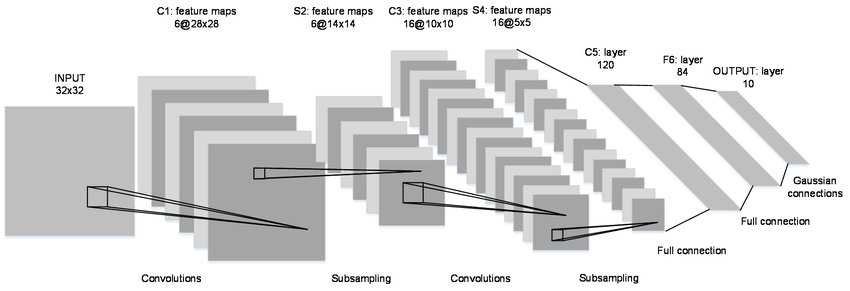
LeNet 아키텍쳐
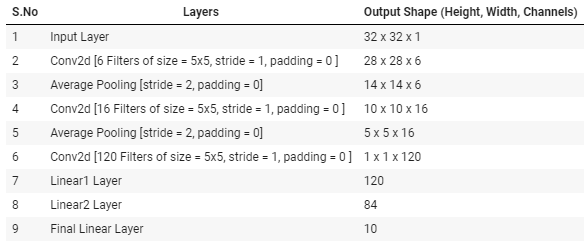
Keras를 사용하여 MNIST 데이터셋을 준비하는 과정
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
from tensorflow.keras.regularizers import l2
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adadelta
# MNIST 데이터셋 로드
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 행(row)과 열(column) 수 저장
img_rows = x_train[0].shape[0]
img_cols = x_train[1].shape[0]
# Keras에서 필요한 형태로 데이터 변경
# 원래 이미지 형태 (60000, 28, 28)를 (60000, 28, 28, 1)로 변경하여 4차원 추가
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
# 단일 이미지의 형태 저장
input_shape = (img_rows, img_cols, 1)
# 이미지 데이터를 float32 데이터 타입으로 변경
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 데이터 정규화: 범위를 (0에서 255)에서 (0에서 1)로 변경
x_train /= 255
x_test /= 255
# 출력값을 원-핫 인코딩
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 클래스 수 저장
num_classes = y_test.shape[1]
# 픽셀 수 저장
num_pixels = x_train.shape[1] * x_train.shape[2]
레이어를 만들어 LeNet을 복제
# 모델 생성
model = Sequential()
# 2개의 CRP 세트 (Convolution, ReLU, Pooling)
model.add(Conv2D(6, (5, 5),
padding="same", # 패딩을 0으로 설정하려면 "valid" 사용
input_shape=input_shape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(16, (5, 5),
padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(120, (5, 5),
padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 완전 연결층 (ReLU 활성화 함수 사용)
model.add(Flatten())
model.add(Dense(120))
model.add(Activation("relu"))
model.add(Dense(84))
model.add(Activation("relu"))
# 소프트맥스 (분류용)
model.add(Dense(num_classes))
model.add(Activation("softmax"))
# 모델 컴파일
model.compile(loss='categorical_crossentropy',
optimizer=Adadelta(),
metrics=['accuracy'])
# 모델 요약 출력
print(model.summary())

MNIST 데이터 세트로 LeNet 트레이닝
에포크 50 으로 모델을 학습시켰고
# 훈련 파라미터 설정
batch_size = 128
epochs = 50
# 모델 훈련
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
# 모델 저장
model.save("mnist_LeNet.h5")
# 훈련된 모델의 성능 평가
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])

