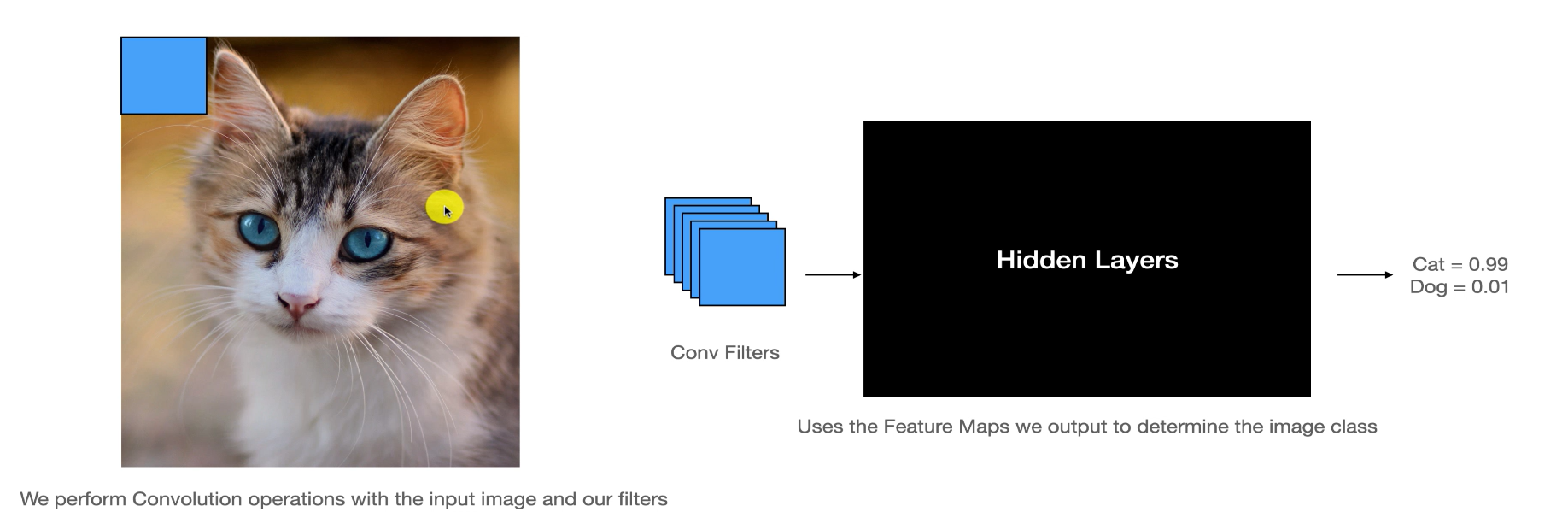
매번 언급되지만 고양이인것을 보자마자 인식한다.
사람은 본능적으로 패턴을 보고 우리뇌는 자기도 모르게 절단면에서 보이는 작은 특징을 결합해서
자동으로 그걸 절단면과 연관 짓는다.

위 사진처럼 필터들이 input image를 돌아다니면서 연산을 한다.
