
전이 학습(Transfer Learning) 및 미세 조정 실습
전이 학습의 필요성
대부분의 사람들이 CNN을 처음부터 끝까지 훈련하지 않는 이유는 대규모 네트워크를 훈련하기에 충분한 크기의 데이터셋을 찾기 어렵기 때문이다.
대신, 대규모 데이터셋으로 사전 훈련된 네트워크를 활용하여 시간을 절약하고 성능을 향상시키면 된다.
전이 학습의 개념 및 원리
전이 학습은 사전 훈련된 네트워크를 활용하여 새로운 데이터셋에 맞게 훈련하는 방법으로
주요 방법으로는
- 특징 추출
- 미세 조정이 있다.
특징 추출 (Feature Extraction)
사전 훈련된 네트워크의 하위 층 가중치를 고정하고 상위 층만 재훈련하는 방법
예를 들어, ImageNet으로 훈련된 네트워크를 사용하여 새로운 클래스에 대해 상위 완전 연결 층을 재훈련
미세 조정 (Fine Tuning)
하위 층 가중치는 고정하고 상위 층 가중치는 학습 가능하게 하여 재훈련하는 방법
작은 학습률을 사용하여 가중치를 조금씩 조정
실습
Step 1. 사전 훈련된 가중치를 사용하여 기본 모형 로드
import tensorflow_datasets as tfds
# 진행 표시줄 비활성화
tfds.disable_progress_bar()
# 데이터셋 로드 및 분할
train_ds, validation_ds, test_ds = tfds.load(
"cats_vs_dogs",
# 10%를 검증 데이터로, 10%를 테스트 데이터로 예약
split=["train[:40%]", "train[40%:50%]", "train[50%:60%]"],
as_supervised=True, # 레이블 포함
)
# 각 데이터셋의 샘플 수 출력
print(f'Number of training samples: {tf.data.experimental.cardinality(train_ds)}')
print(f'Number of validation samples: {tf.data.experimental.cardinality(validation_ds)}')
print(f'Number of test samples: {tf.data.experimental.cardinality(test_ds)}')

결과를 봤을때, "cats_vs_dogs" 데이터셋이 성공적으로 다운로드 및 준비되었음을 알 수 있다.
데이터셋 분할:
훈련 데이터셋 (train_ds): 9305개
검증 데이터셋 (validation_ds): 2326개
테스트 데이터셋 (test_ds): 2326개
각 데이터셋의 샘플 수:
전체 데이터셋의 40%는 훈련 데이터로, 10%는 검증 데이터로, 나머지 10%는 테스트 데이터로 할당됐다.
훈련 데이터셋에서 랜덤으로 9개 출력
import matplotlib.pyplot as plt
# 그림 크기를 설정합니다.
plt.figure(figsize=(10, 10))
# 훈련 데이터셋에서 9개의 샘플을 가져와서 반복합니다.
for i, (image, label) in enumerate(train_ds.take(9)):
# 3x3 격자의 서브플롯을 생성합니다.
ax = plt.subplot(3, 3, i + 1)
# 이미지를 서브플롯에 표시합니다.
plt.imshow(image)
# 레이블에 따라 제목을 'Cat' 또는 'Dog'로 설정합니다.
plt.title('Cat' if int(label) == 0 else 'Dog')
# 축을 숨깁니다.
plt.axis("off")
고양이와 개 이미지가 혼합된 그리드가 화면에 나타날 것인데, 레이블링이 제대로 되었는지 확인해보자.

9개 뿐이지만 레이블이 모두 알맞게 예측됐다.
데이터 표준화(Standardize Data)
픽셀 값을 -1에서 1 사이로 정규화
모델 자체의 일부로 정규화 레이어를 사용하여 이 작업을 수행할것.
1. 이미지 크기 조정
train_ds = train_ds.map(lambda x, y: (tf.image.resize(x, size), y))
validation_ds = validation_ds.map(lambda x, y: (tf.image.resize(x, size), y))
test_ds = test_ds.map(lambda x, y: (tf.image.resize(x, size), y))
-
훈련, 검증, 테스트 데이터셋의 각 이미지를 (150, 150) 크기로 조정
-
tf.image.resize 함수를 사용하여 이미지 크기를 변경하고, 레이블은 그대로 유지
2. 배치 크기 및 데이터셋 최적화:
batch_size = 32
train_ds = train_ds.cache().batch(batch_size).prefetch(buffer_size=10)
validation_ds = validation_ds.cache().batch(batch_size).prefetch(buffer_size=10)
test_ds = test_ds.cache().batch(batch_size).prefetch(buffer_size=10)
batch_size를 32로 설정
cache()를 사용하여 데이터셋을 캐시> 이거왜함?
