아래 사전 학습된 모델들을 사용
1. VGG16
2. ResNet
3. Inception v3
4. MobileNet v2
5. SqueezeNet
6. Wide ResNet
7. MNASNet
1. VGG16
import torchvision.models as models
model = models.vgg16(pretrained=True)
레이어 확인
# 모델 렐이어 확인
model
30개 레이어가 있고 15개의 ReLU처리가 돼있다.
파라미터 갯수 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))
각 레이어의 파라미터 개수를 나타낸다.
정규화 - Normalisation
모든 사전 학습된 모델은 미니 배치의 3채널 RGB 이미지(형태: (3 x H x W))를 입력으로 받는다.
여기서 H와 W는 최소 224여야 하는데,
이미지는 [0, 1] 범위로 로드된 후, 주어진 평균(mean)과 표준 편차(std)로 정규화해야 한다.
# torchvision에서 필요한 모듈 불러오기
from torchvision import datasets, transforms, models
# 이미지가 저장된 디렉토리 경로
data_dir = '/images'
# 테스트 데이터 변환 설정
test_transforms = transforms.Compose([
# 이미지를 (224, 224) 크기로 조정
transforms.Resize((224, 224)),
# 이미지를 텐서(tensor)로 변환
transforms.ToTensor(),
# 이미지 정규화
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 이미지 정규화를 위한 변환 설정
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transforms.Resize((224, 224)): 이미지를 224x224 크기로 조정
transforms.ToTensor(): 이미지를 텐서(tensor) 형태로 변환
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]): 이미지를 주어진 평균과 표준 편차로 정규화
.eval() 사용
eval은 드롭아웃 레이어와 배치 정규화를 할때 사용되는것으로
레이러를 구분짓기 위해 사용되는 함수이다.
여기서는 따로 처리를 하지 않았기에 모든 레이어의 정보들이 출력된다.

# 모델 초기화
model = models.vgg16(pretrained=True)
# 모델을 평가 모드로 전환
model.eval()
# 평가 모드에서 그래디언트 계산을 비활성화
with torch.no_grad():
# 여기에 평가 코드 작성
pass
# 모델 구조 출력
print(model)이전에 드롭아웃(Dropout)과 배치 정규화(BatchNorm) 할때 사용했던 코드이다.
몇 가지 추론 실행
사전 학습된 모델을 사용하여 이미지 분류를 수행하고, 예측 결과를 시각화
ImageNet 클래스 레이블 가져오기:
# ImageNet 클래스 레이블 이름 가져오기
!wget https://raw.githubusercontent.com/rajeevratan84/ModernComputerVision/main/imageNetclasses.json

ImageNet 클래스 레이블 로드
with open('imageNetclasses.json') as f:
class_names = json.load(f)이미지 예측 함수 정의
# 이미지 예측 함수 정의
def predict_image(images, class_names):
to_pil = transforms.ToPILImage()
fig=plt.figure(figsize=(16,16))
for (i, image) in enumerate(images):
# 이미지를 PIL 이미지로 변환 및 텐서로 변환
image = to_pil(image)
image_tensor = test_transforms(image).float()
image_tensor = image_tensor.unsqueeze_(0)
input = Variable(image_tensor)
input = input.to(device)
output = model(input)
index = output.data.cpu().numpy().argmax()
name = class_names[str(index)]
# 이미지 플롯
sub = fig.add_subplot(len(images), 1, i+1)
sub.set_title(f'Predicted {str(name)}')
plt.axis('off')
plt.imshow(image)
plt.show()디렉토리에서 이미지 로드 함수 정의
def get_images(directory='./images'):
data = datasets.ImageFolder(directory, transform=test_transforms)
num_images = len(data)
loader = torch.utils.data.DataLoader(data, batch_size=num_images)
dataiter = iter(loader)
images, labels = dataiter.next()
return images
예제 이미지 다운로드 및 압축 해제
# 예제 이미지 다운로드 및 압축 해제
!wget https://moderncomputervision.s3.eu-west-2.amazonaws.com/imagesDLCV.zip
!unzip imagesDLCV.zip시각화
images = get_images('./images')
predict_image(images, class_names)
그림 위에 예측 레이블이 출력되고,
셰퍼드는 여러개의 이름으로 예측됐다.