다시 고양이로 오면
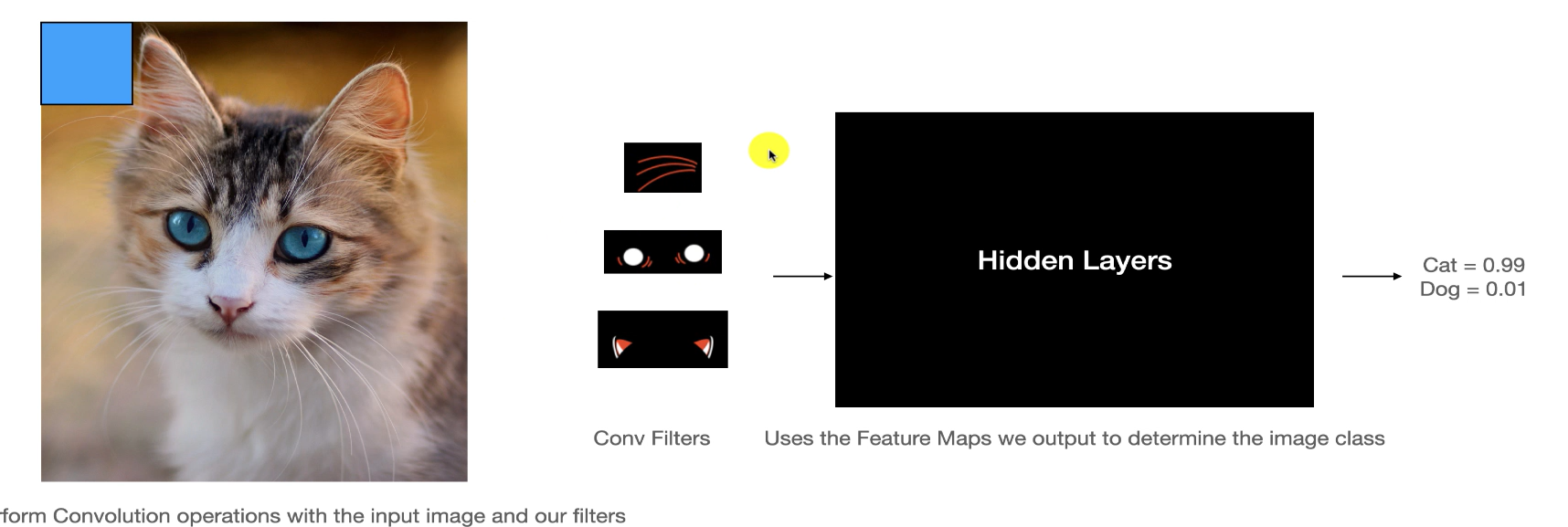
그 필터들이, 수염,눈,귀라고 생각하고 눈의 내용을 담고있는 필터가 input Image(고양이)의 모든 부분을 돌면서 연산을 하고
생성된 기능맵들을 학습된 모델(블랙박스)이 판단해서 확률을 출력해낸다.
기준을 정해주지 않고 학습시킨 모델이라 사람이 안의
내용을 모른다해서 블랙박스 라는 이름이 붙었다.
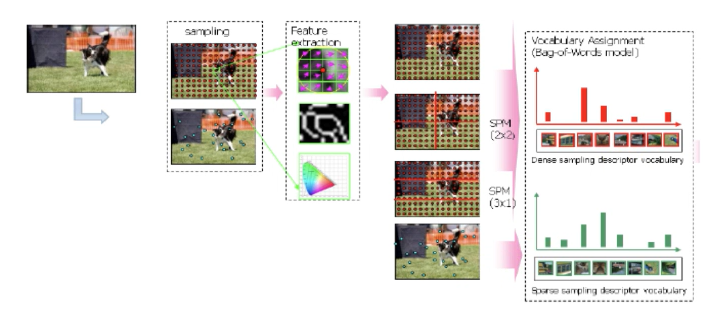
그런데 이 전통적인 방법은 사람이 수동으로 특징을 만들어내는 "hand-crafted features"를 사용했기에
이미지에 대한 다양한 특징을 설명하기 위해 많은 수의 시행착오가 필요했다.
조명이나 각도, 클래스 구분과 같은 이미지의 변화가 큰 경우에는 제한적이여서
OCR과 같이 변화가 적은 작업에는 잘 작동했지만, 다른 유형의 이미지나 데이터셋으로 확장하기는 어려웠기에
수동 특징 생성은 보통 성능이 좋지 않다.
CNN은 이 문제를 해결하기 위해 특징을 자동으로 학습할 수 있는 능력을 제공한다.
