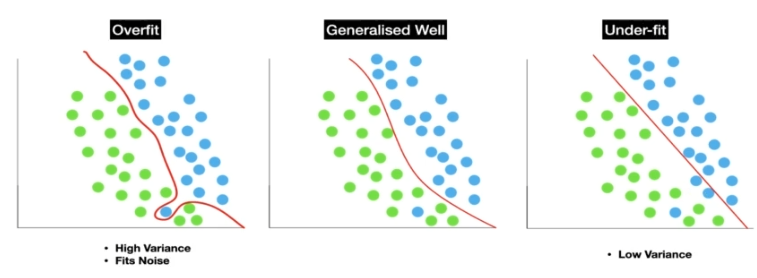
과적합 및 일반화
여태 학습을 하면서 나왔던 과적합 및 일반화에 대해서 다루어보자.
정의
과적합 - Overfitting
과적합은 모델이 훈련 데이터에 너무 맞춰져 있어서 테스트 데이터나 검증 데이터에서는 성능이 저하되는 현상
거북이만 잡다가 토끼를 잡으려고 할때 대처법을 모르는 상황
이는 충분한 데이터가 없거나, 너무 많은 특징을 사용했거나, 과도하게 복잡한 모델을 만든 경우에 발생한다.
일반화 - Generalization
일반화는 모델이 보지 못한 데이터에 대해 얼마나 잘 수행하는지를 나타내는 척도
과적합된 모델은 훈련 데이터에 대해서는 잘 수행하지만, 새로운 데이터에 대해서는 성능이 저하되는데,
이는 일반화가 잘되지 않은 것을 의미한다.
모델이 많은 정보를 학습하면 더 정확해질 수 있지만, 불필요한 특징을 저장할 위험도 있음
예시 설명
1. 색깔을 사용한 구분 문제:
모델이 자동차와 소방차 이미지를 학습한다고 가정

만약 모델이 빨간색을 사용하여 소방차를 구분하게 되면, 빨간색 자동차를 소방차로 잘못 분류할 수 있다.

