1. Setup 및 Install Lightning
사전 학습된 ResNet-50 모델을 활용하여 이미지를 분류하는 작업을 수행
Install
# PyTorch Lightning 및 TorchMetrics를 설치합니다.
!pip install pytorch-lightning --quiet
!pip install torchmetrics

Setup
# 사용할 모든 패키지를 임포트합니다.
import os # 운영체제와 상호작용하기 위해 사용됩니다.
import torch # PyTorch의 주요 패키지로 텐서 연산 및 모델 구축에 사용됩니다.
import torchmetrics # PyTorch 모델의 성능 평가를 위해 사용됩니다.
import torch.nn.functional as F # PyTorch의 다양한 함수적 API를 사용하기 위해 임포트합니다.
from torch import nn # PyTorch의 신경망 모듈을 사용하기 위해 임포트합니다.
from torchvision import transforms # 데이터 전처리 및 변환을 위해 사용됩니다.
from torchvision.datasets import MNIST # MNIST 데이터셋을 불러오기 위해 사용됩니다.
from torch.utils.data import DataLoader, random_split # 데이터 로딩 및 분할을 위해 사용됩니다.
import pytorch_lightning as pl # PyTorch Lightning의 주요 패키지로, 모델 학습을 쉽게 관리하기 위해 사용됩니다.
from pytorch_lightning.loggers import TensorBoardLogger # TensorBoard 로깅을 위해 사용됩니다.
from pytorch_lightning.callbacks.early_stopping import EarlyStopping # 학습 조기 종료를 위한 콜백을 사용하기 위해 임포트합니다.
from pytorch_lightning.callbacks import ModelCheckpoint # 모델 체크포인트 저장을 위한 콜백을 사용하기 위해 임포트합니다.
from PIL import Image # 이미지 처리를 위해 사용됩니다.datasets 다운로드
!gdown --id 1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk
!unzip -q dogs-vs-cats.zip
!unzip -q train.zip
!unzip -q test1.zip 구글 드라이브에서 dogs-vs-cats, train, test1 데이터셋을 다운로드 해준다.
/usr/local/lib/python3.10/dist-packages/gdown/__main__.py:132: FutureWarning: Option `--id` was deprecated in version 4.3.1 and will be removed in 5.0. You don't need to pass it anymore to use a file ID.
warnings.warn(
Downloading...
From (original): https://drive.google.com/uc?id=1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk
From (redirected): https://drive.google.com/uc?id=1Dvw0UpvItjig0JbnzbTgYKB-ibMrXdxk&confirm=t&uuid=95fc0e00-e1f7-473b-aef1-6f00d98156b1
To: /content/dogs-vs-cats.zip
100% 852M/852M [00:23<00:00, 36.4MB/s]Dataloaders 셋업
이미지 분류를 위해 커스텀 데이터셋 클래스를 정의하고, 훈련 및 검증 데이터를 준비
class Dataset():
def __init__(self, filelist, filepath, transform = None):
self.filelist = filelist # 파일 목록을 저장합니다.
self.filepath = filepath # 파일 경로를 저장합니다.
self.transform = transform # 이미지 변환 함수를 저장합니다.
def __len__(self):
return int(len(self.filelist)) # 데이터셋의 크기를 반환합니다.
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index]) # 인덱스에 해당하는 이미지 경로를 생성합니다.
img = Image.open(imgpath) # 이미지를 엽니다.
# 이미지 경로에 "dog"가 포함되어 있으면 레이블을 1로, 그렇지 않으면 0으로 설정합니다.
if "dog" in imgpath:
label = 1
else:
label = 0
# 변환 함수가 정의되어 있으면 이미지를 변환합니다.
if self.transform is not None:
img = self.transform(img)
return (img, label) # 이미지와 레이블을 반환합니다.
