모델을 훈련할 때 데이터셋을 두 개 또는 세 개의 부분으로 나누어야 한다.

모델을 훈련할 때 사용하는 데이터는 훈련 데이터(train 데이터 셋, x_train)이다.
모델은 이 데이터를 보고 학습한다.
그러나 모델이 훈련 데이터만 학습하고 실제로 보지 못한
새로운 데이터를 제대로 처리하지 못하는 상황이 발생할 수 있다.
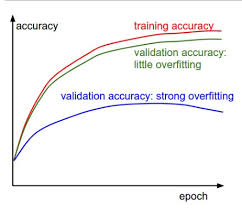
즉, 훈련 데이터에서는 매우 잘 작동하지만 새로운 데이터를 보면 성능이 매우 나쁜 모델이 될 수 있다. -> 과적합(overfitting)
트페이닝 프로세스 예제

이미지들을 네트워크에 통과시키고, 손실을 계산한 후, 기울기 하강법(Gradient Descent)을 사용하여 가중치를 최적화한다.
이 과정이 하나의 에포크 동안 일어나며, 그 후 검증 데이터셋으로 손실과 정확도를 측정하여 모델 성능을 평가하는 것이다.
이러한 과정을 여러 에포크 동안 반복하며, 일반적으로 50 에포크가 많이 알려져있다.

딥러닝 네트워크 훈련 시의 최선의 방법으로
훈련이 끝나면, 모델을 보지 않은 테스트 데이터셋으로 테스트하여 최종 손실과 정확도를 평가한다.
이미지에서는 초록색 부분의 Val 부분이다.

마지막 에포크까지 학습과 검증을 마쳤으면 실제로 만들어진 데이터로 테스트를 진행한다.

기본 성능 지표
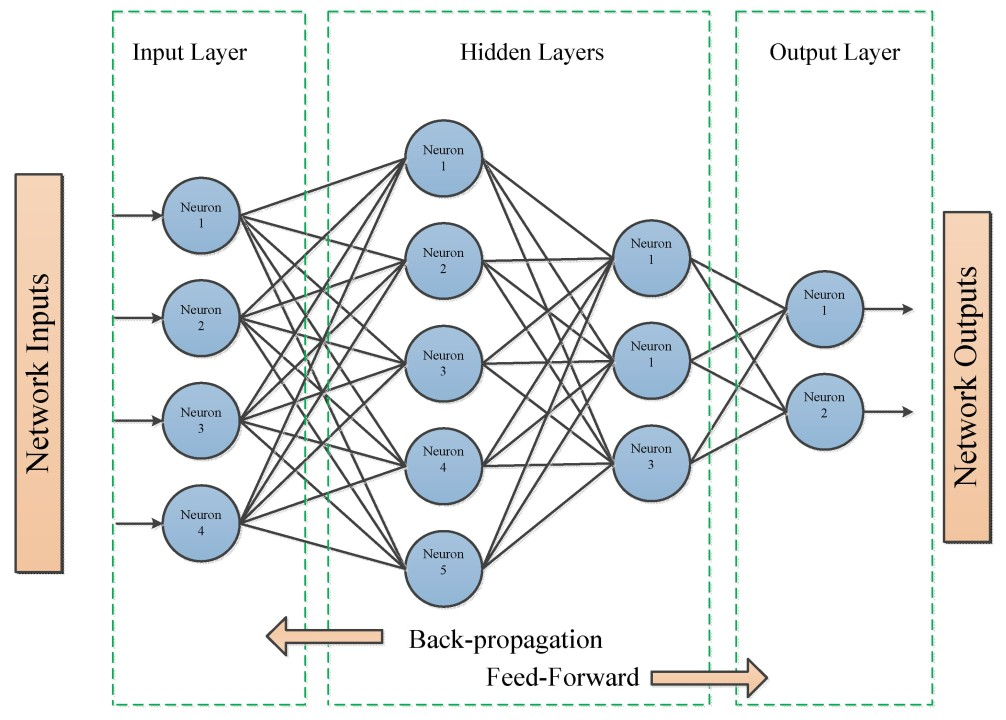
1. 역전파(Backpropagation)
역전파(Backpropagation)를 사용하여 모델을 업데이트할 때, 훈련 손실(Training Loss)을 사용한다.
역전파는 체인 룰을 적용하여 네트워크의 가중치를 업데이트한다.
(훈련손실 : 훈련 손실은 첫 번째 지표로, 네트워크 훈련 중에 모델 성능을 측정하는 방법)
2. 훈련 정확도(Training Accuracy)
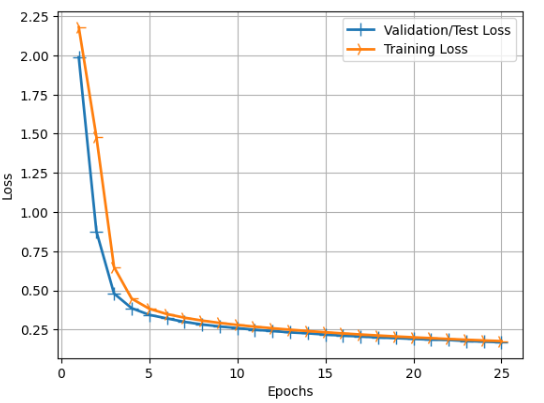
3. 테스트 또는 검증 손실(Test/Validation Loss)
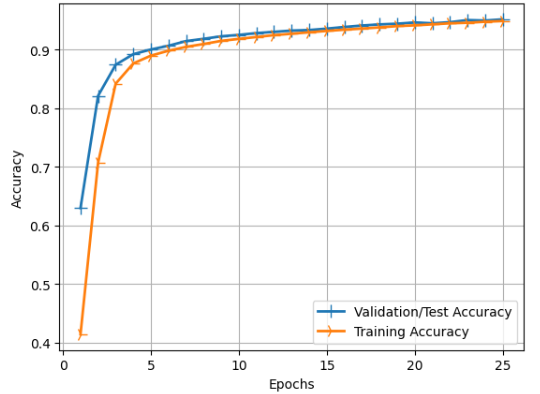
4. 테스트 또는 검증 정확도(Test/Validation Accuracy)
예측 실패
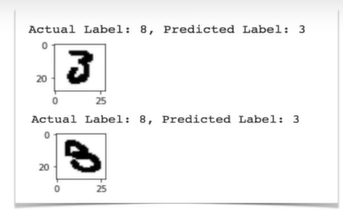
예를 들어, 손으로 쓴 숫자 모델이 숫자 '3'과 '8'을 잘못 예측하는 문제가 있다.
단순히 정확도를 통해서는 이런 문제를 파악할 수 없다.
이런 경우 혼동 행렬(Confusion Matrix)과
분류 보고서(Classification Report)가 필요하다.
이는 모델의 예측 오류를 상세히 분석할 수 있는 도구들이다.