이는 모델이 잘못된 특징(빨간색)을 학습한 예로, 충분한 데이터가 없거나 너무 복잡한 모델을 사용한 경우에 발생할 수 있다.
2. 모델의 결정 경계:
세 가지 모델이 있고, 녹색과 파란색 클래스를 구분하도록 훈련됐다.
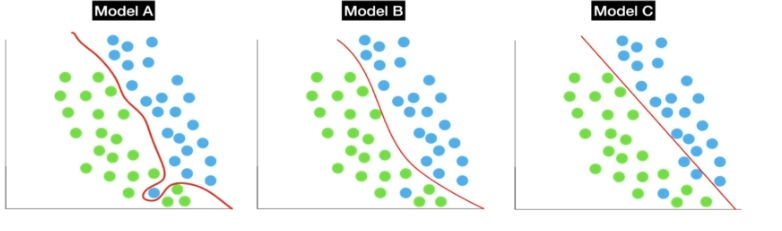
모델 A:
매우 복잡한 결정 경계를 가지고 있어 과적합될 가능성이 크다.
모델 B:
적절한 복잡성을 가지고 있으며, 좋은 성능을 보인다.
모델 C:
너무 단순한 결정 경계를 가지고 있어 일반화가 잘 되지 않는다.
그렇다면 이 모델에서 가장 좋은 모델이라고 불릴수 있는것은?
Model B
세 개의 모델을 보면
성능 평가(Training Accuracy vs Test Accuracy)
문제 : 학습(training) 정확도는 매우 좋지만, test 정확도는 안좋을때
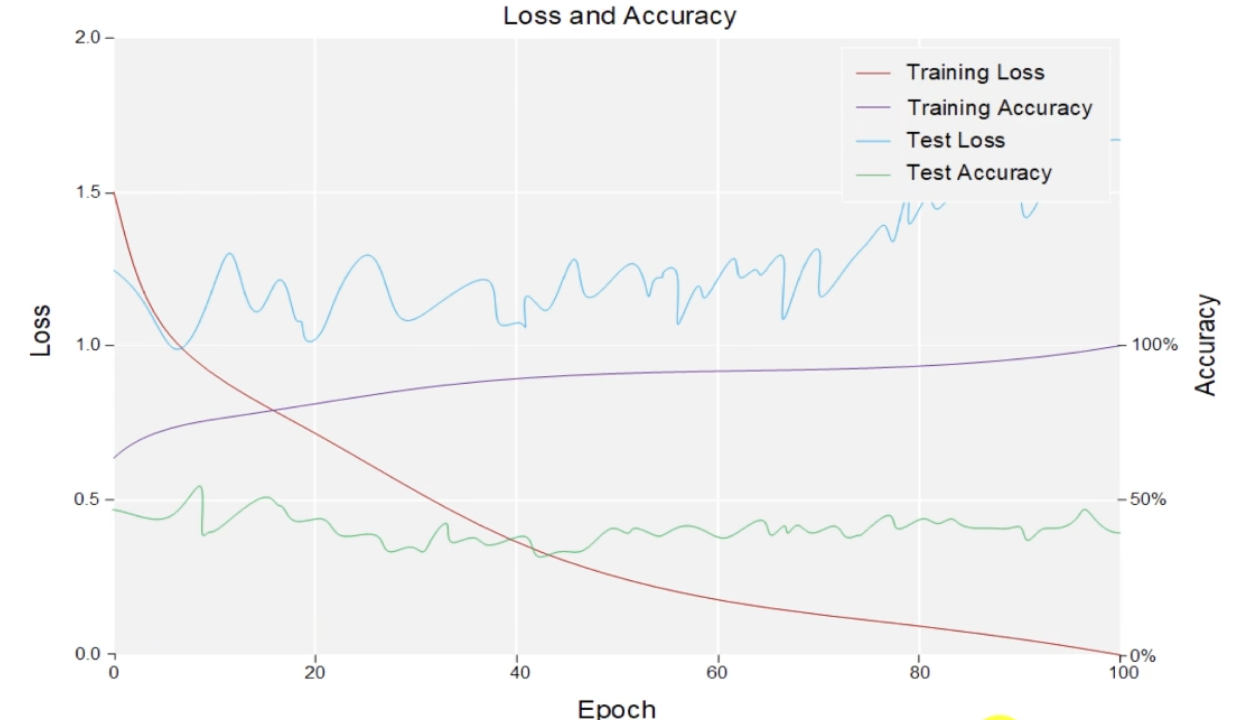
훈련 데이터에서 매우 높은 성능을 보이지만, 테스트 데이터에서 성능이 저하된다 ? > 과적합 의심
예를 들어, 훈련 정확도가 100%에 가까운데 테스트 정확도가 낮다면 과적합이 발생한 것
과적합 방지 방법
-
데이터 양 늘리기
더 많은 데이터를 사용하면 모델이 더 일반화될 가능성이 높아진다. -
모델 복잡도 줄이기
너무 복잡한 모델을 사용하면 과적합될 수 있다. 모델의 복잡도를 줄여야 한다. -
정규화
모델의 복잡성을 줄이고, 적절한 특징을 사용하도록 돕는 다양한 기법을 사용한다.

잘못학습한 예시

예시로 들은 강아지와 튀긴 치킨 사진은 모델이 잘못 학습한 예를 보여준다.
모델이 강아지 사진에 있는 풀이나 나무를 특징으로 학습하면, 풀이나 나무가 있는 다른 이미지를 강아지로 잘못 예측할 수 있다.
이는 모델이 잘못된 특징을 학습한 사례로, 모델의 신뢰성을 떨어뜨릴 수 있다.
결론
딥러닝 모델의 성능을 평가할 때는 과적합과 일반화에 주의해야하며
모델의 성능을 최적화하려면 충분한 데이터, 적절한 복잡도의 모델, 그리고 적절한 정규화 기법을 사용해야 한다.
다음 내용에는 모델의 일반화를 돕는 정규화 기법들에 대해 다루겠다.
