저번 CNN 25에서는 Keras로 만든 모델을 분석 및 해석했다.
이번에는 맨 처음에 PyTorch로 만들었던 모델의 분석
1. PyTorch 모델 및 데이터 설정.
# PyTorch를 임포트합니다.
import torch
# torchvision을 사용하여 데이터셋을 가져오고 유용한 이미지 변환을 수행합니다.
import torchvision
import torchvision.transforms as transforms
# PyTorch의 최적화 라이브러리와 nn을 임포트합니다.
# nn은 네트워크 그래프의 기본 구성 요소로 사용됩니다.
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
# GPU를 사용하고 있는지 확인합니다.
print("GPU 사용 가능 여부: {}".format(torch.cuda.is_available()))
# 장치를 cuda로 설정합니다.
device = 'cuda'
모델을 불러 오기전에 다시한번 CUDA에 대해서 확인하자.
CUDA(Compute Unified Device Architecture)
한글로 번역하면 "통합 디바이스 아키텍처 계산"이며
GPU를 활용하여 연산 집약적인 작업을 더 빠르게 처리한다.
MNIST Test Dataset 로드
MNIST 테스트 데이터를 텐서로 변환하고 정규화한 후, 배치 단위로 로드하여
모델 평가에 사용한다.
# Transform to a PyTorch tensors and the normalize our valeus between -1 and +1
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, )) ])
# Load our Test Data and specify what transform to use when loading
testset = torchvision.datasets.MNIST('mnist',
train = False,
download = True,
transform = transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size = 128,
shuffle = False,
num_workers = 0)모델 정의 클래스 만들기
# 네트워크 모델을 정의하는 클래스를 생성합니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 첫 번째 합성곱 계층: 입력 채널 1, 출력 채널 32, 커널 크기 3x3
self.conv1 = nn.Conv2d(1, 32, 3)
# 두 번째 합성곱 계층: 입력 채널 32, 출력 채널 64, 커널 크기 3x3
self.conv2 = nn.Conv2d(32, 64, 3)
# 맥스 풀링 계층: 커널 크기 2x2, 스트라이드 2
self.pool = nn.MaxPool2d(2, 2)
# 첫 번째 완전 연결 계층: 입력 크기 64 * 12 * 12, 출력 크기 128
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# 두 번째 완전 연결 계층: 입력 크기 128, 출력 크기 10
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 첫 번째 합성곱 계층을 적용하고 ReLU 활성화 함수를 적용합니다.
x = F.relu(self.conv1(x))
# 두 번째 합성곱 계층을 적용하고 ReLU 활성화 함수를 적용한 후 맥스 풀링을 수행합니다.
x = self.pool(F.relu(self.conv2(x)))
# 텐서를 펼쳐서 일렬로 만듭니다 (배치 크기, 64 * 12 * 12).
x = x.view(-1, 64 * 12 * 12)
# 첫 번째 완전 연결 계층을 적용하고 ReLU 활성화 함수를 적용합니다.
x = F.relu(self.fc1(x))
# 두 번째 완전 연결 계층을 적용합니다.
x = self.fc2(x)
return x
2. Model 불러오기
!gdown --id 1yj01iUbYL8ZXHiYRE5Xd639tddSAkzKsPyTorch로 만든 모델을 드라이브에 저장해놨다
실행하면 마운트에 모델이 저장된다.

모델 사용법
모델을 로드할 때 모델 인스턴스,
즉 net = Net()을 생성한 다음 Colab에서 GPU를 사용하여 학습했기 때문에
net.to (device = 'cuda'인 장치)를 사용하여 GPU로 이동한다.
그러니까 GPU로 이동해서 모델의 빈 자리를 만들고
그 자리에 우리가 사용할 모델을 넣어주는것
# 모델 인스턴스를 생성합니다.
net = Net()
# 모델을 CUDA 장치로 이동시킵니다.
net.to(device)
# 지정된 경로에서 모델 가중치를 로드합니다.
net.load_state_dict(torch.load('mnist_cnn_net.pth'))
일치하는 모든 키가 성공적으로 표시되면 Model Loaded successfully.