# 파일 디렉토리 경로를 설정합니다.
train_dir = './train'
test_dir = './test1'
# 디렉토리 내 파일 목록을 가져옵니다.
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
# 이미지 변환을 정의합니다. 이미지를 60x60 크기로 조정하고 텐서로 변환합니다.
transformations = transforms.Compose([transforms.Resize((60,60)), transforms.ToTensor()])
# 훈련 및 검증 데이터셋 객체를 생성합니다.
train = Dataset(train_files, train_dir, transformations)
val = Dataset(test_files, test_dir, transformations)
# 훈련 데이터셋을 20,000개와 검증 데이터셋을 5,000개로 분할합니다.
train, val = torch.utils.data.random_split(train, [20000, 5000])
# 훈련 데이터 로더를 생성합니다. 배치 크기는 32이고, 데이터를 무작위로 섞습니다.
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
# 검증 데이터 로더를 생성합니다. 배치 크기는 32이고, 데이터를 무작위로 섞지 않습니다.
val_loader = torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
getitem: 주어진 인덱스에 해당하는 이미지와 레이블을 반환
이미지 경로에 dog가 포함돼있으면 레이블을 1로 그렇지 않으면 0으로 설정
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index])
img = Image.open(imgpath)
if "dog" in imgpath:
label = 1
else:
label = 0
if self.transform is not None:
img = self.transform(img)
return (img, label)훈련 및 검증 데이터셋 객체 생성:
train과 val 데이터셋 객체를 생성하고, 훈련 데이터셋을 20,000개, 검증 데이터셋을 5,000개로 분할
train, val = torch.utils.data.random_split(train,[20000,5000]) 전체코드
import os
import torch
import torchmetrics
import torch.nn.functional as F
from torch import nn
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
import pytorch_lightning as pl
from pytorch_lightning.loggers import TensorBoardLogger
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
from PIL import Image
import torchvision.models as models
# Dataset class 정의
class Dataset():
def __init__(self, filelist, filepath, transform=None):
self.filelist = filelist
self.filepath = filepath
self.transform = transform
def __len__(self):
return int(len(self.filelist))
def __getitem__(self, index):
imgpath = os.path.join(self.filepath, self.filelist[index])
img = Image.open(imgpath)
if "dog" in imgpath:
label = 1
else:
label = 0
if self.transform is not None:
img = self.transform(img)
return (img, label)
# 파일 디렉토리 경로 설정
train_dir = './train'
test_dir = './test1'
# 디렉토리 내 파일 목록 가져오기
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
# 이미지 변환 정의
transformations = transforms.Compose([transforms.Resize((60, 60)), transforms.ToTensor()])
# train 및 val 데이터셋 객체 생성
train = Dataset(train_files, train_dir, transformations)
val = Dataset(test_files, test_dir, transformations)
# train 데이터셋을 20000개와 5000개로 분할
train, val = torch.utils.data.random_split(train, [20000, 5000])
# 데이터 로더 생성
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
