
목표
- Haarcascade Classier를 사용하여 보행자 감지
- 비디오에서 Haarcascade 분류기 사용
- Haarcascade Classier를 사용하여 차량 또는 차량 감지
사전준비
- 클래스피어(학습된 알고리즘) 다운로드
- 감별자를 사용할 실제 영상
# Our Setup, Import Libaries, Create our Imshow Function and Download our Images
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Define our imshow function
def imshow(title = "Image", image = None, size = 10):
w, h = image.shape[0], image.shape[1]
aspect_ratio = w/h
plt.figure(figsize=(size * aspect_ratio,size))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(title)
plt.show()
!gdown --id 1_X-V1Lp6qMAl_-9opsseieprD3Lhdq8U
!gdown --id 12Df2z5JzOZY6i9rF-cr3AMvHGO6gGyUh
!unzip -qq haarcascades.zip
!unzip -qq videos.zip
영상을 처리하기 전에 컴퓨터 비전에서 영상이 어떻게 처리되는지인가?
영상은 이미지와 다르게 처리된다.
당연히 영상은 이미지의 연속으로 다루기 때문이다.
비디오에는 프레임률이 있다.
프레임률은 초당이미지를 캡처하는 양이다.
흔히 FPS게임을 할때 144fps, 120fps, 60fps로 높은 프레임률을 가질수록
움직임이 부드러워져 유리해서 많은 사람들이 fps은 흔히 알고들있다.
그러면 영상을 어떻게 처리를 할까?
첫번째는 영상의 프레임중 하나를 출력(이미지)해서 해당
이미지를 분석하는것이다.
1. Haarcascade Classier를 사용하여 보행자 감지

흐름은 저번 얼굴, 눈 인식하는 글과 비슷하다.
Classfier(분별자) 들 중 사람형태를 감지하는 body.xml을 가져와서 첫번째 프레임을 추출해서 감지되면 박스를 그리고 없다면 반환하는 것인데,
해당 body classifier는 구식기술로 3명이지만 2명밖에 인식이 안됐다.
하지만 구식 기술치곤 괜찮은 결과를 보이며, 나중에는 YOLO나 최신 기술을 이용해서 인식할것이므로 상관없다.
# 비디오 캡처 개체 만들기
cap = cv2.VideoCapture('walking.mp4')
# 신체 분류기 로드
body_classifier = cv2.CascadeClassifier('Haarcascades/haarcascade_fullbody.xml')
# 첫번째 프레임 읽기
ret, frame = cap.read()
# 성공적으로 읽었을 경우 Ret은 True입니다
if ret:
#보다 빠른 처리를 위해 이미지를 그레이스케일링
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 차체 분류기에 프레임을 전달합니다
bodies = body_classifier.detectMultiScale(gray, 1.2, 3)
# 식별된 신체에 대한 경계 상자 추출
for (x,y,w,h) in bodies:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 255), 2)
# 비디오 캡처를 출력
cap.release()
imshow("Pedestrian Detector", frame)2. 비디오에서 Haarcascade 분류기 사용
비디오 파일에서 보행자를 감지하고, 감지된 보행자 주위에 사각형을 그려 새로우 비디오 파일에 저장하는 코드
# 비디오 캡처 개체 만들기
cap = cv2.VideoCapture('walking.mp4')
# 프레임의 높이와 폭을 구합니다(간섭이 필요합니다)
w = int(cap.get(3))
h = int(cap.get(4))
# 코덱을 정의하고 VideoWriter 개체를 만듭니다. 출력은 'walking_output.avi' 파일에 저장됩니다.
out = cv2.VideoWriter('walking_output.avi', cv2.VideoWriter_fourcc('M','J','P','G'), 30, (w, h))
body_detector = cv2.CascadeClassifier('Haarcascades/haarcascade_fullbody.xml')
# 비디오가 성공적으로 로드되면 루프가 발생합니다
while(True):
ret, frame = cap.read()
if ret:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 차체 분류기에 프레임을 전달합니다
bodies = body_detector.detectMultiScale(gray, 1.2, 3)
# 식별된 신체에 대한 경계 상자 추출
for (x,y,w,h) in bodies:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 255), 2)
# 프레임을 'output.avi' 파일에 씁니다
out.write(frame)
else:
break
cap.release()
out.release()A.
cv2.VideoWriter('walking_output.avi', cv2.VideoWriter_fourcc('M','J','P','G'), 30, (w, h))walking_output.avi'라는 파일에 비디오를 저장하기 위한 VideoWriter 객체를 생성합니다. 비디오 코덱으로는 MJPG를 사용하며, 프레임 속도는 초당 30프레임
walking_output.avi 라는 영상이 저장됐고
grayscale을 하고도 1분이 걸렸다.
14초의 원본 파일을 했을때 훨씬 시간이 많이 걸리는데,
나중에 몇분 몇시간 짜리의 영상을 분석할때
grayscale 을 무조건 해야하겠다는 생각이 들었다.