정확도 계산
테스트 데이터셋에 대해 모델의 정확도를 계산
# 정확도와 총 개수를 초기화합니다.
correct = 0
total = 0
# Gradient 계산을 비활성화합니다.
with torch.no_grad():
for data in testloader:
images, labels = data
# 데이터를 GPU로 이동시킵니다.
images = images.to(device)
labels = labels.to(device)
# 모델을 사용하여 예측합니다.
outputs = net(images)
# 각 이미지에 대한 예측된 클래스를 가져옵니다.
_, predicted = torch.max(outputs.data, 1)
# 총 라벨의 개수를 업데이트합니다.
total += labels.size(0)
# 예측이 올바른지 확인하여 올바른 예측 개수를 업데이트합니다.
correct += (predicted == labels).sum().item()
# 정확도를 계산합니다.
accuracy = 100 * correct / total
print(f'10000개의 테스트 이미지에 대한 네트워크의 정확도: {accuracy:.3f}%')
testloader 에서 데이터를 배치 단위로 가져오고,
데이터를 GPU로 이동 후 모델을 사용하여 이미지를 예측
올바른 라벨과 그릇된 라벨 예측결과를 분석하여 정확도를 계산

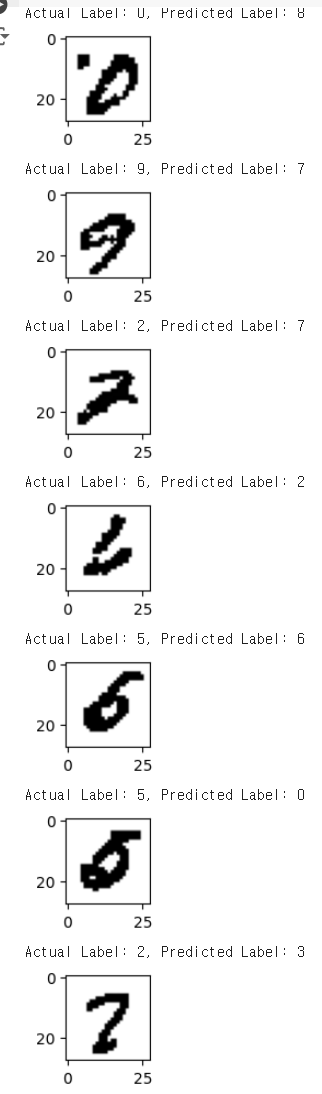
3. 잘못 분류(예측)된 이미지 표시
# 모델을 평가 또는 추론 모드로 설정합니다.
net.eval()
# 검증에는 기울기가 필요하지 않으므로 no_grad로 메모리를 절약합니다.
with torch.no_grad():
for data in testloader:
images, labels = data
# 데이터를 GPU로 이동시킵니다.
images = images.to(device)
labels = labels.to(device)
# 모델의 출력을 가져옵니다.
outputs = net(images)
# torch.argmax()를 사용하여 예측값을 가져옵니다. argmax는 long_tensors에 사용됩니다.
predictions = torch.argmax(outputs, dim=1)
# 각 배치의 테스트 데이터에 대해 예측이 라벨과 일치하지 않는 경우를 확인합니다.
# 일치하지 않는 경우 실제 라벨을 출력합니다.
for i in range(data[0].shape[0]):
pred = predictions[i].item()
label = labels[i].item()
if label != pred:
print(f'실제 라벨: {label}, 예측된 라벨: {pred}')
img = images[i].cpu().numpy().reshape(28, 28)
plt.imshow(img, cmap='gray')
plt.title(f'Actual: {label}, Predicted: {pred}')
plt.show()
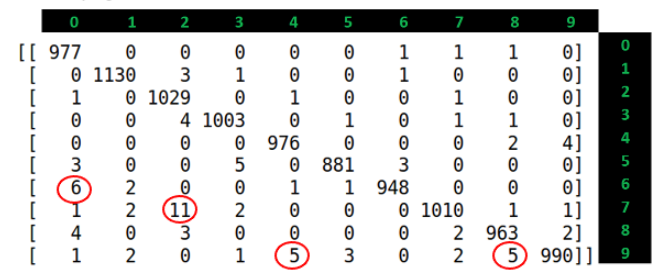
4. Confusion Matrix 생성
이 과정에서는 저번에도 말했듯
1. 실제 라벨, 2.예측 라벨
이 두가지가 필요하다
from sklearn.metrics import confusion_matrix
import torch
# 예측과 라벨을 저장할 빈 텐서를 초기화합니다.
pred_list = torch.zeros(0, dtype=torch.long, device='cpu')
label_list = torch.zeros(0, dtype=torch.long, device='cpu')
with torch.no_grad():
for i, (inputs, classes) in enumerate(testloader):
inputs = inputs.to(device)
classes = classes.to(device)
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
# 배치 예측 결과를 추가합니다.
pred_list = torch.cat([pred_list, preds.view(-1).cpu()])
label_list = torch.cat([label_list, classes.view(-1).cpu()])
# 혼동 행렬 생성
conf_mat = confusion_matrix(label_list.numpy(), pred_list.numpy())
print(conf_mat)

