목표
- Haarcascade Classifer를 사용하여 얼굴을 탐지하는 방법
- Haarcascade Classifer를 사용하여 눈을 감지하는 방법
- Haarcascade Classifer를 사용하여 웹캠에서 얼굴과 눈을 감지
사전준비
-
웹캠(노트북 웹캠사용)
-
함수 선언 및 이미지 다운로드
# Our Setup, Import Libaries, Create our Imshow Function and Download our Images
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Define our imshow function
def imshow(title = "Image", image = None, size = 10):
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
# Download and unzip our images and Haarcascade Classifiers
# Download and unzip our images
!gdown --id 1O2uCujErifjvK1ziRGssaQO9khI15g6q
!gdown --id 1_X-V1Lp6qMAl_-9opsseieprD3Lhdq8U
!unzip -qq images.zip
!unzip -qq haarcascades.zip시작하기 앞서 먼저 오브젝트 디텍션이 무엇인가?
Object Detection =
"이미지에서 개별 개체를 감지 및 분류하고 개체의 영역에 경계 상자를 그릴 수 있는 기능"

위의 사진은 현재 최근의 탐지기에 대한 사진이다.
그러면 최근이 아닌 예전에는 어떤방법을 사용했을까?
제목에 나와있듯 HAAR Cascade Classifiers라고 불리우며 2001년에 개발된 최초의 광학 질감 탐지기를 사용했다.
HAAR Cascade Classifiers
해당 기술은 다양한 에지 기능도 있고 직사각형 기능에 대한 선 기능도 있다.
이미지에서 저러한 특징들을 발견, 조합하면 얼굴이 되고 분류자는 그 특징을 식별하도록 훈련받는다.

"값의 배열이 사람의 얼굴과 일치한다"

해당 방식으로 학습을 시키기 위해선 많은 긍정, 부정적인 이미지를 필요로한다.
1. Haarcascade Classifer를 사용하여 얼굴을 탐지

결과부터 보면 얼굴에 박스를 씌워 놨다.
# OpenCV의 CascadeClassifier 함수를 사용하여 당사의 위치를 확인합니다
# 분류기(XML 파일 형식)가 저장됩니다
face_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_frontalface_default.xml')
# 이미지를 로드한 다음 그레이스케일로 변환합니다
image = cv2.imread('images/Trump.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 우리의 분류기는 감지된 얼굴의 ROI를 튜플로 반환합니다
# 왼쪽 상단 좌표와 오른쪽 하단 좌표를 저장합니다
faces = face_classifier.detectMultiScale(gray, scaleFactor = 1.3, minNeighbors = 5)
# 얼굴이 감지되지 않으면 face_classifier가 반환되고 빈 튜플
if len(faces) == 0:
print("No faces found")
# 우리는 얼굴 배열을 반복하고 직사각형을 그립니다
# 얼굴 하나하나에 걸쳐
for (x,y,w,h) in faces:
cv2.rectangle(image, (x,y), (x+w,y+h), (127,0,255), 2)
imshow('Face Detection', image)A. classifier(분류자)
분류자는 전체 이미지를 분류하려는 경향이 있다.
입력이미지를 피드하고 이미지에 무엇이 있는지 혹은 어떤 클래스에 있는지 알려준다.
이미 학습된 알고리즘으로 맨처음에 구글 드라이브에서 다운로드 했던것을 가져왔다.
face_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_frontalface_default.xml')B. grayscale
굳이 필요하지 않는 단계이지만, grayscale을 하면 많은 시간이 절약된다.
# 이미지를 로드한 다음 그레이스케일로 변환합니다
image = cv2.imread('images/Trump.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)C. detectMultiScale
뒤 scaleFactor, minNeighbors를 조절하면 민감도가 조절된다는 것만 알아두자.
