프로젝트 개요
1. MNIST 데이터셋을 로드합니다.
2. 이미지 쌍 데이터셋을 만듭니다.
3. 모델을 생성하고, 대조 손실 함수를 정의한 후 모델을 훈련
4. 결과를 시각화하여 MNIST 데이터셋의 다른 이미지들을 비교
Keras 구현
1. 데이터 로드 및 설정
(x_train_val, y_train_val), (x_test, y_test) = keras.datasets.mnist.load_data()
# Change the data type to a floating point format
x_train_val = x_train_val.astype("float32")
x_test = x_test.astype("float32")train, test 데이터셋을 다운로드
Hyperparameters 정의
epochs = 10
batch_size = 16
margin = 1 # Margin for constrastive loss.훈련 및 검증 데이터셋 생성
각각 30000개 씩 나눴다.
# Keep 50% of train_val in validation set
x_train, x_val = x_train_val[:30000], x_train_val[30000:]
y_train, y_val = y_train_val[:30000], y_train_val[30000:]
del x_train_val, y_train_val에포크 10, 배치사이즈 16, margin 1
2. 이미지 쌍 데이터셋 & 시각화
트레이닝 쌍둥이
x_train_1 = pairs_train[:, 0] # x_train_1.shape is (60000, 28, 28)
x_train_2 = pairs_train[:, 1]
검증 쌍둥이
x_val_1 = pairs_val[:, 0] # x_val_1.shape = (60000, 28, 28)
x_val_2 = pairs_val[:, 1]
테스트 쌍둥이
x_test_1 = pairs_test[:, 0] # x_test_1.shape = (20000, 28, 28)
x_test_2 = pairs_test[:, 1]
3. 모델 컴파일 및 훈련
훈련
history = siamese.fit(
[x_train_1, x_train_2],
labels_train,
validation_data=([x_val_1, x_val_2], labels_val),
batch_size=batch_size,
epochs=epochs,
)10회 에포크로 트레인

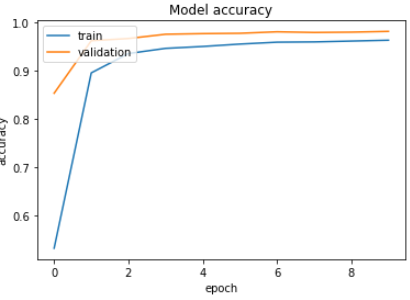
95% 에서 98까지 증가했다.
정확도 log
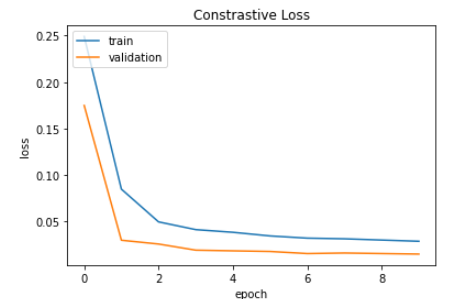
Loss log
4. 결과를 시각화하여 MNIST 데이터셋의 다른 이미지들을 비교
테스트 데이터셋을 사용하여 모델을 평가하는데,
98% 이상의 정확도를 달성한것을 볼 수 있다.


유사한 이미지 쌍과 다른 이미지 쌍에 대한 예측 결과를 보여준다.
결론
장점
유사성 측정에 탁월:
시아미즈 네트워크는 두 입력 간의 유사성을 측정하는 데 매우 효율적입니다. 얼굴 인식, 서명 검증, 지문 매칭 등에서 뛰어난 성능을 보인다.
파라미터 공유:
동일한 가중치와 구조를 가진 두 개의 서브 네트워크를 사용하므로, 학습이 일관되고 파라미터의 수가 줄어들어 효율적이다.
소량의 데이터로 학습 가능:
새로운 클래스의 이미지를 학습할 때, 많은 데이터가 필요하지 않다.
단점
복잡한 데이터 준비:
이미지 쌍을 생성하고 라벨링하는 과정이 필요하므로, 데이터 준비 과정이 복잡할 수 있다.
계산 비용:
두 개의 네트워크를 동시에 실행해야 하므로, 계산 비용이 증가할 수 있다.
응용 분야
- 얼굴 인식
- 서명 검증
- 지문 매칭
- 문사 유사성 비교
- 추천 시스템
5가지를 딱 보면 시아메즈 네트워크가 왜 개발이 됐는지 이해할 수 있는 부분이다.
PyTorch 구현
Keras 보다는 PyTorch로 구현하는 것이 좀 더 자유도 높은 개발을 할 수 있으므로 PyTorch도 찍먹해보자
코드는 생략하겠다.

16개의 이미지를 확인하고 유사성이 높다 판단하여 모두 1이라는 레이블을 갖는다.
학습을 시작하고
Epoch number 0
Current loss 1.5492815971374512
Epoch number 1
Current loss 5.937758922576904
Epoch number 2
Current loss 1.52686607837677
Epoch number 3
Current loss 3.809809446334839
Epoch number 4
Current loss 0.9184529185295105
Epoch number 5
Current loss 0.6202114224433899
Epoch number 6
Current loss 0.45688334107398987
Epoch number 7
Current loss 0.3390580713748932
Epoch number 8
Current loss 0.7456773519515991
Epoch number 9
Current loss 0.2905239760875702
Epoch number 10
Current loss 0.6838889122009277
Epoch number 11
Current loss 0.6770232915878296
...
Epoch number 93
Current loss 0.007222401909530163
Epoch number 94
Current loss 0.005900013726204634
Epoch number 95
Current loss 0.0056257047690451145
Epoch number 96
Current loss 0.004835076164454222
Epoch number 97
Current loss 0.005234717857092619
Epoch number 98
Current loss 0.007568547502160072
Epoch number 99
Current loss 0.006096437573432922
총 100번의 에포크로 학습을 진행을 하였고,
이 수치들을 그래프로 나타냈다.

초반에 Loss 값이 들락날락하다가, 데이터의 개수가 40을 넘어갈때쯤 Loss값이 안정화가 되면서 0에 가까워졌다.
이제 학습한 모델을 가지고 유사성을 계산을 할 것인데, 0과 가까워 질수록 둘은 똑같다는 뜻이다.

테스트 데이터 셋의 데이터들을 위의 사람과 유사성을 비교하는 것을 진행

다른 부분에서 촬영한 동일인물은 0.5 근방의 값을 갖고있고,

다른사람은 2~3의 값을 갖는다.