# 모델 정의
class ImagenetTransferLearning(pl.LightningModule):
def __init__(self):
super().__init__()
self.accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=2) # Accuracy 클래스에 필요한 인수 추가
# Pretrained resnet 초기화
backbone = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
num_filters = backbone.fc.in_features
layers = list(backbone.children())[:-1]
self.feature_extractor = nn.Sequential(*layers)
# Pretrained 모델 사용
num_target_classes = 2
self.classifier = nn.Linear(num_filters, num_target_classes)
def forward(self, x):
self.feature_extractor.eval()
with torch.no_grad():
representations = self.feature_extractor(x).flatten(1)
x = self.classifier(representations)
return F.softmax(x, dim=1)
def train_dataloader(self):
return torch.utils.data.DataLoader(dataset=train, batch_size=32, shuffle=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(dataset=val, batch_size=32, shuffle=False)
def cross_entropy_loss(self, logits, labels):
return F.nll_loss(logits, labels)
def training_step(self, batch, batch_idx):
data, label = batch
output = self.forward(data)
loss = nn.CrossEntropyLoss()(output, label)
self.log('train_loss', loss)
self.log('train_acc_step', self.accuracy(output, label))
return {'loss': loss}
def on_train_epoch_end(self):
# Log epoch metric
self.log('train_acc_epoch', self.accuracy.compute())
self.accuracy.reset()
def validation_step(self, batch, batch_idx):
val_data, val_label = batch
val_output = self.forward(val_data)
val_loss = nn.CrossEntropyLoss()(val_output, val_label)
self.log('val_acc_step', self.accuracy(val_output, val_label))
self.log('val_loss', val_loss)
return val_loss
def on_validation_epoch_end(self):
# Log epoch metric
self.log('val_acc_epoch', self.accuracy.compute())
self.accuracy.reset()
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
# 모델 초기화
model = ImagenetTransferLearning()
# PyTorch Lightning Trainer 초기화
trainer = pl.Trainer(
accelerator='gpu', # Use GPU
devices=1, # Use 1 GPU
max_epochs=10, # Maximum number of epochs
enable_progress_bar=True # Enable progress bar
)
# 모델 학습
trainer.fit(model, train_loader, val_loader)
코드 실행
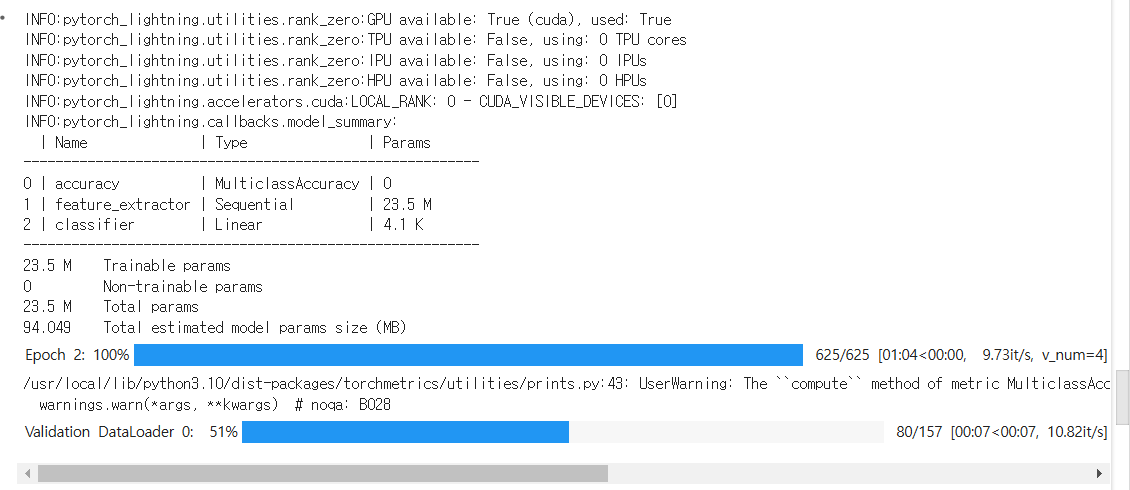
에포크를 실행하고 하나의 에포크가 끝나면 검증한다.

TensorBoard
# Start tensorboard.
%load_ext tensorboard
%tensorboard --logdir lightning_logs/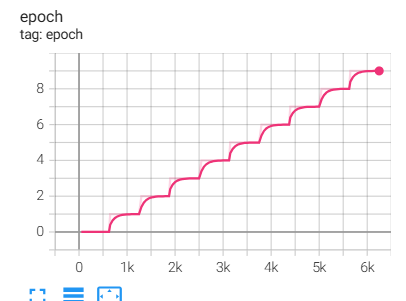
에포크는 0~9까지 10회를 진행

검증 데이터 개수가 늘어날수록 정확도가 늘어난다.
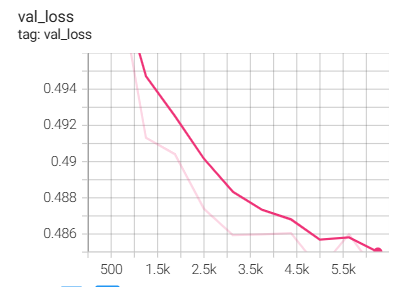
반대로 검증 로스는 줄어든다.

감사합니다. https://www.youtube.com/channel/UCxlkiu9_aWijoD7BannNM7w