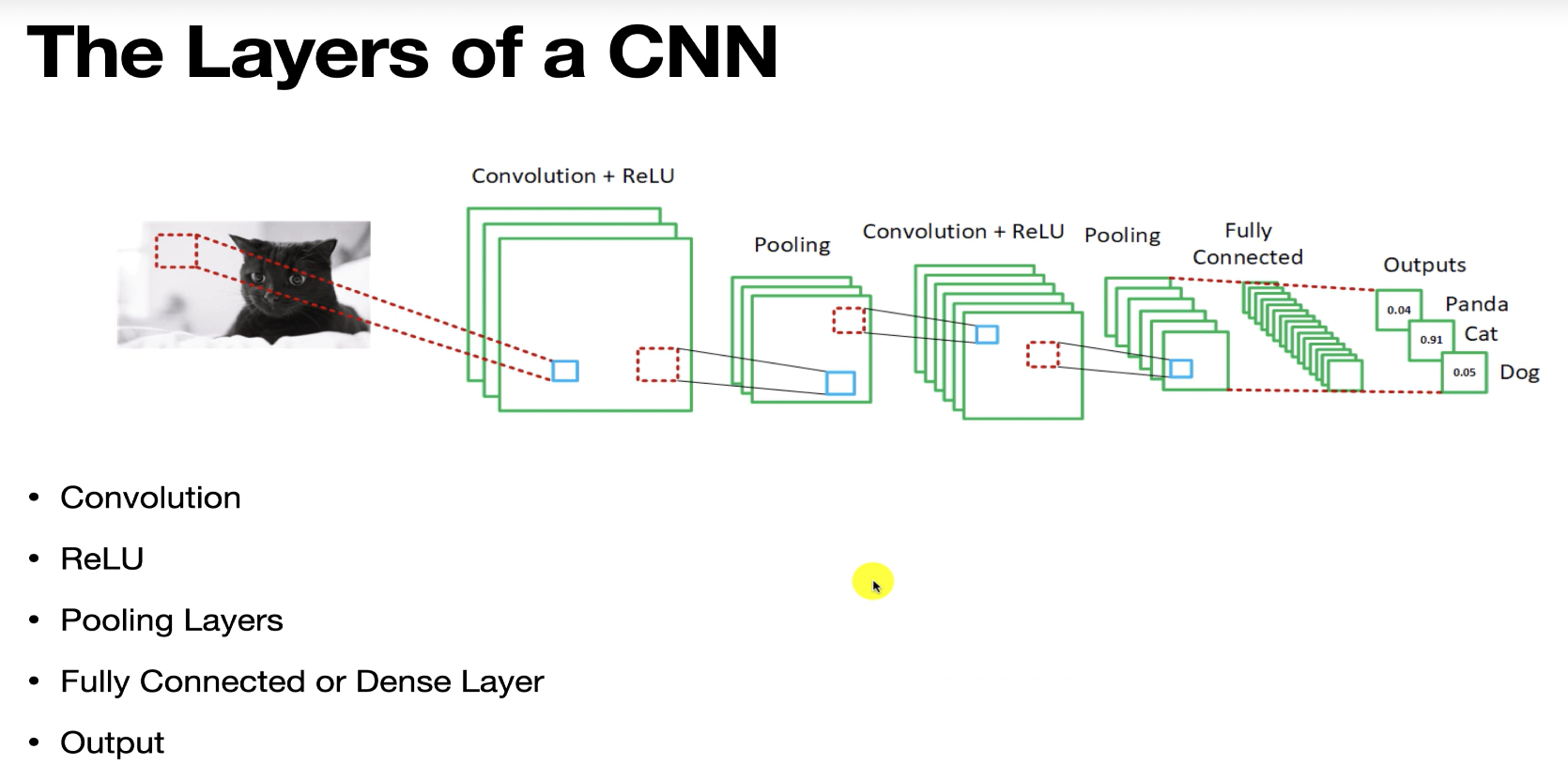
CNN은 데이터로부터 특징을 추출하고 학습하기 때문에,
사전에 정의된 특징을 수동으로 만들어내는 것보다 훨씬 뛰어난 결과를 얻을 수 있다.

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w