트레이닝 데이터가 적은 경우 학습하여 그 정확도와 loss를 확인한다.
그리고 Data Augmentation을 적용하기 위한 방법을 배우고 다음에 적용한 경우를 확인한다.
1. 데이터 로드, 검사 및 시각화
# TensorFlow의 keras 모듈에서 포함된 데이터셋을 직접 로드합니다.
from tensorflow.keras.datasets import fashion_mnist
# Fashion-MNIST 훈련 및 테스트 데이터셋을 로드합니다.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# 클래스 이름을 정의합니다. .datasets()에서 데이터를 로드할 때 클래스는 정수로 표현됩니다.
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress',
'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
classes[0] > 'T-shirt/top' [1] > 'Trouser'

GPU를 사용하고 있는지 확인
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())모델을 학습하기 위해선 GPU를 사용해야한다.

GPU부분에 저렇게 출력이 되면 GPU를 사용하고 있다는 뜻이다.
데이터 검사
# 훈련 및 테스트 데이터의 샘플 수를 출력합니다.
print("Initial shape or dimensions of x_train:", x_train.shape)
# 훈련 데이터와 테스트 데이터의 샘플 수를 출력합니다.
print("Number of samples in our training data:", len(x_train))
print("Number of labels in our training data:", len(y_train))
print("Number of samples in our test data:", len(x_test))
print("Number of labels in our test data:", len(y_test))
# 훈련 및 테스트 데이터의 이미지 차원과 라벨 수를 출력합니다.
print("\n")
print("Dimensions of x_train sample:", x_train[0].shape)
print("Labels in x_train shape:", y_train.shape)
print("\n")
print("Dimensions of x_test sample:", x_test[0].shape)
print("Labels in y_test shape:", y_test.shape)

샘플 데이터 일부 시각화
Fashion-MNIST 훈련 데이터셋의 처음 50개 이미지를 시각화
# MNIST 훈련 데이터셋의 처음 50개의 이미지를 시각화합니다.
import matplotlib.pyplot as plt
# 그림을 생성하고 크기를 변경합니다.
plt.figure(figsize=(16, 10))
# 볼 이미지 수를 설정합니다.
num_of_images = 50
# 1부터 50까지의 인덱스를 반복합니다.
for index in range(1, num_of_images + 1):
class_name = classes[y_train[index]]
plt.subplot(5, 10, index).set_title(f'{class_name}')
plt.axis('off')
plt.imshow(x_train[index], cmap='gray_r')
# 그림을 표시합니다.
plt.show()

2. Data Preprocessing
# 이미지의 행과 열 수를 저장합니다.
img_rows = x_train[0].shape[0]
img_cols = x_train[0].shape[1]
# 단일 이미지의 형상을 저장합니다.
input_shape = (img_rows, img_cols, 1)
print(f'Image rows: {img_rows}')
print(f'Image columns: {img_cols}')
print(f'Input shape: {input_shape}')
One Hot Encode our Labels

from tensorflow.keras.utils import to_categorical
# 이제 출력 라벨을 원-핫 인코딩합니다.
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 원-핫 인코딩된 행렬의 열 수(클래스 수)를 출력합니다.
print("Number of Classes: " + str(y_test.shape[1]))
# 클래스 수를 저장합니다.
num_classes = y_test.shape[1]
Fashion-MNIST 데이터셋의 라벨을 원-핫 인코딩하고, 클래스 수를 출력
이는 모델의 출력이 각 클래스에 대한 확률을 나타내도록 학습
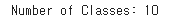
3. Building Model
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import SGD
# create model
model = Sequential()
# Add our layers using model.add()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 모델 요약 출력
model.summary()

Compiling Our Model(정규화 없이)
CNN 모델을 컴파일하고 요약을 출력
# 모델을 컴파일합니다. 이는 우리가 방금 생성한 모델을 저장하는 객체를 만듭니다.
# 옵티마이저를 확률적 경사 하강법(Stochastic Gradient Descent)으로 설정하고 학습률을 0.001로 설정합니다.
# 손실 함수로 다중 클래스 문제에 적합한 categorical_crossentropy를 사용합니다.
# 최종적으로 성능 평가 지표(metrics)로 정확도를 설정합니다.
model.compile(loss='categorical_crossentropy',
optimizer=SGD(0.001, momentum=0.9),
metrics=['accuracy'])
# 모델의 레이어와 파라미터를 표시하는 summary 함수를 사용할 수 있습니다.
print(model.summary())

4. Training Model
# 배치 크기와 에포크 수를 설정합니다.
batch_size = 32 # 한 번에 모델에 전달되는 샘플의 수를 32
epochs = 15
# 모델을 훈련합니다.
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1, # : 훈련 과정의 출력을 설정
validation_data=(x_test, y_test))
# evaluate 함수를 사용하여 정확도 점수를 얻습니다.
# score 변수는 두 개의 값을 가집니다: 테스트 손실과 정확도
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
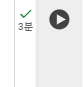
15의 에포크를 학습하는데 3분 걸렸다


모델을 학습하고 결과를 출력하는데 트레이닝 이미지 갯수가 적어 정확도가 높지 않고 loss도 크다.
5. Data Augmentation Example
같은 사진이더라도 사진을 회전하거나, 확대, 축소하여 학습할 데이터를 늘리는것,
데이터의 수가 적을때 사용하면 좋다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 데이터를 다시 로드합니다.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# 데이터를 [샘플 수, 너비, 높이, 색상 깊이] 형식으로 재구성합니다.
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# 데이터 타입을 float32로 변경합니다.
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 데이터 증강을 위한 데이터 생성기를 정의합니다.
data_aug_datagen = ImageDataGenerator(rotation_range=30, # 회전 범위
width_shift_range=0.1, # 가로 이동 범위
height_shift_range=0.1, # 세로 이동 범위
shear_range=0.2, # 기울기 변환 범위
zoom_range=0.1, # 확대/축소 범위
horizontal_flip=True, # 수평 뒤집기
fill_mode='nearest') # 채우기 모드
# 데이터 증강을 위한 이터레이터를 생성합니다.
aug_iter = data_aug_datagen.flow(x_train[0].reshape(1, 28, 28, 1), batch_size=1)
데이터 증강의 결과
생성된 이미지를 확인하여 데이터 증강이 잘 수행되었는지 확인할 수 있다.
import cv2
import matplotlib.pyplot as plt
# 데이터 증강 이미지를 보여주는 함수 정의
def showAugmentations(augmentations=6):
# 새 그림 생성
fig = plt.figure()
for i in range(augmentations):
# 서브플롯 추가
a = fig.add_subplot(1, augmentations, i+1)
# 증강된 이미지 생성
img = next(aug_iter)[0].astype('uint8')
# OpenCV를 사용하여 색상 변환
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 축을 숨김
plt.axis('off')
# 증강된 6개의 이미지를 보여줌
showAugmentations(6)
원본 이미지를 기반으로 데이터 증강 기법을 적용하여 생성된 6개의 변형된 이미지를 보여준다. > Data Augmentation

다음 글에는 이

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w