- 데이터가 메모리에 저장되어 다음번에 더 빠르게 접근할 수 있게하기 위함
batch(batch_size)를 사용하여 데이터셋을 배치 크기(32)로 나눈다.
prefetch(buffer_size=10)를 사용하여 데이터셋을 사전 로드 > 왜?
- 훈련 중 데이터 로드 시간을 줄이기 위해 사용
size = (150, 150)
# 훈련, 검증, 테스트 데이터셋의 이미지 크기를 (150, 150)으로 조정합니다.
train_ds = train_ds.map(lambda x, y: (tf.image.resize(x, size), y))
validation_ds = validation_ds.map(lambda x, y: (tf.image.resize(x, size), y))
test_ds = test_ds.map(lambda x, y: (tf.image.resize(x, size), y))
batch_size = 32
# 훈련 데이터셋을 캐시하고 배치 크기(32)로 나누며 사전 로드(buffer_size=10)합니다.
train_ds = train_ds.cache().batch(batch_size).prefetch(buffer_size=10)
# 검증 데이터셋을 캐시하고 배치 크기(32)로 나누며 사전 로드(buffer_size=10)합니다.
validation_ds = validation_ds.cache().batch(batch_size).prefetch(buffer_size=10)
# 테스트 데이터셋을 캐시하고 배치 크기(32)로 나누며 사전 로드(buffer_size=10)합니다.
test_ds = test_ds.cache().batch(batch_size).prefetch(buffer_size=10)
데이터 정규화를 왜하는지 한번더 짚고 가자
이미지 크기를 표준화하고 데이터셋을 배치 및 최적화하여 모델 훈련 시 효율적으로 데이터를 처리할 수 있도록 준비 하기 위함이고,
이를 통해 훈련 속도를 높이고 메모리 사용을 최적화할 수 있다.
랜덤 데이터 증강 도입
정확도를 높이기 위해 데이터의 모습을 바꾸는 방법을
배운적이 있다. 실습 해보자.
데이터 증강(data augmentation)을 위해 케라스 Sequential 모델을 생성
from tensorflow import keras
from tensorflow.keras import layers
# 데이터 증강을 위한 케라스 Sequential 모델을 생성합니다.
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal"), # 수평으로 이미지를 랜덤 뒤집기
layers.experimental.preprocessing.RandomRotation(0.1), # 이미지를 0.1 라디안만큼 랜덤 회전
]
)
RandomFlip("horizontal"): 이미지를 수평으로 랜덤하게 뒤집
RandomRotation(0.1): 이미지를 0.1 라디안 범위 내에서 랜덤하게 회전
이미지는 위 두개 방식으로 증강을 처리했다.
데이터 증강 시각화
그럼 증강처리한 이미지를 시각화 하자
훈련 데이터셋에서 첫 번째 배치를 가져와 데이터 증강 결과를 시각화
import numpy as np
# 훈련 데이터셋에서 첫 번째 배치를 가져와서 데이터 증강 결과를 시각화합니다.
for images, labels in train_ds.take(1):
plt.figure(figsize=(10, 10))
first_image = images[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
# 첫 번째 이미지를 증강하고 결과를 시각화합니다.
augmented_image = data_augmentation(
tf.expand_dims(first_image, 0), training=True
)
# 증강된 이미지를 플롯에 표시합니다.
plt.imshow(augmented_image[0].numpy().astype("int32"))
# 레이블을 제목으로 설정합니다.
plt.title(int(labels[i]))
# 축을 숨깁니다.
plt.axis("off")

결과를 보면 같은 이미지 이지만, 레이블 예측값이 다르게 나타나는 부분이 있다.
이러한 현상이 나타날수 있는 문제
-
증강의 영향:
단순 이미지가 원본과 매우 달라 모델이 이를 다르게 해석 -
모델의 민감도:
이미지의 특정 부분에 민감하게 반응, 예를 들어 특정 각도에서의
특징이나 배경 요소에 따라 모델의 예측이 달라질 수 있다. -
데이터셋의 불균형:
데이터셋 자체의 불균형이 모델 > 과적합
이러한 문제를 해결하려면,
데이터 추가 수집, 교차검증, 하이퍼파라미터 튜닝 등 모델의 성능을
향상시키는 방안을 적용해야한다.
