Computer Vision을 어떻게 만들것인가?
가장 많이 사용하는 것중
- Matlab
- C++ & Java
- Python Python을 사용할 것이다. 사용한 이유는 접근이 쉽다
애초에 현대 데이터 과학인 딥러닝 라이버리는 기본적으로 Python 을 염두에 두고 작업하도록 만들어졌다.(C++로 코딩됐지만 python에서 작동하도록 만들어졌다.)
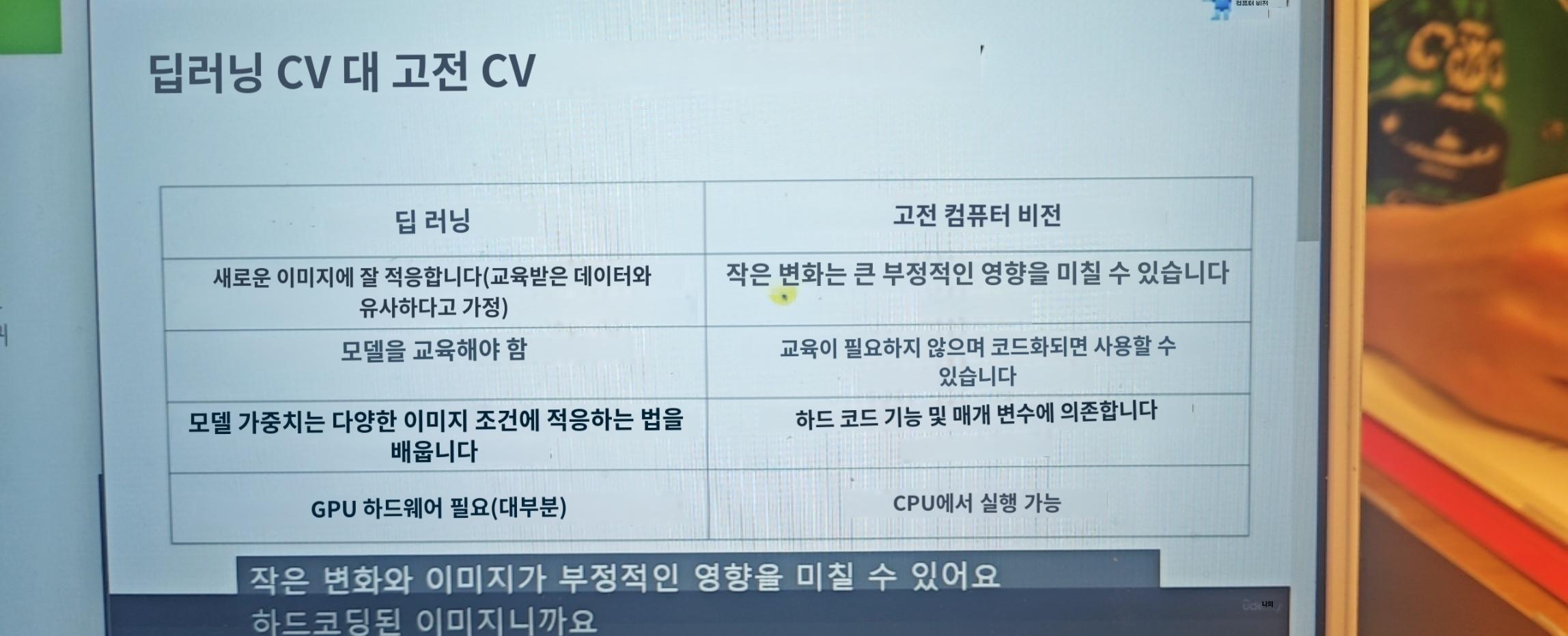
Classical Computer Vision(고전적인 컴퓨터 비전)?
Edge 감지같은 수학적 기술, 간단한 캐스케이드 분류기
Deep Learning Computer Vision?
Classical Computer vision은 현재까지, 넣은 데이터를 기반으로만 계산이 가능했다면 Deep learnig이 들어가고 나서부터 미래의 데이터를 계산을 하면서 판도가 바뀌었다.
Deep Learning 이 왜 뜨는가?
1. Tessorflow(google), Keras(tensorflow 위에있는 레이어), PyTorch(facebook) Theano, Caffe 같은 라이브러리 때문.
- accessible GPU proccessing(액세스 가능한 GPU 처리) 향상
주로 딥러닝의 99%가 CUDA GPU에서 수행된다. (대표 NVIDIA's CUDA)
무엇이 Computer Vision을 어렵게 만드는가?
우리는 어떤것을 보고 인식하고 판단하는것을 누가 가르쳐주지 않아도 자연스럽게 이해하지만, 컴퓨터는 그렇지 않다.
앞으로, 미래에서 컴퓨터 비전을 적용한 것들은 거대한 영역이지만 현재로서는 한가지 유형의 의학적 세부 사항을 이해하는 수준이다.(얼굴을 이해, 이해하는 것과 같은 종류의 학습)
1. Scaling Issues(스케일링 문제)
크기 문제

2. Non-rigid Deformations(비강체 변형)
인간과 유사한 다양한 포즈를 취하는 것과 같은 자연스럽고 풍부하지 않은 변형.

3. Occlusion(폐색)
개체의 일부가 다른 개체에 의해 차단됨

4. Clutter(위장)
문어를 감지하기 힘듦, 번잡한 도심

5. Object Class Variation(객체 클래스 변동)
다 같은 침대같지만 많은 종류의 침대, 소파가 존재

6. ambiguous Optical illusuons
착시

여기 까지 컴퓨터가 이미지를 인식할때 힘든 상황들을 봤다.
그러면 이제 컴퓨터가 이미지를 "어떻게" 인식하는지에 대해 알아야한다.
How do Computers 'see' Images?
기본적으로 컴퓨터는 이미지를 전체적인것으로 보지 않고, pixel, RGB로 분석을 한다.

What are Images? 이미지?
이미지는 가시 광선 스펙트럼의 2D 표현
사람은 스펙트럼의 한 부분을 확인할수있다.
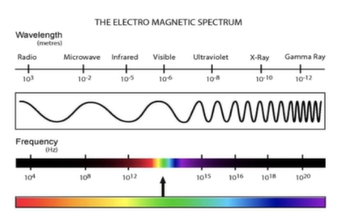
컴퓨터는 어디픽셀에 RGB 혼합비를 확인할 수있다.

