전에 했던것처럼 Fashion MNIST와 GPU를 사용하고 있는지 확인하는 부분은 생략

1. ImageDataGenerator를 이용한 데이터 전처리
이전과 같이 데이터 유형을 재구성하고 변경
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from tensorflow.keras import backend as K
# 데이터의 형태를 [샘플 수, 너비, 높이, 색상 깊이] 형식으로 변경합니다.
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# 데이터 타입을 float32로 변경합니다.
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
이미지 크기, 모양 및 테스트 데이터를 수집하고 정규화
# 행과 열의 수를 저장합니다.
img_rows = x_train[0].shape[0]
img_cols = x_train[0].shape[1]
# 단일 이미지의 형태를 저장합니다.
input_shape = (img_rows, img_cols, 1)
# 데이터를 0과 1 사이로 정규화합니다.
x_test /= 255.0
2. Building Model
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import SGD
from tensorflow.keras import regularizers
L2 = 0.001 # L2 정규화 상수
# 모델 생성
model = Sequential()
# 첫 번째 컨볼루션 층 추가
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
kernel_regularizer = regularizers.l2(L2),
input_shape=input_shape))
model.add(BatchNormalization()) # 배치 정규화 층 추가
# 두 번째 컨볼루션 층 추가
model.add(Conv2D(64, (3, 3), activation='relu', kernel_regularizer = regularizers.l2(L2)))
model.add(BatchNormalization()) # 배치 정규화 층 추가
model.add(MaxPooling2D(pool_size=(2, 2))) # 최대 풀링 층 추가
model.add(Dropout(0.2)) # 드롭아웃 층 추가
model.add(Flatten()) # 플래튼 층 추가
model.add(Dense(128, activation='relu', kernel_regularizer = regularizers.l2(L2))) # 밀집 층 추가
model.add(Dropout(0.2)) # 드롭아웃 층 추가
model.add(Dense(num_classes, activation='softmax')) # 출력 층 추가
# 모델 컴파일
model.compile(loss = 'categorical_crossentropy',
optimizer = tf.keras.optimizers.SGD(0.001, momentum=0.9),
metrics = ['accuracy'])
# 모델 요약 출력
print(model.summary())
여기 위에 총 3개의 정규화 방식을 사용했다.
- L2 정규화
kernel_regularizer=regularizers.l2(L2)
정규화의 강도로 0.001을 사용했으며
이 값은 모델의 가중치에 페널티를 추가하여 과적합(overfitting)을 방지하는 역할을 한다.
값이 작을수록 자유롭게 학습하여 과적합을 줄이는 효과가 적고
값이 클수록 모델이 더 강하게 규제되며, 과적합을 줄이지만,
너무 큰 값은 모델의 성능을 저하시키고 과소적합(underfitting)을 유발할 수있다.
- 배치 정규화
model.add(BatchNormalization())
딥러닝 모델의 학습을 안정화하고 가속화하기 위해 사용하는 기술
말과 이해하는것은 어렵지만 실제로는 타닥타닥 하면된다.
- 드롭아웃
model.add(Dropout(0.2))
각 훈련 샘플마다 뉴런의 20%를 무작위로 비활성화하는 것
3. Training Model
데이터 증강을 사용하여 학습 데이터를 변형하고, 이를 통해 모델의 일반화 성능을 향상시키는 것을 목표
# 데이터 증강을 위한 데이터 생성기 정의
train_datagen = ImageDataGenerator(
rescale = 1./255, # 픽셀 값을 0과 1 사이로 정규화
rotation_range=10, # 이미지를 최대 10도까지 회전
width_shift_range=0.1, # 이미지를 좌우로 최대 10%까지 이동
height_shift_range=0.1, # 이미지를 상하로 최대 10%까지 이동
shear_range=0.1, # 이미지를 최대 10%까지 전단 변형
zoom_range=0.1, # 이미지를 최대 10%까지 확대/축소
horizontal_flip=True, # 이미지를 수평으로 뒤집기
fill_mode='nearest') # 빈 공간을 가장 가까운 픽셀 값으로 채우기
# 데이터 생성기를 일부 샘플 데이터에 맞춥니다.
# train_datagen.fit(x_train)
batch_size = 32
epochs = 15
# 모델 학습
# train_datagen.flow를 사용하여 데이터와 레이블 배열을 받아 증강된 데이터 배치를 생성
history = model.fit(train_datagen.flow(x_train, y_train, batch_size = batch_size),
epochs = epochs,
validation_data = (x_test, y_test),
verbose = 1,
steps_per_epoch = x_train.shape[0] // batch_size)
# evaluate 함수를 사용하여 정확도 점수 획득
# score는 테스트 손실과 정확도 두 가지 값을 가짐
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
정규화 없이
저번 CNN 29 에서 정규화 없이 학습한 결과이고