해석
다른방식으로 표현
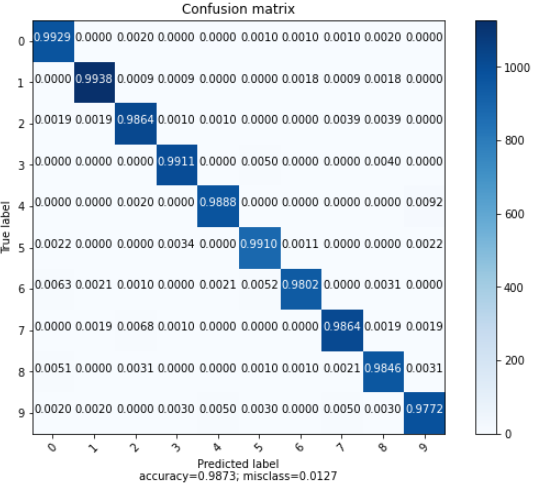
클래스 별로 정확도 확인
각 클래스(0~9) 의 정확도를 확인한다는건데,
우선 결과부터 확인하면
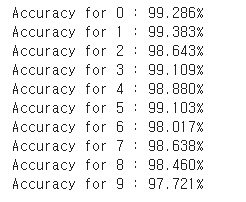
정확도가 가장 높은것은 클래스 1이고
가장 낮은것은 9이다.
MNIST의 테스트 데이터 셋에서는 아무리 이상하게 그려도 1은
1이외의 다른 글씨로 쓰기가 힘들지만,
9와 같이 7, 8 등 7은 2, 8은 3 이처럼 서로 헷갈리게 입력이
될 가능성이 높으며
실제로 각 클래스 별로 그러한 특징을 가진 숫자들의 정확도는
비교적 낮다.
5. Classification Report(분류/예측 보고서)
from sklearn.metrics import classification_report
# 실제 라벨과 예측 라벨을 비교하여 성능 보고서를 출력합니다.
print(classification_report(label_list.numpy(), pred_list.numpy()))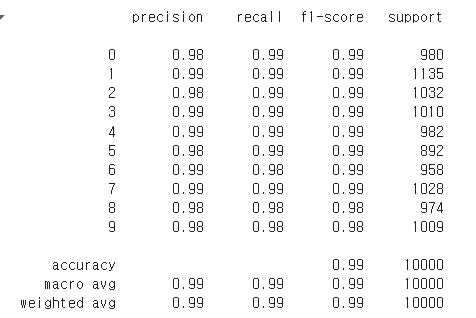
저번 Keras에서 recall과 precision의 관계로 결론을 낸것이 있다.

현재 Report에서는 전반적으로 높은 수치를 나타내 Classification Report 만으로는 확인하기 어렵지만,
Confusion Matrix의 7에 대한 Recall 값을 계산해보자.
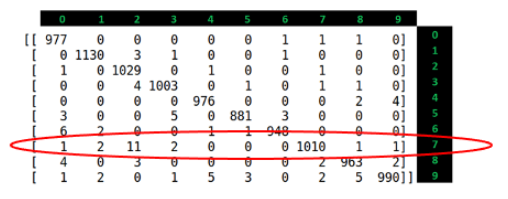
가로 열을 다 더하면 1028로 갯수가 맞다,
이때 잘못 예측한 것이 제일 많은것인데, 그때 Recall 값이 높다.
즉 Recall값이 높다는것은 올바르게 예측도 많이하지만, 거짓 예측도 많아진다는것

이어서 7의 Precision을 계산해보면
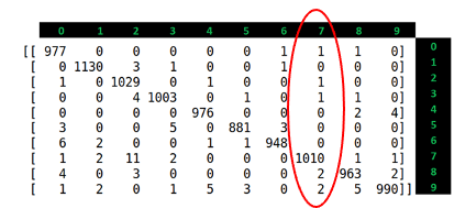
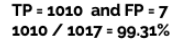
높은 정밀도는 모델이 '7'을 과도하게 예측하지 않으며, 실제 '7'인 경우에 대해서만 예측하는 경향이 강하다는 것을 의미
이는 오탐(False Positive)을 최소화하는 데 중요하다.
이렇게 Recall과 Precision을 계산을 직접 해보면서 이해를 하면
나중에 Classification Report에서 Recall과 Precision의 값들을 보면
대충 어떻게 결과가 나왔는지 확인가능하고 대처할수 있다.