# 우리의 분류기는 감지된 얼굴의 ROI를 튜플로 반환합니다
# 왼쪽 상단 좌표와 오른쪽 하단 좌표를 저장합니다
faces = face_classifier.detectMultiScale(gray, scaleFactor = 1.3, minNeighbors = 5)D. 박스
얼굴을 탐지하면 사각형을 그린다.
for (x,y,w,h) in faces:
cv2.rectangle(image, (x,y), (x+w,y+h), (127,0,255), 2)
2. Haarcascade Classifer를 사용하여 눈을 감지
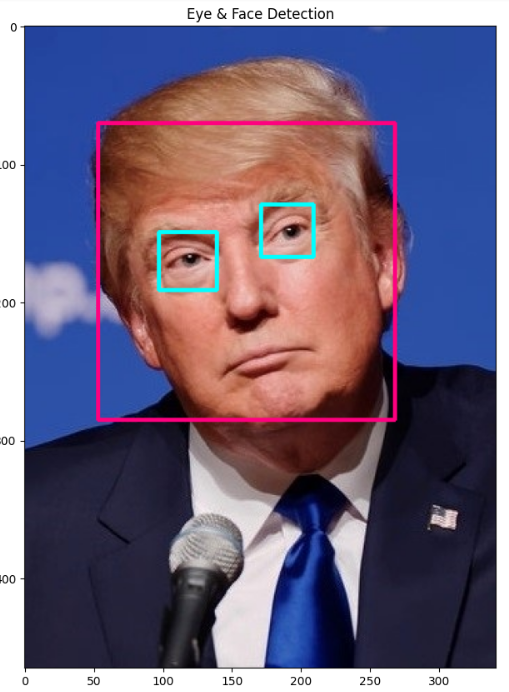
import numpy as np
import cv2
face_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_frontalface_default.xml')
eye_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_eye.xml')
img = cv2.imread('images/Trump.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(gray, 1.3, 5)
# 얼굴이 감지되지 않으면 face_classifier가 반환되고 빈 튜플
if len(faces) == 0:
print("No faces found")
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(127,0,255),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_classifier.detectMultiScale(roi_gray, 1.2, 3)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(255,255,0),2)
imshow('Eye & Face Detection',img)위 얼굴 감지기와 같지만, 눈 감지 분류기를 추가했다.
A. eye_classifier
face_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_frontalface_default.xml')
**eye_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_eye.xml')**B. 사각형
얼굴과 눈이 감지가 되면 찾은 값의 길이정보를 갖고 얼굴과 눈에 사각형을 그려준다.
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(127,0,255),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_classifier.detectMultiScale(roi_gray, 1.2, 3)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(255,255,0),2)
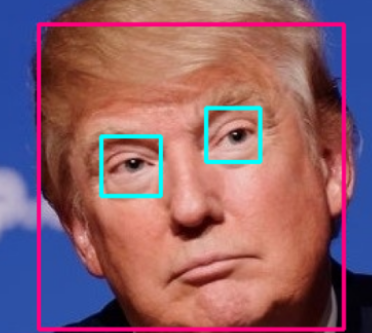
C. 1.2 > 1.5
eyes = eye_classifier.detectMultiScale(roi_gray, 1.5, 3)두번째 인자를 1.5으로 높여줬을때 인식되는 눈의 개수가 하나 줄었다.
이유는 숫자가 커질수록 민감도가 낮아져서 그렇다.
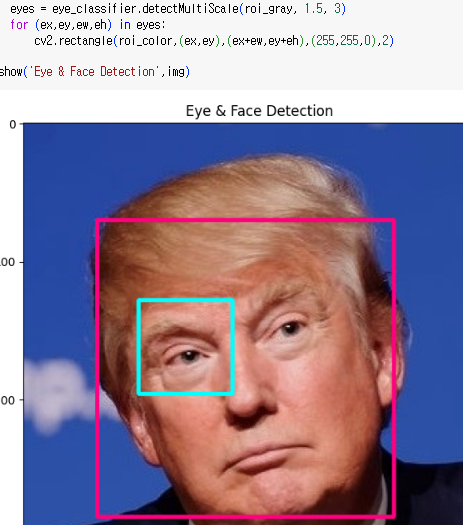
scaleFactor 크게하고 minNeighbors를 작게 설정하면 더 많은 눈을 감지하되 정확성이 떨어짐
scaleFactor 작게하고 minNeighbors를 크게 설정하면 정확도과 향상되지만 처리 속도가 느려짐
위에 적힌 내용처럼 감지의 정확도와 처리속도 사이의 균형을 찾아야 하는데
1.2(1.1~1.5)와 3이 균형잡힌 값으로 많이 사용된다.