ResNet
모델 다운로드
import torchvision.models as models
model = models.resnet18(pretrained=True)모델의 파라미터 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))Evalue로 설정하고 모델의 레이어를 확인
model.eval()ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)예측 출력
images = get_images('./images')
predict_image(images, class_names)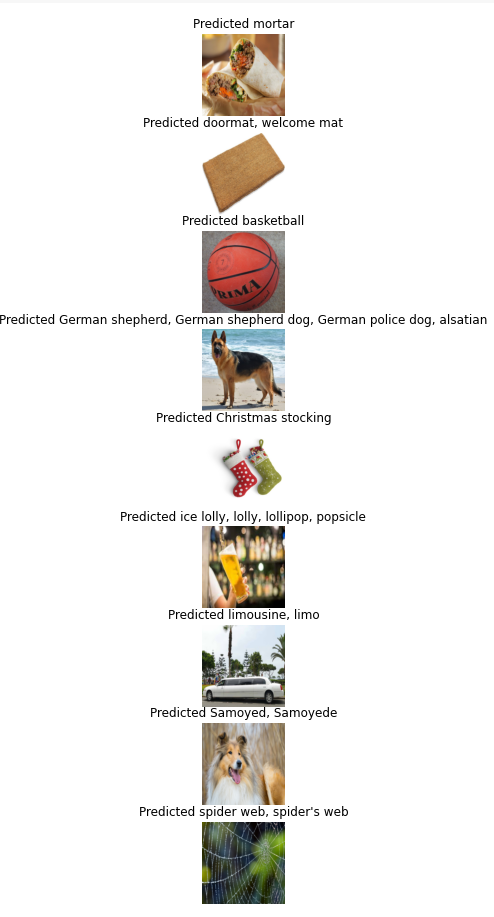
VGG16으로 예측한것과 두번째, 사모예드의 예측결과가 다르지만,
단어가 뜻하는 의미는 비슷하다.
MobileNet
효율성이 좋은 모델
모델 다운로드
import torchvision.models as models
model = models.mobilenet_v2(pretrained=True)파라미터 확인 및 Evalue로 레이어 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))
model.eval()출력 결과
images = get_images('./images')
predict_image(images, class_names)
대체로 괜찮지만, 두번째를 봉투, 농구공을 파우더,
셰퍼드를 늑대와 같이 잘못 예측한것도 있다.
SqueezeNet
1x1 컨볼루션, Fire 모듈등 AlexNet과 같은 성능을 유지하면서 파라미터 수가 적어 크기가 적은 모델이다.
모델 다운
import torchvision.models as models
model = models.squeezenet1_0(pretrained=True)파라미터 확인 및 Evalue로 레이어 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))
model.eval()출력 결과
images = get_images('./images')
predict_image(images, class_names)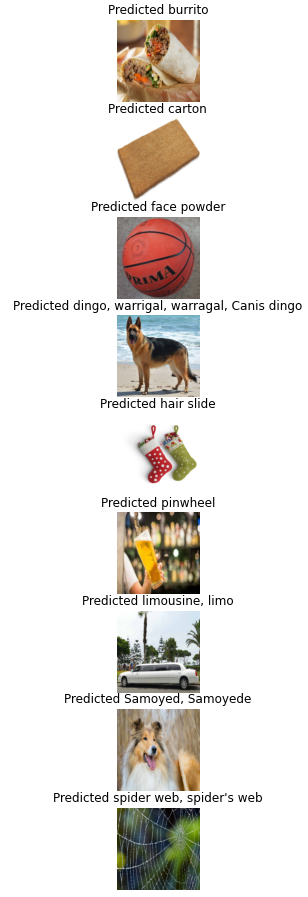
파라미터 수가 줄어 모델의 크기가 줄어 효율면에서는 좋지만,
정확도 측면에서는 2,3,4 번째같은 이미지에서는 좋지않은 모습이다.
Wide ResNet
말그대로 넓은 ResNet으로
ResNet의 깊이를 깊게 하여 학습할 때 발생하는 과적합 문제를 해결하기 위해 만들어졌다.
모델 다운로드
import torchvision.models as models
model = models.wide_resnet50_2(pretrained=True)파라미터 확인 및 Evalue로 레이어 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))
model.eval()출력 결과
images = get_images('./images')
predict_image(images, class_names)
기본적인 ResNet의 결과와 비슷한 결과를 출력한다.
Wide MNASNet
Mobile Neural Architecture Search(MNAS)를 통해 설계된 원래의 MNASNet 아키텍처의 너비를 늘려 성능을 향상시킨 모델
한마디로 표현력을 증가한것,
모델 다운로드
import torchvision.models as models
model = models.mnasnet1_0(pretrained=True)파라미터 확인 및 Evalue로 레이어 확인
from torchsummary import summary
summary(model, input_size = (3,224,224))
model.eval()출력 결과
images = get_images('./images')
predict_image(images, class_names)
결론
VGG16이 전체적으로 가장 좋은 성능을 보였지만, 일부 이미지는 모든 모델에서 예측이 틀렸다.
각 모델은 특정 이미지에 대해 다르게 동작하며, 일부 모델은 특정 유형의 이미지에서 더 나은 성능을 보인다.
다양한 모델을 테스트하고 비교함으로써, 특정 용도에 가장 적합한 모델을 선택해야겠다.