정규화 사용
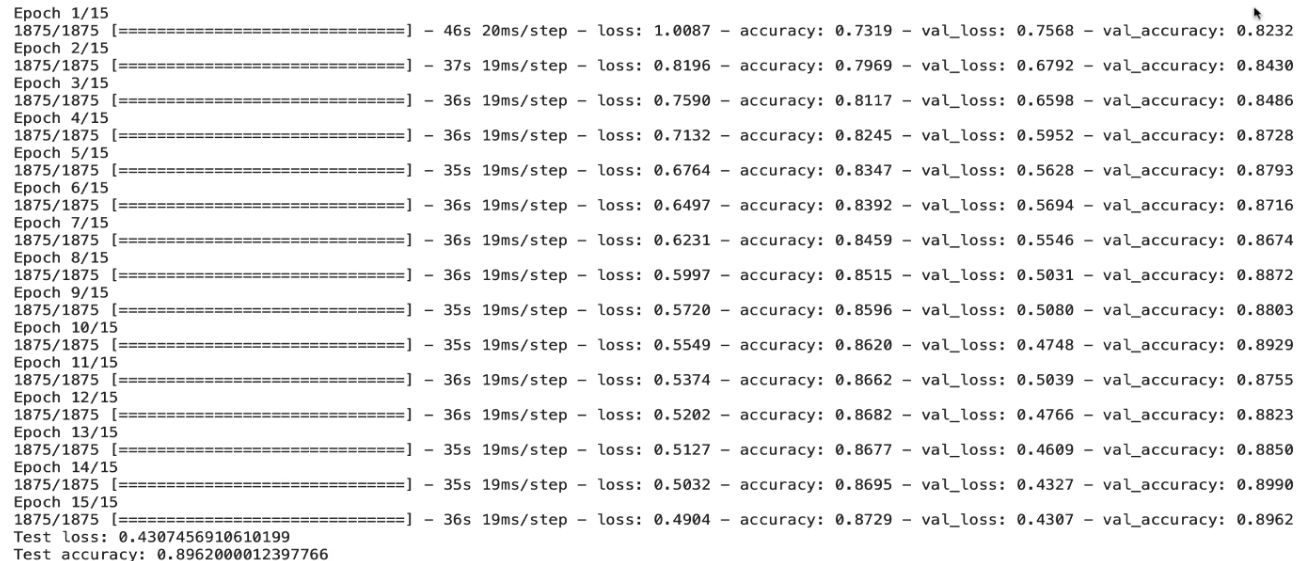
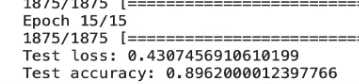
바로 보이는결과로는 정규화 사용이 의미 없어보인다.
하지만 그건 에포크가 15이여서 나타날수 있는 경우의 수이고
실제로는 대중적으로 사용되는 에포크 50으로 학습을 하면
정규화를 적용한 것이 확실히 더 낫다는걸 알 수 있을것이다.

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w