Step 2. 모델 구축
중요사항
- 입력 값을 [0, 255] 범위에서 [-1, 1] 범위로 스케일링하기 위해 Normalization 레이어를 추가
사전 훈련된 Xception 모델이 해당 범위로 스케일된 입력값을 기대하기 때문
- 정규화를 위해 분류 레이어 전에 Dropout 레이어를 추가
Dropout 레이어를 추가하는 이유는 과적합(overfitting)을 방지하고 모델의 일반화 성능을 향상
- 기본 모델의 배치 정규화 통계가 업데이트되지 않도록 기본 모델을 호출할 때 training=False로 설정하여 추론 모드에서 실행되도록 한다.
배치 정규화 통계가 업데이트되지 않도록 기본 모델을 추론 모드로 실행하는 이유는 미세 조정(fine-tuning) 시 모델의 성능을 안정적으로 유지하기 위함
기본 모델로 Xception 모델을 사용
1. 기본 모델 로드 및 동결:
base_model = keras.applications.Xception(
weights="imagenet", # Load weights pre-trained on ImageNet.
input_shape=(150, 150, 3),
include_top=False, # Do not include the ImageNet classifier at the top.
)
base_model.trainable = False
-
ImageNet 데이터셋으로 사전 훈련된 Xception 모델을 로드
-
include_top=False로 설정하여 ImageNet 분류기를 포함X
-
base_model.trainable = False로 설정하여 기본 모델의 가중치를 동결
2. 데이터 증강 및 입력 스케일링:
inputs = keras.Input(shape=(150, 150, 3))
x = data_augmentation(inputs) # Apply random data augmentation
scale_layer = keras.layers.Rescaling(scale=1 / 127.5, offset=-1)
x = scale_layer(x)
- keras.Input을 사용하여 입력 레이어를 정의
- data_augmentation을 사용하여 입력 데이터에 랜덤 증강을 적용
- Rescaling 레이어를 사용하여 입력 이미지를 [-1, 1] 범위로 스케일링
3. 기본 모델 적용 및 추가 레이어:
x = base_model(x, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x) # Regularize with dropout
outputs = keras.layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
- 기본 모델을 추론 모드(training=False)로 호출하여 배치 정규화 통계가 업데이트되지 않도록한다.
- GlobalAveragePooling2D 레이어를 추가하여 공간 차원을 축소
- Dropout(0.2) 레이어를 추가하여 정규화
- Dense(1) 레이어를 추가하여 최종 출력을 정의
4. 모델 요약:
model.summary()
위의 코드를 실행한 결과를 보자.
결과
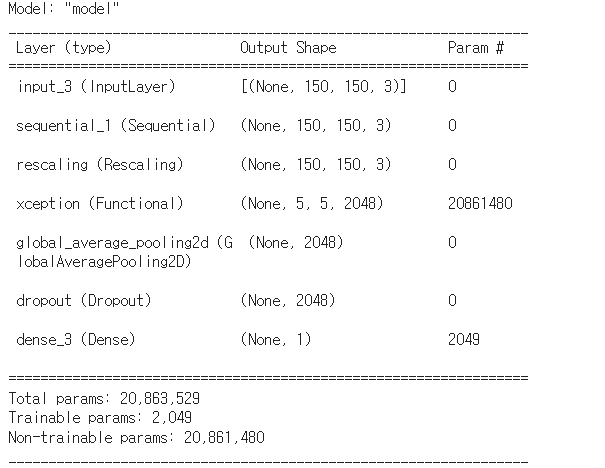
총 파라미터 수: 20,863,529
학습 가능한 파라미터: 2,049
학습 불가능한 파라미터: 20,861,480
이 모델은 데이터 증강, 스케일링, 기본 모델 적용, 글로벌 풀링, 드롭아웃, 최종 출력 레이어로 구성되어 있으며,
기본 모델의 가중치를 동결하여 사용하고 있다.
Top Layer 훈련
사전 훈련된 모델의 최상위 레이어만 훈련할 것인데,
2,049개의 훈련 가능한 파라미터만 다룰 예정
# 모델 컴파일
model.compile(
optimizer=keras.optimizers.Adam(), # Adam 옵티마이저 사용
loss=keras.losses.BinaryCrossentropy(from_logits=True), # 이진 교차 엔트로피 손실 함수 사용
metrics=[keras.metrics.BinaryAccuracy()], # 이진 정확도 메트릭 사용
)Adam은 적응형 학습률을 사용하여 학습 과정을 최적화
# 훈련 설정
epochs = 20 # 총 20 에포크 동안 훈련
# 모델 훈련
model.fit(train_ds, epochs=epochs, validation_data=validation_ds)
훈련 데이터셋(train_ds)을 사용하여 모델을 훈련하고, 검증 데이터셋(validation_ds)을 사용하여 각 에포크 후 모델 성능을 평가
위 코드의 출력결과는 아래와 같다.