Loss, 정확도의 값이 출력됐다. 93%로 나쁘지 않다.
Test loss: 0.24367770552635193
Test accuracy: 0.9312999844551086AlexNET을 복제하고 CIFAR10 데이터 세트에 대한 트레이닝 시작
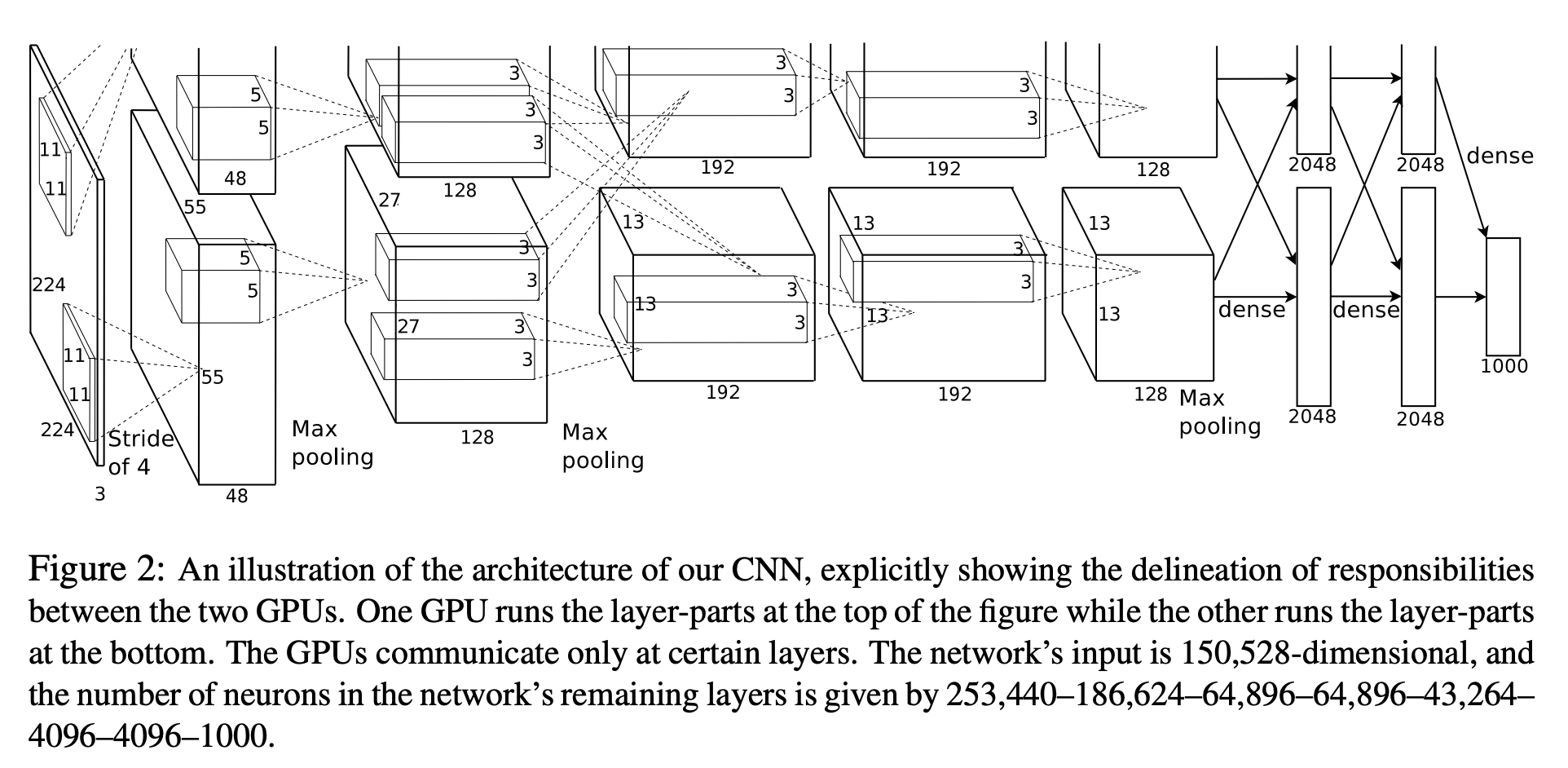
AlexNET 아키텍쳐
CIFAR10 데이터 세트

데이터 셋 로드 및 원-핫 인코딩
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import Adadelta
from tensorflow.keras.utils import to_categorical
# CIFAR-10 데이터셋 로드
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 데이터 형태/차원 출력
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# 출력값을 원-핫 인코딩
num_classes = 10
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
트레이닝 데이터셋으로 50000개, 32x32 크기의 3차원 이미지를 다운로드, 같은 규격의 테스트 데이터셋 10000개를 다운로드했다.

AlexNET 모델 빌드
l2_reg = 0.001
# 모델 초기화
model = Sequential()
# 1번째 Conv Layer
model.add(Conv2D(96, (11, 11), input_shape=x_train.shape[1:],
padding='same', kernel_regularizer=l2(l2_reg)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 2번째 Conv Layer
model.add(Conv2D(256, (5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 3번째 Conv Layer
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 4번째 Conv Layer
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(1024, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# 5번째 Conv Layer
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(1024, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 1번째 FC Layer
model.add(Flatten())
model.add(Dense(3072))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
# 2번째 FC Layer
model.add(Dense(4096))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
# 3번째 FC Layer
model.add(Dense(num_classes))
model.add(BatchNormalization())
model.add(Activation('softmax'))
# 모델 요약 출력
print(model.summary())
# 모델 컴파일
model.compile(loss='categorical_crossentropy',
optimizer=Adadelta(),
metrics=['accuracy'])
모델 학습 및 검증
# 교육 파라미터
batch_size = 64
epochs = 25
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
model.save("CIFAR10_AlexNet_10_Epoch.h5")
# 교육받은 모델의 성능 평가
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
25회 에포크로 테스트 했을때, 1.26의 loss와 0.61의 정확도를 보인다.
좋지 않은 모델이다.
개선하기 위해선, 학습 데이터의 양을 늘리거나, 현재 모델이 매우 복잡해
과적합의 가능성이 있어, 레이어를 줄이거나,
정규화 기법을 추가로 사용하는 방법이 있다.
Current Top Performers in CIFAR10
아래는 최근 CIFAR10의 좋은 성능을 보이는 상위 10개 모델이다.
99% 이상으로 굉장히 높은 정확도를 보여준다.
굉장히 심오한 뉴럴 네트워크로 구성돼있으며,
파라미터의 개수가 굉장히 적음에도 높은 정확도를 보여주는것도 있다.
추가로 Extra Traing Data은 추가 외부 데이터로 훈련을 했다는 것이다.


감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w