3. Haarcascade Classifer를 사용하여 웹캠에서 얼굴과 눈을 감지
Google colab에서 웹캠 찍는것에 관한 코드를 실행 시켜주고
사진을 찍는 코드를 실행하면
from IPython.display import Image
try:
filename = take_photo()
print('Saved to {}'.format(filename))
# Show the image which was just taken.
display(Image(filename))
except Exception as err:
# Errors will be thrown if the user does not have a webcam or if they do not
# grant the page permission to access it.
print(str(err))권한에 대한 요청을한다.
허락을 누르면 웹캠으로 스트리밍이 실행되고
capture 버튼을 누르면 이미지를 저장한다.
파일에 저장돼있고, 해당 이미지의 상대위치를 알아내서 코드에 넣을수 있게 준비한다.
저장된 사진을 아까 처럼 얼굴, 눈 감지하는 코드에 넣어주자.
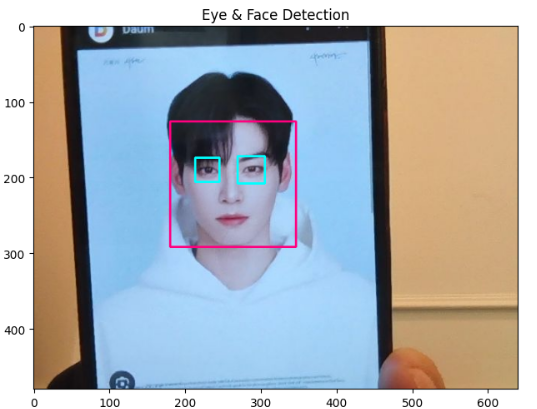
차은우의 얼굴과 눈이 정상적으로 인식이 된다.
from IPython.display import display, Javascript
from google.colab.output import eval_js
from base64 import b64decode
def take_photo(filename='photo.jpg', quality=0.8):
js = Javascript('''
async function takePhoto(quality) {
const div = document.createElement('div');
const capture = document.createElement('button');
capture.textContent = 'Capture';
div.appendChild(capture);
const video = document.createElement('video');
video.style.display = 'block';
const stream = await navigator.mediaDevices.getUserMedia({video: true});
document.body.appendChild(div);
div.appendChild(video);
video.srcObject = stream;
await video.play();
// Resize the output to fit the video element.
google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true);
// Wait for Capture to be clicked.
await new Promise((resolve) => capture.onclick = resolve);
const canvas = document.createElement('canvas');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
canvas.getContext('2d').drawImage(video, 0, 0);
stream.getVideoTracks()[0].stop();
div.remove();
return canvas.toDataURL('image/jpeg', quality);
}
''')
display(js)
data = eval_js('takePhoto({})'.format(quality))
binary = b64decode(data.split(',')[1])
with open(filename, 'wb') as f:
f.write(binary)
return filenameGoogle colab Webcam
from IPython.display import display, Javascript
from google.colab.output import eval_js
from base64 import b64decode
def take_photo(filename='photo.jpg', quality=0.8):
js = Javascript('''
async function takePhoto(quality) {
const div = document.createElement('div');
const capture = document.createElement('button');
capture.textContent = 'Capture';
div.appendChild(capture);
const video = document.createElement('video');
video.style.display = 'block';
const stream = await navigator.mediaDevices.getUserMedia({video: true});
document.body.appendChild(div);
div.appendChild(video);
video.srcObject = stream;
await video.play();
// Resize the output to fit the video element.
google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true);
// Wait for Capture to be clicked.
await new Promise((resolve) => capture.onclick = resolve);
const canvas = document.createElement('canvas');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
canvas.getContext('2d').drawImage(video, 0, 0);
stream.getVideoTracks()[0].stop();
div.remove();
return canvas.toDataURL('image/jpeg', quality);
}
''')
display(js)
data = eval_js('takePhoto({})'.format(quality))
binary = b64decode(data.split(',')[1])
with open(filename, 'wb') as f:
f.write(binary)
return filename