결과

해석
-
첫 번째 에포크에서는 훈련 손실이 0.1793, 이진 정확도가 91.92%, 검증 손실이 0.0832, 검증 이진 정확도가 96.78%
-
두 번째 에포크에서는 훈련 손실이 감소하고 이진 정확도는 증가하며, 검증 손실도 감소
-
다음 에포크들에서도 훈련 및 검증 성능이 점진적으로 개선되는 경향을 보입니다.
step 3. Fine Tuning(미세조정)
미세 조정에서는 기본 모델의 동결을 해제하고 낮은 학습률로 전체 모델을 끝까지 훈련을 목적으로 한다.
1. 기본 모델 동결 해제
base_model.trainable = True
기본 모델의 동결을 해제하여 학습 가능한 상태로 만든다.
단, 추론 모드로 실행되도록 설정되어 배치 정규화 레이어가 배치 통계를 업데이트하지 않도록 해줘야한다.
2. 모델 컴파일
model.compile(
optimizer=keras.optimizers.Adam(1e-5), # Low learning rate
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[keras.metrics.BinaryAccuracy()],
)
매우 낮은 학습률(1e-5)로 Adam 옵티마이저를 사용
미세 조정 시 모델이 안정적으로 학습할 수 있도록 해준다.
metrics=[keras.metrics.BinaryAccuracy()]: 이진 정확도를 메트릭으로 사용하여 모델의 성능을 평가
3. 모델 훈련
epochs = 10 # 총 10 에포크 동안 훈련
model.fit(train_ds, epochs=epochs, validation_data=validation_ds)
결과

해석
- 첫 번째 에포크에서는 훈련 손실이 0.1086, 이진 정확도가 95.52%, 검증 손실이 0.0574, 검증 이진 정확도가 97.55%
- 두 번째 에포크에서는 훈련 손실이 감소하고 이진 정확도는 증가하며, 검증 손실도 감소합니다.
- 다음 에포크들에서도 훈련 및 검증 성능이 점진적으로 개선되는 경향을 보입니다.
차이점
이전 단계: 상위 레이어만 훈련
이전 단계에서는 사전 훈련된 Xception 모델의 상위 레이어만 훈련했다
모델의 대부분의 파라미터는 동결된 상태로 남아 있었고, 상위 레이어만 학습
Fine Tuning 단계: 전체 모델 훈련
Fine Tuning 단계에서는 사전 훈련된 모델의 동결을 해제하고, 낮은 학습률을 사용하여 전체 모델을 훈련
기본 모델의 모든 파라미터가 학습 가능해지며, 추가로 미세 조정 가능
요약
훈련 가능한 파라미터의 수:
이전 단계 : 2,049개의 파라미터만 훈련
Fine Tuning 단계 : 동결해제 > 20,809,001개의 파라미터가 훈련
학습률:
이전 단계: 기본 학습률을 사용하여 상위 레이어만 훈련
Fine Tuning 단계: 매우 낮은 학습률(1e-5)을 사용하여 모델 전체를 훈련
이는 이미 학습된 가중치를 조금씩 조정하기 위함
모델 동결 상태:
이전 단계: 기본 모델이 동결된 상태로, 배치 정규화 레이어가 업데이트되지 않는다.
Fine Tuning 단계: 기본 모델의 동결을 해제하지만, 추론 모드로 설정하여 배치 정규화 레이어가 업데이트되지 않도록 한다.
왜 사용하는가?
이전 단계:
사전 훈련된 가중치를 최대한 활용하여 초기 학습을 빠르게 수행
빠른 수렴과 안정적인 초기 성능을 확보
Fine Tuning 단계:
전체 모델을 미세 조정하여 더욱 세밀한 최적화를 수행
새로운 데이터셋에 대해 모델을 보다 잘 적응시키기 위해 모든 가중치를 재학습
낮은 학습률을 사용하여 이미 학습된 중요한 표현을 망치지 않도록 신중하게 조정
결론
결국 이 두 단계는 함께 사용된다.
두 단계는 함께 사용되어 모델이 새로운 데이터셋에서 잘 일반화되도록 해준다.
처음에는 상위 레이어만 학습하여 안정적인 시작을 하고, 이후에는 전체 모델을 미세 조정하여 성능을 극대화하기 위함이다.
