
model.add(Dense(128, activation='relu'))
# 최종 완전 연결(Dense) 층을 각 클래스(10개)에 대한 출력으로 생성합니다.
model.add(Dense(num_classes, activation='softmax'))
# 모델을 컴파일합니다. 이는 우리가 방금 생성한 모델을 저장하는 객체를 만듭니다.
# 옵티마이저로 확률적 경사 하강법(SGD, 학습률 0.001)을 사용합니다.
# 손실 함수는 다중 클래스 문제에 적합한 categorical_crossentropy로 설정합니다.
# 마지막으로, 성능을 평가할 메트릭으로 정확도를 설정합니다.
model.compile(loss='categorical_crossentropy',
optimizer=SGD(0.001),
metrics=['accuracy'])
# summary 함수를 사용하여 모델의 층과 매개변수를 표시할 수 있습니다.
print(model.summary())

결과를 보면
Sequential 모델의 요약 정보로
앞에 None이 붙어있는데 Keras 라이브러리를 사용하기 위해
형식을 맞춰주려고 붙여준 차원이라,
실제로는 사용과 연산하지 않는부분이라
초기화 될때 None으로 출력된다.
- conv2d (Conv2D):
Output Shape: (None, 26, 26, 32)
입력 이미지 크기 28x28에서 3x3 필터를 적용하여 26x26 크기로 축소되고, 32개의 필터를 사용합니다.
Param #: 320
계산: (331+1)*32 = 320 (필터 크기 3x3, 입력 채널 1, 바이어스 1, 필터 수 32)
- conv2d_1 (Conv2D):
Output Shape: (None, 24, 24, 64)
이전 레이어의 출력 크기 26x26에서 3x3 필터를 적용하여 24x24 크기로 축소되고, 64개의 필터를 사용합니다.
Param #: 18496
계산: (3332+1)*64 = 18496 (필터 크기 3x3, 입력 채널 32, 바이어스 1, 필터 수 64)
- max_pooling2d (MaxPooling2D):
Output Shape: (None, 12, 12, 64)
2x2 풀링을 적용하여 크기가 12x12로 축소됩니다.
Param #: 0
MaxPooling 레이어는 학습 가능한 파라미터가 없습니다.
- flatten (Flatten):
Output Shape: (None, 9216)
12x12x64의 출력 텐서를 1D 벡터로 평탄화합니다.
Param #: 0
Flatten 레이어는 학습 가능한 파라미터가 없습니다.
- dense (Dense):
Output Shape: (None, 128)
9216개의 입력을 받아 128개의 뉴런으로 출력합니다.
Param #: 1179776
계산: 9216*128 + 128 = 1179776 (입력 9216, 출력 뉴런 128, 바이어스 128)
- dense_1 (Dense):
Output Shape: (None, 10)
128개의 입력을 받아 10개의 뉴런(클래스)으로 출력합니다.
Param #: 1290
계산: 128*10 + 10 = 1290 (입력 128, 출력 뉴런 10, 바이어스 10)
- 총 파라미터
Total params: 1,199,882 (모델의 총 파라미터 수)
Trainable params: 1,199,882 (학습 가능한 파라미터 수)
Non-trainable params: 0 (학습 불가능한 파라미터 수 없음)
y_test.shape
이것의 결과를 찍어보면 어떻게 나올까
앞서 y_train과 함께 핫 인코딩을 하였기때문에
(라벨이 개수, 0~9) 로 출력이 될 것이다.
(10000, 10)

모델 코드 주석 삭제
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import SGD
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = SGD(0.001),
metrics = ['accuracy'])역시 간결하다.
하지만 주석이 없었더라면 이해하는데 오랜 시간이 걸렸다.