walking_output.avi - youtube shorts
2-1 Colab 내에서 분별
방법
- FFMPEG를 사용하여 AVI 파일을 MP4로 변환
!ffmpeg -i /content/walking_output.avi walking_output.mp4 -y- IPython에서 HTML 플러그인 로드
from IPython.display import HTML
from base64 import b64encode
mp4 = open('walking_output.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()- HTML 비디오 플레이어 표시
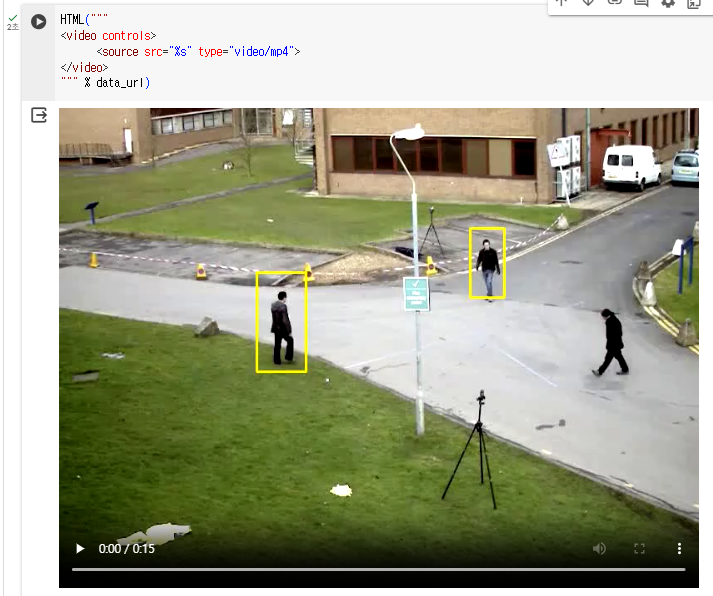
walking_output.mp4 저장되는것을 볼 수 있다.

3. Haarcascade Classier를 사용하여 차량 감지
A. 이미지 추출 후 감지
사람 감지 했던것처럼 도로 비디오에서 1프레임을 뽑아서 인식했을땐 하나밖에 인식이 안된다.

B. 영상 감지
영상으로 감지했을 때에는 예전 모델치고는 준수한 결과를 확인할 수 있다.
# Create our video capturing object
cap = cv2.VideoCapture('cars.mp4')
# Get the height and width of the frame (required to be an interfer)
w = int(cap.get(3))
h = int(cap.get(4))
# Define the codec and create VideoWriter object.The output is stored in 'outpy.avi' file.
out = cv2.VideoWriter('cars_output.avi', cv2.VideoWriter_fourcc('M','J','P','G'), 30, (w, h))
vehicle_detector = cv2.CascadeClassifier('Haarcascades/haarcascade_car.xml')
# Loop once video is successfully loaded
while(True):
ret, frame = cap.read()
if ret:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Pass frame to our body classifier
vehicles = vehicle_detector.detectMultiScale(gray, 1.2, 3)
# Extract bounding boxes for any bodies identified
for (x,y,w,h) in vehicles:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 255), 2)
# Write the frame into the file 'output.avi'
out.write(frame)
else:
break
cap.release()
out.release()도로 자동차 인식 결과

3-1 Colab에서 실행
- FFMPEG를 사용하여 AVI 파일을 MP4로 변환
!ffmpeg -i /content/cars_output.avi cars_output.mp4 -y- IPython에서 HTML 플러그인 로드
from IPython.display import HTML
from base64 import b64encode
mp4 = open('cars_output.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()- HTML 비디오 플레이어 표시
HTML("""
<video controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
