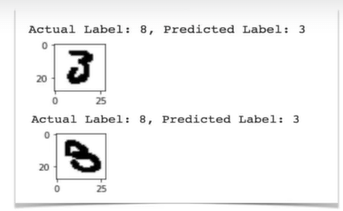
저번에 이런 정확도가 높아도 예측이 실패하는 경우가 있다.
이런 경우에 모델의 예측 오류를 상세히 분석할 수 있는 도구들을 사용한다.
혼동 행렬(Confusion Matrix)
분류 보고서(Classification Report)
1. 혼동 행렬(Confusion Matrix)
범주형 출력값을 가지는 분류 모델에서 사용된다.
주로 테스트 데이터셋에서 수행되지만, 훈련 데이터셋에서도 사용할 수 있다.
그러나 훈련 데이터셋에서 수행하는 것은 별로 의미가 없다.
모델의 성능을 실제로 보기 위해서는 보지 못한 데이터인 테스트 데이터셋에서 수행하는 것이 중요
혼동 행렬을 생성하기 위해서는 두 개의 입력 인수
- 실제 라벨(테스트 라벨)
- 예측된 라벨(모델에 X 테스트 데이터를 입력하고 얻은 예측 값)
MNIST 혼동 행렬 예제


위에 모델로 예측한 라벨과 실제 라벨이 있다.
대각선에 큰 숫자가 있을 경우 모델이 잘 작동하고 있다는 의미한다.
예를 들어, (0,0)에 있는 973은 실제로 0인 데이터를 모델이 973번 올바르게 예측했음을 의미한다.
대각선 외의 숫자는 모델이 잘못 예측한 횟수를 나타낸다.

예를 들어, 실제로 0인 데이터를 모델이 2번 2로 잘못 예측했음을 의미
다시 대각선을 보면
각각 1000개 정도로 10묶음으로 10000개이다.
얼추 test 데이터 셋의 개수랑 같다.

이제 위의 행렬을 어떻게 해석하는지 이해했으니
대각선이 아닌 큰 값을 작게 만들어주는 작업을 해야한다.
이진 분류 문제
이진 분류 문제에서는 네 가지 가능한 결과가 있다.

- 진짜 음성(True Negative)
- 거짓 양성(False Positive)
- 거짓 음성(False Negative)
- 진짜 양성(True Positive)
혼동 행렬은 이 네 가지 결과를 시각화하는 데 유용
정확도(Accuracy): (진짜 양성 + 진짜 음성) / 전체 샘플 수.
오분류율(Error Rate): 1 - 정확도.
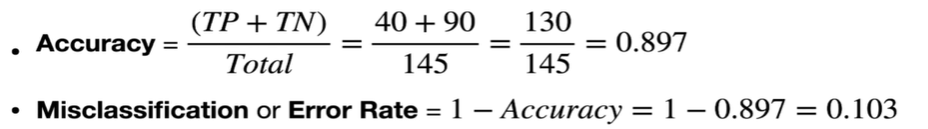
재현율(Recall): (진짜 양성) / (진짜 양성 + 거짓 음성).
실제로 긍정인 경우, 모델이 얼마나 자주 올바르게 예측하는지를 나타낸다.
정밀도(Precision): (진짜 양성) / (진짜 양성 + 거짓 양성).
모델이 긍정으로 예측한 경우, 얼마나 자주 올바른지를 나타낸다.
F1 점수: 정밀도와 재현율의 조화 평균
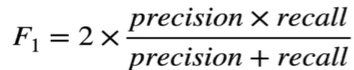
2. 분류 보고서
분류 보고서는 각 클래스에 대해 정밀도, 재현율, F1 점수, 지원(Support)을 제공
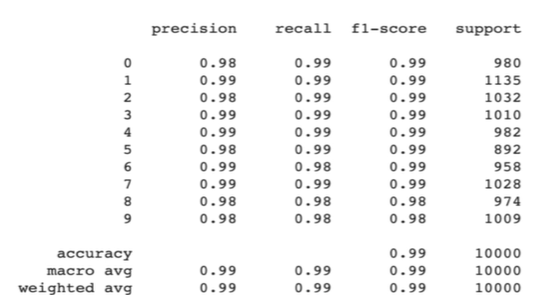
지원은 각 클래스의 샘플 수를 나타내며, 중요한 지표는 아니지만 클래스의 비율을 파악하는 데 유용하다.
